Implementing
IIIF By The Numbers
Kevin S. Clarke Anthony Vuong
Digital Library Software Developer Development Support Engineer
<ksclarke@library.ucla.edu> <avuong@library.ucla.edu>
A Tale of Two Architectures
Sinai Palimpsests Project
- Uses a "Level 0" IIIF compatible tile server
Californica/Ursus (Hyrax/Blacklight)
- Cantaloupe "Level 2" IIIF compatible image server
Servers
Server-oriented architecture treats individual applications (or websites) as the primary consideration.
There may be multiple IIIF servers, each one selected and configured to meet the needs of its application.
Services
Service-oriented architecture provides a functionality to a variety of applications.
"IIIF as a service" means instead of maintaining multiple architectures for serving IIIF images, we build one that meets the needs of multiple applications.

How Do We Make Decisions?

A Metrics Based Approach
- Share and reuse work with and from our colleague
- Talked with The Getty (also doing IIIF measurements)
- Build / use tools that can help test multiple factors
- docker-cantaloupe works locally or in the cloud
- Used `time`, Locust, CloudWatch, and AWS CLI tools
Image Conversion
Image Delivery
Vertical vs. Horizontal Scaling
Local VM
8 Cores E5-2630 v3 @ 2.40GHz
8 GB memory DDR4 2133MHZ
Compiled version of Kakadu
AWS Lambda
2 Core Lambda function
1024 MB memory
Compiled version of Kakadu
Image Conversion
Our Local Process
- Run script for TIFF to JP2 conversion
- Read TIFFs off our NetApp file system
- Have Kakadu convert them into JP2s
- Upload the JP2s to Cantaloupe's S3 source bucket
- Time how long it takes to process 1000 images
Our Lambda Process
- Upload TIFFs into an S3 bucket from NetApp file system
- Lambda function is triggered by the bucket event
- Kakadu in Lambda function converts TIFF into JP2
- Lambda function stores JP2 in Cantaloupe's S3 bucket
- Get time it took to process 1000 images from Cloudwatch






Some Questions
- What happens when we give our local VM 16 cores? 32?
- How far can we vertically scale using local resources?
- How large of an image can we convert on AWS Lambda?
- Its file system is (currently) limited to 512 MB
- Its memory is (currently) limited to 3008 MB
Local VMWare
AWS Fargate
(simple)
Image Delivery
AWS Fargate
(scaled)
VMWare
- 2 VMs
- 1 Docker container runner in each VM
- Specs of container
- 8GB Memory
- 6 Cores
- Total = 16GB Memory / 12 CPU cores
- Cantaloupe 4.1.1
AWS Fargate
- 3 Fargate Containers
- Specs of container
- 8GB Memory
- 4 Cores(Fargate max)
- Total = 24GB Memory / 12 CPU cores
- Cantaloupe 4.1.1
AWS Fargate(Scaled)
- 10 Fargate Containers
- 8GB / 4CPU each container
- Aggregate specs
- 80GB Memory
- 40 CPUs
- Cantaloupe 4.1.1
Delivery Test Case #1
- Single Image Fixed Test
- Large Image(110-130MB)
- Medium Image(50-60MB)
- PCT:50 / Full Image Request
- IIIF URI used
- /full/pct:50/0/default.jpg?cache=false
- /full/full/0/default.jpg?cache=false
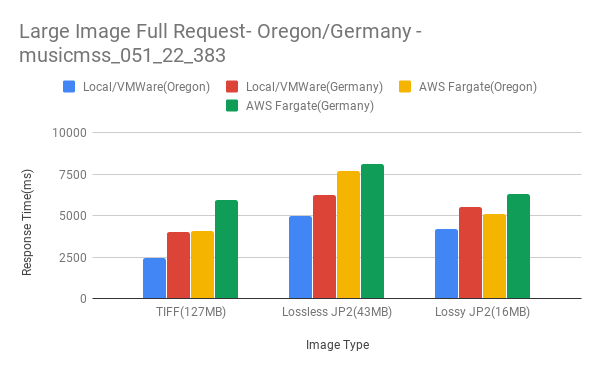
Large Full Image Results

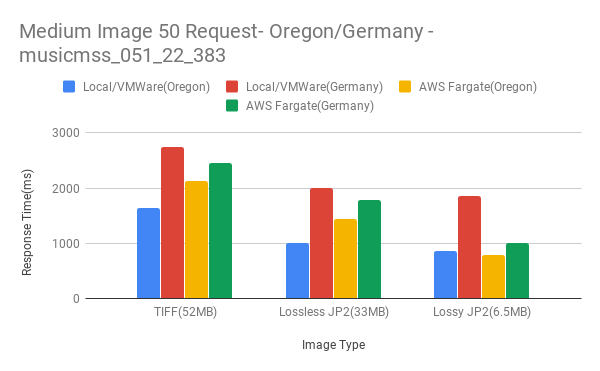
Medium Full Image Results

Large Image Results (50%)

Medium Image Results (50%)

Large Full Multi-Region
Large 50% Multi-Region

Medium Full Multi-Region

Medium 50% Multi-Region
Delivery Test Case #2
- Simulated workload with concurrent users
- Various regions/tiles of an image
- Large Image(110-130MB)
- Medium Image(50-60MB)
- 20, 50, 100, 200 concurrent users
- 5-15 seconds wait per user request
- 1000+ URLs, picked at random
- Locust load test left on for 5 minutes
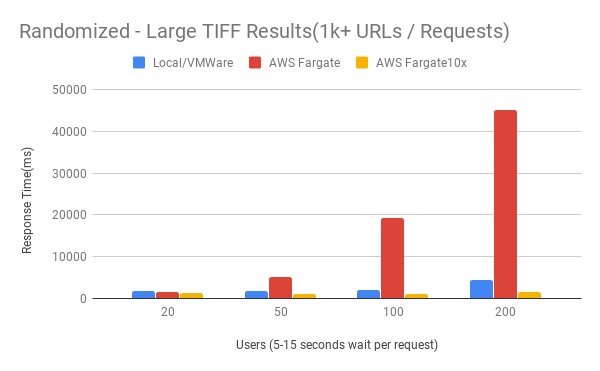
Random - Large TIFF Results
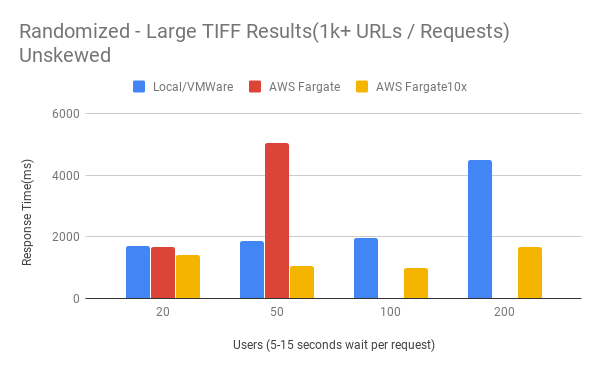
Random Large TIFF Unskewed Results
Random - Large Lossless Results

Random Large Lossless Unskewed Results

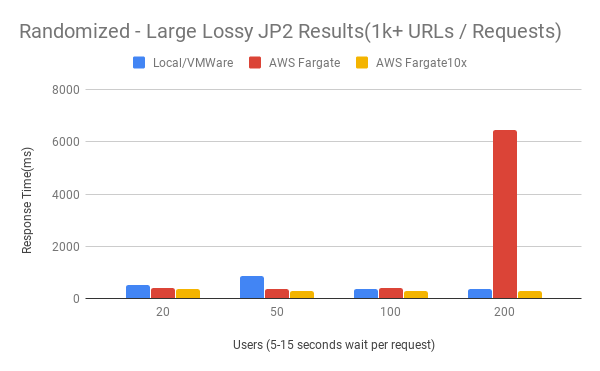
Random - Large Lossy Results
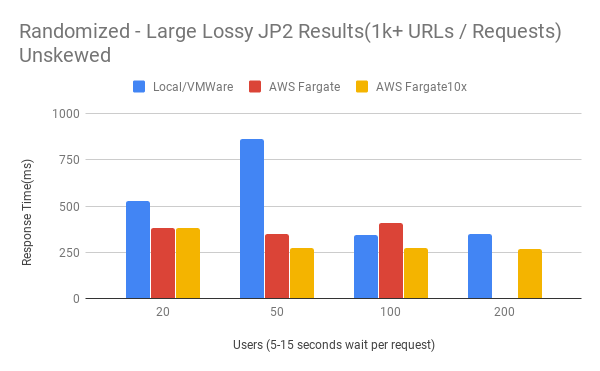
Random Large Lossy Unskewed Results
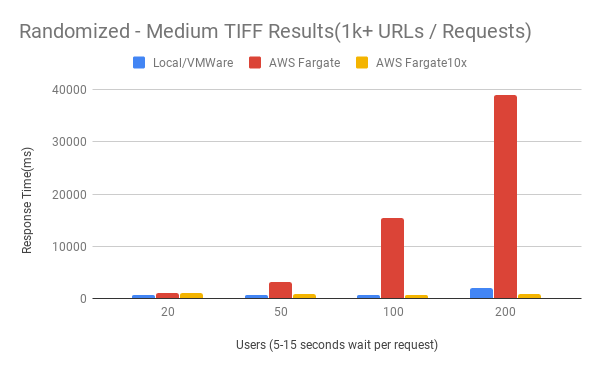
Random - Medium TIFF Results
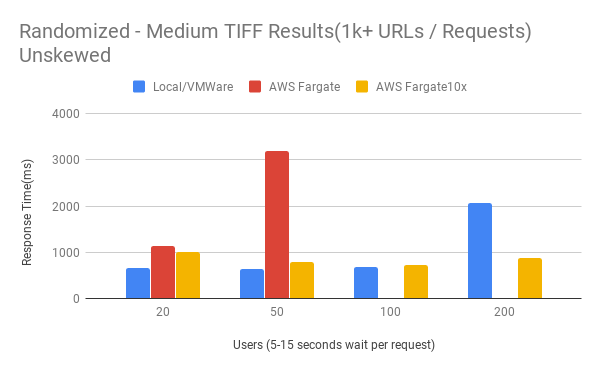
Random Medium TIFF Unskewed Results
Random - Medium Lossless Results

Random Medium Lossless Unskewed Results

Random - Medium Lossy Results
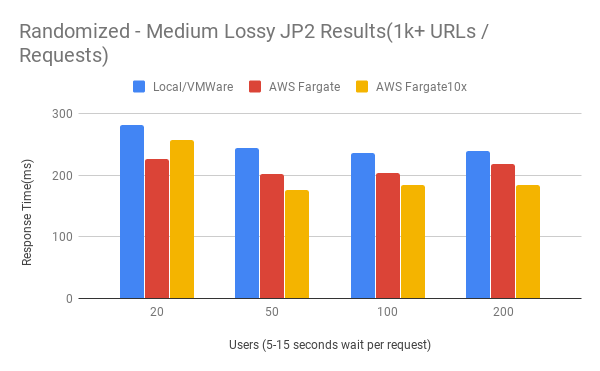
Discoveries
- Generating JPEG derivatives from full TIFF requests are faster than using Kakadu's Native Processor for Lossless and Lossy images
- S3 GET speeds appear to be limited to gigabit at the most. Averages from 30-50MB/s vs 400MB/s on local netapp storage
- Makes a huge difference on larger images, not so much smaller images.
- Wait times could cause image downloads to be stacked and bog down container resources
- Current assumption is that network bandwidth is the bottleneck rather than compute
- Scaling out the Fargate containers allows for more parallel requests to be executed and balance the load across multiple resources
What do we do now?
- Decide on Lossy, Lossless, or TIFF as sources
- Decide on using on-premise hardware or AWS
- For full image pixel requests, latency becomes an issue. Delivery times can vary between on-premise vs AWS
- Do we want to serve full image pixels?
- Launch and experiment with a production service
- Gather real work-load use cases
- Experiment reducing latency from other countries using AWS CloudFront
- Make containers more "production" ready
- More detailed monitoring needed!
- Automate all the things!
UCLA Library
Kevin S. Clarke Anthony Vuong
Digital Library Software Developer Development Support Engineer
<ksclarke@library.ucla.edu> <avuong@library.ucla.edu>
IIIF By The Numbers
By Kevin S. Clarke


