Akka
Cluster

A hands-on introduction
About me
- ~4 years working with Scala
- Previous Java background
- /lregnier
- /whiteprompt
Leonardo Regnier
Today's goal
"Learn to love Akka"

What is Akka Cluster?
Akka Cluster is all about membership
Akka Cluster provides a fault-tolerant decentralized peer-to-peer based cluster membership service with no single point of failure or single point of bottleneck.
An Akka Cluster overview
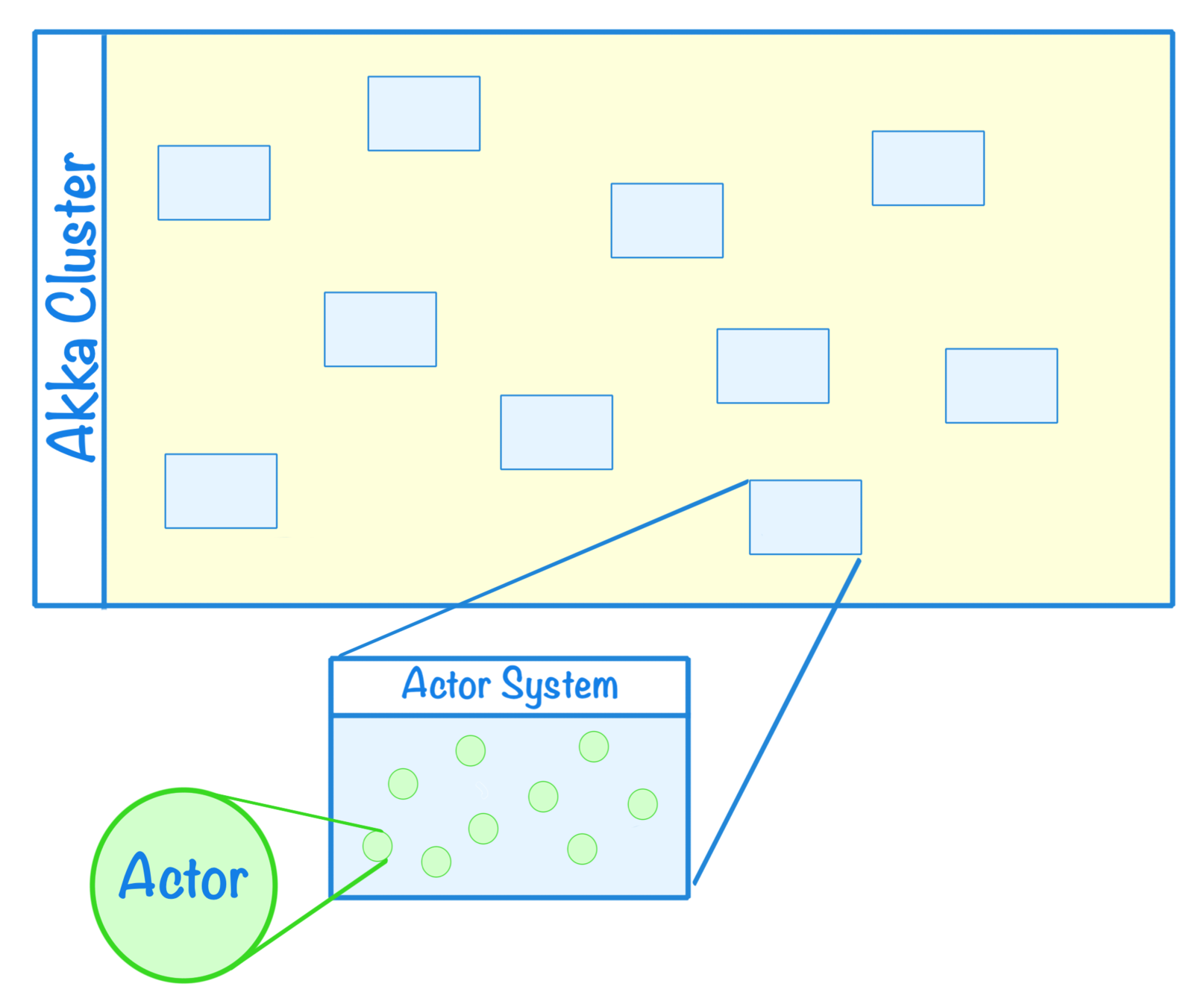
A cluster is a group of nodes, each running an actor system.
Clustering vs Remoting?
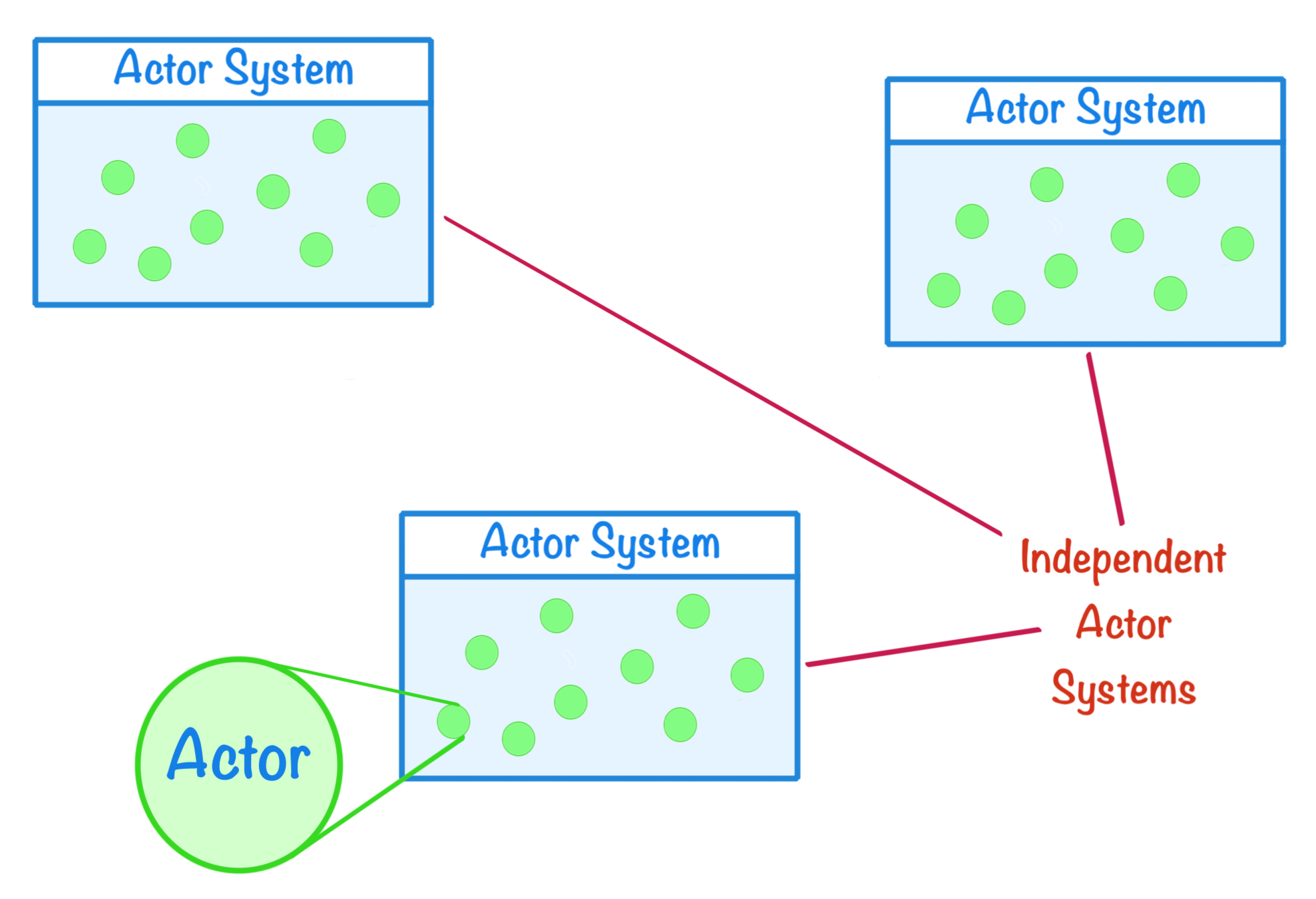
Each actor system runs independently of other remote instances
So, what can go inside a node?
- Cluster membership and the actors running on that node of the application are decoupled.
- The only requirement for a node to join a Cluster is to share the same ActorSystem name.
- An Akka application can be distributed over a cluster with each node hosting some part of the application.

EASY, RIGHT?
How does it work?
Akka Cluster provides Membership and Fault-tolerance automatically
How does it work?
Membership
- Cluster membership is communicated using a Gossip Protocol, where the current state of the cluster is gossiped randomly through all cluster members.
- After gossip convergence a leader for the cluster can be determined. The role of the leader is to shift members in and out of the cluster.
How does it work?
Fault-tolerance
- The failure detector is responsible for trying to detect if a node is unreachable from the rest of the cluster. It uses an implementation of The Phi Accrual Failure Detector for doing so.
- The failure detector will also detect if the node becomes reachable again. When all nodes that monitored the unreachable node detects it as reachable again the cluster, after gossip dissemination, will consider it as reachable.

What should I do?
Cluster doesn’t support a zero-configuration discovery protocol. A list of seed nodes must be specified so that nodes can join the cluster.
Provide seed nodes:
- Use a list of known pure seed nodes with well-known IP addresses or DNS names.
- Use existing service discovery/registry technology like Apache ZooKeeper, HashiCorp Consul, or CoreOs/etcd and add some “glue.”
What should I do?
Failure detection using simple heartbeats is not good enough for production. Network partitions (or split brain scenarios) may occur. Do not use auto-down for production.
Provide a way to resolve network partitions:
- Plug in Akka Split Brain Resolver (commercial)
- Roll your own implementation, all required APIs are public
- Perform manual downing if using some external monitoring service

Going Reactive with Akka Cluster:
Reactive Tickets
https://github.com/lregnier/reactive-tickets
Domain Objects
case class Event(id: String, name: String, description: String)
case class Ticket(id: String)Event:
Create Event: POST /events
Get Event: GET /events/{eventId}
Remove Event: DELETE /events/{eventId}
List Events: GET /events
Event Tickets:
List Tickets: GET /events/{eventId}/tickets
Buy a Ticket: POST /events/{eventId}/tickets/purchase
API Reference
Reactive Tickets
EventHttp
Endpoint
Event
Manager
Event
Repository
TicketSeller
Supervisor
Ticket
Seller(1)
Ticket
Seller(2)
Ticket
Seller(n)
Rest API
Services
Persistence
Reactive Tickets


Reactive Manifesto
Message Driven:
Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency.
Responsive:
Responsive systems focus on providing rapid and consistent response times, establishing reliable upper bounds so they deliver a consistent quality of service.
Elastic:
The system stays responsive under varying workload. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them.
Resilient:
The system stays responsive in the face of failure.
Reactive Checklist
Message Driven:
An asynchronous message-passing stack is being used among the different system layers: Akka-Http, Akka, Reactive Mongo.
Responsive:
Under varying workload the system might not be able to provide rapid and consistent response times.
Elastic:
We need to be able to increase and decrease resources horizontally in order to be elastic.
Resilient:
In the face of failure the system does not stay responsive since we have only one instance.
We need to scale out!

Akka Cluster to the rescue!
A few words on Cluster Singleton
-
It allows you to have exactly one actor of a certain type running somewhere in the cluster.
-
A ClusterSingletonManager actor should be started on all nodes (or all nodes with specified role). It will create the actual singleton actor on the oldest node.
- The singleton actor can be accessed from any node by using a provided ClusterSingletonProxy.
Reactive Checklist
Message Driven:
An asynchronous message-passing stack is being used among the different system layers: Akka-Http, Akka, Reactive Mongo.
Responsive:
System can scale out and potentially provide rapid and consistent response times.
Elastic:
TicketSellerSupervisor singleton represents a bottleneck as it allocates all TicketSellers in one single node and does not distribute them evenly across the Cluster.
Resilient:
TicketSellerSupervisor singleton represents a single point of failure too. In case the node containing the TicketSellerSupervisor and the TicketSellers fails, their state is lost.

A few words on Cluster Sharding
-
It takes care of automatically distributing actors (with an identifier, so called entities) across multiple nodes in the cluster.
-
Each entity actor runs only at one place, and messages can be sent to the entity without requiring the sender to know the location of the destination actor.
- This is achieved by sending the messages via a provided ShardRegion actor, which knows how to route the message with the entity id to the final destination through implementing extractEntityId and extractShardId functions.
Reactive Checklist
Message Driven:
An asynchronous message-passing stack is being used among the different system layers: Akka-Http, Akka, Reactive Mongo.
Responsive:
System can scale out and potentially provide rapid and consistent response times.
Elastic:
All TicketSellers are distributed evenly across the Cluster.
Resilient:
In case any node containing a TicketSeller fails, its state is lost.

A few words on Akka Persistence
-
It enables stateful actors to persist their internal state so that it can be recovered when an actor is started, restarted after a JVM crash or by a supervisor, or migrated in a cluster.
-
Based on EventSourcing: only changes to an actor’s internal state are persisted but never its current state directly (except for optional snapshots). Stateful actors are recovered by replaying stored changes to these actors from which they can rebuild internal state.
- Storage backends plugins available for journals and snapshots: Cassandra, Redis, MongoDB, ...
Reactive Checklist
Message Driven:
An asynchronous message-passing stack is being used among the different system layers: Akka-Http, Akka, Reactive Mongo.
Responsive:
System can scale out and provide rapid and consistent response times.
Elastic:
All TicketSellers are distributed evenly accros the Cluster.
Resilient:
In case any node containing a TicketSeller fails, the TicketSeller gets restarted in some other node holding its original state.
REACTIVE
AT LAST!

Conclusions
-
Akka provides by design the necessary tools for building real reactive systems.
- An Akka Cluster is the foundation on top of which these tools will be used.
- Understanding the purpose and motivations of the different Akka extensions, such as Cluster, is the first step.

Akka Cluster
By Leonardo Regnier



