NoSQL and MSA
Нереляционные базы данных и
как с этим жить опыт их использования на реальном проекте
2017, Кенжаев А.З.
Введение.
Что такое "нереляционные базы даных"?
В чем отличие от реляционных?
Где их можно использовать и для чего?

Не SQL на примере


Text
NoSQL(non SQL || non relational || not only SQL)

- термин приобрел популярность в 2009 (хэштег в твиттере #nosql)
- в некоторых NoSQL базах данных используется SQL-like DML 😱
- это не серебряная пуля; каждому инструменту свои задачи
Предпосылки
- Много данных. Очень.
- Удобство schemaless структур
- Новые требования к производительности, отказоустойчивости, масштабируемости и нагрузкам etc.
- Популяризация таких архитектур приложений, как сервис-ориентированная, микросервисная и событийно-ориентированная
SQL. В чем проблема?
- Вопросы к производительности
- Боль репликации и шардинга
- Проблемы с масштабируемостью
- RDBMS зачастую представляет комбайн, который для некоторых задач является оверхедом
- Сложность реализации определенных структур данных
- Деплой, администрирование
- Open source
SQLлючения из правил
PostgreSQL.
Репликации и шардинг (хотя все равно все не слишком здорово), JSONB, крутая типизация, программы на стороне сервера и много чего еще
Clickhouse 🚀🚀🚀 (Yandex)
Столбцовая СУБД, крутое сжатие данных, обработка запроса параллельна на ядрах и распределена по серверам, хранение триллионов строк, обработка сотен миллионов строк в секунду и тд
Применение NoSQL
Key-value хранилище
Для чего:
- кэш
- некоторый data-sharing между сервисами
- использование соответствующей структуры данных (например, id/расположение документов, изображений)
Примеры: Berkeley DB, MemcacheDB, Redis, Riak, Amazon Dynamo, Tarantool
Применение NoSQL
BigTable-like хранилище
Для чего:
- большие данные
- распределенные базы данных
- масштабируемость
- сверхвысокая производительность
Примеры: Hadoop, Hypertable и Cassandra
Применение NoSQL
Документо-ориентированная СУБД
Для чего:
- гибкая иерархическая структура данных
- необходимость репликации и шардинга
- производительность
Примеры: CouchDB, MongoDB
Применение NoSQL
На основе графов
Для чего:
- сложные связанные структуры данных, графы
- например, для социальных сетей
Примеры: Neo4j, OrientDB
Применение NoSQL
А еще
- Service Bus (Шина сервиса), очереди, события
- Secondary Storage (Дополнительное хранилище)
- Горячие данные
- Логи, счетчики, метрики, журналы
- и многое другое
Опыт использования NoSQL решений на реальном проекте с микросервисной архитектурой (MSA)

- > 15 000 RPS IO each
- Десятки миллионов активных задач
-
Гарантированность выполнения
-
Отказоустойчивость
-
Масштабируемость горизонтально
-
Модульность
- Высокая производительность
- 3 x 4 CPU 1 GB RAM
Архитектура
Задача
Необходимо разработать сервис-планировщик (Scheduler), который умеет хранить и выполнять задачи (таски) по заданному для каждой периоду времени, а также, соответственно, отдавать информацию таске, о статусе ее выполнения и уметь делать с информацией о задачах всякие штуки
- Время - CRON-like выражение с поддержкой секунд
- Например, */10 - каждые 10 секунд
- Суть тасков - отправка HTTP-запросов
- Нужен REST-API интерфейс для работы с тасками
export default {
taskSchema: {
_id: String,
request: Object,
schedule: String,
status: String,
createdAt: { type: Date, default: Date.now },
updatedAt: { type: Date, default: Date.now },
},
};
/**
* Index of available task statuses
* @type {Object}
*/
export default {
running: 'running',
stopped: 'stopped',
done: 'done',
deleted: 'deleted',
outdated: 'outdated',
};
Схема:
ENUM статусов задачи:
Легко!
- Автоматически дописываем задачу в crontab с нужным временем и запросом
- cron будет сам дергать какой-то наш скрипт с указанными параметрами, а скрипт будет отправлять запрос на камеру

0 5 * * * node ~/script.js -request {"method": "GET", url: "http://google.com"}
Но есть проблемы
- Гарантированность выполнения
-
Отказоустойчивость
-
Масштабируемость горизонтально
-
Высокая производительность
Сервис обслуживает десятки (а в будущем сотни) тысяч камер, на которые отправляет запросы.
Возможные варианты:
- Переписать на
Найти блокеры и bottlenecks и устранить
Database
- Для задач нужно persistent хранилище с удобным доступом
- Это хранилище должно быть быстрым
- Нужны репликация и шардирование
- В текущей схеме в общем-то нет реляций, нам нужна лишь коллекция задач
- Запрос может быть разный, в зависимости от интерфейсов того, кто создает задачу, отправляет непосредственно запрос и т.д., то есть нам бы очень хотелось schemaless
- У нас нет особых требований по аналитике - в основном это поиск и фильтрация по статусам/датам
Database
Исходя из указанных предпосылок, вполне можно выбрать:
- Репликация и шардирование из коробки
- Достаточно высокая скорость вставки и выборки
- Нормально справляется с миллионами документов
- Схема коллекции может быть очень гибкой
- Агрегирование данных
- MapReduce
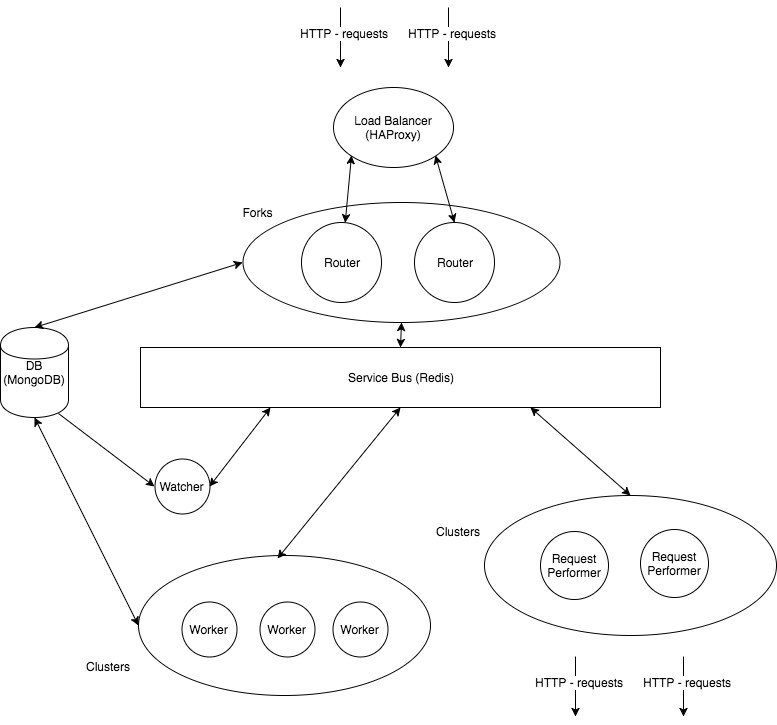
Services
2. Мы должны гарантировать выполнение задач, и иметь возможность горизонтально масштабироваться
Наше приложение можно разбить на следующие сервисы:
- Relay Service. Предоставляет REST-API (endpoint) для работы с нашим сервисом.
- Scheduler Service. Отвечает за непосредственно планирование выполнения задач.
- Request Performer. Умеет отправлять HTTP-запросы
- Watcher. Следит за тем, чтобы все задачи действительно выполнялись.
Services
Сервисная шина спешит на помощь.
- Все сервисы общаются только через нее. Это дает нам независимость сервисов друг от друга
- У каждого сервиса есть свой канал. Если мы хотим что-то сказать сервису, то нам достаточно "послать сообщение" в этот канал.
- Каждый сервис предоставляет из себя кластер из воркеров. Это дает
-
горизонтальную масштабируемость - расширяем кластер, добавляем новый воркер
-
отказоустойчивость. если кто-то упал, остальные продолжают работать и забирать сообщения
-
производительность. кто-то сильно занят - работу сделают другие
Service Bus
В свою очередь, шина должна быть
- Персистентной
- С высокой пропускной способностью
- Поддерживать Pub/Sub, MQ
- Быть весьма быстрой
- Уметь масштабироваться
По сути, шина становится самой критичной точкой отказа и "боттлнеком" сервиса (не считая БД).
И очень бы хотелось спокойно спать по ночам :)
Service Bus
В качестве шины будем использовать еще одно NoSQL решение:
- Умеет Pub/Sub
- Пропускная способность инстанса - 80 000 rps
- Может быть персистентным
- В качестве MQ будем использовать List (lpush/brpop), он же и выступит в качестве балансировщика нагрузки
- Есть redis-cluster (хотя пока еще не очень)
- Есть время жизни ключей (TTL)
- И умеет еще очень много чего полезного :)
const waitForNewTask = () => redis
.brpop([redisChannel.newTasks, workerId], 0)
.then(([, message]) => {
handleTask(message);
waitForNewTask();
});
Ожидание задач от шины
export function send(command) {
if (getConnectionsTotal() < connectionsLimit) {
sendRequest(command);
} else {
redisPusher.lpush(
redisChannel.workerRequests,
JSON.stringify(command)
);
}
}Отправка события в шину
Что же в итоге вышло?

Итоги
- Выбирать инструменты нужно исходя из задач и проблем
- NoSQL решения также могут себя проявить в совершенно неожиданных ролях, казалось бы, не слишком связанными непосредственно с базами данных (спасибо термину за это)
- Есть некоторые клевые архитектурные паттерны, которые здорово покрывают класс задач, связанных с микросервисами, масштабируемостью и т.д., но надо помнить про п.1
- А еще наш пилотный запуск (перевод парка из 20 тысяч камер в исходное положение в 24:00) произошел как-то так:

Спасибо за внимание!
NoSQL and MSA
By Artur Kenzhaev

