



Kyoung Rok Jang
Studying Web Science
Samuel Brody and Mirella Lapata
EACL '09
Presenter: Kyoungrok Jang
| Sense induction | WSD | |
|---|---|---|
| Assumption | We don't know all the possible senses of a word | All the possible senses are known beforehand |
| Goal | Discover all the possible senses | Identify the intended sense of a word in context |
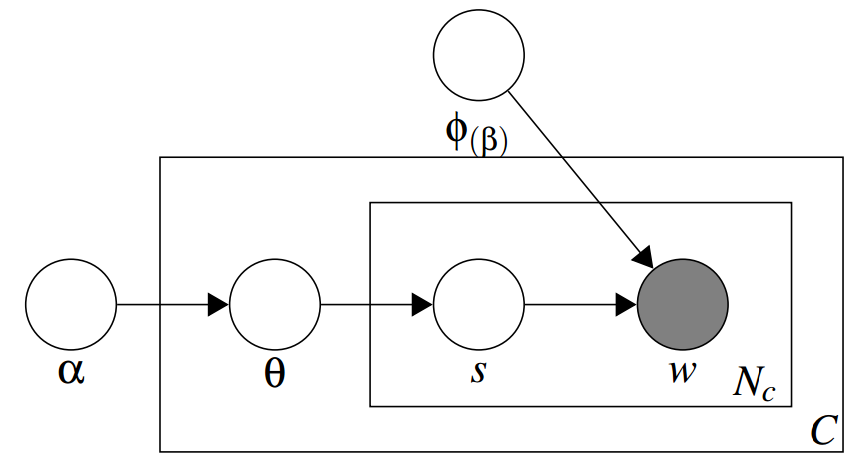
Each word in the context window is generated by:
prob. of word
prob. of word
prob. of sense
given
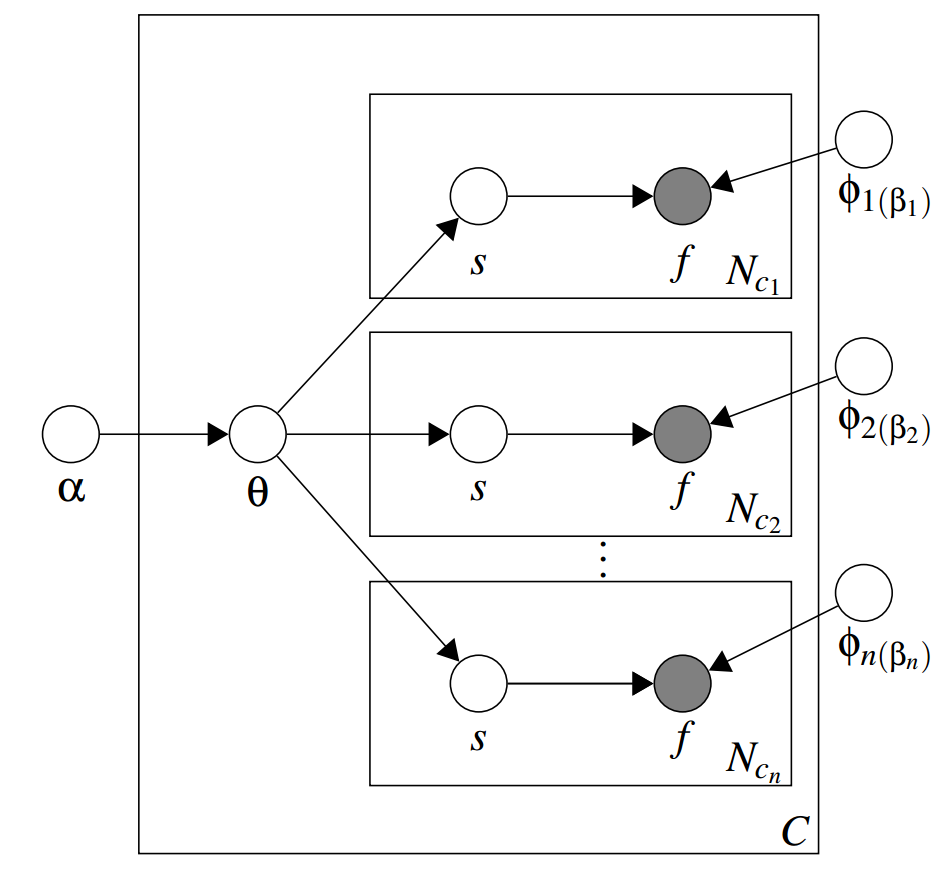
Word
POS
Dep.
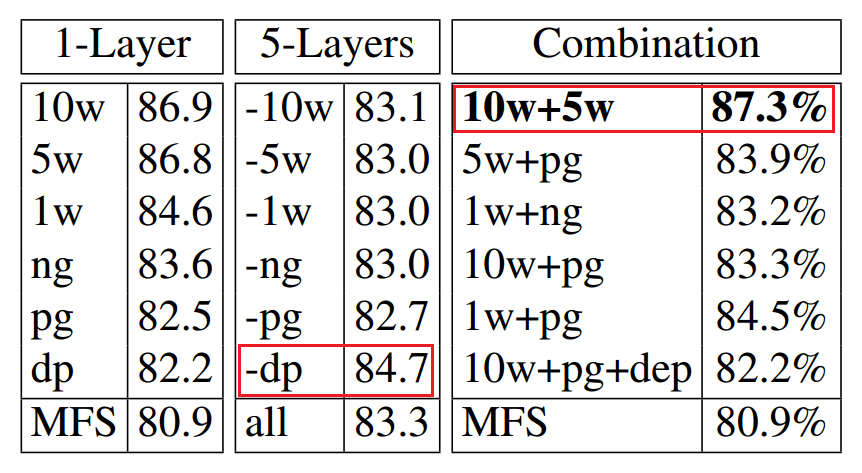
For each layer:
** Lemmatized words are used
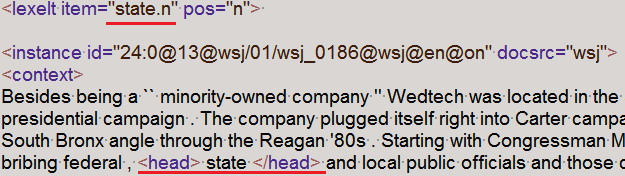
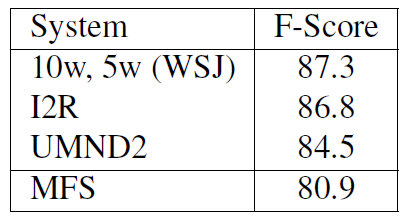
Semeval-2007 Task 02: Evaluating Word Sense Induction and Discrimination Systems
By Kyoung Rok Jang
