Learning to Segment Moving Objects
- Pavel Tokmakov
- Cordelia Schmid
- Karteek Alahari
Received: 2 December 2017
Accepted: 10 September 2018
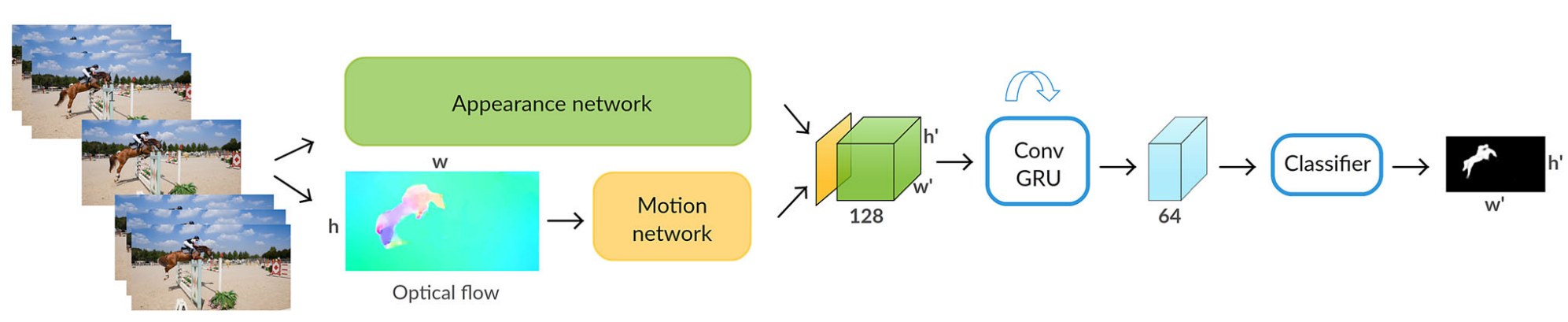
Overview
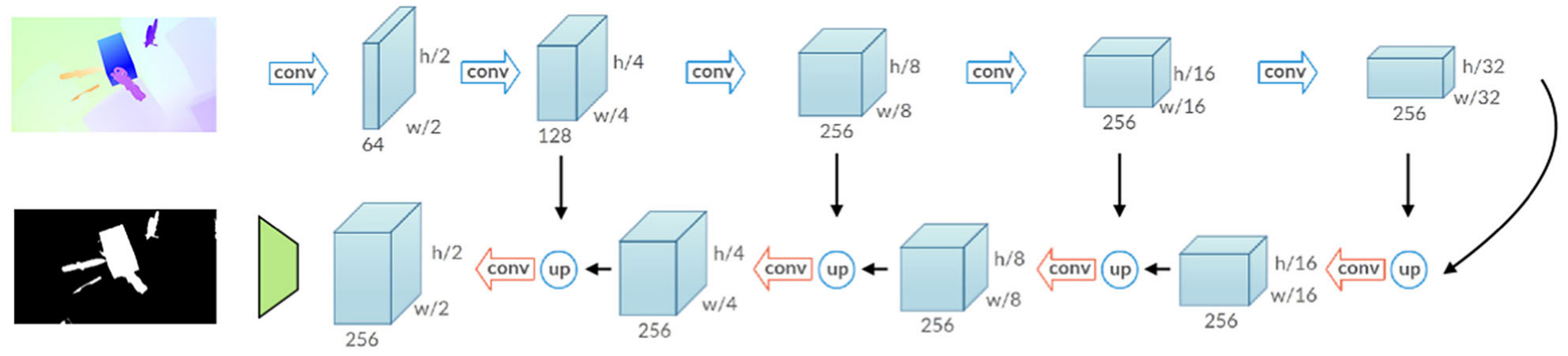
Appearance Network
- high-level encoding of a frame
- objects and background separation
DeepLab v1- DeepLab v2
w \times h \rightarrow
128 \times w/8 \times h/8
Motion Pattern Network
Input: 2 consecutive video frames
Output: per-pixel motion labels
trained on synthetic data = easy GT
and finetuned on real videos
f(x) = \max(0, x)
Training [synthetic]
- FlyingThings3D dataset
- easy GT optical flow annotations
- 2250 video sequences
- mini-batch SGD

Result [synthetic]
Result [real-world]

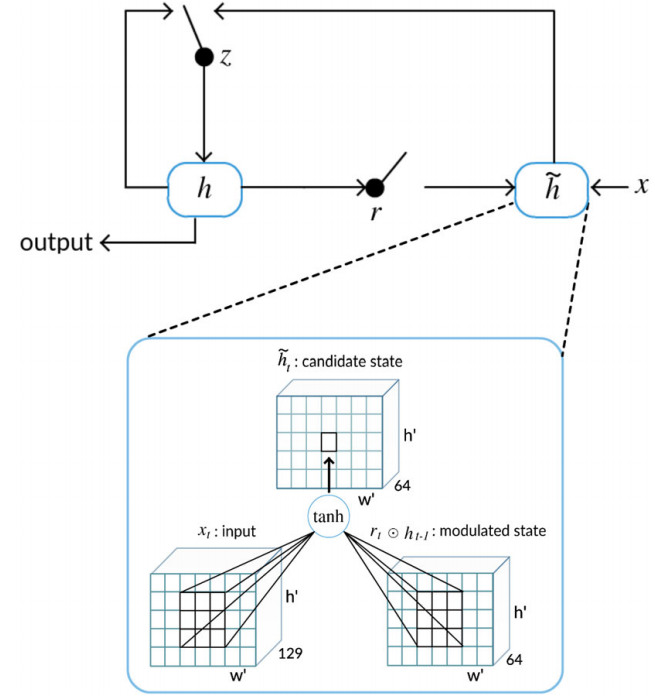
ConvGRU Visual Memory Module
h - state matrix
z_t = \sigma(x_t * w_{xz} + h_{t-1} * w_{hz} + b_z)
r_t = \sigma(x_t * w_{xr} + h_{t-1} * w_{hr} + b_r)
\tilde{h_t} = \tanh(x_t * w_{x\tilde{h}} + r_t \odot h_{t-1} * w_{h\tilde{h}} + b_{\tilde{h}})
h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h_t}
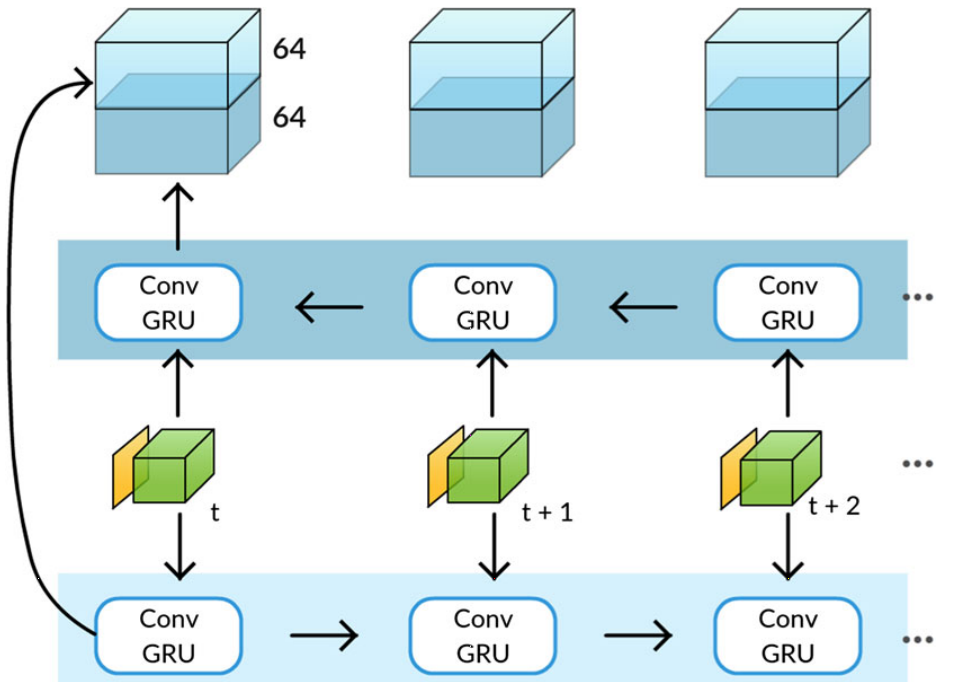
Bidirectional Processing
Training
- backprop
- 6n layer CNN (12n bidirectional)
- pretrained appearance and motion networks
- DAVIS dataset (real-world sequences) + augmentation
Experiments
- training datasets:
- FT3D
- DAVIS
- testing datasets:
- FT3D
- DAVIS
- FusionSeg
- FBMS
- SegTrack-v2
Appearance stream
- DeepLab-v1
- DeepLab-v2
Training MP-Net
- mini-batch (13) SGD
- learning rate: 0.003
- momentum: 0.9
- weight decay: 0.005
- 27 epochs
- learning rate and weight decay * 0.1 every 9 epochs
- downsample FT3D (by 2)
Training Visual Memory Module
- backprop and RMSProp
- learning rate: 0.0001 (decreased after every epoch)
- weight decay: 0.005
- initialization of conv methods (except ConvGRU) with xiavier method
- batch - random video and random subset of 14 consec. frames
- 7 x 7 consolutions on ConvGRU
- 30000 iterations
\frac{1}{n_{in}}
\frac{2}{n_{in} + n_{out}}
\frac{2}{n_{in}}
MP-Net design
Input
- RGB data (single vs pair)
- GT vs estimation optical flow
- optical flow as flow vectors vs angle field
- + combinations
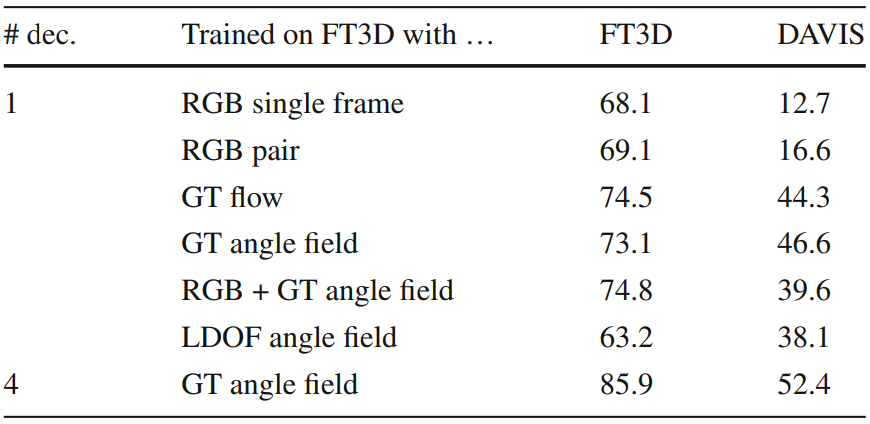
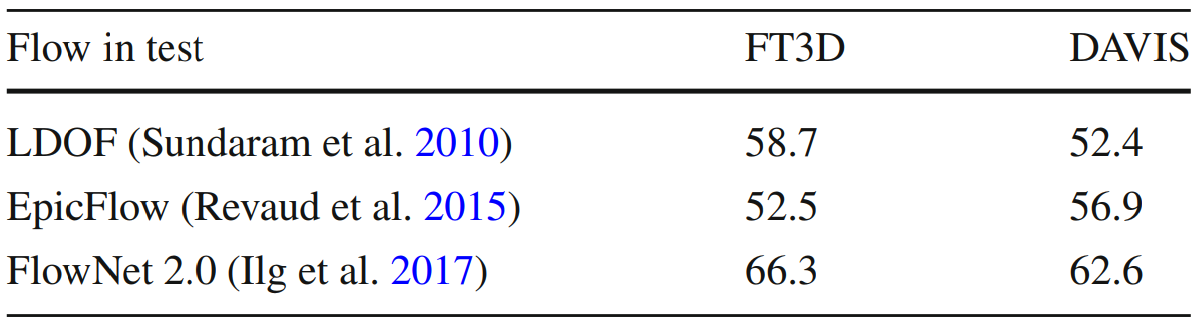
Flow quality
EpicFlow vs FlowNet 2.0 vs LDOF
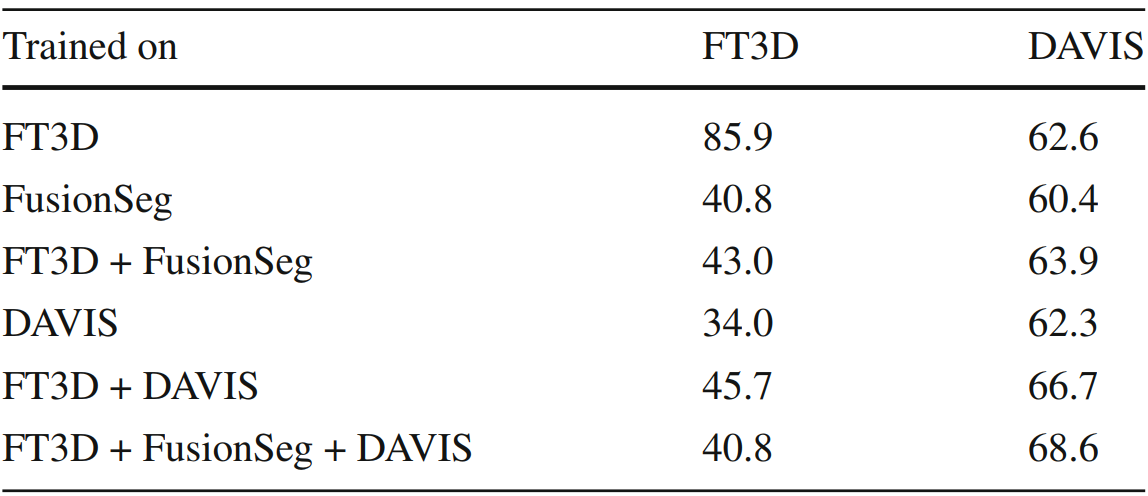
Training on real videos
training on FusionSeg and DAVIS
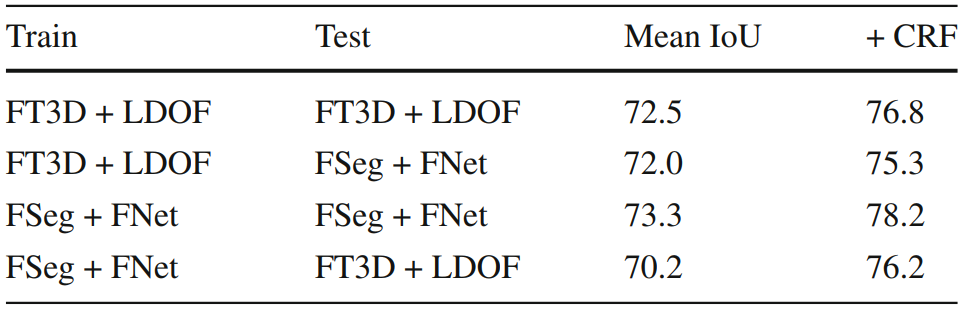
MP-Net influence
Motion network influence on whole model
State-of-the-Art
- DeepLab-v2 appearance stream
- ConvGRU memory model trained on DAVIS
- Bi-directional processing
- MP-Net finetuned on FusionSeg with FlowNet 2.0
- DenseCRF post-processing
Resulting model
Benchmarks
- DAVIS
- FBMS
- SegTrack-v2
DAVIS
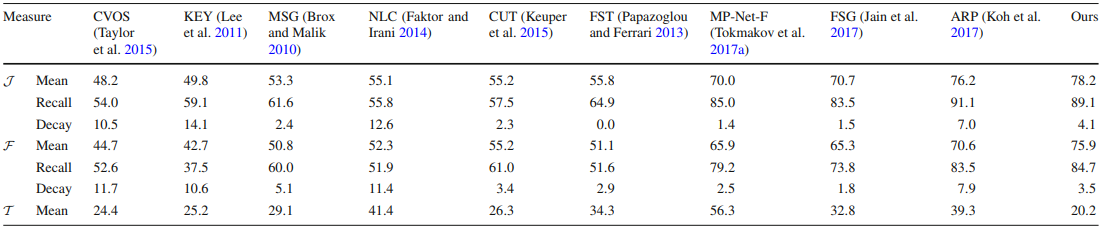
previous SotA - ARP beat by 2%
DAVIS

FBMS
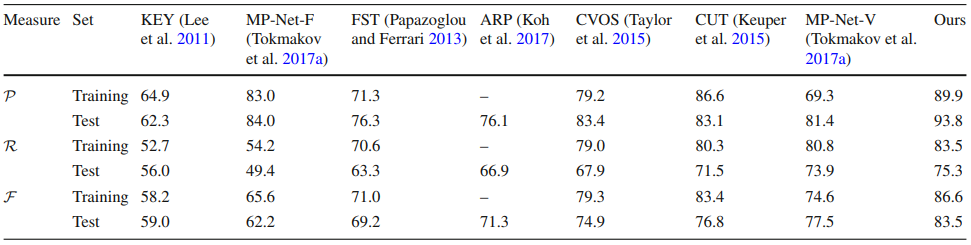
- ARP by 12%
- MP-Net-V by 6%
FBMS

SegTrack-v2
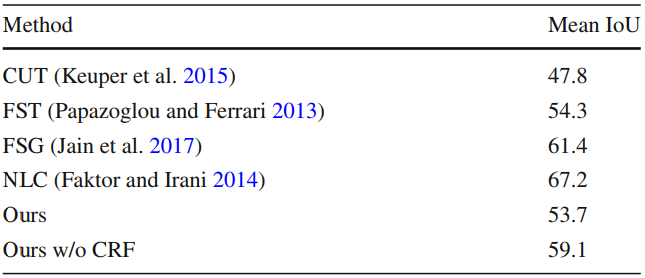
SegTrack-v2

Thank you for your attention!
Learning to Segment Moving Objects
By Marián Skrip



