
Zui Chen
Fate is Fluid, Destiny is in the hands of Man.
Bingliang Zhang, Zui Chen
Large Action Space
Imperfect Information
Long-Horizon
Non-Trivial Valuation
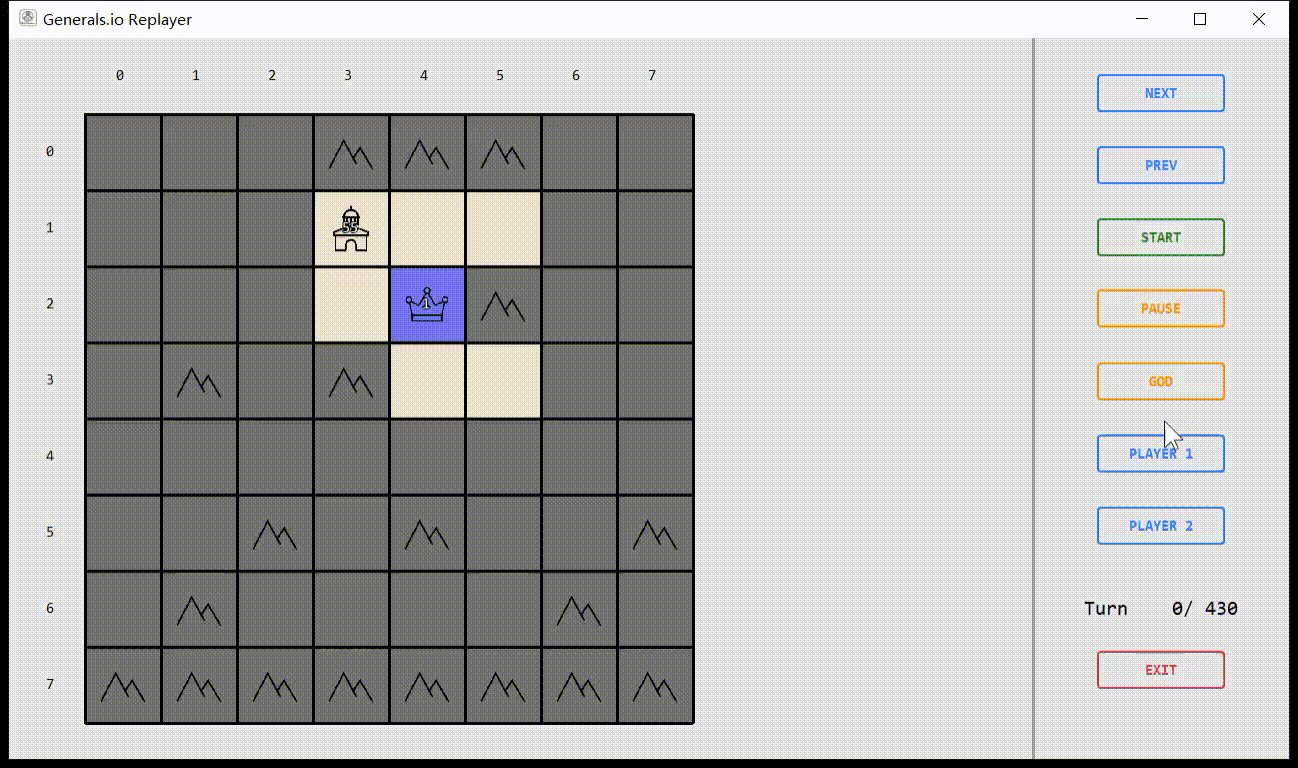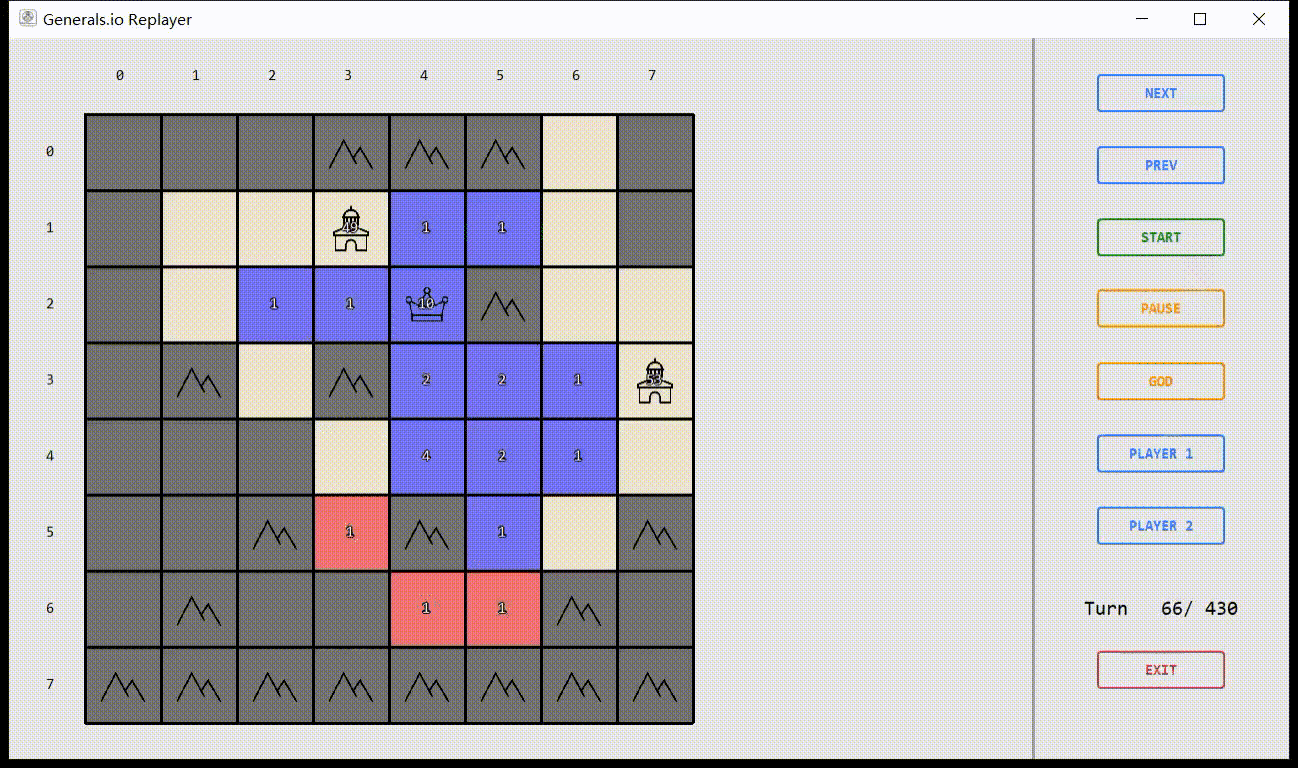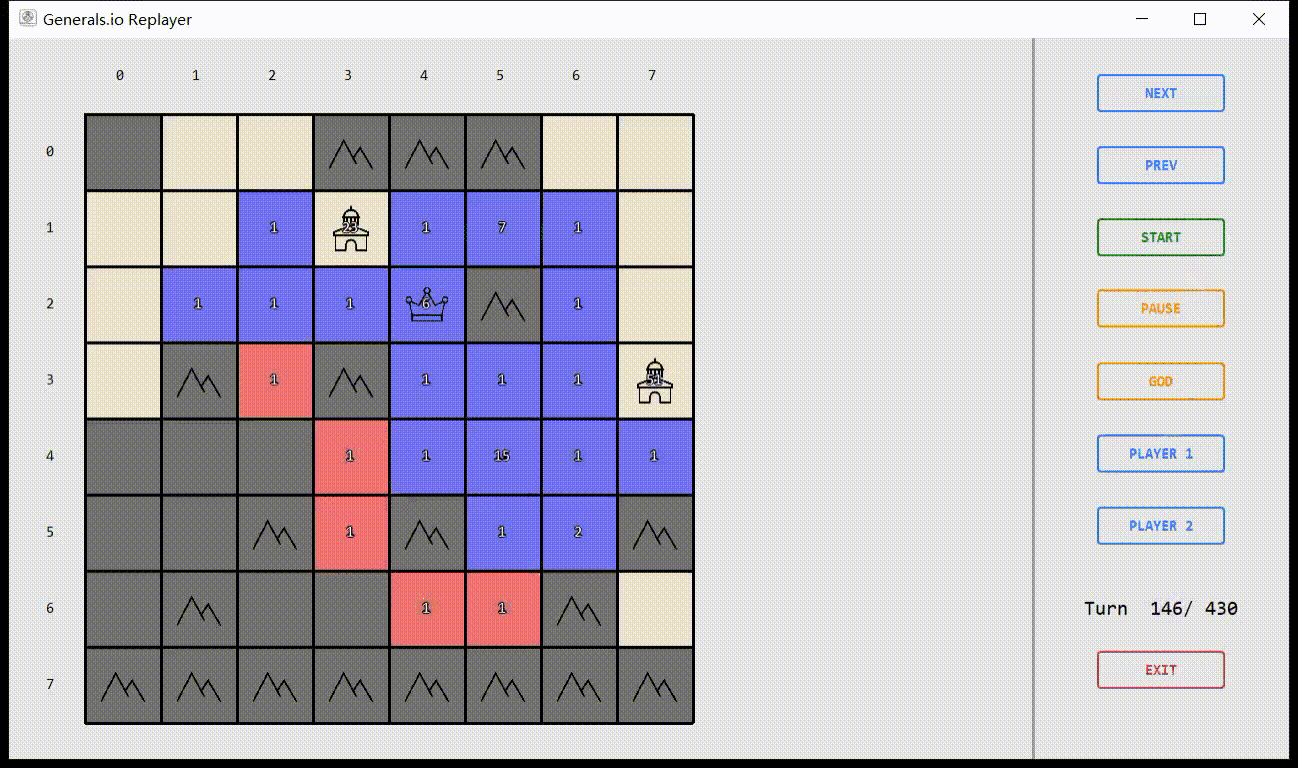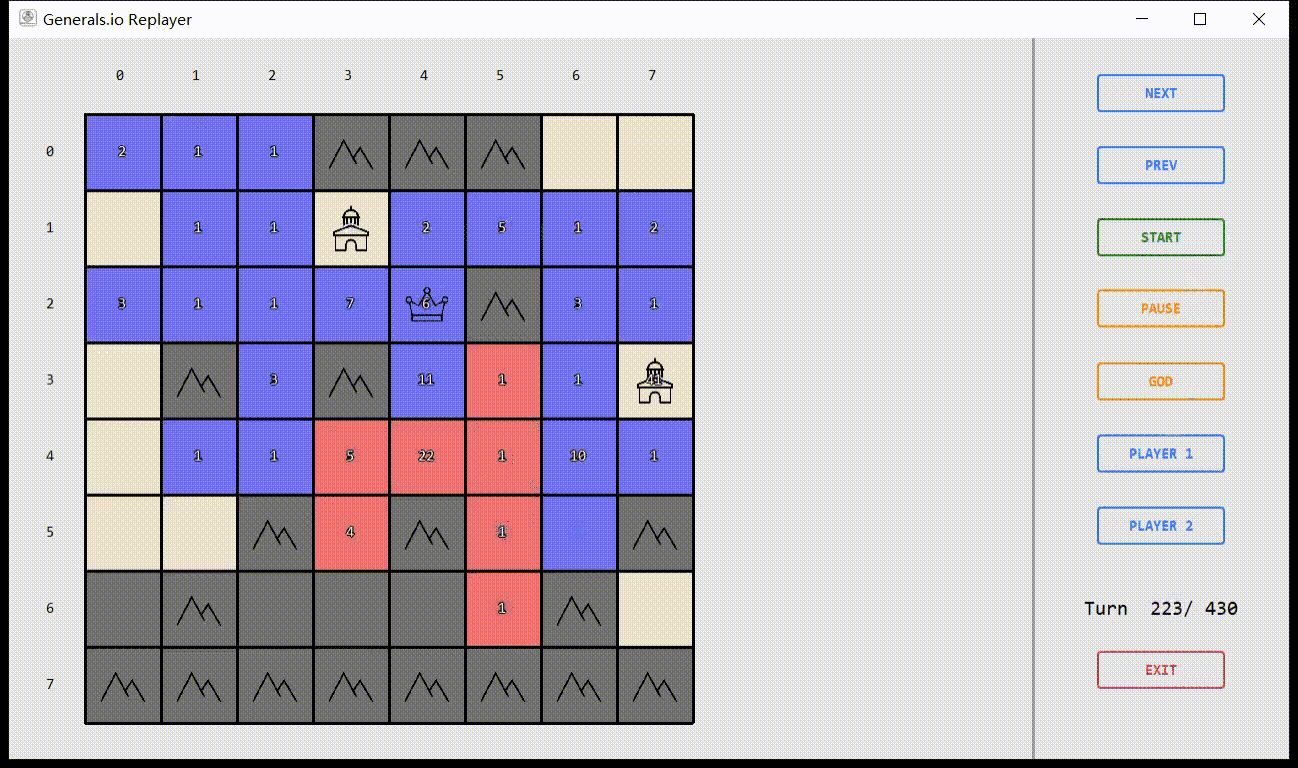
Virtual Environment
Based on OpenAI Gym
RL Frameworks
Modified from tianshou
s
Model Architectures
Specifically Designed
for generals.io game
State/Feature Design
Reward Design
RL Algorithm Choice
Fully Convolutional
Attention-Based
Simulator & Interface
pixel-wise feature representation:
One-hot
pixel-wise feature representation:
One-hot
One-hot
pixel-wise feature representation:
One-hot
One-hot
One-hot
pixel-wise feature representation:
One-hot
One-hot
One-hot
NORMALIZED float
pixel-wise feature representation:
One-hot
One-hot
One-hot
NORMALIZED float
Broadcast
pixel-wise feature representation:
One-hot
One-hot
One-hot
NORMALIZED float
Broadcast
Multi-frame stacking
pixel-wise feature representation:
One-hot
One-hot
One-hot
NORMALIZED float
Broadcast
Multi-frame stacking
?
pixel-wise feature representation:
RL ALgorithm Choice:
RL ALgorithm Choice:
Reward Design:
RL ALgorithm Choice:
Reward Design:
RL ALgorithm Choice:
Reward Design:
Spatial-Related Large Action Space of Various Size
Spatial-Related Large Action Space of Various Size
Fully Convolutional Layers
Spatial-Related Large Action Space of Various Size
Long Horizon, Action Continuity
Fully Convolutional Layers
Spatial-Related Large Action Space of Various Size
Long Horizon, Action Continuity
Fully Convolutional Layers
Attention Window Layers
We train our model from scratch:
Bingliang Zhang, Zui Chen
Thank You!
By Zui Chen




