Encoding,
Unicode,
Python2
Miért?
- Alapvető hogy tudjuk helyesen kezelni
(programozás 1x1)
- Leggyakoribb típus text (str, unicode)
- Helyesen jelenjenek meg az ékezetes karakterek
(pl. user nem tudja beírni a nevét...)
- olvasható log output
Miért ?
(nyomós ok)
So I have an announcement to make: if you are a programmer working in 2003 and you don't know the basics of characters, character sets, encodings, and Unicode, and I catch you, I'm going to punish you by making you peel onions for 6 months in a submarine. I swear I will.Joel Spolsky
Mi az a
character set?
ASCII (0-127)
0-31: control characters

OEM

0
127
128
255
Mi az a
character set?
Mi az a Unicode?
- Az "egyetlen", egyesített character set
- character --> code point összerendelés
1,114,112 in the range 0 to 10FFFF
egy karakter nem feleltethető meg egy byte-nak
- Szabány: The Unicode Standard
jelenleg 120,000 karakter van benne,
legújabb verzió Unicode 8.0
-
Szervezet: Unicode Consortium
http://unicode.org/
Unicode példák
'Hello': U+0048 U+0065 U+006C U+006C U+006F
'X': U+0058
egy karakter: U+hex
Mi az az encoding?
- Karakterek (string) tárolási formája byte-okban
- Unicode előtt összemosódott a character settel
ASCII (?)
OEM (?)
Latin-1 v ISO-8859-1
ISO-8859-2
UCS-2 v UTF-16
UTF-8
UCS-4
Encoding röviden
Unicode
byte-ok
UTF-8
Unicode Transformation Format
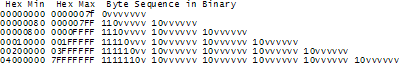
- variable-width encoding
- 1 byte-ig kompatibilis ASCII-vel
0-127 ugyanaz mint ASCII 0-127 - leggyakoribb (főleg weben)
- valid ASCII = valid UTF-8
Mi a különbség
character set és
encoding között?
Semmi ?
$ man ascii
Oct Dec Hex Char Oct Dec Hex Char
────────────────────────────────────────────────────────────────────────
000 0 00 NUL '\0' 100 64 40 @
001 1 01 SOH (start of heading) 101 65 41 A
002 2 02 STX (start of text) 102 66 42 B
003 3 03 ETX (end of text) 103 67 43 C
004 4 04 EOT (end of transmission) 104 68 44 D
005 5 05 ENQ (enquiry) 105 69 45 E
006 6 06 ACK (acknowledge) 106 70 46 F
007 7 07 BEL '\a' (bell) 107 71 47 G
010 8 08 BS '\b' (backspace) 110 72 48 H
011 9 09 HT '\t' (horizontal tab) 111 73 49 I
012 10 0A LF '\n' (new line) 112 74 4A J
013 11 0B VT '\v' (vertical tab) 113 75 4B K
014 12 0C FF '\f' (form feed) 114 76 4C L
015 13 0D CR '\r' (carriage ret) 115 77 4D M
016 14 0E SO (shift out) 116 78 4E N
017 15 0F SI (shift in) 117 79 4F O
020 16 10 DLE (data link escape) 120 80 50 P
021 17 11 DC1 (device control 1) 121 81 51 Q
022 18 12 DC2 (device control 2) 122 82 52 R
023 19 13 DC3 (device control 3) 123 83 53 S
024 20 14 DC4 (device control 4) 124 84 54 T
025 21 15 NAK (negative ack.) 125 85 55 U
026 22 16 SYN (synchronous idle) 126 86 56 V
027 23 17 ETB (end of trans. blk) 127 87 57 W
030 24 18 CAN (cancel) 130 88 58 X
031 25 19 EM (end of medium) 131 89 59 Y
032 26 1A SUB (substitute) 132 90 5A Z
033 27 1B ESC (escape) 133 91 5B [
034 28 1C FS (file separator) 134 92 5C \ '\\'
035 29 1D GS (group separator) 135 93 5D ]
036 30 1E RS (record separator) 136 94 5E ^
037 31 1F US (unit separator) 137 95 5F _
040 32 20 SPACE 140 96 60 `
041 33 21 ! 141 97 61 a
042 34 22 " 142 98 62 b
043 35 23 # 143 99 63 c
044 36 24 $ 144 100 64 d
045 37 25 % 145 101 65 e
046 38 26 & 146 102 66 f
047 39 27 ´ 147 103 67 g
050 40 28 ( 150 104 68 h
051 41 29 ) 151 105 69 i
052 42 2A * 152 106 6A j
053 43 2B + 153 107 6B k
054 44 2C , 154 108 6C l
055 45 2D - 155 109 6D m
056 46 2E . 156 110 6E n
057 47 2F / 157 111 6F o
Encoding beállítás
Szövegszerkesztőben
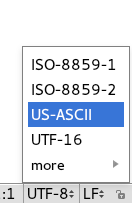

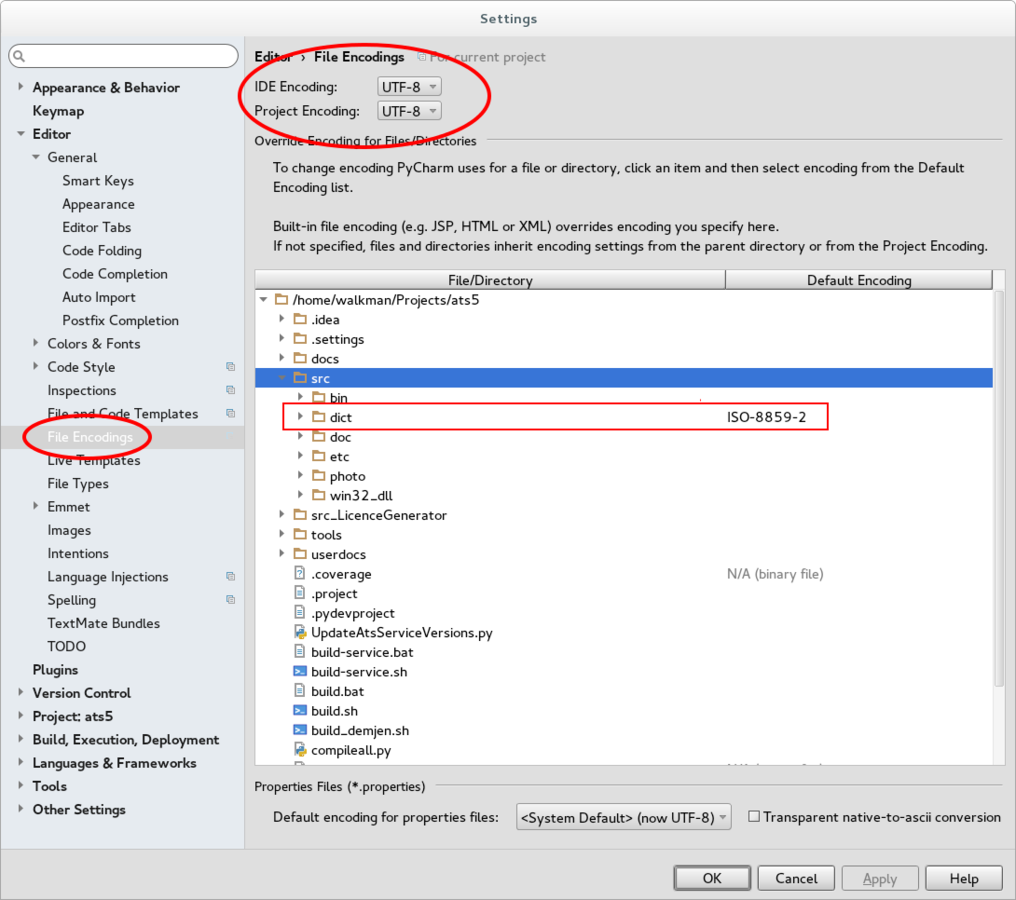
Terminálban
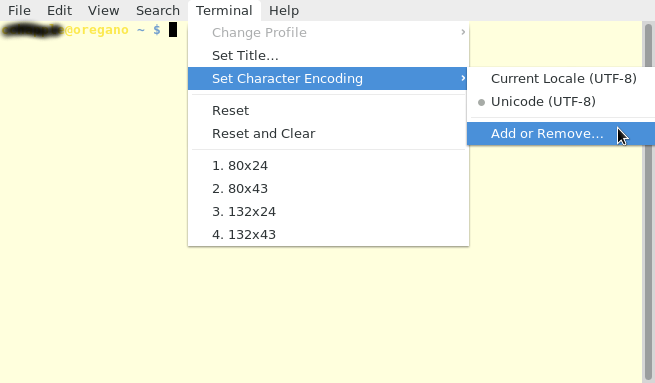
1.
2.
$ locale
LANG="en_US.UTF-8"
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="hu_HU.utf8"
LC_TIME="hu_HU.utf8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="hu_HU.utf8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="hu_HU.utf8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="hu_HU.utf8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
# /etc/sysconfig/language
RC_LANG="en_US.UTF-8"
OpenSuse beállítás:
# ~/.bashrc
export LANG="en_US.utf8"OpenSUSE
beállítások
Elérhető locale lista
❯ locale -a
aa_DJ
aa_DJ.utf8
aa_ER
aa_ER@saaho
aa_ET
af_ZA
af_ZA.utf8
...
en_GB
en_GB.iso885915
en_GB.utf8
...
hu_HU
hu_HU.utf8
...Weboldalon
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
...
<meta charset="utf-8"> HTML5:
XML-ben
<?xml version="1.0" encoding="UTF-8" ?>Emailben
header
Content-Type: text/plain; charset="UTF-8"Python fájlban
# -*- coding: utf-8 -*-String típusok Pythonban
str
- "byte-string"
- nem tudjuk az enkódolását,
valamilyen meta forrásból kell beszerezni
unicode
- unicode codepointok sorozata
(ugyanúgy mint a szabványban)
- nincs enkódolása
>>> u'tűrő'
u't\u0171r\u0151'
U+0171
U+0151
unicode
konstruktor
unicode(object[, encoding[, errors]])
- összes paraméter str
- 1. paramétert konvertáljuk
- 2. paraméterben megadott enkódolással
- ha 2.-at kihagyjuk, alapértelmezett enkódolás: ASCII
>>> unicode('abcdef')
u'abcdef'
>>> s = unicode('abcdef')
>>> type(s)
<type 'unicode'>
>>> unicode('abcdef' + chr(255))
Traceback (most recent call last):
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff in position 6:
ordinal not in range(128)
unicode
konstruktor hibakezelés
-
strict: nem konvertálja
-
replace: � (U+ffffd)
-
ignore: kihagyja
>>> unicode('\x80abc', errors='strict') # 0x80 == 128
Traceback (most recent call last):
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0x80 in position 0:
ordinal not in range(128)
>>> unicode('\x80abc', errors='replace')
u'\ufffdabc'
>>> unicode('\x80abc', errors='ignore')
u'abc'basestring
mindkettő közös őse
>>> isinstance('alma', basestring)
True
>>> isinstance(u'alma', basestring)
True
>>> isinstance(u'alma', str)
False
>>> isinstance(u'alma', unicode)
True
>>> isinstance('alma', unicode)
False
>>> isinstance('alma', str)
True
>>>
bytes
alias str
>>> bytes
<type 'str'>
bytearray
>>> bytearray
<type 'bytearray'>
>>> bytearray('alma')
bytearray(b'alma')
>>> bytearray('alma')[0]
97
>>>
encodings
Python2-ben
Irányok
str
unicode
.encode()
.decode()
Mi a probléma?
- Python2-ben ezek összefolynak
(történelmi okokból)
-
Python2 alap fileok enkódolása: ASCII
- str + unicode: str->ből unicode lesz implicit dekódolással, ami alaból ASCII, pl.:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte \
0xc3 in position 0: ordinal not in range(128)
>>> "Hello " + u"Unicode"
u'Hello Unicode'coercing str
into unicode
bal oldali str-t implicit dekódolja az interpreter unicode-á az alapértelmezett enkódolással
(Python2 esetén ASCII)
Mikor nem lehet Unicode-ból
ASCII-val konvertálni?
Ha a karakter nem esik a 0-127 tartományba!
?
# -*- coding: utf-8 -*-- alapértelmezett encoding: ASCII
- csak a file enkódolását változtatja meg
- editorok, IDE-k speciálisan kezelik

Általános stratégia
Kódon belül minden unicode,
I/O határokon alakítjuk át
- fileból olvasás
- HTTP request
- HTTP response
- kommunikáció külső eszközzel
- stb.
Mikor milyen Exceptiont kapunk?
>>> "Hello " + u"Unicode"u'Hello Unicode'1.
2.
>>> '\xc3\xa9tterem' == u'étterem'__main__:1: UnicodeWarning: Unicode equal comparison failed to convert \
both arguments to Unicode - interpreting them as being unequal
False
Helyesen:
>>> '\xc3\xa9tterem'.decode('utf-8') == u'étterem'
True
>>> u'étterem'.encode('utf-8')
'\xc3\xa9tterem'3.
>>> '\xc3\xa9tterem'.decode()Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode \
byte 0xc3 in position 0: ordinal not in range(128)
>>> '\xc3\xa9tterem'.decode('utf-8')
u'\xe9tterem'Helyesen:
4.
>>> u'Árvíztűrő'.encode('utf8')
'\xc3\x81rv\xc3\xadzt\xc5\xb1r\xc5\x91'
>>> u'Árvíztűrő'.encode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character \
u'\xc1' in position 0: ordinal not in range(128)Helyesen:
>>> u'kisvasút'.find('vas\xc3\xbat')5.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: \
ordinal not in range(128)
>>> u'kisvasút'.find(u'vasút')
3>>> u'vasút'.encode('utf-8')
'vas\xc3\xbat'Helyesen:
>>> u'kisvasút'.find('vas\xc3\xbat'.decode('utf-8'))
3
vagy
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte \
0xc3 in position 0: ordinal not in range(128)
6.
>>> '\xc3\xa9tterem'.encode('utf-8')>>> u'étterem'.encode('utf-8')
'\xc3\xa9tterem'
Helyesen:
>>> '\xc3\xa9tterem'.decode('utf-8').encode('utf-8')
'\xc3\xa9tterem'Miért működik?
>>> print '€'
€
>>> print 'árvíztűrő tükörfúrógép'
árvíztűrő tükörfúrógép
- '€': enkódolt bytestring
- terminál encoding: UTF-8
- azt a byte stringet amit a print küld a terminálnak, így jeleníti meg
>>> import locale
>>> locale.getpreferredencoding()
'UTF-8'Miért nem működik?
>>> print u'£1'.encode('latin-1')
�1
>>>
>>> import locale
>>> locale.getpreferredencoding()
'ISO-8859-1'
>>> print u'£1'.encode('latin-1')
£1$ export LC_ALL='en_US.latin1'
$ pythonFájlok kezelése
Pythonban
>>> with open('unifile.txt') as f:
... content = f.read()
>>> type(content)
<type 'str'>
>>> content
'\xc3\x81rv\xc3\xadzt\xc5\xb1r\xc5\x91 t\xc3\xbck\xc3\xb6rf\xc3\xbar\xc3\xb3g\xc3\xa9p'open()
>>> content + u'valami'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 0: \
ordinal not in range(128)
>>> with open('unifile.txt') as f:
... content = f.read().decode('utf-8')
>>> type(content)
<type 'unicode'>
>>> content
u'\xc1rv\xedzt\u0171r\u0151 t\xfck\xf6rf\xfar\xf3g\xe9p'open(), decode
>>> content + u'valami'
u'\xc1rv\xedzt\u0171r\u0151 t\xfck\xf6rf\xfar\xf3g\xe9p\nvalami'>>> content = u'árvíztűrő tükörfúrógép'
>>> with open('unifile2.txt', 'w') as f:
... f.write(content.encode('utf-8'))
...
open(), write, encode
$ file unifile2.txt
unifile2.txt: UTF-8 Unicode text, with no line terminators
>>> import io
>>> with io.open('unifile.txt', encoding='utf-8') as f:
... content = f.read()
>>> type(content)
<type 'unicode'>
>>> content
u'\xc1rv\xedzt\u0171r\u0151 t\xfck\xf6rf\xfar\xf3g\xe9p'
io.open()
- encoding csak text mode-ban ('t')
- ha nincs megadva, platform függő
import io
>>> content = u'árvíztűrő tükörfúrógép'
>>> with io.open('unifile3.txt', 'w') as f:
... f.write(content)
...
22L
>>>io.open(), write
$ file unifile3.txt
unifile3.txt: UTF-8 Unicode text, with no line terminators
String kezelés
ATS5-ben
Általános stratégia
Kódon belül minden str,
I/O határokon alakítjuk át
class LoginWindow(skinDialog, mixRaise):
...
def _BtnLogin(self, event=None, md5=None):
...
login = DB_LOGIN_GetByLogin(asc(self.txName.GetValue()))példa:
ATS5 példa 2.
from Lib import Util as uti
def checkTicket():
currentZone = dzon.DB_ZONES_GetByID(sheep['zone_id'])
...
return {
'sheepID': sheep['id'] if sheep['id'] else None,
'currentZoneID': currentZone['id'] if currentZone['id'] else None,
'currentZoneName': uti.uc(currentZone['name']) if currentZone['id'] else None,
'ticketName': uti.uc(created['partname']) if created else None,
'expirationDateTime': expirationDateTime if created else None,
'personalID': personal['id'] if personal else None,
'personalName': uti.uc(personal['name']) if personal else None,
'personalPhotoURL': photoUrl if photo else None
}wx, unicode
>>> import wx
>>> 'unicode' in wx.PlatformInfo
True
-
wx függvények és metódusok --> return unicode
-
wx függvényhívás str-el: először unicode-ra konvertálódik az alapértelmezett encoding-al
-
ha unicode-al hívunk wx függvényt, nincs konvertálás
kétféle build, mi unicode build-ot használjuk:
Pub.Encoding
def PublicsPreload( ... ):
...
Pub.Encoding = Pub.Ini.get('Language', 'Encoding')
...
wx.SetDefaultPyEncoding(Pub.Encoding)[Language]
Encoding = iso-8859-2
LangId0 = HU
LangName0 = Magyar
LangId1 = EN
LangName1 = English
Common/PubInit.py
ats.ini
Lib.Util.asc()
def asc(txt="", nonevalue="None", encoding=None):
if not encoding:
encoding = Pub.Encoding
if txt is None:
return nonevalue
elif type(txt) is unicode:
txt = txt.replace(unichr(0x20ac), unichr(127)) # euro sign handling
return txt.encode(encoding, errors='replace')
elif type(txt) is str:
return txt
else:
return str(txt)"bármi" --> str
Lib.Util.uc()
def uc(txt="", nonevalue=u"None", encoding=None):
if not encoding:
encoding = Pub.Encoding
if txt is None:
return nonevalue
elif type(txt) is str:
txt = unicode(txt, encoding)
txt = txt.replace(unichr(127), unichr(0x20ac)) # euro sign handling
return txt
elif type(txt) is unicode:
return txt
else:
txt = unicode(str(txt), encoding )
txt = txt.replace(unichr(127), unichr(0x20ac)) # euro sign handling
return txt"bármi" --> unicode
nyelvi (dict) fileok
>>> Pub.DictConfig = ReadDict("ConfigMain" , Pub.Langcodes[Pub.Lang] , Pub.DictPath)
>>> Pub.DictConfig[28]
'Szerz\xf5d\xe9sek kezel\xe9se'
>>> uc(Pub.DictConfig[28])
u'Szerz\u0151d\xe9sek kezel\xe9se'
>>> Pub.DictConfig[28].decode(Pub.Encoding)
u'Szerz\u0151d\xe9sek kezel\xe9se'Adatbázis lekérdezések
>> anteus = DB_PERSONAL_GetByID(1)
>> type(anteus['name'])
str
>>> anteus['name']
'Anteus Kft. - Telep\xedt\xf5'
>>> anteus['name'].decode('utf-8')
Traceback (most recent call last):
File "/usr/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 3066, in run_code exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-6-e5b28db2d71b>", line 1, in <module> anteus['name'].decode('utf-8')
File "/usr/lib64/python2.7/encodings/utf_8.py", line 16, in decode return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xed in position 19: invalid continuation byteIn[7]: anteus['name'].decode('iso-8859-2')
>>> anteus['name'].decode(Pub.Encoding)
u'Anteus Kft. - Telep\xedt\u0151'
>>>Line endings
| stílus | rövid név | karakterek | ASCII dec |
|---|---|---|---|
| UNIX | LF | \n | 10 |
| DOS / Windows | CRLF | \r\n | 13, 10 |
| régi OS X (nem használt) |
CR | \r | 13 |
Editor beállítás

Problémák
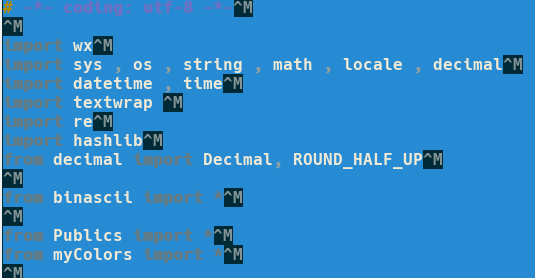
SVN panaszkodik "whitespace errors"-ra
Ha keverjük, diff-ekben elveszik a valós tartalom
Megoldás:
Mindenütt kizárólag Unix stílusú
(LF, '\n') használata!
Filevége kezelés Pythonban
>>> with open('src/bin/Lib/Publics.py') as f:
... content = f.read()
...
>>> content[:48]
'from DB_Util import *\r\nfrom ExitCodes import *\r\n'
>>> with open('src/bin/ATS_Mobile.py') as f:
... content = f.read()
...
>>> content[:46]
'#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n'Universal newlines
open() 'U' mode kapcsoló:
>>> with open('src/bin/Lib/Publics.py', 'U') as f:
... content = f.read()
...
>>> content[:48]
'from DB_Util import *\nfrom ExitCodes import *\nfr'
str.splitlines()
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
(universal newlines approach)
További
olvasnivalók
Ned Batchelder
talk
Wikipedia
Joel Spolsky
blog post
Python2 dokumentáció
Armin Ronacher
blog posts
Unicode, encoding, Python2
By Kiss György



