Elasticsearch

You know, for search...
WHY SEARCH SUCKS?

WHY SEARCH SUCKS LESS?



COMMON PROBLEMS
- no FTS
- SQL like clause -> precision over recall, full scan
- no index
- keywords, fuzzy, wildcards, phase, regular expressions - not always available
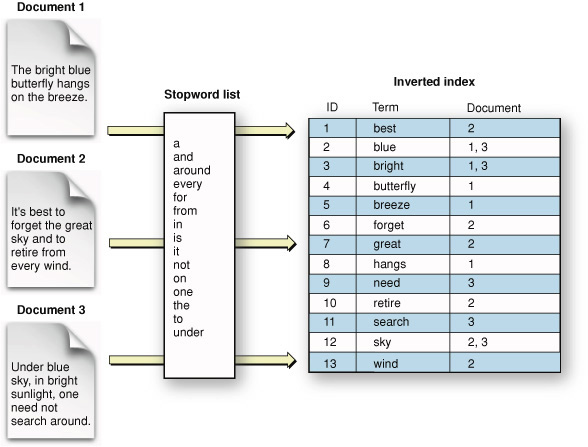
INVERTED index to the rescue
What is Elasticsearch
NoSQL
Search Server (based on Lucene)
Data cruncher (slice and dice)
Details
distributed
open-source
RESTful
document oriented
schema free
GLOSSARY
-
IR (information retrieval) - Finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers, query is an attempt ….)
-
index - like a table the relational database world.But in contrast to a relational database, the table values stored in an index are prepared for fast and efficient full-text searching and in particular, do not have to store the original values.
-
document - with analogy to relational databases is a row of data in a database table. Comparing an ElasticSearch document to a MongoDB one, both can have different structures, but the one in ElasticSearch needs to have the same types for common fields.
-
document type - In ElasticSearch, one index can store many objects with different purposes. Document type lets us easily differentiate these objects.
-
shard - it's separate Apache Lucene index
SEARCH evolution

LET"S Build an Example
start server
create index
insert data
search data
Let's talk more about....
SERVER

Deploy with 2 shards and 1 replica
Start with one node
add second node
add third and forth node

MORE on SERVER
-
scatter and gather
- (near) real time search - refresh 1 s
- cloud storage support
- per document consistency - no need to commit
you've said it's schema free....
YES, but....
SCHEMA MAPPINGS
{
"mappings": {
"post": {
"properties": {
"id": {"type":"long", "store":"yes", "precision_step":"0" },
"name": {"type":"string", "store":"yes", "index":"analyzed" },
"published": {"type":"date", "store":"yes","precision_step":"0" },
"contents": {"type":"string", "store":"no", "index":"analyzed" }
}}}}
Querying and indexing process
Indexing
Searching
Analysis
Tokenization
Filtering
Analyzer
OTO LUCynKa

*zielona
QUERY DLS

QUERY types....
Filters....
- boolean- fast- no scoring- cacheable*
Queries...
- fuzzy, scoring- slownot cacheable
Filter when you can, query when you must
*psst: Cache is not invalidate it's updated too!
Queries
Basic
- term, terms, match query, boolean match- phase match, match prefix, multi match- query string, field, prefix, fuzzy, all, wildcard, range
Compound - can combine multiple queries
- bool- filtered- boosting- custom score
BOOBS HELP SCORE FACET :)

AH SORRY... ;)
BOOST - Boost is an additional value used in the process of scoring
SCORE (ask Lucene) - scoring uses a combination of the Vector Space Model (VSM) of Information Retrieval and the Boolean model to determine how relevant a given Document is to a User's query
FACET(ed search) - is a technique for accessing information organized according to a faceted classification system, allowing users to explore a collection of information by applying multiple filter
NESTED objects
Nested objects/documents allow to map certain sections in the document indexed as nested allowing to query them as if they are separate docs joining with the parent owning doc.
{"id": 1, "title": "Book one",
"prices" : [ {
"price": 13.27,
"region": "Europe"},
{"price": 12.70,
"region": "USA" },
{"price": 11.99,
"region": "Asia"}]}
SPATIAL DATA
YES! Based on geojson specification.
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [[13, 53],[14, 52]]
}
}}}}
TOOLS and libraries
- native Java client
- JEST
- elastic.js (angular, jQuery)
- .NET client
... and more
- sense
- curl
PLUGINs, use cases
- log stash
- kibana
- rivers
- dashboard plugins
Thank you

Elasticsearch
By marcin



