N-gram簡介及應用
Lecturer:Lamuyag
Date:Oct. 18th, 2020
OUTLINE
-
什麼是N-Gram
-
二、三元模型公式
-
實際使用
-
lab
-
參考資料
什麼是N-Gram
每一個字節片段=gram
假設第N個詞出現只與前面N-1個詞相關
常用
Bi-Gram、Tri-Gram
二元模型、三元模型

二元模型公式
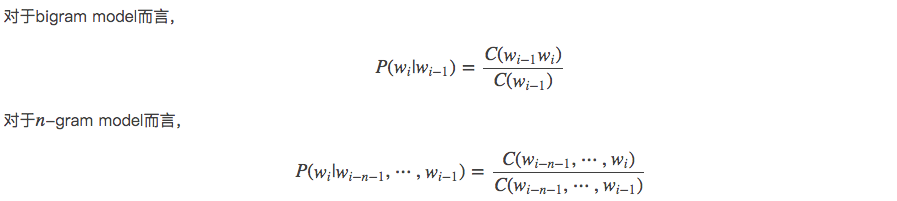
實際例子




基於語料庫判斷合理性
s1 = "<s> I want English food </s>"
s2 = "<s> want I English food</s>"
基於語料庫判斷合理性
P(s1)=
P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
基於語料庫判斷合理性
P(s1)=0.000031
P(s2)=0.00000002057
P(s1)>P(s2)
實作
from collections import Counter, namedtuple
import json
import re
DATASET_DIR = './WebNews.json'
with open(DATASET_DIR, encoding = 'utf8') as f:
dataset = json.load(f)
# 除了繁體中文字以外的字
seg_list = list(map(lambda d: d['detailcontent'], dataset))
rule = re.compile(r"[^\u4e00-\u9fa5]")
seg_list = [rule.sub('', seg) for seg in seg_list]
# 利用 set,將重複的字與機率去除,例如計算出兩次在「桃園」後出現「縣」的機率都是 1,只保留一組。
def ngram(documents, N=2):
ngram_prediction = dict()
total_grams = list()
words = list()
Word = namedtuple('Word', ['word', 'prob'])
for doc in documents:
split_words = ['<s>'] + list(doc) + ['</s>']
# 計算分子
[total_grams.append(tuple(split_words[i:i+N])) for i in range(len(split_words)-N+1)]
# 計算分母
[words.append(tuple(split_words[i:i+N-1])) for i in range(len(split_words)-N+2)]
total_word_counter = Counter(total_grams)
word_counter = Counter(words)
for key in total_word_counter:
word = ''.join(key[:N-1])
if word not in ngram_prediction:
ngram_prediction.update({word: set()})
next_word_prob = total_word_counter[key]/word_counter[key[:N-1]]
w = Word(key[-1], '{:.3g}'.format(next_word_prob))
ngram_prediction[word].add(w)
return ngram_prediction
# 使用trigram,也就是計算接在兩個字之後第三個字的機率。對結果進行排序,因此在預測下一個字時,能夠直接取得前幾個最高機率的字。
tri_prediction = ngram(seg_list, N=3)
for word, ng in tri_prediction.items():
tri_prediction[word] = sorted(ng, key=lambda x: x.prob, reverse=True)
# 預測輸入的下一個字
text = '桃園'
next_words = list(tri_prediction[text])[:5]
for next_word in next_words:
print('next word: {}, probability: {}'.format(next_word.word, next_word.prob))參考資料
N-gram簡介及應用
By Lamuyang



