資料庫的 Transaction
微起個頭
先看一下基本操作
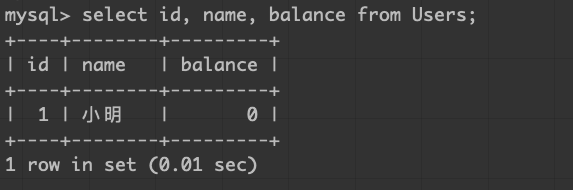

從資料庫拿資料
更新資料庫的資料
Transaction 是什麼

把幾個 query 合起來作為一個單位
---> 一個 transaction
Transaction 是什麼
例如甲轉帳 100 元給乙
begin
read(A)
A = A - 100
write(A)
read(B)
B = B + 100
write(B)
commit
T1
Transaction 是什麼
例如更新用戶資料
begin
write(A)
write(B)
write(C)
...
commit
T1
Transaction 的特性
Atomicity (all or none)
Concistency (資料保持某種一致性或正確性)
Isolation (transaction 之間的隔離)
Durability (持久性)
ACID
除了 Atomicity 資料庫一定會保證全部成功或全部失敗之外
其它的會因為做法不同而有不同程度的分別
Durability
commit 成功的資料更動
會持續存在
不太會因為系統掛掉資料就沒有了
單個硬碟不被認為是 stable storage
但是比起主記憶體
他可以承受沒電很久
也算是有某種程度的 durability ?
資料要寫到 stable storage 才算成功
information residing in stable storage is never lost
Atomicity
在同一個 transaction 裡面的指令
最後會全部成功或全部失敗
如果寫完 A 正要去寫 B 的時候
斷電了
怎麼辦
要去做之前,先記錄下來
這樣即使出意外 還有紀錄可以查
而且要記錄到 disk,這種紀錄檔叫 log
Isolation
讓 transaction 不太需要擔心別的 transaction 做了什麼
沒有 isolation 的話可能會有怪怪的結果
| begin A = A - 100 B = B + 100 commit |
begin A = A * 1.05 B = B * 1.05 commit |
T1 T2
schedule
總和不變
總和 * 1.05
Isolation
如果不要 concurrency 的話
一個 transaction 完才處理另外一個
效能很差 也浪費資源
同時間能處理的 query 會少很多
cpu、i/o 不會同時被利用
簡單的 transaction 要等耗時間的 transaction
Consistency
比較模糊
跟另外 3 個不在同一個層次
應該是說資料對於 application 來說 邏輯上的正確性/一致性
然後這個正確性不會因為 transaction 的關係被破壞
Isolation
1. 怎樣的 schedule 是 ok 的,怎樣的是不 ok 的
2. 怎麼讓不 ok 的 schedule 不要都 commit 成功
怎樣的 schedule ok
| begin A = A - 100 B = B + 100 commit |
begin A = A * 1.05 B = B * 1.05 commit |
T1 T2
| begin A = A - 100 B = B + 100 commit |
begin A = A * 1.05 B = B * 1.05 commit |
T1 T2
來討論 schedule 的 serializability
沒有干擾
有干擾
serial schedule
總和不變
總和 * 1.05
換成 read 跟 write
| read(A) write(A) read(B) write(B) |
read(A) write(A) read(B) write(B) |
T1 T2
| read(A) write(A) read(B) write(B) |
read(A) write(A) read(B) write(B) |
T1 T2
是不是 non-serial 就不行
| read(A) write(A) |
read(B) write(B) |
T1 T2
不同目標的話就沒關係
serializable
| read(A) write(A) |
read(B) write(B) |
T1 T2
≡
serial schedule
是不是同一個目標只要有交錯就不行
| read(A) read(A) |
read(A) |
T1 T2
如果都是 read 就沒關係
serializable
| read(A) read(A) |
read(A) |
T1 T2
≡
serial schedule
感覺不行交換的例子
| read(A) write(A) |
write(A) |
T1 T2
conflict & non-conflict operations
兩個 operations 針對同一個目標
至少其中一個是 write
這樣他們就是 conflict operations
| read(A) write(A) |
write(A) |
T1 T2
conflict-equivalent schedules
一個 schedule
可以透過交換 non-conflict operations
轉為另一個 schedule 的話
他們兩個就是 conflict-equivalent
| read(A) write(A) |
read(B) write(B) |
T1 T2
| read(A) write(A) |
read(B) write(B) |
T1 T2
≡
conflict-serializable
一個 schedule
如果可以透過交換 non-conflict operations
轉為另一個 serial schedule 的話
他就是 conflict-serializable
| read(A) write(A) |
read(B) write(B) |
T1 T2
| read(A) write(A) |
read(B) write(B) |
T1 T2
conflict serializable
≡
serial schedule
一個不錯的計算 schedule 是否為 conflict serializable 的方法
畫 dependency graph
以 transaction 為點
conflict operation 為邊
先的 transaction 指向後的 transaction
T1
T2
dependency graph
T1
T2
| read(A) write(A) |
read(B) write(B) |
T1 T2
| read(A) read(A) |
read(A) |
T1 T2
dependency graph
T1
T2
| write(A) |
read(A) write(A) |
T1 T2
dependency graph
T1
T2
| read(A) write(A) |
write(A) |
T1 T2
有 cycle 的 schedule 就不是 conflict-serializable
沒有的就是
serializable
Serializable means that concurrency has added no effect.
Unserializable schedules introduce inconsistencies.
不能讓 non-serializable 的 schedule 成功
1. 事前預防
2. 發生的時候 abort / rollback
1 事前預防
lock 的機制
要先拿到 lock 才能做事
沒拿到就要等
|
begin read(A) ... |
begin write(A) ... |
T1 T2
一個基本的 lock 方式
shared lock & exclusive lock
| shared | exclusive | |
| shared | O | X |
| exclusive | X | X |
|
begin read(A) ... |
begin write(A) ... |
T1 T2
read 前要先拿 shared lock
write 前要先拿 exclusive lock
2 發生 non-serializable schedule 的時候 abort / rollback
不擋操作 但記下操作的時間
偵測到有 non-serializable schedule 的時候
abort / rollback 其中一個或多個 transaction
其實只允許 serializable 的 schedule 的話
大多數時候效能還是太爛了
在對資料更新的時候
其他人都不能讀
或是一直有人讀的話 就一直不能更新
isolation levels
- serializable
- repeatable read
- read committed
- read uncommited
對同一個目標讀兩次
結果不會被別的 transaction 改變 嗎
4 個 level 都不允許 dirty writes
如果有一個目標已經被更新了但還沒 commit 或 rollback
其它 transaction 不能去更新
看起來好像只有 read uncommitted
可以解決資料在更新的時候不能讀
或是有人讀的時候其他人不能更新的狀況?
Multiple versions
讓多個版本的資料同時存在
transaction在更新資料的時候 可以只更新自己的版本
其他人也可以只讀自己的版本
例如 repeatable read
|
begin read(A) read(A) ... |
begin write(A) read(A) ... |
T1 T2
會 read 到自己剛剛修改的結果
兩次 read 結果會一樣
因為他看的是自己的版本
小總結
isolation level 爲 serializable 的時候
幾乎不會在 transaction 這部分
造成 application 資料的 inconsistency
但是因為效能代價太大 可能只有特殊情況才會用
大多資料庫管理系統預設的是 read committed
(MySQL 是 repeatable read)
不是用 serializable 的話
寫 application 的人就要注意更多可能造成 inconsistency 的狀況
必要的時候可以在 connection 改變 isolation level
=> set session transaction isolation level serializable
或是在某個 query 指定要拿 lock
=> SELECT ... FOR SHARE (shared lock)
=> SELECT ... FOR UPDATE (exclusive lock)
參考資料
Database Transactions
By luyunghsien




