Data Mining Pipeline
Making Meaning from Data
Tables
Hypercubes
Metacube
Tables
Goals
- Data mining tables aggregate information from many feature tables to provide insight or answer a question
- Data mining tables are used to create hypercubes for analyzing experiments
Features
- Data mining tables do not affect the recommendation system in production
- Data mining tables are used for analysis of features during a sliding 90-day timeframe
Tables in Production
dm_course_consumption
dm_user_persona
dm_course_interest
dm_visitor_experiment
dm_query_course_performance
dm_query_performance
dm_top_query_performance
dm-course_performance
dm_search_position
dm_visitor_enrollment
dm_visitor_engagement
dm_subcat_interest
dm_course_performance
This table provides a way to analyze course performance across several metrics over a 90-day time period. A feature hypercube is created from this table, which is then used for the experiment hypercube.
CREATE TABLE dm_course_performance (
courseid bigint,
num_visitors int,
course_epmv int,
course_bpmv int,
course rpmv int,
course_bpe int,
course_rpe int )
PARTITIONED BY (datestamp date)
Extract
Transform
Load
Title Text
Hypercubes
Goals
- Hypercubes allow slicing, or dimension reduction
- Hypercubes allow drill-up/drill down; you can analyze one dimension or increase complexity by examining interaction between many dimensions
- Hypercubes allow roll up; you can summarize across one dimension
Features
- Hypercubes can be configured on the fly (CLI) or in a more permanent fashion (hypercubes.py)
- Hypercubes are self-building
- Hypercube queries are optimized for performance
- Hypercubes are shareable and can be combined
Experiment Hypercubes
course_interest
purchaser_type
success_subcontext
course_enrollment
avg_minconsumed_1wk
persona
featured_subcontext
course_epmv
course_bpe
context_type
avg_npsbp_1wk
subcat_interest
totals
denominator
Hypercube Components
- Hypercube map
- Hypercube core
- Feature Hypercube
- Experiment Hypercube
feature
feature
feature
feature
feature
feature
experiment hypercube
hypercube map
feature_map['course_epmv'] = {
'table': 'dm_course_performance',
'field': 'course_epmv',
'type': 'int',
'binning': {
'null_value': '8',
'values': ['1', '4', '8', '16', '32'],
'default_value': '64'
}}
feature_map['course_bpmv'] = {
'table': 'dm_course_performance',
'field': 'course_bpmv',
'type': 'int',
'binning': {
'null_value': '4',
'values': ['1', '2', '4', '8', '16', '32'],
'default_value': '64'
}}
CREATE TABLE dm_hypercube_re_19074_course_epmv_visitorid_prod (
variant varchar(255),
days_since_last_visit int,
path_type varchar(64),
path_topology varchar(64),
datestamp date,
visitorid bigint,
course_epmv int,
impressions int,
views int,
enrolled int,
revenue float,
minconsumed_1wk int,
nps_flag_1wk int,
nps_1wk int
)
INSERT INTO dm_hypercube_re_19074_course_epmv_visitorid_prod
SELECT variant, days_since_last_visit, path_type, path_topology, datestamp, visitorid, course_epmv, sum(impressions), sum(views), sum(enrolled), sum(revenue), sum(minconsumed_1wk), sum(nps_flag_1wk), sum(nps_1wk)
FROM (SELECT
vv.variant variant,
CASE WHEN vg.days_since_last_visit IS NULL THEN 0
WHEN vg.days_since_last_visit<=7 THEN 7
WHEN vg.days_since_last_visit<=14 THEN 14
WHEN vg.days_since_last_visit<=30 THEN 30
WHEN vg.days_since_last_visit<=91 THEN 91
ELSE 0 END days_since_last_visit,
CASE WHEN vp.path_type IS NULL THEN 'other'
ELSE vp.path_type END path_type,
CASE WHEN vp.path_topology IS NULL THEN 'other'
ELSE vp.path_topology END path_topology,
mf.datestamp datestamp, mf.visitorid visitorid,
CASE WHEN cp.course_epmv IS NULL THEN 8
WHEN cp.course_epmv<=1 THEN 1
WHEN cp.course_epmv<=4 THEN 4
WHEN cp.course_epmv<=8 THEN 8
WHEN cp.course_epmv<=16 THEN 16
WHEN cp.course_epmv<=32 THEN 32
ELSE 64 END course_epmv,
markedasseen_flag impressions, islanded_flag views, enrolled enrolled, booking revenue,
minconsumed_1wk minconsumed_1wk, nps_flag_1wk nps_flag_1wk, nps_1wk nps_1wk
FROM impression_funnel mf
LEFT OUTER JOIN dm_hypercube_visitor_variant_re_19074_prod vv ON
vv.visitorid=mf.visitorid AND vv.datestamp=mf.datestamp
LEFT OUTER JOIN dm_visitor_engagement vg ON
vg.visitorid=mf.visitorid AND vg.datestamp=mf.datestamp
LEFT OUTER JOIN visitor_path vp ON
vp.visitorid=mf.visitorid AND vp.datestamp=mf.datestamp
LEFT OUTER JOIN dm_course_performance cp ON
cp.courseid=mf.courseid AND cp.datestamp=mf.datestamp
WHERE mf.datestamp BETWEEN '2021-01-01' AND '2022-01-01'
) x
GROUP BY variant, days_since_last_visit, path_type, path_topology, datestamp, visitorid, course_epmv;
Metacube
Overview
The metacube combines all of the experiment hypercubes into one table for uploading to redshift, for use in Tableau, R, & Chartio.
experiment
hypercube
experiment
hypercube
experiment
hypercube
experiment
hypercube
metacube
CREATE TABLE dm_recommendation_experiment_metacube_prod (
dimension_name string,
dimension_value string,
visitor_days int,
variant varchar(255),
days_since_last_visit int,
path_type varchar(64),
path_topology varchar(64),
datestamp date,
impressions int,
views int,
enrolled int,
revenue float,
minconsumed_1wk int,
nps_flag_1wk int,
nps_1wk int,
impressions_2 int,
views_2 int,
enrolled_2 int,
revenue_2 float,
minconsumed_1wk_2 int,
nps_flag_1wk_2 int,
nps_1wk_2 int
)
PARTITIONED BY (experiment bigint, component_id varchar(10), hashing_variable varchar(10));
Experiment Workbook
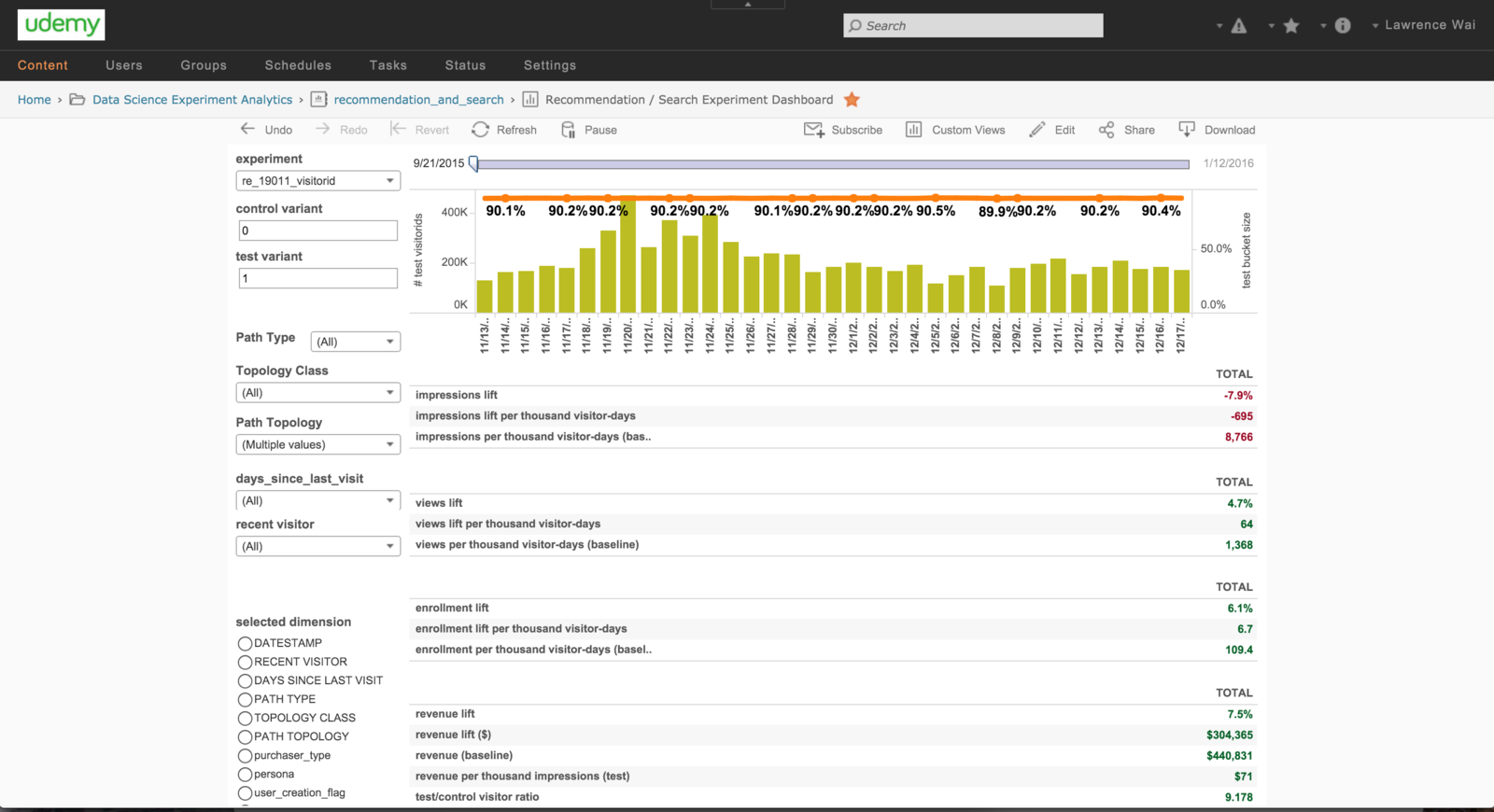
deck
By marswilliams



