Des applications pratiques du text mining scientifique
Patrice Lopez
-
Text mining / fouille de textes correspond à un ensemble de technique visant à extraires des informations structurées (patterns) de textes brutes
-
Data Mining / fouille de données / Data science, ensemble de technique visant à extraires des informations structurées (patterns) de données brutes
-
Data Analytics (traitement analytique de donnéee) est l’exploitation des d’informations structurées (extraites ou non de données brutes) en vue de résoudre un problème d’activité économique
-
Text Analytics correspond à du Data Analytics sur des données d’origine textuelle (provenant souvent de fouille de textes)
Cette présentation...
- ... se focalisera uniquement sur le text mining
(pas sur le data mining)
- ... ne couvrira que les applications effectives
(pas les applications potentielles et à venir)
- ...se concentre sur les applications scientifiques et techniques
(pas sur l'analyse de sentiments, les mots-clefs publicitaires, etc.)
Pourquoi le text mining?
Croissance du volume de publications
-
~1,5 millions nouveaux articles scientifiques par an
-
+7% par an, double tous les 10 ans
-
Scientometrics 2010; 84(3): 575–603
-
-
2.2 millions de publications brevets par an
| chercheur | 1977 | 2012 |
|---|---|---|
| lectures articles/mois | 12-13 | 22 |
| temps par article | 48 mn | 32 mn |
| articles par an | ~120 000 | > 1 000 000 (x8) |
-
Résumé et classifications ne suffisent pas
-
“Only 7.84% of the scientific claims made in full-text articles are found in their abstracts.”
-
Catherine Blake. “Beyond genes, proteins, and abstracts: Identifying scientific claims from full-text biomedical articles.” Journal of Biomedical Informatics Volume 43, Issue 2, April 2010, Pages 173–189
-
- Revue systématique (“systematic review”), étude exhaustive de la littérature pertinente à une question de recherche : 10 000 plein textes à lire, >1000 heures en moyenne, jusqu'à 18 mois
- Recherche de brevets : ~80% des documents des rapports de recherche OEB ne partagent pas la classe principale IPC de la demande
Nécessité d'exploiter le plein texte
- Les autorités publiques de santé d'Afrique de l'ouest considèraient que le virus Ebola n'avait pas été observé au Libéria, Sierra Leone et Guinée avant 2013
- Aucune précaution, mesure, etc. relatif au virus Ebola n'avait été prévue pour le personnel médical de ces pays
- Pour cette raison l’épidémie causa plus de 11 000 décès
Un exemple : l'épidémie du virus Ebola au Libéria, Sierra Leone et Guinée en 2013-2016

Un exemple : l'épidémie du virus Ebola au Libéria, Sierra Leone et Guinée en 2013-2016

Dans le plein texte uniquement...


Tâche typique du Text mining
Exemple
avec
Adage in public health: “The road to inaction is paved with research papers.”
Applications pratiques du text mining
Amélioration des moteurs de recherche
- Pour un moteur de recherche standard, une requête sur un terme va retourner toutes ses occurences
- Pour les recherches d'information orientées rappel, cela aboutit à un bruit et une perte de temps considérable
Galaxie d'Andromède
Andromeda galaxy
Andromeda
M31
NGC 224
PGC 2557
MCG+07-02-016
UGC 454
1RXS J004241.8+411535
CGCG 535-017
MAXI J0043+410
CGCG 0040.0+4100
2PBC J0042.6+4111
MCG +07-02-016
XMMLPt 1010
GIN 801
XMMM31 J004244.1+411607
B3 0040+409

2MASX J00424433+4116074
J004244.4+411612
IRAS 00400+4059
EXSS 0039.9+4059
IRAS F00400+4059
1H 0039+408
KTG 01C
1ES 0039+409
LDCE 0031 NED007
XSS J00425+4102
HDCE 0029 NED003
2FGL J0042.5+4114
LQAC 010+041 001
HOLM 017A
NSA 127580
PGC 002557
11HUGS 013
etc.

- Les expansions de requêtes ne résolvent pas le problème d'accès à l'information scientifique, mais au contraire agravent le bruit
- Le text mining permet de résoudre en amont le problème en désambiguisant les termes en contexte

entity-fishing

entity-fishing
Recherche de mesures physiques
- If you want to check for a thickness in the range between 100 and 300 micron, you could use the query:
- Cette expression va manquer beaucoup de formes communes : 100,5μm, 0,2mm, 2.10-4m, etc.
- Elle demande une connaissance experte du moteur de recherche
- Beaucoup d’erreurs possible dans sa formulation
- Très peu de moteurs de recherche supportent de tels opérateurs (pas Google Scholar par exemple)
([1-2][0-9][0-9] or 300) 3W (OR micro?, micromet?r??, MU_M, UM)

grobid-quantities

grobid-quantities

Recherche de document en Chimie
- La base PubChem par exemple contient plus de 600 millions d'entrées : substances, composés, dosages
- Des outils de text mining sont utilisés pour identifier les entités chimiques mentionnées dans les documents afin de les rendre cherchables
- SureChEMBL, SciFinder (CAS), Reaxys (Elsevier), ChemSpider, PatSnap
- Ces outils sont utilisés de façon routinière par les chimistes depuis quelques années
SureChEMBL : substances chimique textuelles

SureChEMBL : formules graphiques

SureChEMBL : requêtes

Extraction d'information
- Extraction d'entités bio-médicales et de relations



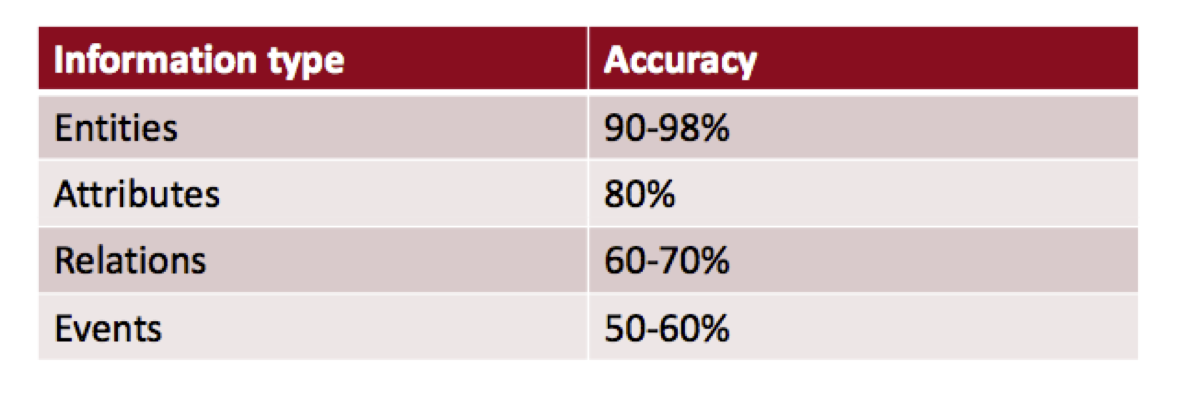
Pour des domaines établis, riches en ressources comme la biomédicine!
- L'extraction automatique d'informations bibliographiques est aujourd'hui communément utilisée dans les grands services de diffusion d'information scientifique
- réseau sociaux pour chercheurs ;
- grands organismes scientifiques CERN, NASA ;
- service de recherche académique Google Scholar, Semantic Scholar
Informations bibliographiques

HAL : références bibliographiques extraites automatiquement du PDF par GROBID
Merci pour votre attention !
Patrice Lopez
INIST
By kermitt2
