OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
- This paper introduce OpenHands, a library where we take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition.
- It is a open-source library, all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible.
Abstract:
Introduction:
- When compared against text and speech-based NLP research, the progress in AI research for sign languages is significantly lagging.
- We implement these ideas and release several datasets and models in an open-source library OpenHands with the following key contributions:
- Standardizing on pose as the modality.
- Standardized comparison of models across languages.
- Corpus for self-supervised training.
- Effectiveness of self-supervised training.x
Background and Related Work:
Models for ISLR:
Pretraining strategies
- Sequence based models
- Graph based models
- Masking-based pretraining
- Contrastive-learning based
- Predictive Coding
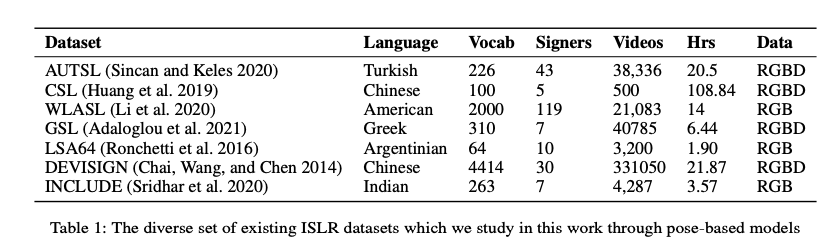
Datasets available in Openhands library:
Experiment Setup and Results:
- PyTorch Lightning to preprocessing data and for training pipelines
- Adam Optimizer
- For LSTM Batch size as 32 and initial learning rate (LR) as 0.005
- For BERT, batch size as 64, and LR of 0.0001.
- For ST-GCN and SL-GCN, batch size of 32 and LR of 0.001.
- Single NVIDIA Tesla V100 GPU
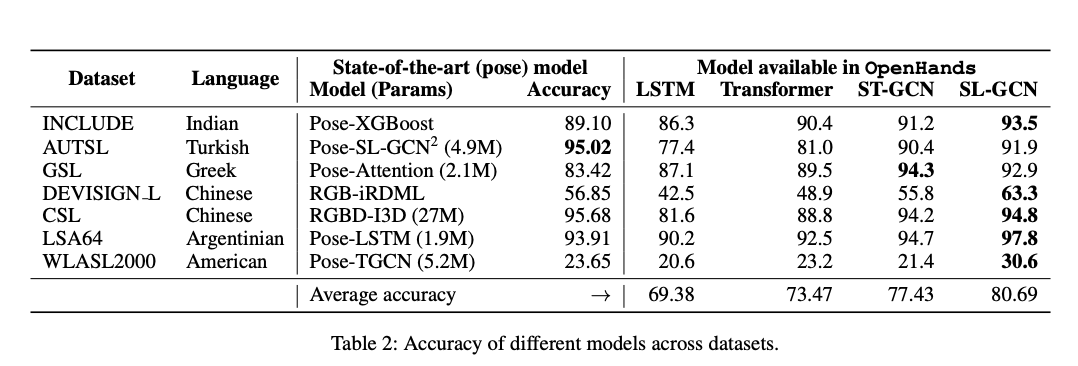
Comparision of each dataset with its state of the art model and with models available in OpenHands:
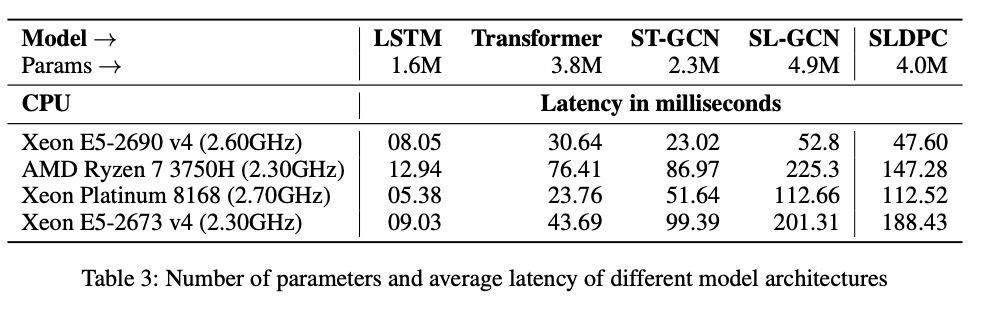
Comparision of Inference times across various models and CPUs:
Indian SL Corpus for Self-supervised pretraining

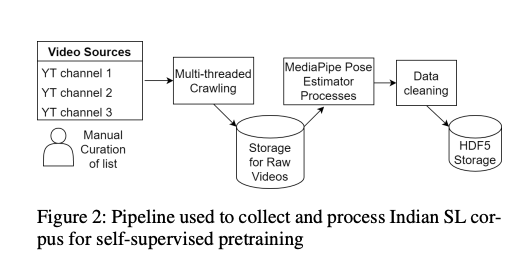
Explains process of collection and storing SL corpus:
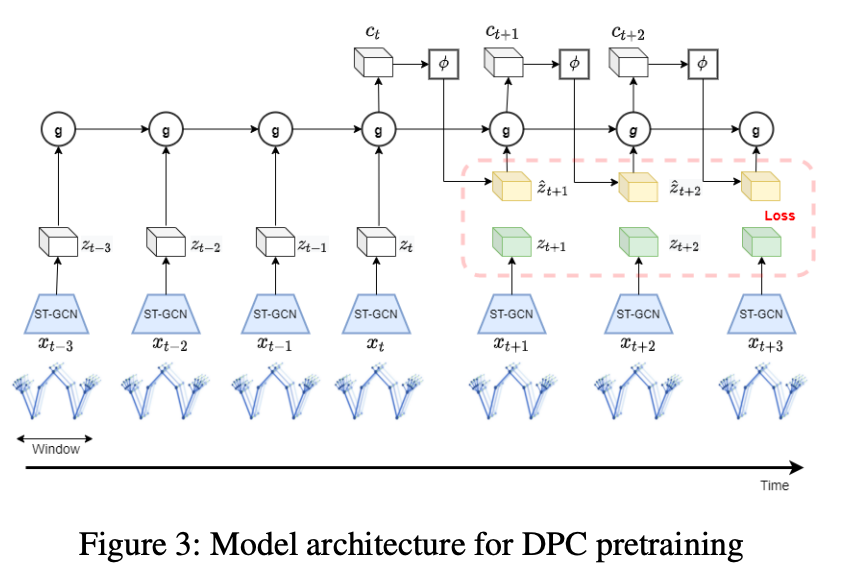
Pretraining Startiges:
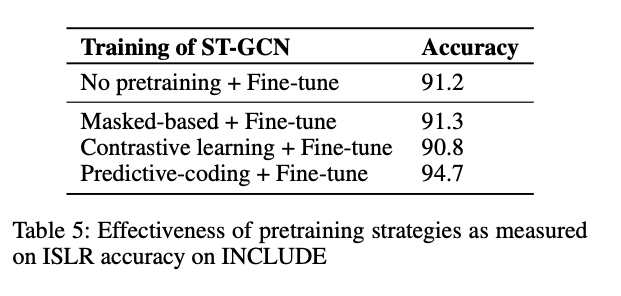
Effectiveness of pretraining startegies:
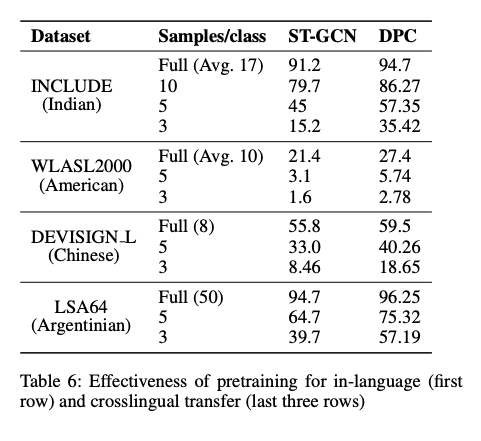
Evaluation on low-resource and crosslingual settings:
Conclusion:
- Introduced 7 pose-based datasets and 4 different ISLR models across 6 sign languages as part of openhands library.
- Also released first large corpus of SL data for self-supervised pretraining.
- Among different pretraining strategies and found DPC as effective.
- Also showed that pretraining is effective both for in-language and crosslingual transfer.
Future Work:
- Evaluating alternative graph-based models.
- Efficiently sampling the data from the raw dataset such that the samples are diverse enough.
- Quantized inference for 2×-4× reduced latency
- Extending to CSLR.
deck
By Manideep Ladi cs20m036



