關聯式資料庫的 index 的基本資料結構 (B+ tree)
關聯式資料庫 不太恰當的類比
Tables?
database 由 tables 組成
每個 table 有固定的欄位
可以放一筆筆的資料進去
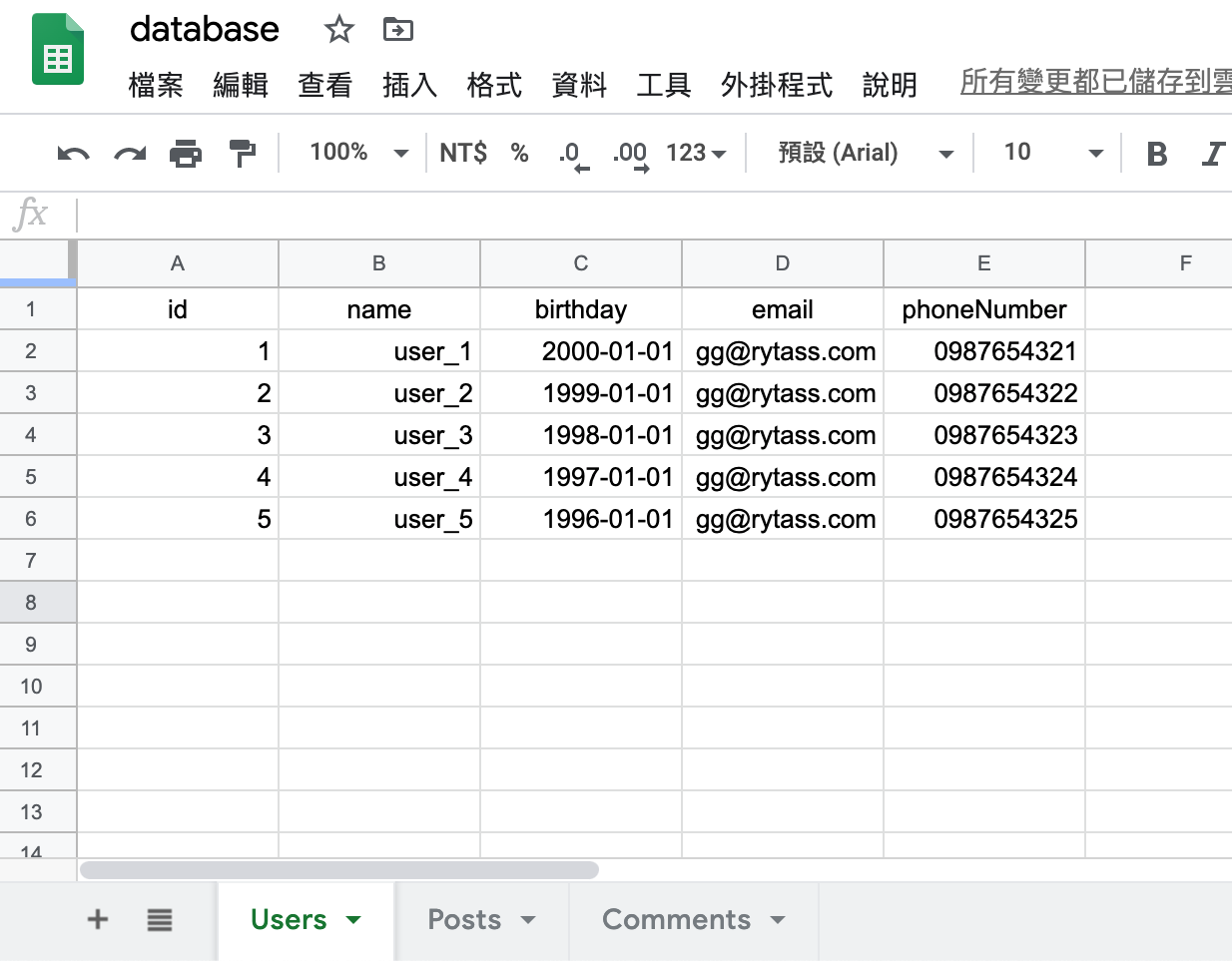
關聯式資料庫 GUI (Sequel Pro)
database
tables
columns
data
如果今天要找 2000-01-01 出生的用戶
SELECT id, name FROM Users WHERE birthday = '2000-01-01';SQL 是聲明式的語言
我們指出要找什麼資料
怎麼找基本上是由資料庫的 server 幫我們決定
欄位
table
條件
SQL
所以資料庫 server 可能會怎麼找呢
1. 把資料全部抓出來,再過濾 birthday
2. 如果我們事先告訴它要建立 birthday 的 "index",它可以用可能比較有效率的找法
或
index 的功能就像是書後面的 index

如果要為某個 table 的某個欄位建立 index
指令就像這樣
CREATE INDEX ON Users (birthday);table
欄位
今天要介紹 index 的資料結構
還有資料庫的 server 大概是怎麼用 index 來找資料
從二元搜尋樹出發
root
leaf
4
2
6
1
3
5
7
leaf
leaf
leaf
假設擺滿 d 層,有 n 個 node
\Rightarrow 2^d \sim n
\Rightarrow d \sim \log_2 n
或是用 2 分搜尋法舉例
2 個要切 1 次
4 個要切 2 次
8 個要切 3 次
...
n 個要切 次
\log_2 n
樹的深度 (層數) 就是最多要找的次數
如果照 二元搜尋樹 的邏輯來實作 index
1. value
2. 該筆資料或是該筆資料存放的位置 (紅點)
3. 左 child node 存放的位置 (黑點)
4. 右 child node 存放的位置 (黑點)
可能會像這樣
4
2
6
1
3
5
7
每個 node 存
假設要找值為 3 的那筆資料
4
2
6
1
3
5
7
data
資料庫的資料存在硬碟裡
從硬碟拿資料的速度很慢
但是這樣一個一個拿 不夠快
更快的方式:在 1 個 node 裡多放一些資料,減少向硬碟取資料的次數
其實
作業系統
為了增加效率
要從硬碟拿資料的時候
都有設計一個最小的單位 (block)
例如 4KB 之類的
每次至少要拿那個大小
沒辦法只拿個 2 bytes 到記憶體之類的
data block
資料庫管理系統 (MySQL, Microsoft SQL Server...) 也有這樣的設計
資料基本上就是切成一個個 block
一開始可以設定 block 的大小
一個 node 可以放多少 key 跟 block 的大小有關
所以我們來介紹 m-way search tree
9
18
1
2
4
5
7
8
10
11
13
14
16
17
19
20
22
23
25
26
3
6
12
15
24
3-way search tree
21
最多可以有 3 個 children
最多可以放 3 - 1 = 2 個值
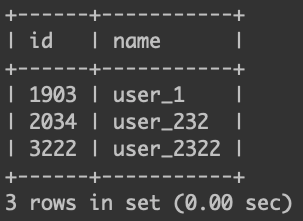
假設要找 id 為 16 的那筆資料
9
18
1
2
4
5
7
8
10
11
13
14
16
17
19
20
22
23
25
26
3
6
12
15
24
21
data
m-way search tree
假設每個 node (block) 都擺滿
來數一下每層可以擺幾個值
第 1 層 (root, 1 個 node):m - 1
第 2 層 (m 個 node):m * (m - 1)
第 3 層 (m * m 個 node):m * m * (m - 1)
第 4 層 (m * m * m 個 node):m * m * m * (m - 1)
...
通常資料庫 1 個 block 可以有幾百個值
=> 第 2 層就可以放幾萬
=> 第 3 層就可以放幾百萬~幾億
b-tree
m-way search tree 沒有限制太多
b-tree 限制比較多
就是多了一些規定的 m-way search tree
4
3
2
2
1
3
4
1
(ordered linked list)
b-tree 的定義
1. 每一個節點最多有 m 個子節點
2. 有 k 個子節點的非葉子節點擁有 k − 1 個鍵
3. 如果根節點不是葉子節點,那麼它至少有兩個子節點
4. 除根節點外每一個節點最少有 ⌈m/2⌉ 個子節點 (葉子不算)
5. 所有的葉子節點都在同一層
應該不用記
我的理解是這樣定義
可以保持 tree 足夠平衡
又可以有最有效率的新增、查詢、刪除流程
(不是 root 的非葉子節點差不多都在半滿 ~ 全滿的狀態)
b-tree 插入 data (m = 3)
一開始有一個 1
然後加入一個 2
再加入一個 3 的話會超過兩個 --> 要分開來
(中間那個變成 parent)
1
1
2
3
2
1
2
1
3
b+ tree
1. 只有葉子節點帶 data
2. 葉子節點那一層同時是 linked list
什麼是 linked list
2
2
3
4
1
單向
2
雙向
2
2
2
4
1
3
比較一下
2
1
4
3
5
6
3
5
7
1
2
b-tree
b+ tree
3
4
5
6
7
另一個 b+ tree 的例子
7
3
5
9
11
假設要找 6 到 10 之間的每筆資料
1
2
3
4
5
6
7
8
9
10
11
12
13
data
data
data
data
data
有 index 不一定比較快
7
5
6
7
8
3
5
...
999996
999997
如果需要拿回的資料太多
用了 index 反而會因為一次一塊照順序拿
比直接把全部的 data 都拿出來再過濾還慢
如果找 6 ~ 100000 之間
有 index 不一定比較快
D
B
C
C
C
A
B
...
如果需要拿回的資料太多
用了 index 反而會因為一次一塊照順序拿
比直接把全部的 data 都拿出來再過濾還慢
C
C
如果找 C 類別的所有資料
所以即使有建立某個欄位的 index
資料庫管理系統也不一定會用
它會對欄位的值做統計 (像是哪個值有幾筆資料)
用統計的資料比較各種方案之後
才決定用哪種方式找資料
不過如果是沒統計到的欄位,它用預設值去估計,就可能還是會不準
參考資料
b-tree 維基百科
b-tree, b+ tree 的 youtube 上課影片
談資料庫效能的書
multi-way search tree 筆記
b-tree 跟 b+ tree 新增、刪除、查詢的過程 (demo)
B+ tree
By luyunghsien




