Base de Datos
Curso Java Experto
Clase 6
SQL
SQL
El SQL es un lenguaje estándar de programación para el acceso a bases de datos.
El lenguaje SQL se utiliza para acceder y manipular datos en cualquier base de datos del mercado, como por ejemplo, para las bases de datos MySQL, Oracle, DB2, SQL Server, Access.
El SQL es un lenguaje estructurado y un estándar ANSI para el acceso y manipulación de los datos de cualquier base de datos.
Características generales
- Un sistema de base de datos suele contener varias bases de datos.
- Cada base de datos suele contener varias tablas.
- Las tablas almacenan los datos organizados por filas.
- Cada fila contiene varios campos o columnas.
- Cada campo tiene una serie de propiedades, como por ejemplo, el nombre del campo, su longitud, tipo de dato que se va a almacenar, etc.
- Las sentencias SQL no son sensibles a mayúsculas y minúsculas, es decir, 'SELECT' y 'select' son dos palabras iguales para SQL.
- Algunos sistemas de bases de datos necesitan un punto y coma después de cada sentencia SQL para ejecutarse correctamente
CREATE DATATABASE mibasededatos;
- Este punto y coma también puede servir para separar una sentencia SQL de otra sentencia SQL en la misma línea.
CREATE DATATABASE mibasedeatos; CREATE TABLE mitabla1;
1.- Lenguaje de definición de datos (DDL).
DDL está compuesto por sentencias para la creación (CREATE), modificación (ALTER) y borrado (DROP) de los componentes principales de una base de datos:
- base de datos (DATABASE)
- tablas (TABLE)
- vistas (VIEW)
- índices (INDEX)
- procedimientos almacenados (PROCEDURE)
- disparadores (TRIGGER).
2.- Lenguaje de manipulación de datos (DML).
DML está compuesto por sentencias que sirven para :
- consultar (SELECT)
- insertar (INSERT)
- modificar (UPDATE)
- borrar (DELETE)
3.- Lenguaje de control de datos (DCL).
DCL está compuesto por sentencias SQL para controlar las funciones de administración :
- Confirmar la operacion (COMMIT)
- Retroceder la operacion (ROLLBACK)
- Dar permisos (GRANT)
- Quitar permisos (REVOKE)
Lenguaje de definición de datos (DDL)
CREATE DATABASE
-
Esta sentencia sirve para crear una base de datos con un nombre específico.
-
Para poder crear una base de datos, el usuario que la crea debe tener privilegios de creación asignados.
-
IF NOT EXISTS significa: SI NO EXISTE, por lo tanto, esto es útil para validar que la base de datos sea creada en caso de que no exista, si la base de datos existe y se ejecuta esta sentencia, se genera error.
-
CREATE SCHEMA o CREATE DATABASE son sinónimos.
-
Ejemplo:
CREATE DATABASE IF NOT EXISTS complejo_de_cine;
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] nombre_base_datosCREATE TABLE
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] nombre_de_tabla
nombre_de_columna tipo_de_dato [NOT NULL | NULL]
[DEFAULT valor_por_defecto][AUTO_INCREMENT] [UNIQUE | [PRIMARY]
KEY [CONSTRAINT [nombre_relación] FOREIGN KEY (nombre_columna)
REFERENCES nombre_de_tabla (nombre_columna)]
[ON DELETE opciones_de_referencia] [ON UPDATE opciones_de_referencia]opciones_de_referencia:
RESTRICT | CASCADE | SET NULL | NO ACTION
tipo_de_dato:
| BIT[(longitud)]**
| TINYINT[(longitud)]
| SMALLINT[(longitud)]
| MEDIUMINT[(longitud)]
| INT[(longitud)]**
| INTEGER[(longitud)]
| BIGINT[(longitud)]**
| REAL[(longitud,decimales)]
| DOUBLE[(longitud,decimales)]**
| FLOAT[(longitud,decimales)]
| DECIMAL[(longitud[,decimales])]
| NUMERIC[(longitud[,decimales])] | DATE **
| TIME **
| TIMESTAMP
| DATETIME **
| YEAR
| CHAR[(longitud)] [BINARY] ** | VARCHAR(longitud) [BINARY] ** | BINARY[(longitud)]
| VARBINARY(longitud)
| TINYBLOB
| BLOB
| MEDIUMBLOB
| LONGBLOB
| TINYTEXT [BINARY]
| TEXT [BINARY]
| MEDIUMTEXT [BINARY]
| LONGTEXT [BINARY]
| ENUM(valor1, valor2, valor3,. . .) | SET(valor1, valor2, valor3,. . .) | JSON-
Esta sentencia comienza creando la tabla, con la opción IF NOT EXISTS, de la misma manera que CREATE DATABASE, luego comienza a declarar cada una de las columnas de dicha tabla con sus tipos de datos.
-
Las opciones NOT NULL | NULL, sirven para especificar si dicha columna puede aceptar valores nulos: NULL, o si no puede guardar valores nulos: NOT NULL.
-
También se puede de manera opcional, indicar un valor por defecto para una columna. En dicho caso, si se inserta una fila en la tabla, sin asignarle un valor a una columna que tiene definido DEFAULT, se insertará la fila y la columna tendrá el valor por defecto definido.
-
AUTO_INCREMENT: se refiere a un valor AUTO INCREMENTAL; sirve para aquellas columnas con valores que numéricos enteros donde se necesita que dicho valor se incremente en uno por cada fila insertada en la tabla. Se utiliza muy frecuentemente en las claves primarias.
-
UNIQUE: sirve para indicar que una columna en la tabla no puede tener valores repetidos, debe ser UNICA. No pueden existir dos filas en la tabla que tengan el mismo valor para un atributo definido como UNIQUE.
-
PRIMARY KEY: sirve para especificar que una columna es clave primaria de una tabla. Si una columna es clave primaria implica que sus valores no deben repetirse.
-
Las tablas se relacionan entre ellas por medio de claves foráneas de la siguiente manera: se define una CONSTRAINT que significa RESTRICCIÓN y se le asigna un nombre para identificarla; dicho nombre funciona como clave que identifica unívocamente a cada CONSTRAINT que exista en la base de datos, por lo que toda CONSTRAINT debe tener un nombre no repetido; luego se indica con la palabra FOREIGN KEY, cuál es la columna de la tabla que funciona como clave foránea, indicando a continuación a cuál tabla y a cuál columna de dicha tabla hace referencia la clave foránea con la palabra REFERENCES.
Las opciones de referencia sirven para establecer que se hará en casos de que se elimine o se actualice una fila de la tabla primaria que está siendo referenciada por una fila de la tabla secundaria.
- CASCADE: Eliminar o actualizar la fila de la tabla primaria, y automáticamente eliminar o actualizar las filas coincidentes en la tabla secundaria.
- SET NULL: Eliminar o actualizar la fila de la tabla primaria, y establecer la columna de clave externa (Foreign key) de la tabla secundaria a NULL. Si se especifica una SET NULL, hay que asegurarse que no se haya declarado la columna de la tabla secundaria como NOT NULL.
- RESTRICT: Rechaza la operación de eliminación o actualización en la tabla primaria.
- NO ACTION: Una palabra clave de SQL estándar. En MySQL, equivalente a RESTRICT.
- SETDEFAULT: Esta acción es reconocido por MySQL, pero no todos los motores de base de datos lo tienen, en este caso se establece que para una operación de eliminación o actualización en la tabla primaria se establecerá un valor por defecto para la tabla secundaria.
Para una ON DELETE / ON UPDATE que no se especifica ninguna opción de referencia, la acción por defecto es siempre RESTRICT.
CREATE TABLE IF NOT EXISTS `Pelicula`
( `@id_pelicula` INT NOT NULL,
`anio_estreno` YEAR NULL,
`disponible` TINYINT(1) NOT NULL,
`duracion` INT NOT NULL,
`fecha_ingreso` DATE NULL,
`nombre` VARCHAR(100) NOT NULL,
`titulo_original` VARCHAR(100) NULL,
`#id_pais_de_origen` INT NOT NULL,
`# id_genero` INT NOT NULL,
PRIMARY KEY (`@id_pelicula`),
CONSTRAINT `Pais de Origen de Pelicula` FOREIGN KEY
REFERENCES `PaisDeOrigen`
ON DELETE NO ACTION
ON UPDATE NO ACTION,
CONSTRAINT `Genero de Pelicula` FOREIGN KEY
REFERENCES `Genero`
ON DELETE NO ACTION
ON UPDATE NO ACTION)

Ejemplo
Lenguaje de manipulación de datos (DML)
SELECT
Una de las sentencias SQL más importantes es SELECT, ya que permite realizar consultas sobre los datos almacenados en la base de datos.
SELECT <lista de atributos>
FROM <lista de tablas>
WHERE <condición>;<lista de atributos> es una lista de los atributos cuyos valores serán recuperados por la consulta.
<lista de tablas> es una lista de las tablas necesarias para procesar la consulta.
<condición> es una expresión condicional (booleana) que se evalúa en las filas de la tabla, aquellas filas que cumplan con la condición booleana serán el resultado de la consulta.
Selección sin condición
SELECT nombre_columna,nombre_columna FROM nombre_tabla;Selección de todas las columnas de una tabla, se simplifica colocando * en lugar de colocar todos los nombres de las columnas:
SELECT nombre_columna,nombre_columna FROM nombre_tabla;Selección de determinadas columnas sin valores repetidos. La palabra reservada DISTINCT (distinto) sirve como filtro: selecciona todas las filas de la tabla y devuelve el valor de las columnas indicadas con una previa eliminación de aquellas filas que tuvieran el mismo valor en la o las columnas especificadas en la cláusula SELECT:
SELECT DISTINCT nombre_columna, nombre_columna FROM nombre_tabla;DISTINCT
Al realizar una consulta puede ocurrir que existan valores repetidos para algunas columnas. Por ejemplo
SELECT nombre FROM personas;| nombre |
|---|
| Juan |
| Juan |
| José |
Esto no es un problema, pero a veces queremos que no se repitan, por ejemplo, si queremos saber los nombre diferentes que hay en la tabla personas", entonces utilizaremos DISTINCT.
SELECT DISTINCT nombre FROM personas;| nombre |
|---|
| Juan |
| José |
WHERE
La cláusula WHERE se utiliza para hacer filtros en las consultas, es decir, seleccionar solamente algunas filas de la tabla que cumplan una determinada condición.
Por ejemplo:
Seleccionar las personas cuyo nombre sea ANTONIO
SELECT * FROM personas
WHERE nombre = 'ANTONIO';Selección con utilización de operadores en la condición:
SELECT nombre_columna, nombre_columna FROM nombre_tabla
WHERE nombre_columna operador valor;
SELECT nro, fecha, monto, cliente_nombre FROM facturas
WHERE monto >200;
AND OR
Los operadores AND y OR se utilizan para filtrar resultados con 2 o más condiciones.
El operador AND mostrará los resultados cuando se cumplan las 2 condiciones.
Condición1 AND condición2
El operador OR mostrará los resultados cuando se cumpla alguna de las 2 condiciones.
Condicion1 OR condicion2
SELECT * FROM personas
WHERE nombre = 'ANTONIO'
AND apellido1 = 'GARCIA';Selección con AND y OR en la condición
SELECT * FROM Clientes
WHERE pais='Argentina'
AND provincia='Buenos Aires';
SELECT * FROM Customers
WHERE provincia='Córdoba'
OR provincia='Buenos Aires';ORDER BY
ORDER BY se utiliza para ordenar los resultados de una consulta, según el valor de la columna especificada.
Por defecto, se ordena de forma ascendente (ASC) según los valores de la columna.
Si se quiere ordenar por orden descendente se utiliza la palabra DES
SELECT nombre_columna(s)
FROM nombre_tabla
ORDER BY nombre_columna(s) ASC|DESC;COUNT, SUM, MAX, MIN y AVG
Como en muchas aplicaciones de bases de datos se necesitan el agrupamiento y la agregación, SQL dispone de funciones que incorporan estos conceptos: COUNT, SUM, MAX, MIN y AVG.
- La función COUNT devuelve el número de filas o valores especificados en una consulta.
- Las funciones SUM, MAX, MIN y AVG se aplican a un conjunto de valores numéricos y devuelven, respectivamente, la suma, el valor máximo, el valor mínimo y el promedio de esos valores.
SELECT SUM (sueldo), MAX (sueldo), MIN (sueldo), AVG (sueldo)
FROM empleados;Limit
Se puede utilizar para restringir el número de filas que puede retornar una sentencia SELECT.
LIMIT, toma uno o dos argumentos numéricos, ambos deben ser no negativos y enteros.
Con dos argumentos, el primer argumento especifica el desplazamiento de la primera fila a devolver, y el segundo especifica el número máximo de filas a devolver. El desplazamiento de la fila inicial es 0 (no 1):
SELECT * FROM nombre_tabla LIMIT 5,10;
-- Devuelve desde la fila 6 hasta la 15.Con un argumento, el valor especifica el número de filas a devolver desde el principio del resultado:
SELECT * FROM nombre_tabla LIMIT 5;
-- Devuelve las primeras 5 filas.Group by
En muchos casos queremos aplicar funciones a subgrupos de filas de una tabla, estando los subgrupos divididos en base a algunos valores de uno o más atributos. Por ejemplo, vamos a suponer que queremos saber el número de empleados que trabajan en cada proyecto. En estos casos, tenemos que dividir las filas de la tabla en subconjuntos no solapados de filas. Cada grupo (partición) estará compuesto por las filas que tienen el mismo valor para algún(os) atributo(s), denominado(s) atributo(s) de agrupamiento. Después podemos aplicar la función independientemente a cada grupo.
La cláusula GROUP BY especifica los atributos de agrupamiento, que también deben aparecer en la cláusula SELECT, por ejemplo:
Si quisiéramos saber, para todos proyectos de una empresa, el nro. de proyecto, el nombre del proyecto y el número de empleados que trabajan en cada proyecto.
SELECT nro_proyecto, nombre_proyecto, COUNT (*)
FROM proyectos
GROUP BY nro_proyecto, nombre_proyecto;Having
HAVING proporciona una condición en el grupo de filas asociado a cada valor de los atributos de agrupamiento. En el resultado de la consulta sólo aparecen los grupos que satisfacen la condición.
HAVING siempre debe ir acompañado previamente de un GROUP BY, ya que HAVING sirve para expresar una condición que es evaluada por cada grupo; aquellos grupos que la cumplan aparecerán en el resultado de la consulta.
Si quisiéramos saber, para todos proyectos de una empresa, el nro. de proyecto, el nombre del proyecto y el número de empleados que trabajan en cada proyecto y mostrar sólo aquellos proyectos que tengan más de 3
empleados trabajando:
SELECT nro_proyecto, nombre_proyecto, COUNT (*) FROM proyectos
GROUP BY nro_proyecto, nombre_proyecto
HAVING COUNT (*) > 2;La selección de datos puede ser mucho más compleja como se muestra a continuación:
SELECT [ALL | DISTINCT | DISTINCTROW] lista_atributos FROM nombre_tabla
[WHERE condición]
[GROUP BY {nombre_columna | expresión}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condicion]
[ORDER BY {nombre_columna | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]INSERT
La sentencia INSERT INTO se utiliza para insertar nuevas filas en una tabla.
Es posible insertar una nueva fila en una tabla de dos formas distintas:
-
En su formato más sencillo, INSERT se utiliza para añadir una sola fila a una tabla. Debemos especificar el nombre de la tabla y una lista de valores para la fila. Los valores deben suministrarse en el mismo orden en el que se especificaron los atributos correspondientes en el comando CREATE TABLE. Por ejemplo, para añadir una fila nueva a la tabla película:
INSERT INTO nombre_tabla
VALUES (valor1, valor2, valor3, ...);
INSERT INTO pelicula
VALUES (2, 2014, true, 122, 01/08/2014, "Relatos Salvajes", "Relatos Salvajes",1);INSERT INTO nombre_tabla (columna1, columna2, columna3,...)
VALUES (valor1, valor2, valor3, ...);
INSERT INTO EMPLEADO (nombre, apellido, dni) VALUES ('Ricardo', 'Roca', '653298653');-
Una segunda forma de la sentencia INSERT permite especificar explícitamente los nombres de los atributos que se corresponden con los valores suministrados en el comando INSERT. Esto resulta útil si la relación tiene muchos atributos y sólo vamos a asignar valores a unos cuantos en la fila nueva. Sin embargo, los valores deben incluir todos los atributos con la especificación NOT NULL y ningún valor predeterminado. Los atributos que permiten los valores NULL o DEFAULT son los que se pueden omitir. Por ejemplo, para introducir una fila para un nuevo EMPLEADO del que únicamente conocemos los atributos nombre, apellido, y dni, podemos utilizar:
UPDATE
La sentencia UPDATE se utiliza para modificar valores en una tabla.
La sintaxis de SQL UPDATE es:
UPDATE nombre_tabla
SET col_nombre_1={valor1|DEFAULT} [, col_nombre_2={valor2|DEFAULT}] [WHERE condicion]
[ORDER BY ...]
[LIMIT cantidad_filas]La cláusula SET establece los nuevos valores para las columnas indicadas.
La cláusula WHERE sirve para seleccionar las filas que queremos modificar.
Ojo: Si omitimos la cláusula WHERE, por defecto, modificará los valores en todas las filas de la tabla.
-
Ejemplo: Si quisiéramos editar una determinada película para cambiar su duración y definir que la misma está disponible para ser programada:
UPDATE Pelicula
SET disponible=1, duracion=160
WHERE id_pelicula=4;DELETE
La sentencia DELETE sirve para borrar filas de una tabla.
La sintaxis de SQL DELETE es:
DELETE FROM nombre_tabla [WHERE condicion] [ORDER BY ...]
[LIMIT cantidad_filas]Si queremos borrar todos los registros o filas de una tabla, se utiliza la sentencia:
DELETE * FROM nombre_tabla;-
Las filas se eliminan explícitamente sólo de una tabla a la vez. Sin embargo, la eliminación se puede propagar a filas de otras tablas si se han especificado opciones de acciones referenciales en las restricciones de integridad referencial del DDL.
-
En función del número de filas seleccionadas por la condición de la cláusula WHERE, ninguna, una o varias filas pueden ser eliminadas por un solo comando DELETE.
-
La ausencia de una cláusula WHERE significa que se borrarán todas las filas de la relación; sin embargo, la tabla permanece en la base de datos, pero vacía. Debemos utilizar el comando DROP TABLE para eliminar la definición de la tabla.
-
Ejemplo: Si quisiéramos eliminar todas aquellas películas estrenadas en años anteriores a 1990 podríamos ejecutar la siguiente sentencia:
DELETE FROM Pelicula
WHERE anio_estreno <1990;Ejemplo
/*
Crear BD
*/
CREATE DATABASE IF NOT EXISTS pruebas;
USE pruebas;
/*
Crear tabla
*/
CREATE TABLE tblUsuarios (
idx INT PRIMARY KEY AUTO_INCREMENT,
usuario VARCHAR(20),
nombre VARCHAR(20),
sexo VARCHAR(1),
nivel TINYINT,
email VARCHAR(50),
telefono VARCHAR(20),
marca VARCHAR(20),
compañia VARCHAR(20),
saldo FLOAT,
activo BOOLEAN
);
INSERT INTO tblUsuarios
VALUES
('1','BRE2271','BRENDA','M','2','brenda@live.com','655-330-5736','SAMSUNG','IUSACELL','100','1'),
('2','OSC4677','OSCAR','H','3','oscar@gmail.com','655-143-4181','LG','TELCEL','0','1'),
('3','JOS7086','JOSE','H','3','francisco@gmail.com','655-143-3922','NOKIA','MOVISTAR','150','1'),
('4','LUI6115','LUIS','H','0','enrique@outlook.com','655-137-1279','SAMSUNG','TELCEL','50','1'),
('5','LUI7072','LUIS','H','1','luis@hotmail.com','655-100-8260','NOKIA','IUSACELL','50','0'),
('6','DAN2832','DANIEL','H','0','daniel@outlook.com','655-145-2586','SONY','UNEFON','100','1'),
('7','JAQ5351','JAQUELINE','M','0','jaqueline@outlook.com','655-330-5514','BLACKBERRY','AXEL','0','1'),
('8','ROM6520','ROMAN','H','2','roman@gmail.com','655-330-3263','LG','IUSACELL','50','1'),
('9','BLA9739','BLAS','H','0','blas@hotmail.com','655-330-3871','LG','UNEFON','100','1'),
('10','JES4752','JESSICA','M','1','jessica@hotmail.com','655-143-6861','SAMSUNG','TELCEL','500','1'),
('11','DIA6570','DIANA','M','1','diana@live.com','655-143-3952','SONY','UNEFON','100','0'),
('12','RIC8283','RICARDO','H','2','ricardo@hotmail.com','655-145-6049','MOTOROLA','IUSACELL','150','1'),
('13','VAL6882','VALENTINA','M','0','valentina@live.com','655-137-4253','BLACKBERRY','AT&T','50','0'),
('14','BRE8106','BRENDA','M','3','brenda2@gmail.com','655-100-1351','MOTOROLA','NEXTEL','150','1'),
('15','LUC4982','LUCIA','M','3','lucia@gmail.com','655-145-4992','BLACKBERRY','IUSACELL','0','1'),
('16','JUA2337','JUAN','H','0','juan@outlook.com','655-100-6517','SAMSUNG','AXEL','0','0'),
('17','ELP2984','ELPIDIO','H','1','elpidio@outlook.com','655-145-9938','MOTOROLA','MOVISTAR','500','1'),
('18','JES9640','JESSICA','M','3','jessica2@live.com','655-330-5143','SONY','IUSACELL','200','1'),
('19','LET4015','LETICIA','M','2','leticia@yahoo.com','655-143-4019','BLACKBERRY','UNEFON','100','1'),
('20','LUI1076','LUIS','H','3','luis2@live.com','655-100-5085','SONY','UNEFON','150','1'),
('21','HUG5441','HUGO','H','2','hugo@live.com','655-137-3935','MOTOROLA','AT&T','500','1');Ejemplos de consultas
- Listar los nombres de los usuarios
- Calcular el saldo máximo de los usuarios de sexo “Mujer”
- Listar nombre y teléfono de los usuarios con teléfono NOKIA, BLACKBERRY o SONY
- Contar los usuarios sin saldo o inactivos
- Listar el login de los usuarios con nivel 1, 2 o 3
- Listar los números de teléfono con saldo menor o igual a 300
- Calcular la suma de los saldos de los usuarios de la compañia telefónica NEXTEL
- Contar el número de usuarios por compañía telefónica
- Contar el número de usuarios por nivel
- Listar el login de los usuarios con nivel 2
- Mostrar el email de los usuarios que usan gmail
- Listar nombre y teléfono de los usuarios con teléfono LG, SAMSUNG o MOTOROLA
Soluciones
# Listar los nombres de los usuarios
SELECT nombre FROM tblUsuarios;
# Calcular el saldo máximo de los usuarios de sexo "Mujer"
SELECT MAX(saldo) FROM tblUsuarios WHERE sexo = 'M';
#Listar nombre y teléfono de los usuarios con teléfono NOKIA, BLACKBERRY o SONY
SELECT nombre, telefono FROM tblUsuarios WHERE marca IN('NOKIA', 'BLACKBERRY', 'SONY');
#Contar los usuarios sin saldo o inactivos
SELECT COUNT(*) FROM tblUsuarios WHERE NOT activo OR saldo <= 0;
#Listar el login de los usuarios con nivel 1, 2 o 3
SELECT usuario FROM tblUsuarios WHERE nivel IN(1, 2, 3);
#Listar los números de teléfono con saldo menor o igual a 300
SELECT telefono FROM tblUsuarios WHERE saldo <= 300;
#Calcular la suma de los saldos de los usuarios de la compañia telefónica NEXTEL
SELECT SUM(saldo) FROM tblUsuarios WHERE compañia = 'NEXTEL';
#Contar el número de usuarios por compañía telefónica
SELECT compañia, COUNT(*) FROM tblUsuarios GROUP BY compañia;
#Contar el número de usuarios por nivel
SELECT nivel, COUNT(*) FROM tblUsuarios GROUP BY nivel;
#Listar el login de los usuarios con nivel 2
SELECT usuario FROM tblUsuarios WHERE nivel = 2;
#Mostrar el email de los usuarios que usan gmail
SELECT email FROM tblUsuarios WHERE email LIKE '%gmail.com';
#Listar nombre y teléfono de los usuarios con teléfono LG, SAMSUNG o MOTOROLA
SELECT nombre, telefono FROM tblUsuarios WHERE marca IN('LG', 'SAMSUNG', 'MOTOROLA');Modelo de persistencia
Al desarrollar una aplicación bajo el Modelo de Objetos todas nuestras entidades residen en memoria principal, donde sus relaciones se expresan como punteros que indican la posición de memoria donde encontrar el objeto vinculado.
El problema surge debido a que la memoria principal es limitada y es necesario poder almacenar los objetos en un medio que permita recuperarlos en cualquier momento futuro independientemente de la ejecución del programa (concepto que llamaremos persistencia).
Para solucionar este problema es que hacemos uso de las bases de datos relacionases, donde la información se guarda en forma de filas y columnas en tablas. Pero al comparar el modelo de objetos y el relacional surgen ciertas similitudes y diferencias:

-
Originalmente podemos establecer una equivalencia entre el concepto de Tabla/Clase, y Fila/Instancias de un objeto de esa clase. Pero más adelante empezaremos a tener ciertas dificultades para que esta asignación sea tan lineal.
-
Los objetos tienen comportamiento mientras que las tablas sólo permiten habilitar ciertos controles de integridad (constraints) o pequeñas validaciones antes o después de una actualización (triggers). Como vimos anteriormente, los procedimientos almacenados no están asociados a una tabla lo que no se corresponde con la asignación de comportamiento de los objetos.
-
Los objetos encapsulan información para favorecer la abstracción del observador. Una tabla no tiene esa habilidad; como vimos anteriormente usando las consultas SELECT podemos obtener uno, varios o todos los valores de las columnas.
-
En el modelo de objetos es posible generar Interfaces que permiten establecer un contrato entre dos partes: quien publica un determinado servicio y quien lo usa. En el álgebra relacional la interfaz no se convierte en ninguna entidad.
-
La Herencia es una relación estática que se da entre clases que favorece agrupar comportamiento y atributos en común. Cuando se instancia un objeto recibimos la definición propia de la clase y de todas las superclases de las cuales hereda. En el modelo lógico de Entidad/Relación existen supertipos y subtipos, pero en la implementación física las tablas no tienen el concepto de herencia; es por eso que surge la necesidad de realizar algunas adaptaciones que se describirán en esta sección.
-
Al no existir el comportamiento en las tablas y no estar presente el concepto de interfaz no es posible aplicar el concepto de Polimorfismo en el álgebra relacional.
JDBC
JDBC
Es una API que permite la ejecución de operaciones sobre bases de datos desde el lenguaje de programación Java, independientemente del sistema operativo donde se ejecute o de la base de datos a la cual se accede, utilizando el dialecto SQL del modelo de base de datos que se utilice.
URL de la BD
La sintaxis general:
jdbc:nombre del subprotocolo:otros elementos
"jdbc:mysql://localhost:3006/empleados"
Ejemplo:
donde se utiliza el subprotocolo para seleccionar el controlador concreto para la conexión con la base de datos.
El formato del parámetro "otros" elementos depende del subprotocolo empleado.
Realización de la conexión
Lo primero es enterarse de los nombres de las clases de los controladores JDBC utilizados por el fabricante:
com.mysql.jdbc.Driver
org.postgresql.Driver
A continuación se debe encontrar la librería necesaria donde se encuentra el controlador puede ser .jar o .zip. Importar la librería al proyecto.
DriverManager es la clase responsable de la selección de los controladores de base de datos y de la creación de las conexiones pertinentes. Sin embargo, antes de que el administrador de controladores pueda activarlo, ese controlador debe estar registrado.
La forma de registrarlo:
Class.forName("com.mysql.jdbc.Driver");Una vez registrados los controladores, la base de datos se abre de la siguiente forma:
String url = "jdbc:mysql://localhost:3306/autos";
String username = "root";
String password = "asd123";
Connection conn = DriverManager.getConnection(url,username,password);El DriverManager intentará encontrar uno que use el protocolo especificado por la URL de la BD, recorriendo todos los controladores registrados en el.
Archivo de conexión
A veces resulta apropiado usar un archivo de propiedades para especificar la URL, el nombre de usuario, la contraseña y el controlador de la BD. Este podría ser el aspecto de uno de esos archivos:
jdbc.url = jdbc:mysql://localhost:3306/autos;
jdbc.username = root;
jdbc.password = asd123;
jdbc.drivers = com.mysql.jdbc.Driver;El código necesario para leer el archivo de propiedades y abrir la conexión con la BD:
Properties props = new Properties();
FileInputStream in = new FileInputStream("database.properties");
props.load(in);
in.close();
String driver = props.getProperty("jdbc.driver");
String url = props.getProperty("jdbc.url");
String username = props.getProperty("jdbc.username");
String password = props.getProperty("jdbc.password");
//establecer conexion
Connection conn = DriverManager.getConnection(url,username,password);Ejecución de comandos SQL
Para ejecutar un comando SQL primero debe crear un objeto Statement. Para ello puede utilizar el objeto Connection obtenido a partir de la llamada a DriverManager.getConnection.
Statement stat = conn.createStatement();A continuación, escriba la sentencia que quiere ejecutar en una cadena, por ejemplo:
String command = "UPDATE libros set precio = 5.0 where titulo not like 'Java'";
Y después, llame al método executeUpdate de la clase Statement:
stat.executeUpdate(command);ExecuteUpdate
- Devuelve el número de filas que han sido afectadas por el executeUpdate.
- Puede ejecutar acciones del tipo INSERT, UPDATE y DELETE, así como también comandos de definición de datos como CREATE TABLE y DROP TABLE
ExecuteQuery
- Se utiliza para lanzar consultas tipo SELECT.
- Cuando se lanza una consulta lo importantes es el resultado. El método executeQuery devuelve un objeto de tipo ResultSet que se puede utilizar para procesar filas de resultados.
ResultSet
ResultSet rs = stat.executeQuery("SELECT * FROM libros");El bucle básico para analizar un conjunto de resultados tiene este aspecto:
while(rs.next())
{
//inspeccionar una fila de resultados
}Existen métodos de este tipo para cada uno de los tipos de datos del lenguaje Java. Cada método tiene dos formas que toman distintos tipos de argumentos:
- argumento numerico: se hace referencia a la columna que se encuentra en la posición marcada por el número.
- cadena: hace referencia a la columna del conjunto de resultados que tenga ese nombre.
El uso de argumentos numéricos es un poco más eficiente, pero las cadenas hacen que el código sea más legible y fácil de entender.
String isbn = rs.getString(1);
Double precio = rs.getDouble("precio");Cuando se inspeccione una fila, querrá conocer el contenido de cada columna. Existe una gran cantidad de métodos para obtener esta información:
Tipos de datos SQL y sus equivalentes en Java
| INTEGER o INT | int |
| SMALLINT | short |
| NUMERIC(m,n), DECIMAL(m,n) | java.sql.Numeric |
| FLOAT(n) | double |
| REAL | float |
| DOUBLE | double |
| CHARACTER(n) o CHAR(n) | String |
| VARCHAR(n) | String |
| BOOLEAN | boolean |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
| BLOB | java.sql.Blob |
| CLOB | java.sql.Clob |
| ARRAY | java.sql.Array |
Sentencias Predefinidas
Considere la siguiente consulta:
SELECT * FROM libros l where l.nombreAutor = nombre;En lugar de construir una sentencia cada vez que el usuario lanza una consulta como esta, podemos prepararla con una variable y usarla muchas veces, rellenando previamente dicha variable con una cadena diferente.
Cada variable en una consulta predefinida está indicada con un carácter ?. Si existen varias de ellas, se debe tener cuidado con las posiciones de las mismas a la hora de configurar los valores. Por ejemplo:
String query = "SELECT * FROM libros l WHERE l.nombreAutor = ?";
PreparedStatement ps = conn.preparedStatement(query);Antes de ejecutar la sentencia, es necesario enlazar cada variable con su correspondiente valor a través del método set. Existen distintos tipos de set que se ajustan con cada uno de los distintos tipos de variables de datos. En este caso, queremos asignar una cadena:
ps.setString(1,nombre);Una vez que las variables se han unido con sus valores, se puede ejecutar la consulta:
ResultSet rs = ps.executeQuery();TRANSACCIONES
Transacción
Agrupar un grupo de sentencias para formar una transacción que se puede confirmar (committed) cuando todo vaya bien o deshacer (rollback) si uno de los comandos de la misma produce un error.
La principal razón para agrupar comandos en transacciones es la integridad de la BD.
Autocommit
Por defecto, una conexión a la BD esta en modo autocommit, y cada comando SQL realiza un commit a la BD tan pronto como se ejecuta. Tras esta operación no hay marcha atrás.
Para comprobar la configuración del modo autocommit actual, llame al método getAutoCommit de la clase Connection.
Para desactivar este modo:
conn.setAutoCommit(false);Después, se crea un objeto Statement como es habitual:
Statement stat = conn.createStatement();Llame a executeUpdate tantas veces como sea necesario
stat.executeUpdate(command1);
stat.executeUpdate(command2);
stat.executeUpdate(command3);
...Cuando todos los comandos han sido ejecutados llame al método commit:
conn.commit();Sin embargo, cuando se produce un error hay que llamar a:
conn.rollback();Esto provoca que todos los comandos ejecutados desde el último commit sean automáticamente invertidos. Se lanza el rollback ante un SQLException
ORM
Para acceder de forma efectiva a la base de datos relacional desde un contexto orientado a objetos, es necesaria una interfaz que traduzca la lógica de los objetos a la lógica relacional. Esta interfaz se llama ORM object-relational mapping) o "mapeo de objetos a bases de datos", y está formada por objetos que permiten acceder a los datos y que contienen en sí mismos el código necesario para hacerlo.
Ventajas
- Reutilización: permite llamar a los métodos de un objeto de datos desde varias partes de la aplicación e incluso desde diferentes aplicaciones.
- Acceso a los datos: las empresas que crean las bases de datos utilizan variantes diferentes del lenguaje SQL. Si se cambia a otro sistema gestor de bases de datos, es necesario reescribir parte de las consultas SQL que se definieron para el sistema anterior. Si se crean las consultas mediante una sintaxis independiente de la base de datos y un componente externo se encarga de traducirlas al lenguaje SQL concreto de la base de datos, se puede cambiar fácilmente de una base de datos a otra. Este es precisamente el objetivo de las capas de abstracción de bases de datos. Esta capa obliga a utilizar una sintaxis específica para las consultas y a cambio realiza el trabajo de optimizar y adaptar el lenguaje SQL a la base de datos concreta que se está utilizando.
- Portabilidad: hace posible que la aplicación cambie a otra base de datos, incluso en mitad del desarrollo de un proyecto. Si se debe desarrollar rápidamente un prototipo de una aplicación y el cliente no ha decidido todavía la base de datos que mejor se ajusta a sus necesidades, se puede construir la aplicación utilizando una base de datos sencilla orientada a prototipos y cuando el cliente haya tomado la decisión, cambiar fácilmente a un motor más completo como MySQL. Solamente es necesario modificar una línea en un archivo de configuración y todo funciona correctamente.
-
Reducir el tedioso proceso de desarrollo de sistemas de mapeo relacional de objetos: proveyendo bibliotecas de clases que son capaces de realizar mapeos automáticamente. Dada una lista de tablas en la base de datos, y objetos en el programa, ellos pueden automáticamente mapear solicitudes de un sentido a otro. Ejemplo: la consulta a un objeto persona por sus números telefónicos resultará en la creación y envío de la consulta apropiada a la base de datos, y los resultados son traducidos directamente en objetos de números telefónicos dentro del programa.
Desventajas
- En la práctica no es tan simple.
- Todos los sistemas ORM tienden a hacerse visibles en varias formas, reduciendo en cierto grado la capacidad de ignorar la base de datos.
- La capa de traducción puede ser lenta e ineficiente (comparada en términos de las sentencias SQL que escribe), provocando que el programa sea más lento y utilice más memoria que el código "escrito a mano".
Hibernate ORM
Hibernate es una herramienta de ORM para la plataforma Java que facilita el mapeo de atributos entre una base de datos relacional tradicional y el modelo de objetos de una aplicación, mediante archivos declarativos (XML) o anotaciones. Busca solucionar el problema de la diferencia entre los dos modelos de datos coexistentes en una aplicación: que se usa en la memoria de la computadora (orientación a objetos) y el utilizado en las bases de datos (modelo relacional).
Cómo?
Para lograr esto, el desarrollador puede detallar cómo es su modelo de datos, qué relaciones existen y qué forma tienen.
Esta información le permite a la aplicación:
- manipular los datos en la base de datos operando sobre objetos, con todas las características de la POO.
- convertir los datos entre los tipos utilizados por Java y los definidos por SQL
- genera las sentencias SQL y libera al desarrollador del manejo manual de los datos que resultan de la ejecución de dichas sentencias, manteniendo la portabilidad entre todos los motores de bases de datos con un ligero incremento en el tiempo de ejecución.
El archivo de configuración
Para poder indicar a Hibernate cuales son los datos de la conexión a nuestra base de datos, tales como el usuario y la contraseña y demás parámetros de configuración necesitamos el archivo XML hibernate.cfg.xml.
XML proviene de eXtensible Markup Language (“Lenguaje de Marcas Extensible”). Se trata de un metalenguaje (un lenguaje que se utiliza para decir algo acerca de otro) extensible de etiquetas que fue desarrollado por el Word Wide Web Consortium (W3C), una sociedad mercantil internacional que elabora recomendaciones para la World Wide Web. Las bases de datos, los documentos de texto, las hojas de cálculo y las páginas web son algunos de los campos de aplicación del XML. El metalenguaje aparece como un estándar que estructura el intercambio de información entre las diferentes plataformas.
A continuación, se muestra un ejemplo básico del archivo de configuración, que deberá ubicarse en la carpeta src/main/resources relativa a la raiz del proyecto:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" “http://www.hibernate.org/dtd/hibernate- configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/poo-cine </property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
</session-factory>
</hibernate-configuration>
- sección hibernate-configuration que posee una subsección llamada session-factory que es donde colocaremos todas las propiedades de la configuración, tales como la ruta de configuración a nuestra base de datos y las credenciales de autenticación.
- propiedad hibernate.dialect especifica que versión del lenguaje SQL se usará para confeccionar las consultas a la base de datos; en este caso en particular le indicamos que optimice las consultas para MySQL.
- propiedad hibernate.connection.driver_class especifica que clase será la encargada de proveer el acceso a la base de datos, es decir quién será el encargado de enviar las consultas SQL al motor de base de datos y entregar la respuesta a nuestra aplicación; en este caso en particular utilizamos el controlador de JDBC de MySQL.
- propiedad hibernate.connection.url indica la ruta de conexión a la base de datos, es decir cuál será el protocolo de conexión, la IP del host en donde se encuentra instalado el servidor de bases de datos, el nombre de la base de datos a conectarnos, entre otras opciones de conexión. Su sintaxis es la siguiente: jdbc:mysql://host:puerto/database jdbc:mysql://host:puerto/database?user=usuario&password=clave
-
Otras propiedades útiles para el archivo de configuración son show_sql y format_sql que pueden recibir valores true o false y permiten mostrar en tiempo de ejecución las consultas SQL que Hibernate genera para obtener los datos de la base de datos.
Una vez creado el archivo de configuración es necesario obtener una instancia de la clase SessionFactory, que es la que nos proveerá acceso a la Session actual de Hibernate, clase que es encargada de procesar todos nuestros pedidos de mapeo. Para obtener una instancia de esta clase debemos ejecutar el siguiente bloque de código:
final StandardServiceRegistry registry = new StandardServiceRegistryBuilder()
.configure() // obtiene los valores de hibernate.cfg.xml
.build();
try {
SessionFactory sessionFactory = new MetadataSources(registry ).buildMetadata().buildSessionFactory();
}
catch (Exception e) {
// La variable registry será destruída al crear el SessionFactory,
// pero como han surgido problemas en el proceso de creación lo hacemos manualmente
StandardServiceRegistryBuilder.destroy(registry );
}
Este proceso sólo debe realizarse una vez para toda la aplicación al inicio de la ejecución, luego todos nuestros elementos de la capa de acceso a datos DAO (Data Access Object) harán uso de la SessionFactory anterior para pedir servicios de mapeo a Hibernate.
Luego en cualquier método de nuestra capa de acceso a datos podemos obtener una instancia de sesión para comunciarnos con Hibernate de la siguiente forma:
Session session = sessionFactory.openSession();
session.beginTransaction();
// nuestro código de operaciones con Hibernate
session.getTransaction().commit();
session.close();¿Qué hace sessionFactory.getCurrentSession()? Primero, la puede llamar tantas veces como desee y en donde quiera, una vez consiga su org.hibernate.SessionFactory. El método getCurrentSession() siempre retorna la unidad de trabajo "actual". Es importante notar el llamado al método close() luego de realizar las operaciones con Hibernate para poder liberar los recursos reservados al momento de la ejecución.
Una org.hibernate.Session se inicia cuando se realiza la primera llamada a getCurrentSession() para el hilo actual, es decir para la sesión actual. Luego Hibernate la vincula al hilo actual. Cuando termina la transacción, ya sea por medio de guardar o deshacer los cambios, Hibernate desvincula automáticamente la org.hibernate.Session del hilo y la cierra por usted. Si llama a getCurrentSession() de nuevo, obtiene una org.hibernate.Session nueva y obtiene una nueva org.hibernate.Session unidad de trabajo.
Title Text
- Bullet One
- Bullet Two
- Bullet Three
Ejercicio 1
a- Elaborar un programa de consola desde donde se accede a una Base de Datos "banco" ya registrada con mySql, que contiene la tabla "clientes" con los campos "numCuenta, nombre, fechaActivacion y saldo", para una serie de clientes.
El programa se conectará con esta BD y realizará una serie de consultas a ésta mediante un menú de opciones.
Las opciones serán:
-
Mostrar todos los datos
-
Mostrar los clientes con saldo mayor a $100.000
-
Obtener el saldo promedio de todos los clientes
-
Mostrar datos de un determinado cliente
b- Implementar una capa de datos con el Modelo Cliente. Para mostrar usar el toString
Ejercicio 2, 3 y 5
A la base de datos de banco, agregar las siguientes tablas con las siguientes relaciones:

Los tipos de movimiento pueden ser:
1-Transferencia
2- Compra
2- Venta
Ejercicio 2
Crear una aplicación de escritorio que permita almacenar una nueva cuenta en la base de datos siempre y cuando el código de la cuenta no este ya en la base de datos. En este ejemplo se usan PreparedStatements.

Ejercicio 3
Crear una aplicación web que sirva para hacer transferencias entre las cuentas. Con este ejemplo vamos a aprovechar para ver como crear transacciones y deshacerlas si falla alguna de las operaciones. En este ejemplo se usan statement para ver lo tedioso que puede ser.

Ejercicio 4
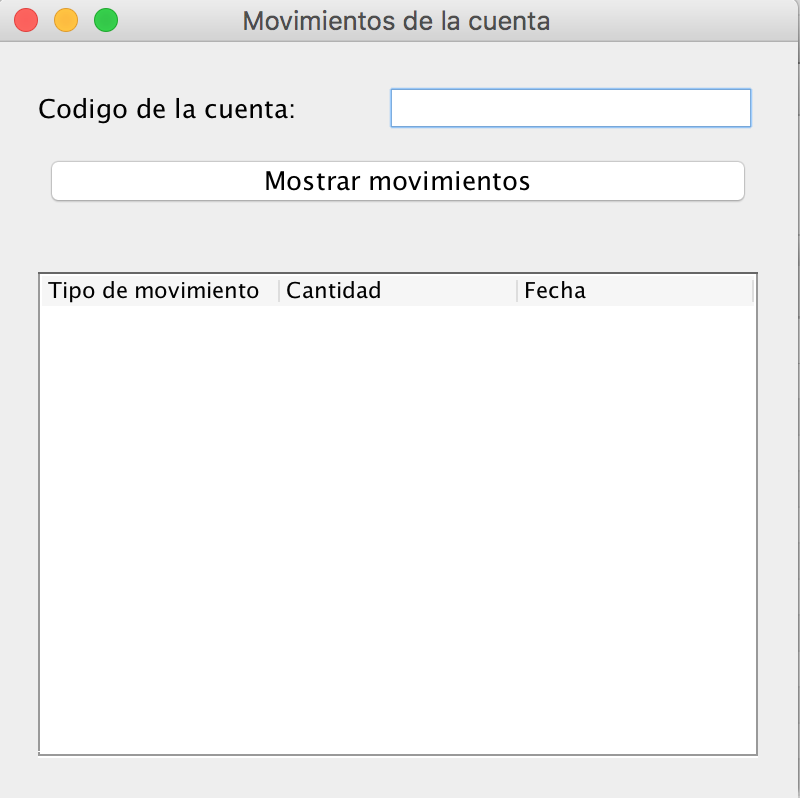
Crear una aplicación de escritorio que muestra la lista de operaciones realizadas sobre una cuenta y para ver algo nuevo los datos de la consulta se obtienen de dos tablas distintas usando un join, aunque esto es cosa del sql y para la parte java no hay nada distinto y vamos recorrer los datos del resulset obtenidos de la consulta para mostrarlos en una tabla.
Curso Java Experto Clase 6
By Marina Garcia




