











陳Ken
一位熱愛爬山的前端工程師
邊緣人再也不怕
Side Project
沒隊友 QQ
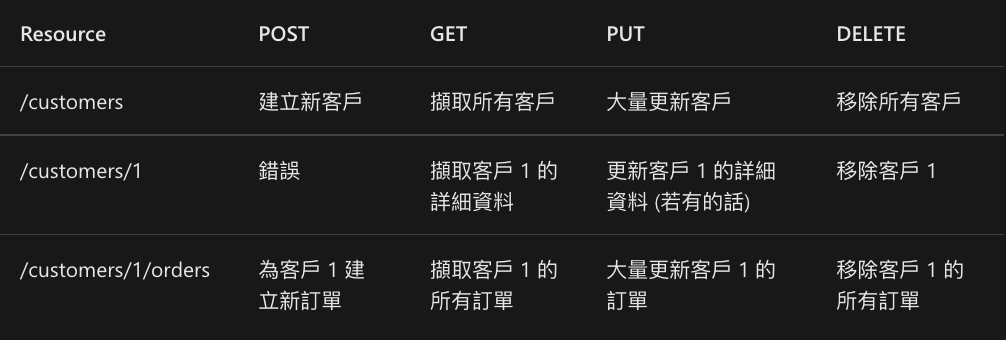
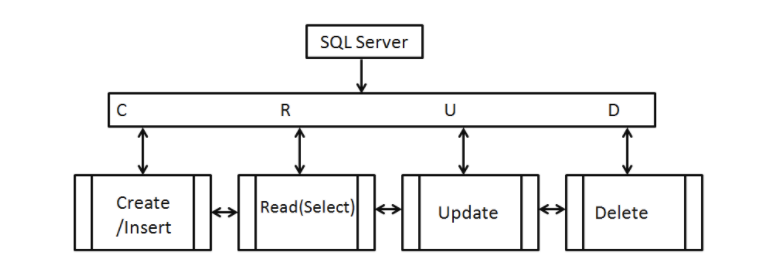
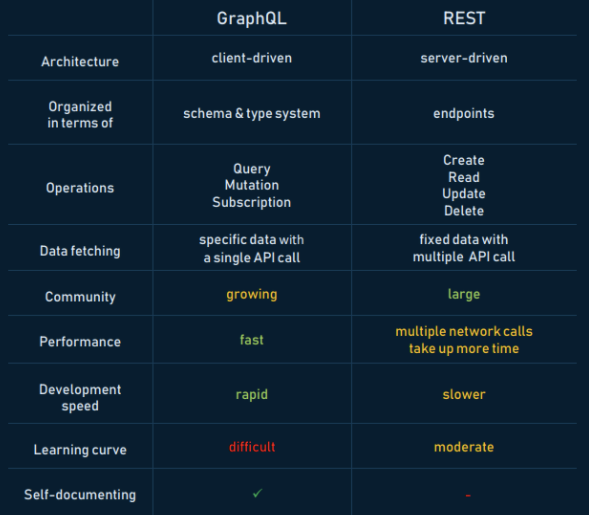
增 (Create)
查 (Read)
改 (Update)
刪 (Delete)
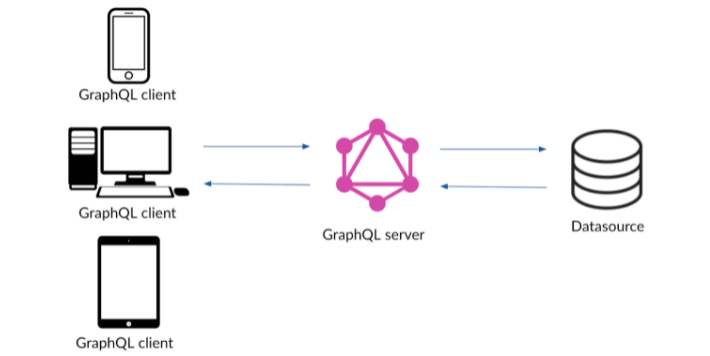
每個 endpoint 背後對應的是 ...
伺服器端的
某個資源
domain.com/customers
domain.com/customers/1/orders
像這裡是 DB 的某張表
(resources )
增 (Create)
查 (Read)
改 (Update)
刪 (Delete)
POST
GET
PUT
DELETE
SQL
語法
HTTP
請求方法
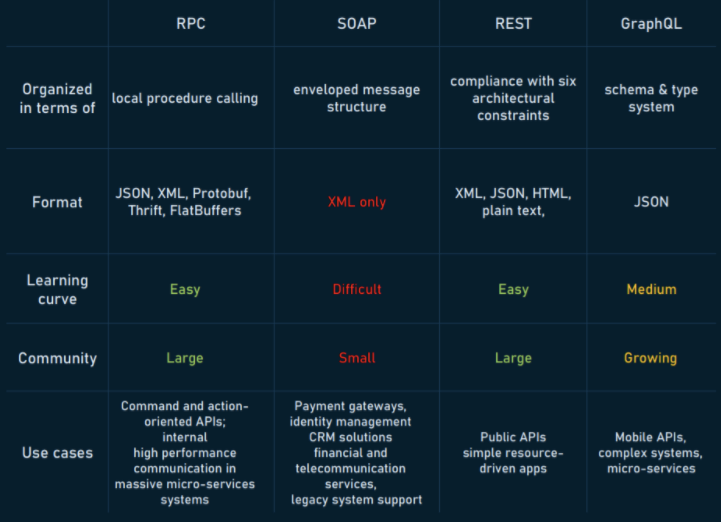
ref - CRUD工程师晋级之路
CRUD 到很厭世、
懷疑人生
ref - CRUD 工程师的价值是什么
打這支 endpoint 會回傳什麼資料啊?文件呢???
現在這個畫面我要打哪幾隻 API 才能拿到所有資料啊??
這個欄位會回傳什麼型別給我啊?
一定會是 List (array) 嗎?還是有可能是 null
我不確定耶~程式碼是不是多做點 fallback 啊?
我要怎麼樣打 API 會比較有效率?哪些可以先 cache somewhere
我現在到底有多少隻 endpoint 啊?
我想要xxx資料,要打哪隻 API 啊?
疑問多到
懷疑人生
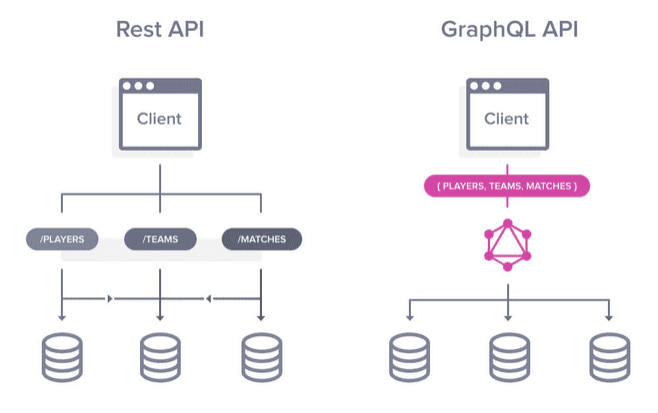
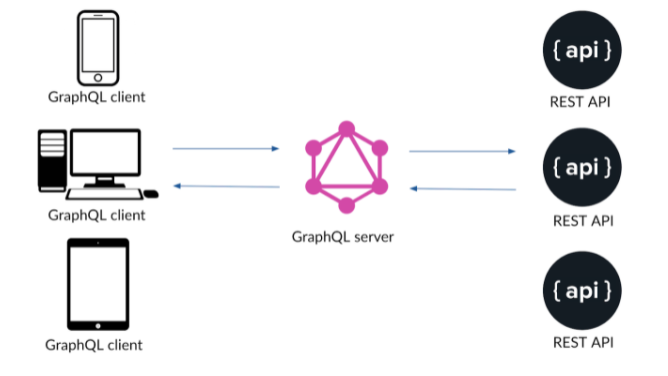
RESTful API : 需要打很多次 request
為了取得所有 resources
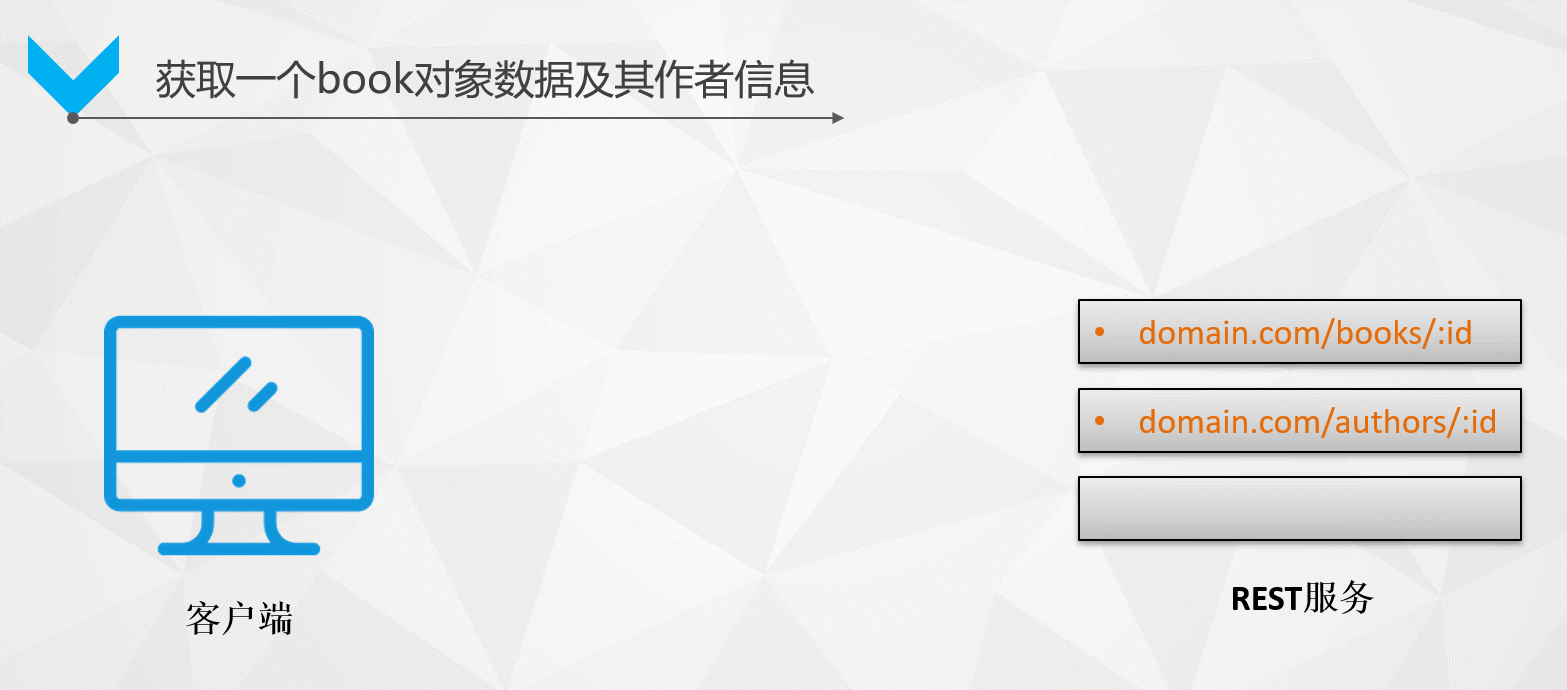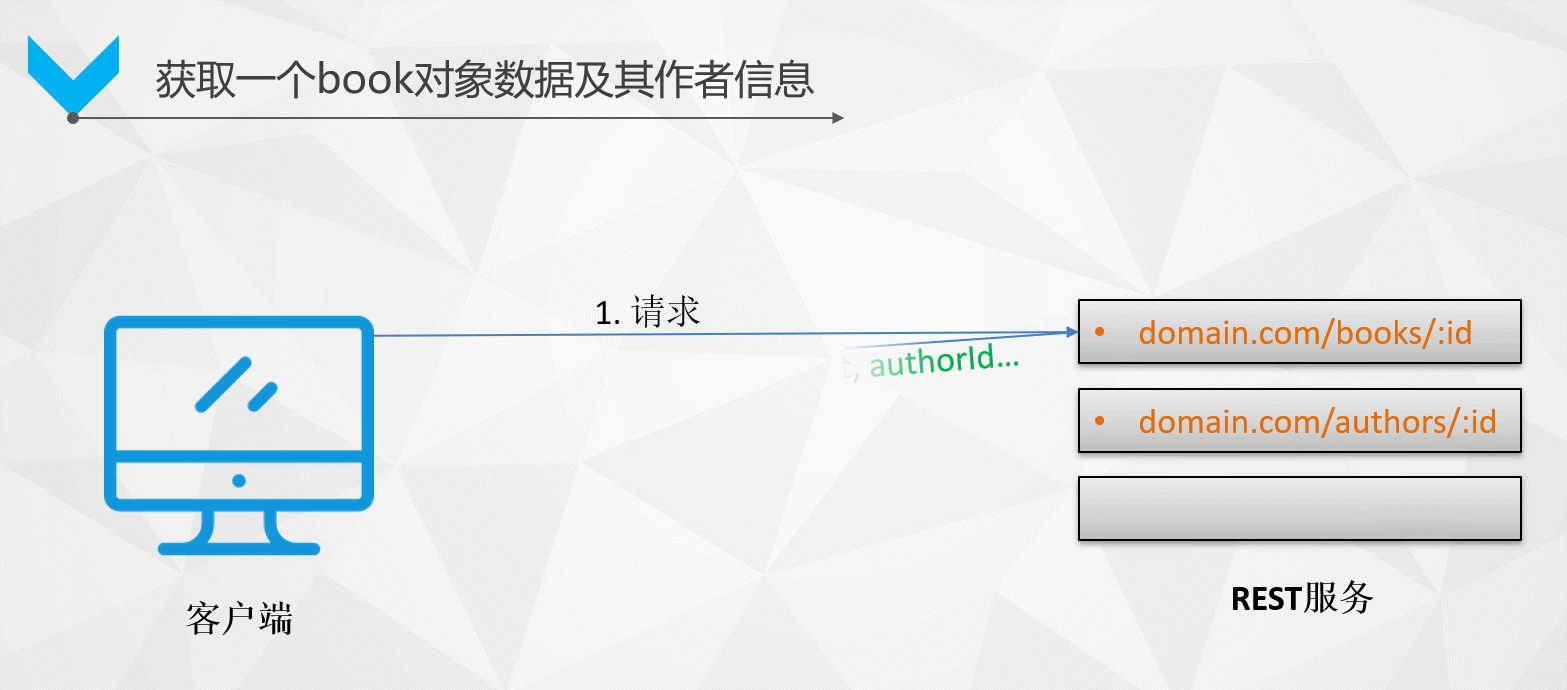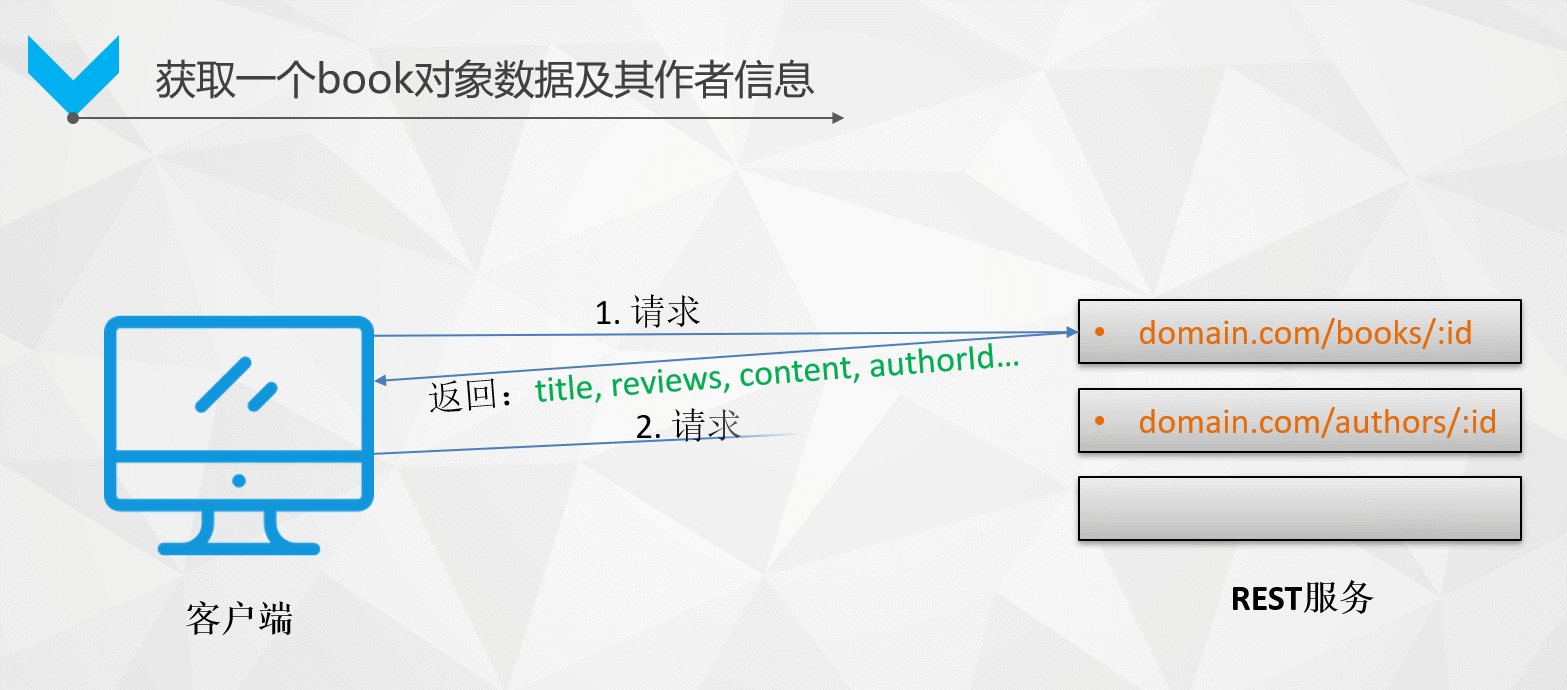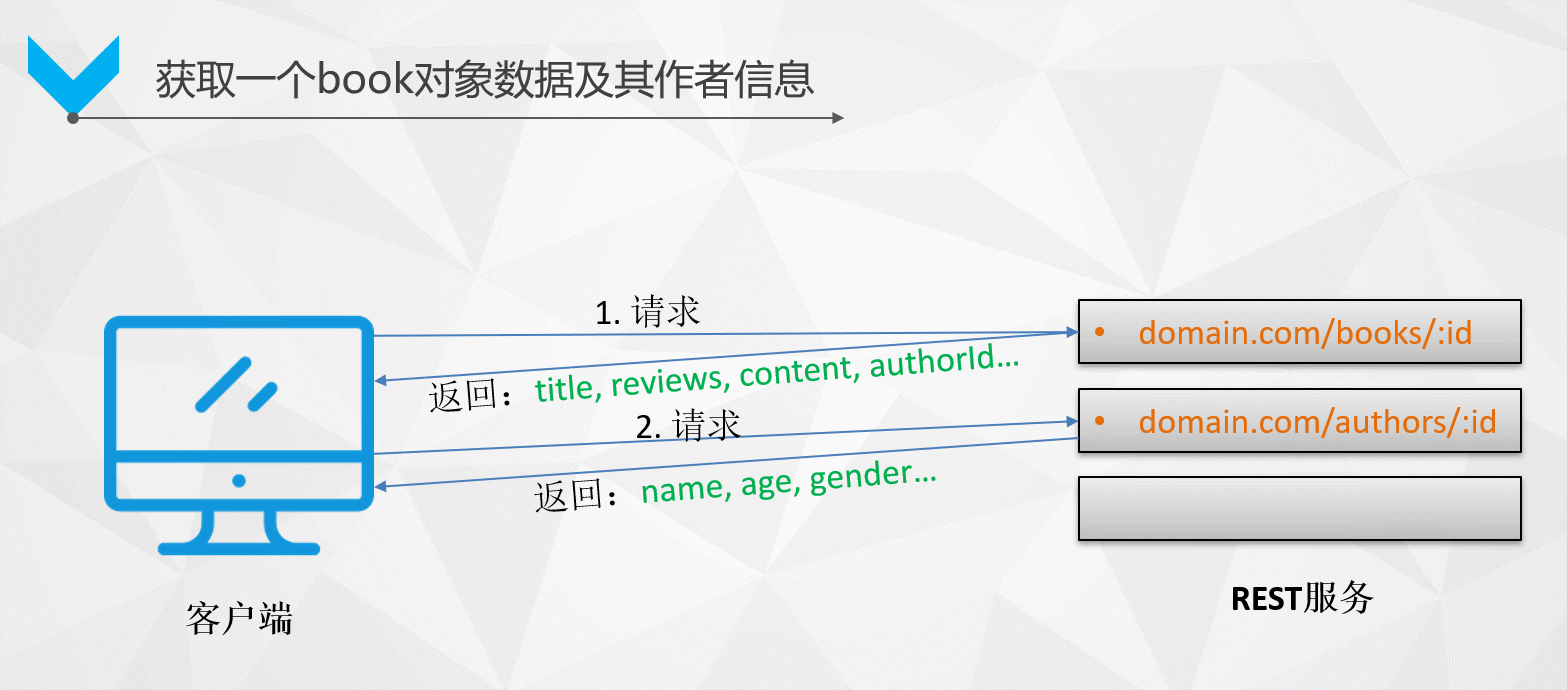
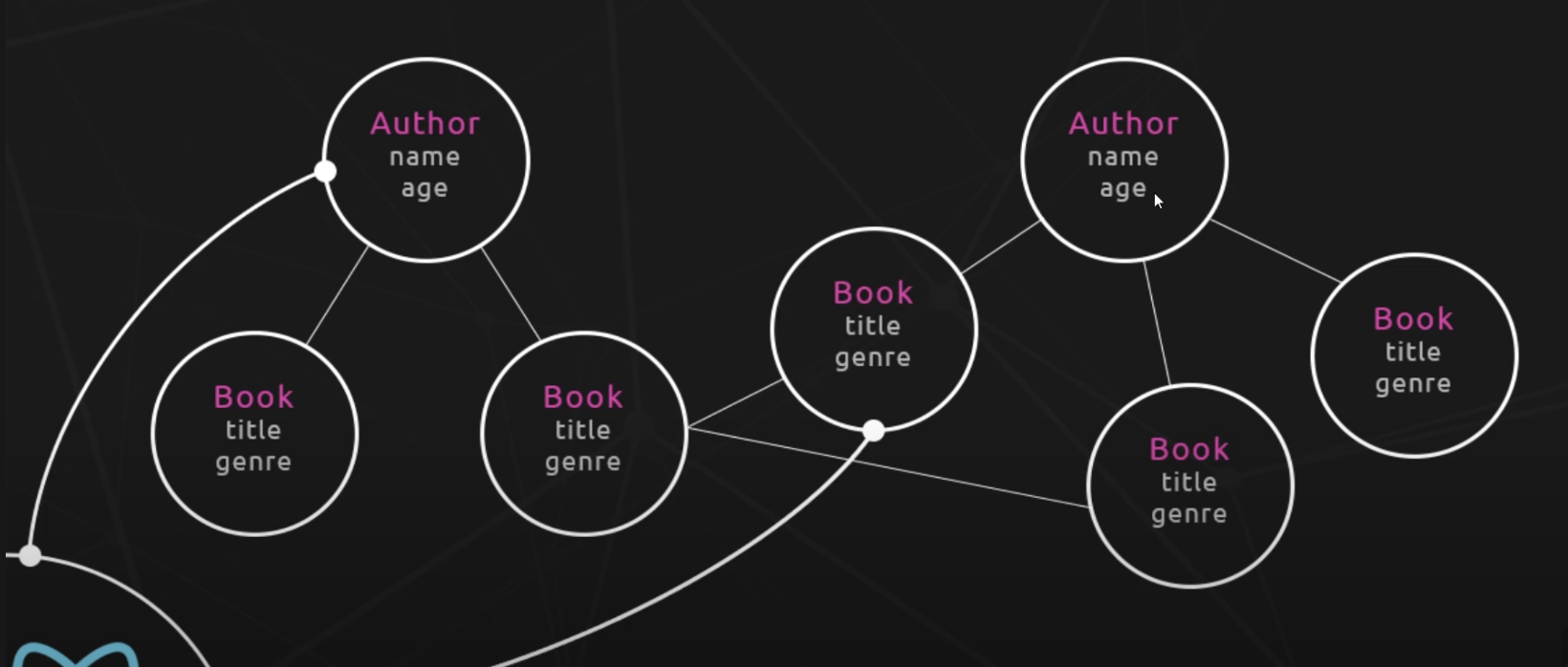
如何拿到某本書及該作者的所有資訊?
GraphQL API : 1次 request,取得所有 resources
如何拿到某本書及該作者的所有資訊?
endpoints
domain.com/graphql
domain.com/customers
domain.com/customers/{id}/orders
domain.com/products
domain.com/articles
domain.com/device-management
domain.com/device-management/managed-devices
domain.com/device-management/managed-devices/{id}
domain.com/device-management/managed-devices/{id}/scripts
domain.com/device-management/managed-devices/{id}/scripts/{id}
接 1 組 datasource
接 多 組
REST API
如何拿到某本書及該作者的所有資訊?
如何拿到某本書及該作者的所有資訊?
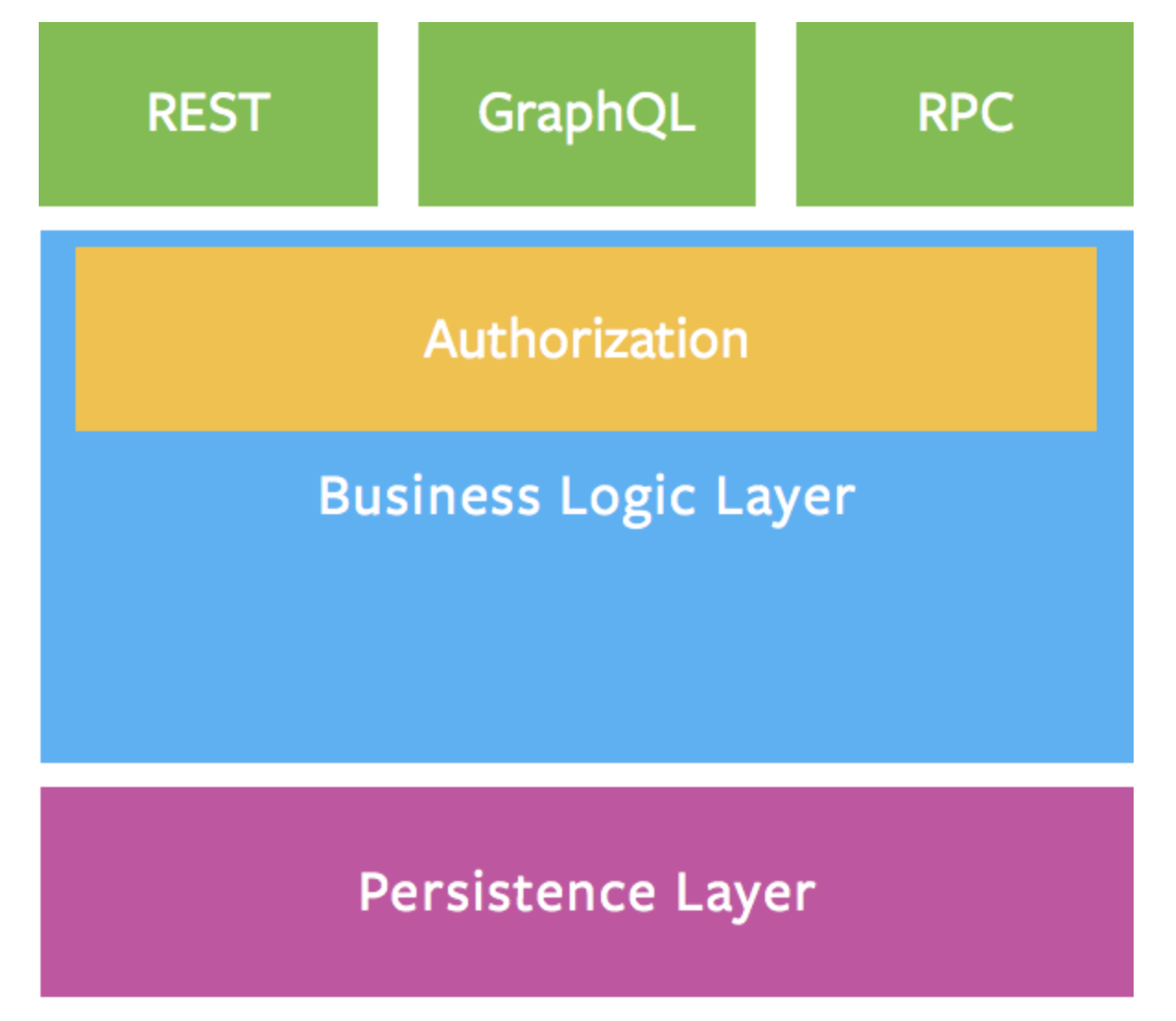
圖像化 描述、定義好 商業需求 與Resource 之前的關係
取得實際 Resource
如何拿到某本書及該作者的所有資訊?
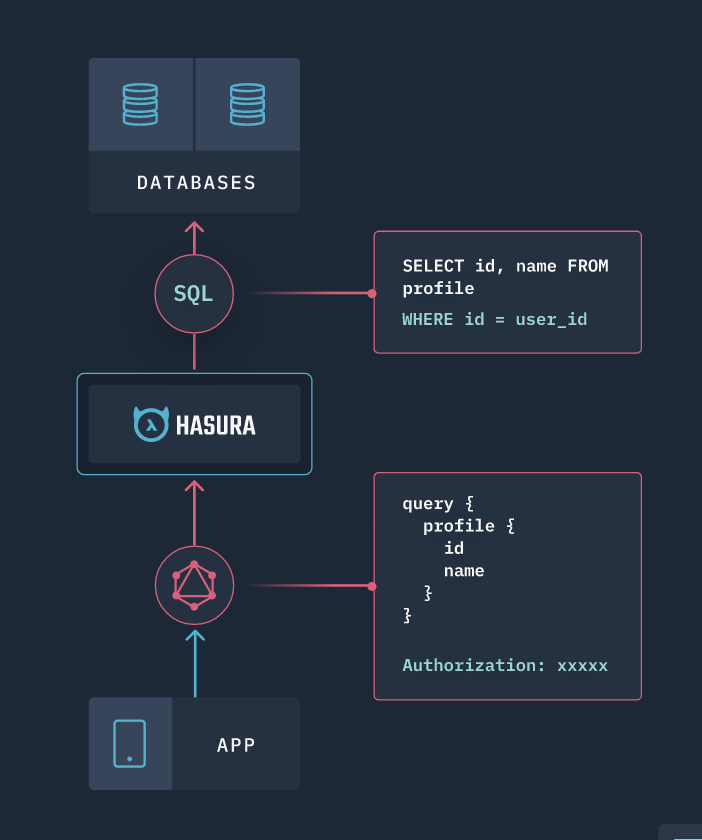
前端透過 Query (等於 REST 的 GET)取得所需的資料
Query 什麼?
前、後端 討論出的 Schema
如何拿到某本書及該作者的所有資訊?
前端透過 Query (等於 REST 的 GET)取得所需的資料
Query 什麼?
前、後端 討論出的 Schema
// schema.js
const Query = `
type Query {
author(id: Int!): Author
book(id: Int!): Book
}
`;// author.js
export const typeDef = `
type Author {
id: Int!
name: String
books: [Book]
}
`;// book.js
export const typeDef = `
type Book {
title: String
author: Author
}
`;
那 Schema 怎麼取得資源呢?
定義 Schema 時,同時也定義 Type了
如何拿到某本書及該作者的所有資訊?
// schema.js
const Query = `
type Query {
author(id: Int!): Author
book(id: Int!): Book
}
`;// author.js
export const typeDef = `
type Author {
id: Int!
name: String
books: [Book]
}
`;// book.js
export const typeDef = `
type Book {
title: String
author: Author
}
`;
那 Schema 怎麼取得資源呢?
寫 Resolver
const resolvers = {
Query: {
author(parent, args, context, info) {
return authors.find(user => user.id === args.id);
}
}
}
const authors = [
{ id: '1', name: '金庸' },
{ id: '2', name: '村上春樹'},
{ id: '3', name: '李琴峰' }
]
const server = new ApolloServer({
typeDefs,
resolvers,
dataSources: () => ({
authorAPI: new AuthorAPI(),
bookAPI: new BookAPI()
})
});
server.listen().....未處理 author 的books
db connect
api call
{
accounts {
inbox {
unreadEmailCount
}
}
}{
mainAccount {
drafts(first: 20) {
...previewInfo
}
}
}
fragment previewInfo on Email {
subject
bodyPreviewSentence
}所有帳號下的信箱的未讀信件的數量
主帳號前 20 篇草稿的預覽資訊
搞屁啊~ 從原本溝通 endpoint, response payload
感覺我現在好像還要多寫個 GraphQL schema
現在只不過變成改討論 schema, type
但我還不是要另外寫 resolver 來取得 resources
頂多可能格式或形狀能更符合業務需求
還有資料型別這件事能早點來出來討論
這樣我是不是寫原本的 endpoint 還比較省事?!
不過 Schema 好像就可以直接作為文件了?!
有人能幫我開 GraphQL schema 嗎?
有人能幫我寫 GraphQL resolver 嗎?
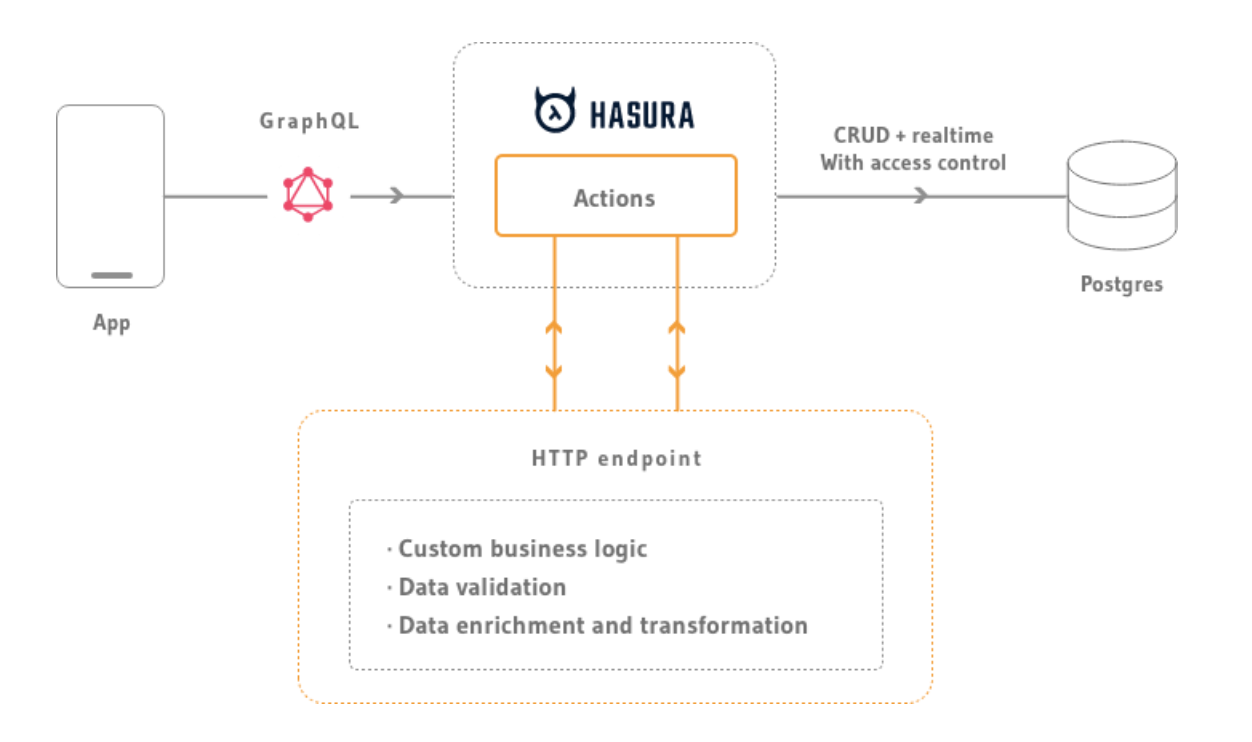
Query, Mutation 都幫你串好了
也包含 filter, pagination, aggregation
db constraint 也一併被考慮進去
Show Me the code
# 建立一張 Table book
- id
- isbn
- name
- author_id -> author.id
- book_tag id
# 建立一張 Table author
- id
- name
# 建立一張 Table tag
- id
- name
# 建立一張 Table book_tag
- id
- tag_id -> tag.id
- book_id -> book.id
# 建立一張 View
- book name
- author name
- tag nameQuery, Mutation 一樣沒問題
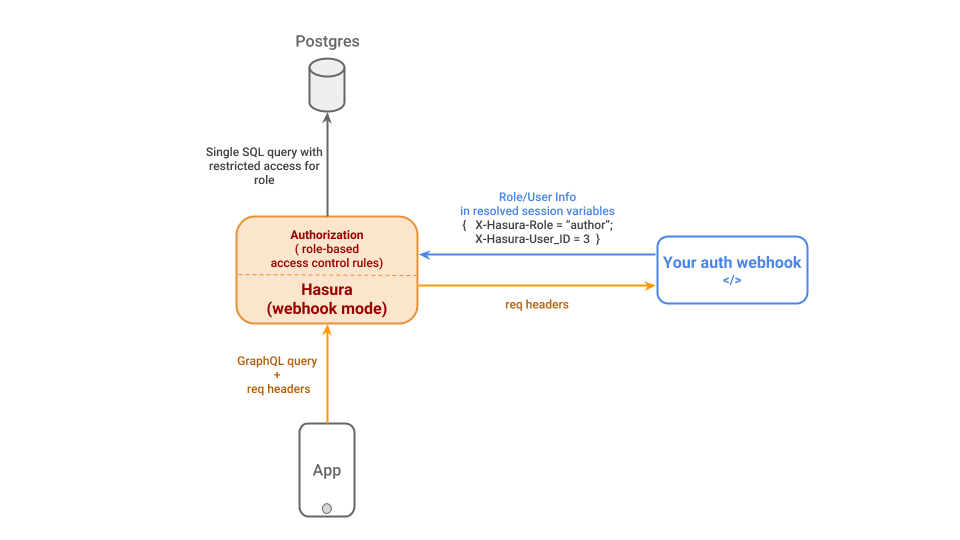
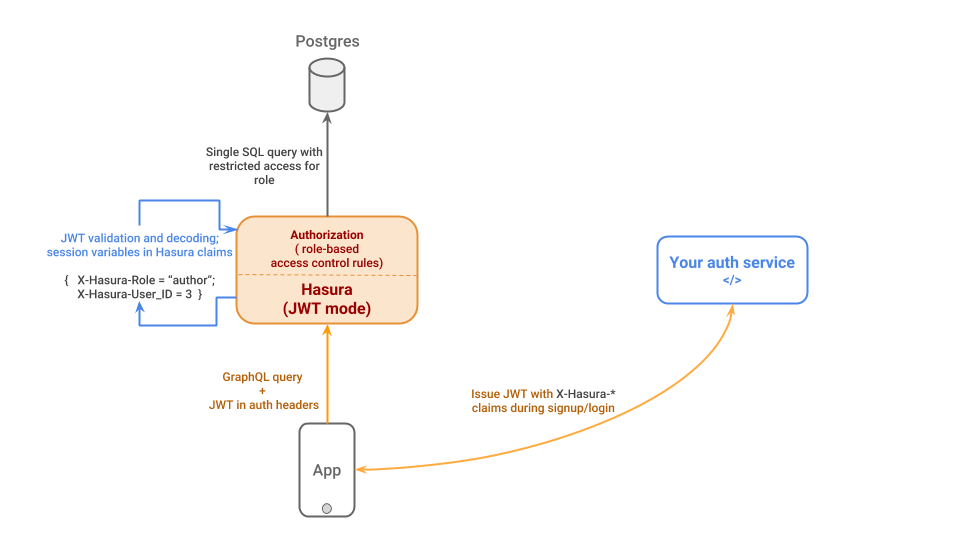
可以整合 Webhook, JWT
可以整合 Webhook, JWT
可以針對欄位,某個 record 的某個 column,保護
Row level Permission
Column level Permission
Role Permission
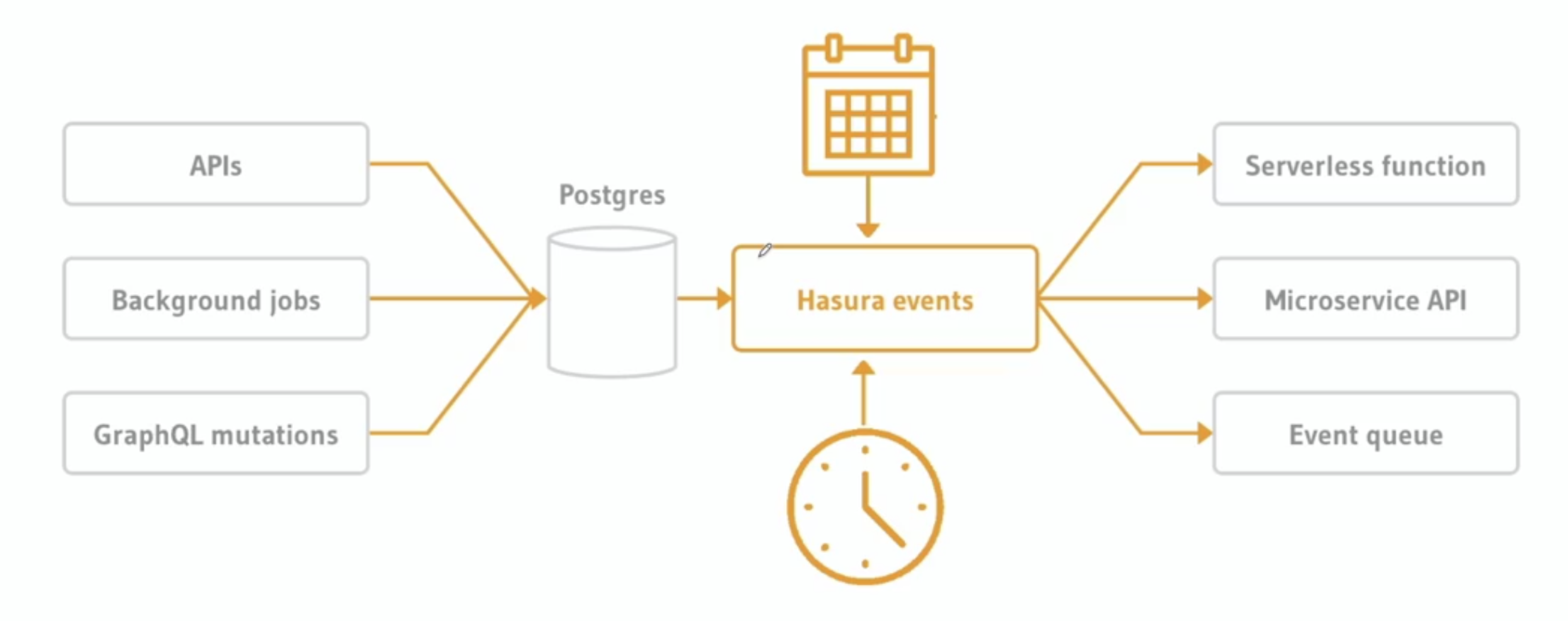
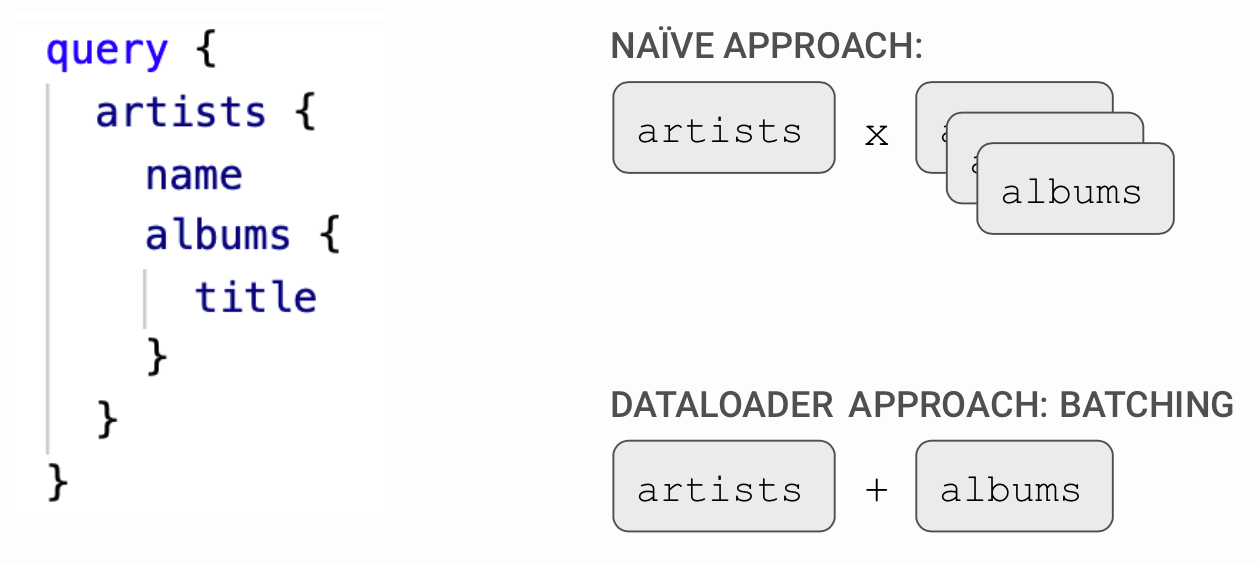
N + 1 效能問題也順便幫你想到了
SELECT id,name FROM artists;
# 跑 1 次
SELECT title FROM albums WHERE artist_id = <artist-id>
# n 個 artisit 跑 n 次SELECT artists.name as name
FROM artists
JOIN albums
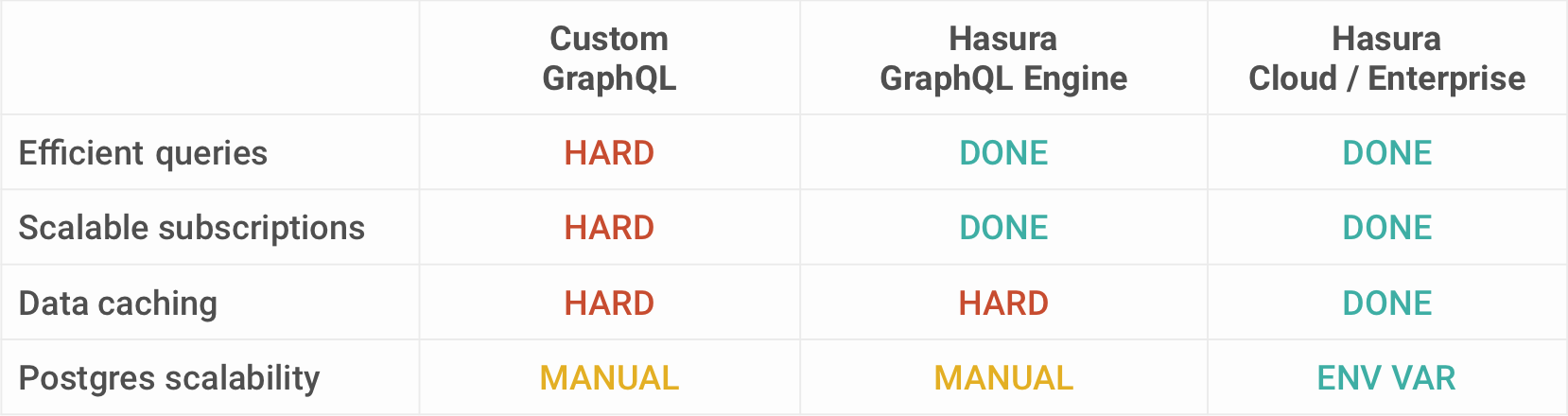
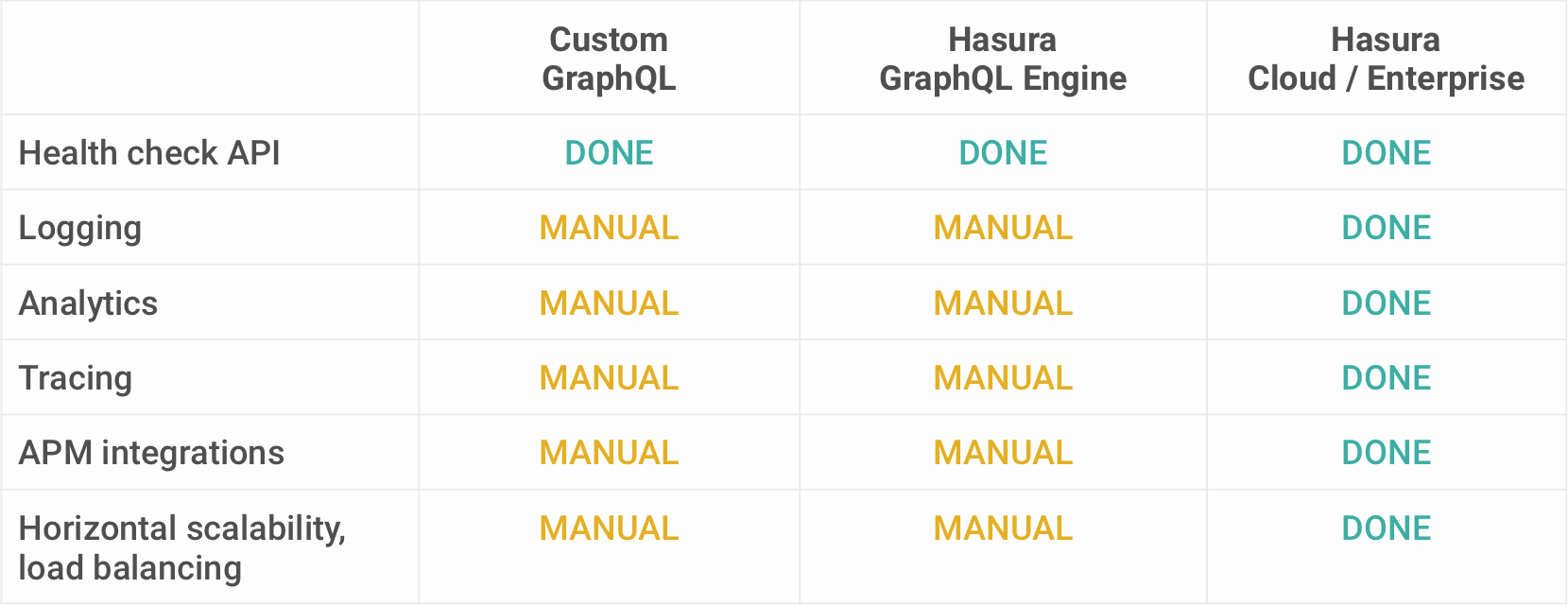
ON (artists.id = albums.artist_id)One common concern with GraphQL, especially when comparing it to REST, are the difficulties to maintain server-side cache. With REST, it’s easy to cache the data for each endpoint, since it’s sure that the structure of the data will not change.
With GraphQL on the other hand, it’s not clear what a client will request next, so putting a caching layer right behind the API doesn’t make a lot of sense.
Server-side caching still is a challenge with GraphQL. More info about caching can be found on the GraphQL website.
Response Caching
Caching GraphQL queries at the server side needs a different approach compared to a typical REST API architecture. In REST, you can cache queries at the HTTP layer using GET requests and serve it in front of a CDN. Typically GraphQL queries are POST requests and caching needs to be handled differently.
Query Caching: Hasura already offers query caching in the OSS version, where the internal representation of the fully qualified GraphQL AST is cached, so that it’s plan need not be computed again. For Postgres, Hasura makes use of Prepared Statements to make query execution faster. Read more about Hasura's fast GraphQL query execution.
Data Caching: Hasura Cloud goes a step further and adds support for data caching on top of the query caching that's already available. Hasura has enough information about the data models across data sources, and the authorization rules at the application level letting users cache authenticated GraphQL API calls that works for shared data.
Cache invalidation is handled by using a TTL configuration so that state data is refreshed within a time interval. So clients can query with a @cached directive for data caching.
Learn more about the usage of @cached directive in this video - An approach to automated caching for public & private GraphQL APIs.
By 陳Ken




