Retrieval Augmented Generation
檢索增強生成
AI應用研究教育中心
真理大學
王柳鋐
2024/11
Last modified
2024/11/5
Outline
☞ Revolution of LLM
☞ Blooming of LLM
☞ More Than You Think, Lower Than Expected
☞ Practice using LlamaIndex & GPT
Revolution of LLM
Representation of Words
Training Paradigm

word embedding
向量長度 =詞彙數量(e.g. length: 10000)

Network Architecture

輸入層
隱藏層
輸出層
Transformer, 2017/06
Word2Vec, 2013/01
Pre-trained, 2010/10
Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8), 2554-2558.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Rumelhart, D., Hinton, G. & Williams, R. Learning representations by back-propagating errors. Nature 323, 533–536 (1986). https://doi.org/10.1038/323533a0
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), 541-551
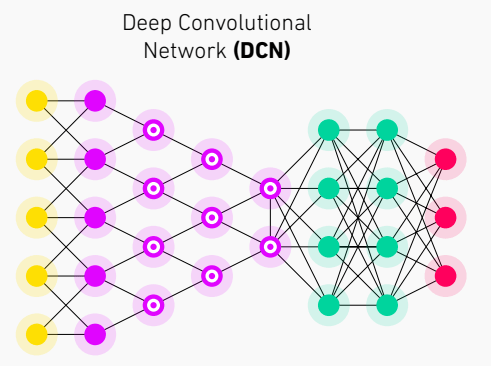
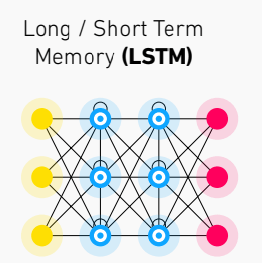
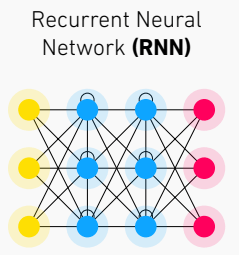
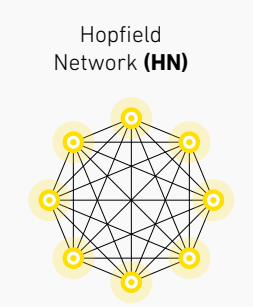
Novel Network Architecture: Transformer(1/3)
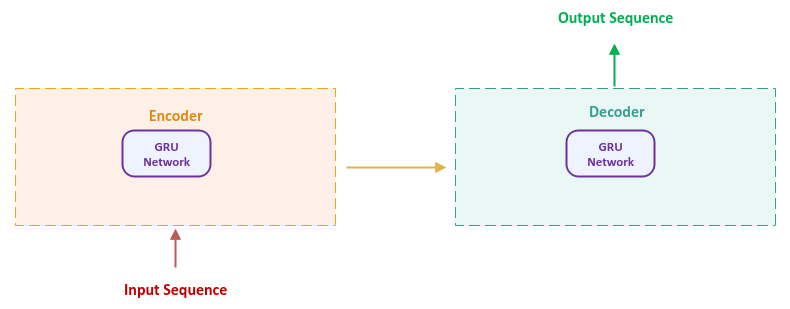
Sutskever, I., Vinyals, O., & Le, Q.V. (2014). Sequence to Sequence Learning with Neural Networks. ArXiv, abs/1409.3215.
seq2seq model, 2014/09
Encoder-Decoder Model for NLP tasks
文字型任務
編碼器
解碼器
Novel Network Architecture: Transformer(2/3)
attention, 2014/09
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. CoRR, abs/1409.0473.

seq2seq model, 2014/09
Attention: focus on specific parts of input while generating output
認知科學:選擇性注意力
Novel Network Architecture: Transformer(3/3)

Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems (p./pp. 5998--6008), .
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06

Self-Attention: input interact with each other
上下文context
Transformer-based Language Models BERT(1/5)
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics.
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
BERT, 2018/10

token
embedding
(Encoder-only)
(BERT base)
預訓練pre-training
prediction (probability)
下游任務downstream task
FNN
(微調, Fine-tuning)


dim: 768
Training Paradigm Shifting Pre-trained + fine-tuning
遷移學習:預訓練(pre-trained) + 目標領域資料集收集、訓練(fine-tune)

機器學習傳統做法
資料集1
資料集2
資料集3
任務1
任務2
任務3
兩階段: 非監督式、監督式
不同任務、不同資料集
Transfer Learning
來源領域任務
資料集S
目標領域任務
大量
資料集T
小量
預訓練unsupervised
微調supervised
Pan, S.J., & Yang, Q. (2010). A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering, 22, 1345-1359.
pre-trained, 2010
Representation of Words one-hot encoding(1/3)

One-hot encoding
1
2
3
4
5
6
7
8
編碼:以向量表示
編號
詞彙
<SOS>
編號
0 0 0 0 0 0 0 0
<SOS> I played the piano
編碼
輸入層
隱藏層
輸出層
Word Embedding(詞嵌入)
字彙語意相近,編碼必須給予比較近的「距離」

Representation of Words word embedding(2/3)
Mikolov, T., Chen, K., Corrado, G.S., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. International Conference on Learning Representations.
Word2Vec, 2013/01

Word Embedding
詞彙
維度
Word2Vec
Representation of Words word embedding: word2vec(3/3)
Word2Vec學習大量詞彙,將字詞對應到100-300維度的空間。
Transformer-based Language Models GPT-2 (2/5)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners.
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019

BERT, 2018/10
decoder-only

117M Parameters

1,542M Parameters

Transformer-based LM Pre-trained + Fine-tune (3/5)
預訓練
預訓練
預訓練
預訓練
微調
微調
微調
微調
微調
Transformer-based LM You Never Know What They Really Do (4/5)
Transform-based Model



●●●
pre-trained data sets
NN1
Task 1
NN2
Task 2
NNn
Task N
target domain data sets
●●●
●●●
●●●
LLM
Transformer-based LM What happened to embedding? (5/5)

Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024
Transformer-based LM What happened to embedding? (5/5)

Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024
Transformer-based LM What happened to embedding? (5/5)
Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024

難以捕捉更高層次的語義概念
難以進行邏輯運算和因果推理
缺乏情境理解
Blooming of LLMs




Gemini Pro 2.0
GTP-4o
Claude 3.5 Sonnet
LLaMa 3.3
Sonar Pro

Microsoft 365 Copilot
Open AI
GTP-o1 preview
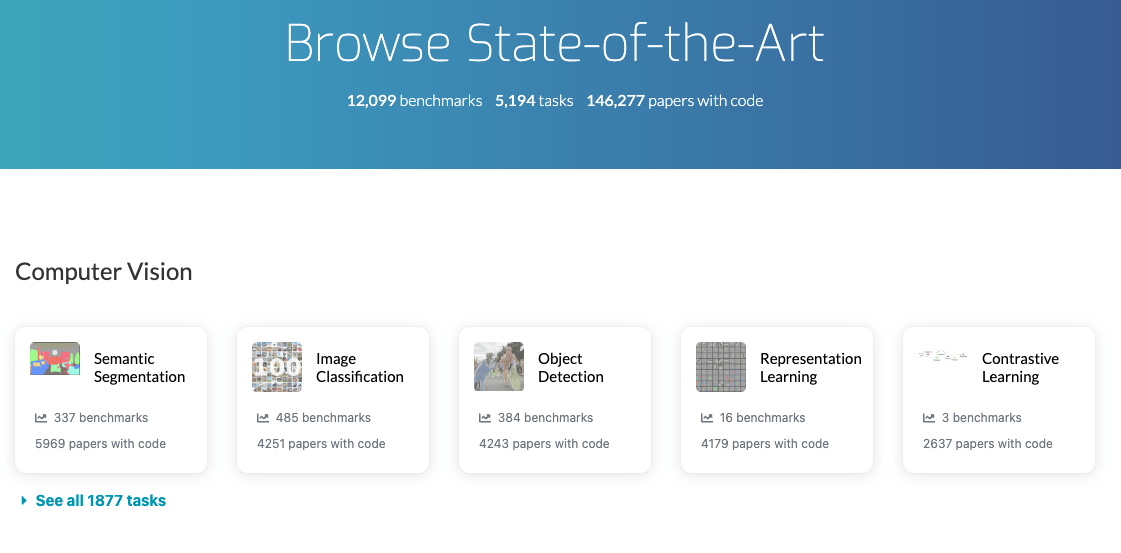
LLM comparison Browse State-of-the-Art (1/3)
LLM comparison Browse State-of-the-Art (2/3)

Sept. 8th 2024

LLM comparison price, context, pros & cons (3/3)
LLMs are More Than You Think, but also Lower Than Expected

Capabilities of Pattern Matching
Mirzadeh, I., Alizadeh-Vahid, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models.

One of the solutions: RAG
Hallucination
Prompt Engineering
Prompt Engineering Describing tasks via NL (1/3)
McCann, B., Keskar, N.S., Xiong, C., & Socher, R. (2018). The Natural Language Decathlon: Multitask Learning as Question Answering. ArXiv, abs/1806.08730.
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
A prompt is natural language text describing the task that an AI should perform.
It can be a query, specifying a style, providing relevant context, or assigning a role.

Prompt Engineering Describing tasks via NL (2/3)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Brown, T.B., Mann, B., Ryder, N., et. al. (2020). Language Models are Few-Shot Learners. ArXiv, abs/2005.14165.
Prompt Engineering, 2018/06


Meta-learning: learning in context, not real training.
Few-Shot Learner, 2020/05
Prompt Engineering Describing tasks via NL (3/3)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Few-Shot Learner, 2020/05
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E.H., Xia, F., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models. ArXiv, abs/2201.11903.
Prompt Engineering, 2018/06
Chain-of-Thought, 2022/01

Step-by-Step
Q+ \sum_{i} A_i
as Input
Retrieval Augmented Generation RAG (1/5)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
RAG, 2020/05

RAG for knowledge intensive tasks
1. parametric memory: a pre-trained seq2seq model
2. non-parametric memory: a dense vector index of Wikipedia
e.g. word embedding
RAG ReAct Reasoning and Action (2/6)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
RAG, 2020/05
ReAct, 2022/10

Chain-of-Thought
Act 1: Search [Q]
Act 2: Search [Obs 1]
Act 3: Search [Obs 2]
Act 4: Finish [answer]
context
LangChain ReAct Design Pattern: High Level Abstraction (3/6)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
RAG, 2020/05
ReAct, 2022/10


Setting, Resouces
Interactive UI for Work Flow Design
LangChain + LangSmith

LlamaIndex For Efficient Indexing & Retrieval (4/6)

LlamaIndex For Efficient Indexing & Retrieval


RAG Research Framework (5/6)
RAG possible knowledge aware applications (6/6)

Ji, S., Pan, S., Cambria, E., Marttinen, P., & Yu, P.S. (2020). A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Transactions on Neural Networks and Learning Systems, 33, 494-514.

Zou, X. (2020). A Survey on Application of Knowledge Graph. Journal of Physics: Conference Series, 1487.
Legal AI
web crawler


Context
Query
Prompt
LLM
Output

Vector DB
RAG
關懷理論

Scenario: 法律扶助
問責 合規
來源 透明
專家審查
defining an appropriate workflow
Practice RAG system from scratch
Context
Query
Prompt
LLM
Output
Vector DB
❶ Dataset
❸ Embedding
➍ Similarity
❷
➎ Reranking algorithm
➏

pip install llama-indexLlamaIndex Hello world (1/6)
1. 安裝Python套件


●●●


2. 準備知識庫
支援各種檔案格式(參考官網文件)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (2/6)

2. 準備知識庫
data資料夾:5個PDF檔

範例程式
知識庫

3. 設定OpenAI API Key (可更換別的LLM)

LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)

LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (3/6)

輸入申請之API KEY
import os
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,)
def setCurrentWD():
abspath = os.path.abspath(__file__)
dname = os.path.dirname(abspath)
os.chdir(dname)
setCurrentWD() # 設定工作目錄, 以免找不到data資料夾
# 1. Loading & Parsing
documents = SimpleDirectoryReader("data").load_data()
# 2. Indexing & vector store
index = VectorStoreIndex.from_documents(documents)
# 3. Query
query_engine = index.as_query_engine()
response = query_engine.query("Tell me about rag")
print(response)LlamaIndex Hello world (4/6)
response = query_engine.query("Tell me about rag")
LlamaIndex output (5/6)
RAG models leverage a retriever to retrieve text documents based on an input query and use them as additional context when generating a target sequence. These models have been shown to achieve state-of-the-art results on various tasks such as open Natural Questions, WebQuestions, CuratedTrec, MS-MARCO, Jeopardy question generation, and FEVER fact verification. RAG models generate responses that are more factual, specific, and diverse compared to baseline models like BART. The retrieval mechanism in RAG plays a key role in improving results across different tasks.
實際回應

出處

LlamaIndex Cost (6/6)
$0.12
<$0.01
Embedding (indexes) 可以只算一次
Embedding預訓練是不是MultiLingual?效果差很多!
Hands on...
RAG
By Leuo-Hong Wang




