|
RAZVOJ METODOLOGIJE ZA AVTOMATIČNO KLASIFIKACIJO ELEKTRONSKIH PUBLIKACIJ V UNIVERZALNO DECIMALNO KLASIFIKACIJO - UDK |
Matjaž Kragelj, študent
dr. Mirjana Kljajić Borštnar, mentorica
Digitalna knjižnica Slovenije (2006-2008)

- kopija publikacij na dLib.si ali
- vsebina namesto originalnega portala
- povečevanje števila partnerjev
- največja porast števila/količine
publikacij na dLib.si
- začetek arhiviranja v repozitorij
po shemi OAIS
Ne dosti kasneje (2008-2011)
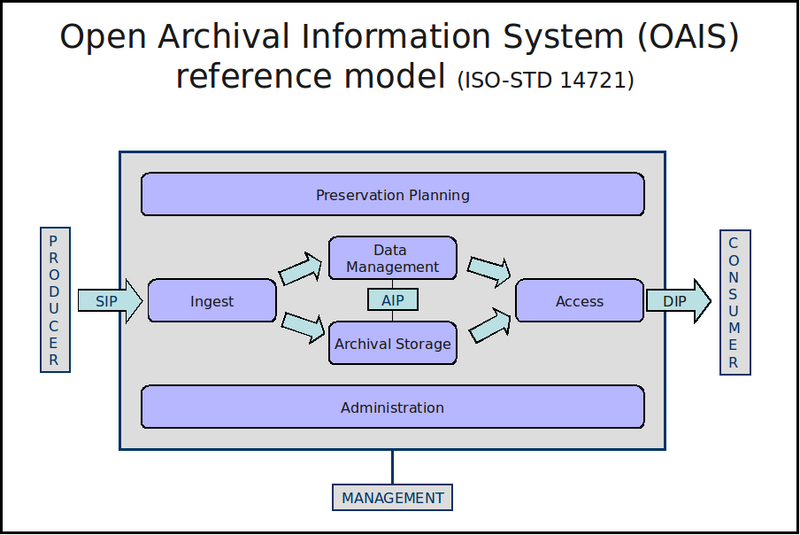
image: https://wiki.archivematica.org
- arhivska kopija se pošlje v repozitorij (Fedora commons)
- ogledna kopija dostopna javnosti/uporabnikom
- metapodatki (arhiv + javni dostop)
OAIS - Open Archival Information System
Avtomatizacija digitalizacije
- 1995 - 2015 (Zunanji izvajalci digitalizacije)
- priprava tehničnih dokumentacij
- pogodbe, javna naročila
- prevzemi, zapisniki, pregledi, popravki,...
- 2015 - 2020 (Zunanji izvajalci + digitalizacija znotraj NUK)
- nabava strojne opreme
- razvoj programske opreme
- 30-50% digitalizacije "in house"
- 2021 - (Večina digitalizacije "in house")
Avtomatizacija digitalizacije

Avtomatizacija digitalizacije
Avtomatizacija digitalizacije
Avtomatizacija digitalizacije
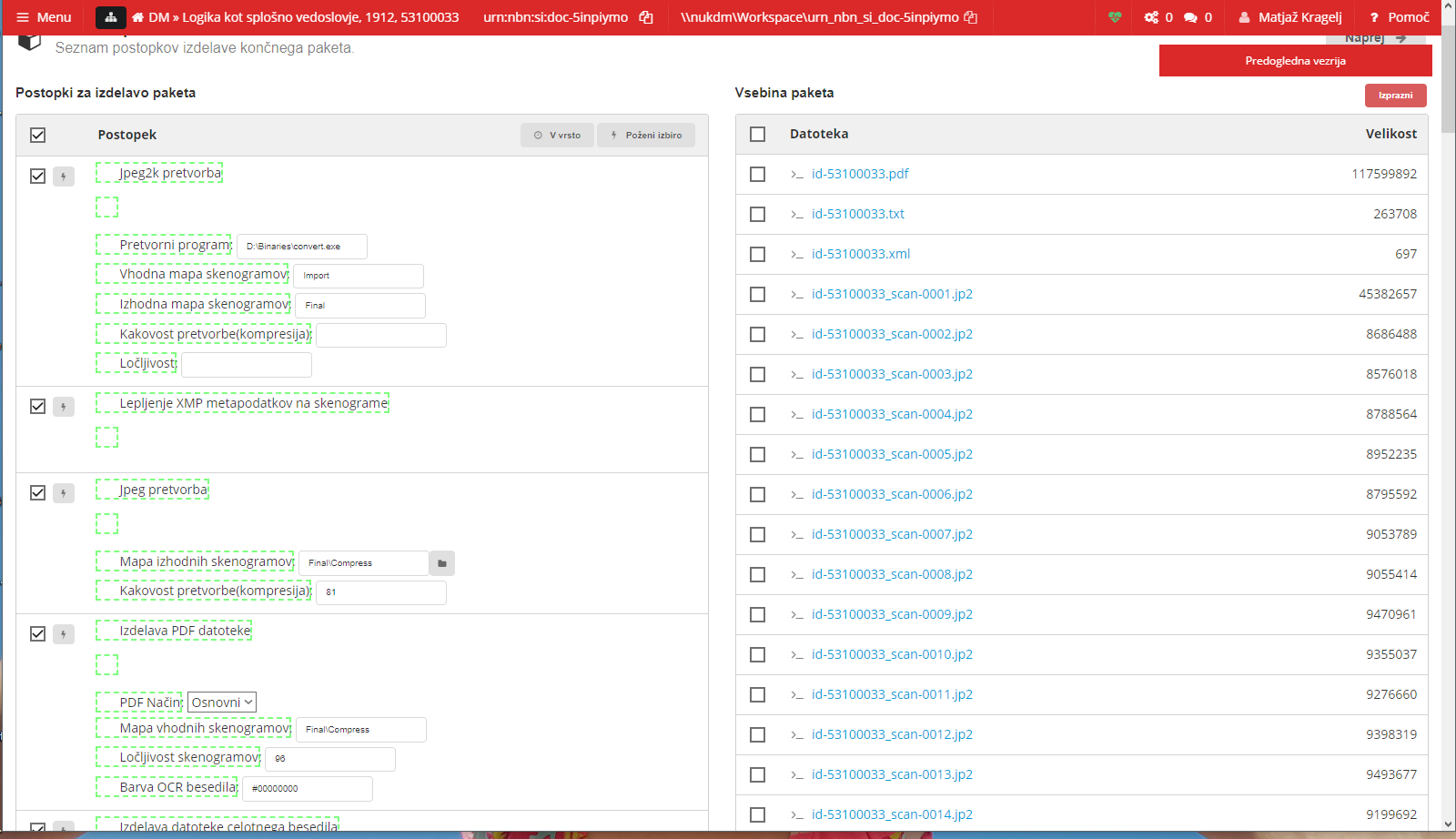
- predstavitev zgolj z (meta)podatki
Vizualizacija podatkov....brez!
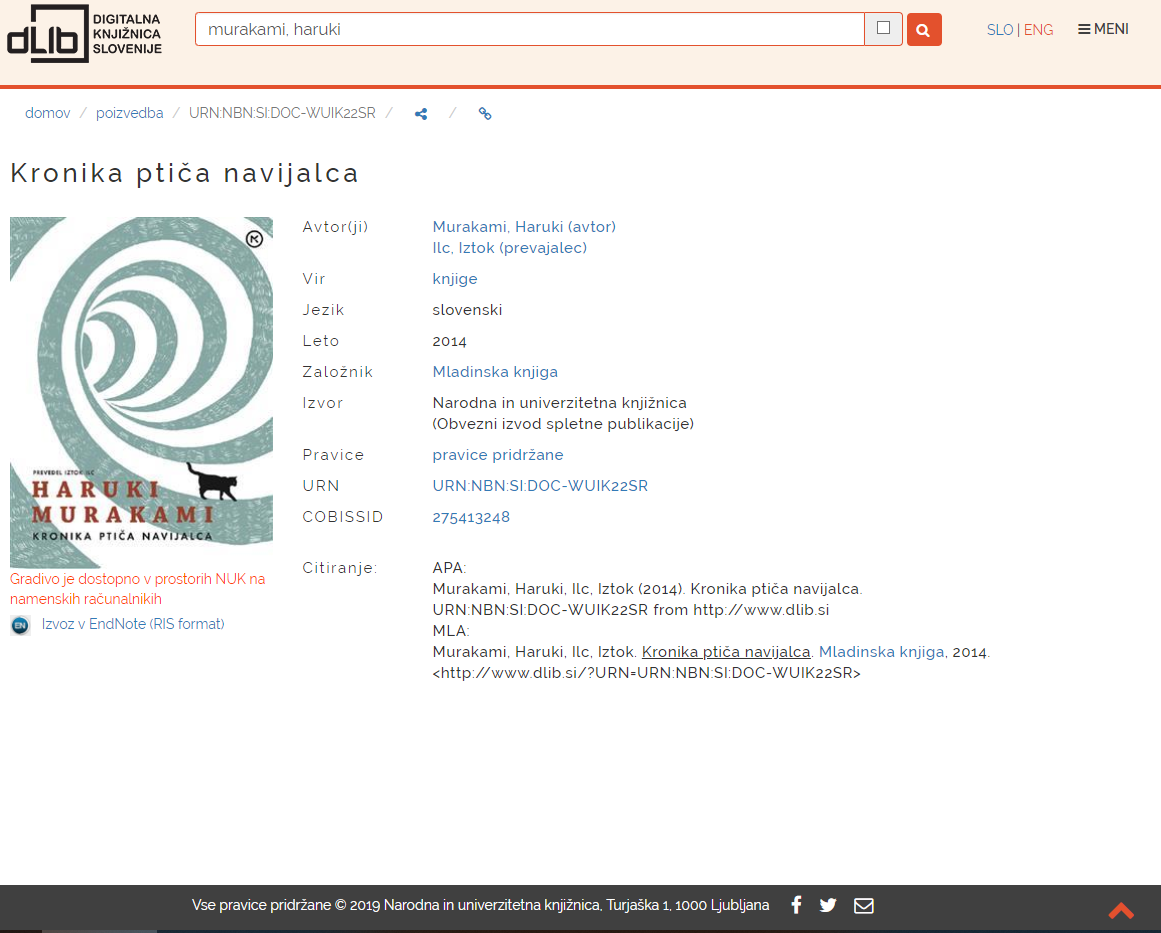
- graf: publikacija / avtorji
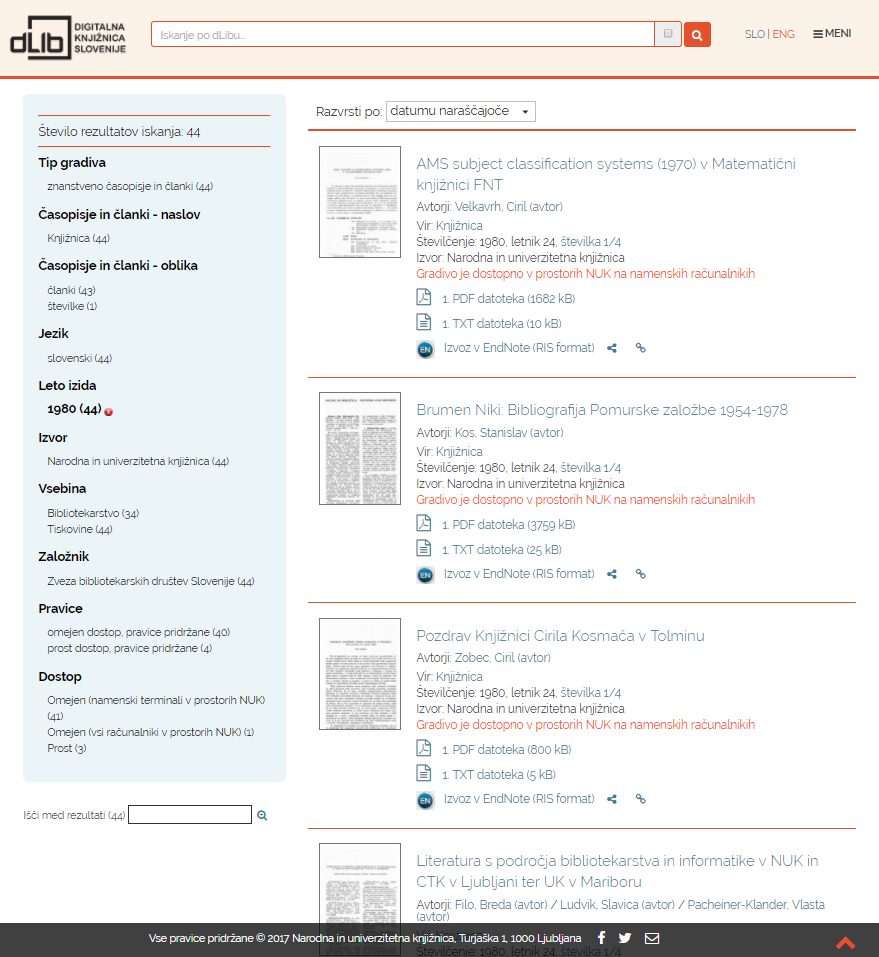
- uporabniški vmesnik
Vizualizacija podatkov: publikacije - avtorji
https://www.nuk.uni-lj.si/d3/test/knjiznica_1980.html
- graf: oznake vsebine / naslovi
Vizualizacija podatkov: predmetne oznake - naslovi
Podatkovno rudarjenje
Analiza teksta vključuje iskanje informacij, leksikovno analizo za proučevanje razdelitve frekvence besed, prepoznavanje vzorcev, označevanje, ekstrakcijo informacij, tehnike preiskovanja podatkov, z vključevanjem povezav, vizualizacijo in prediktivno analizo.
- proces pridobivanja visokokvalitetnih informacij iz teksta
- Knjižno gradivo predstavlja enega od temeljev naše kulturne dediščine
-
Digitalna knjižnica Slovenije vsebuje več kot 840.000 enot publikacij
- 70% vseh elektronskih publikacij dostopnih na portalu Digitalne knjižnice Slovenije (www.dlib.si) ni bibliografsko obdelanih
-
Za te publikacije - iskanje mogoče samo po naslovu, številki in polnem besedilu
-
S pomočjo text mininga je moč ustvariti klasifikacijo, fasete oz. filtre,..
Podatkovno rudarjenje - dLib.si
Podatkovno rudarjenje - dLib.si (UDK)
Univerzalna decimalna klasifikacija (UDK) :
Obsegajo sistematično ureditev vseh področij človeškega znanja. Celotno človeško vedenje je razporejeno v deset glavnih skupin, ki so označene s številkami od 0 do 9
Vanj se lahko vgrajujejo vrstilci za nova znanja. Vrstilci so neodvisni od jezika ali pisave in so sestavljeni iz arabskih številk ter sprejetih znakov
Trenutno preveden v 51 jezikov
0 Znanost in znanje. Organizacije. Informacije. Dokumentacija. Bibliotekarstvo. Institucije. Publikacije 1 Filozofija. Psihologija 2 Teologija. Verstva 3 Družbene vede. Politika. Ekonomija. Pravo. Izobraževanje 5 Matematika. Narovoslovje 6 Uporabne znanosti. Medicina. Tehnika 7 Umetnost. Arhitektura. Fotografija. Glasba. Šport 8 Jezik. Književnost 9 Geografija. Biografija. Zgodovina
Podatkovno rudarjenje (primeri gradiva)
- Laibacher Zeitung (časopis) – 58.500+ številk
- Ljubljanski Zvon (časnik) – 11.000+ člankov
- Dom in svet (literarni mesečnik) – 16.000+ člankov
UDK= 821.163.6 --> Slovenska književnost
UDK= 008(497.4)"18/19“ --> Jezik, književnost (Slovenija) 18XX-19XX.
ZA VSE TRI „časopise“ velja: zgolj en zapis v knjižničnem katalogu COBISS za vse pripadajoče publikacije časopisa
Podatkovno rudarjenje (primeri gradiva)
Text

Podatkovno rudarjenje (primeri gradiva)
Text

Podatkovno rudarjenje
HIPOTEZA:
Ali lahko (s pomočjo metod strojnega učenja) z verjetnostjo vsaj 0.8,
za vsako naključno publikacijo, ki vstopa v sistem, pozitivno potrdimo avtomatsko dodeljen vsaj en primeren UDK vrstilec?



Podatkovno rudarjenje
STRUKTURA PUBLIKACIJ na dLib.si
(časovna komponenta - leto nastanka)
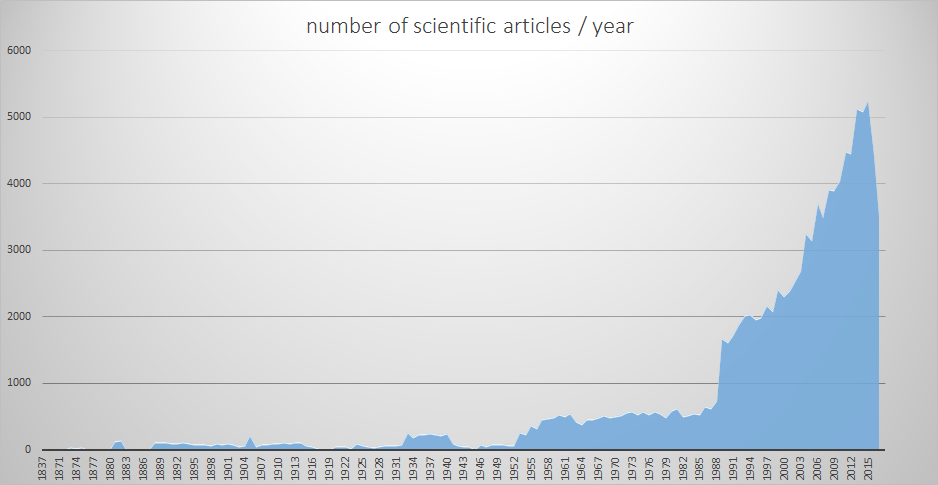
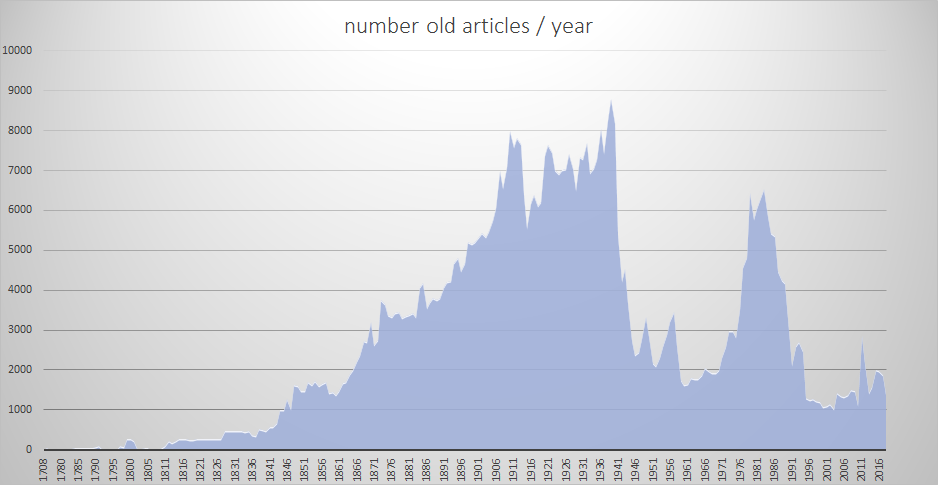
znanstveno časopisje
cca. 70.000 enot
staro časopisje
90% celotnega dLib.si
Podatkovno rudarjenje - raziskava
V prvi iteraciji se ukvarjamo z znanstvenimi besedili,
v drugi s starimi članki.
POTEK RAZISKAVE po fazah:
1) Izbor podatkov ( MSSQL, izbor člankov, URN, naslov, UDK-ji, Full-text)
2) Izvoz podatkov (export metapodatkov in polnega besedila v .json)
3) Priprava podatkov (čiščenje, lematizacija)
4) Pretvorba besedil v vektorje (doc2vec, tfidfVectorizer)
5) Strojno učenje (nadzorovano, nenadzorovano)
6) Analiza rezultatov
Podatkovno rudarjenje - raziskava
1,2) Izbor in izvoz podatkov
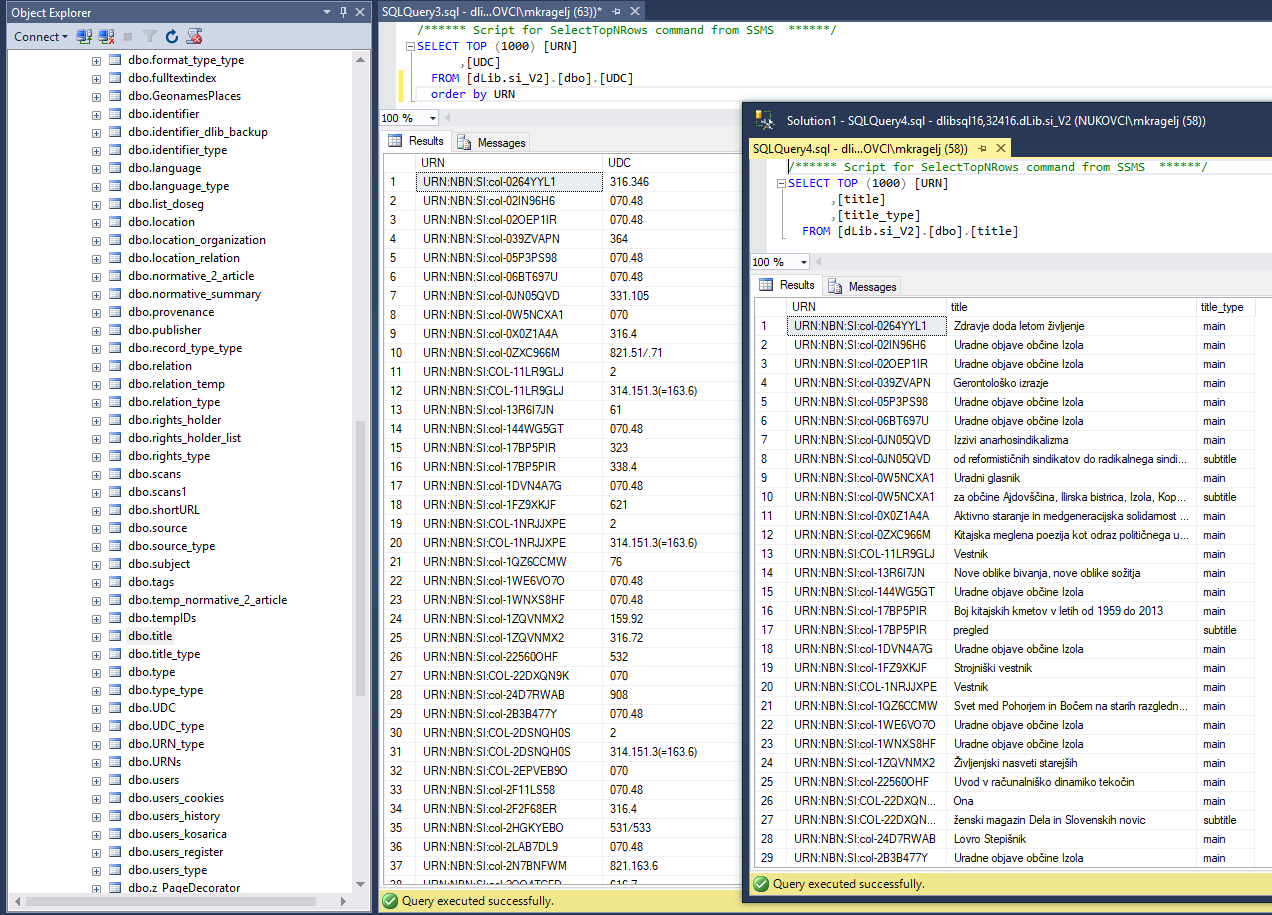
Podatkovno rudarjenje - raziskava
1,2) Izbor in izvoz podatkov
Text
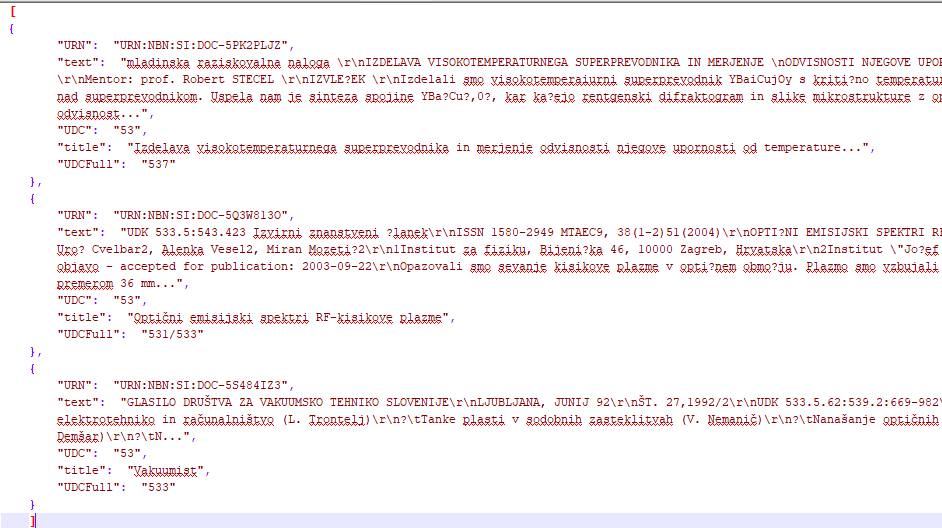
3) čiščenje, lematizacija
čebel, čebela, čebelah, čebelam, čebelama, čebelami, čebele, čebeli, čebelo, bčela, zhbele, zhebela, zhebelle, zhebéla, zhebéle, bzhéla, bčela, bčela, bčele, zhbel, zhbelam, zhbelami, zhbele, zhebelam, zhebelam, zhebéla, zhebéle, zhebęla, zhebęli, čebele, čbela, čbele, čbéla, čbéla, čebel, čebelami, čebele
čebelar, čebelarja, čebelarje, čebelarjem, čebelarjema, čebelarjev, čebelarji, čebelarjih, čebelarju, zhbelar, zhbelarja, zhbelarjam, zhbelarjev, zhbelarji
- umikanje stop-words
- lematizacija (korenjenje)
- upraba slovarjev (staro besedišče)
4) Tokenizacija in vektorizacija v TF-IDF
term frequency–inverse document frequency

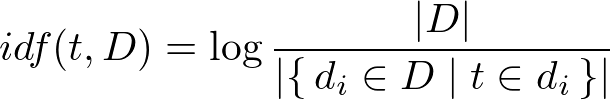
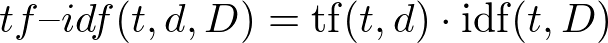
https://medium.com/@MSalnikov/text-clustering-with-k-means-and-tf-idf-f099bcf95183
Podatkovno rudarjenje - raziskava
Algoritem razdeli dane vhodne podatke, po svojih kriterijih, v več kategorij, ki imajo svoje značilnosti. To se imenuje rojenje (clustering). Število kategorij in njihove značilnosti izlušči algoritem iz vhodnih podatkov, brez nadzora učitelja.
Nenadzorovano učenje (unsupervised learning):
odkrivanje zakonitosti učnih primerov.
Vprašanje:
- ali lahko primere razdelimo v smiselne skupine?
CILJ:
Podatkovno rudarjenje - raziskava
Nenadzorovano učenje (clustering, k-means)
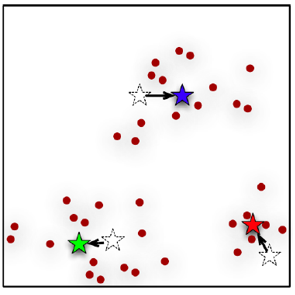
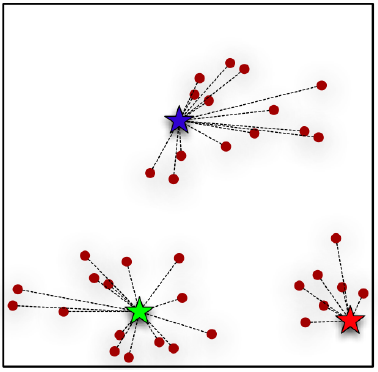
https://bigdata-madesimple.com/possibly-the-simplest-way-to-explain-k-means-algorithm/
k-means je iterativni algoritem. Deluje v dveh korakih
- vsaki točki dodeli gručo (glede na najbližji centroid)
- premik centroida na povprečje (center) točk v gruči
k=število gruč
Podatkovno rudarjenje - raziskava
Nenadzorovano učenje (clustering, k-means)
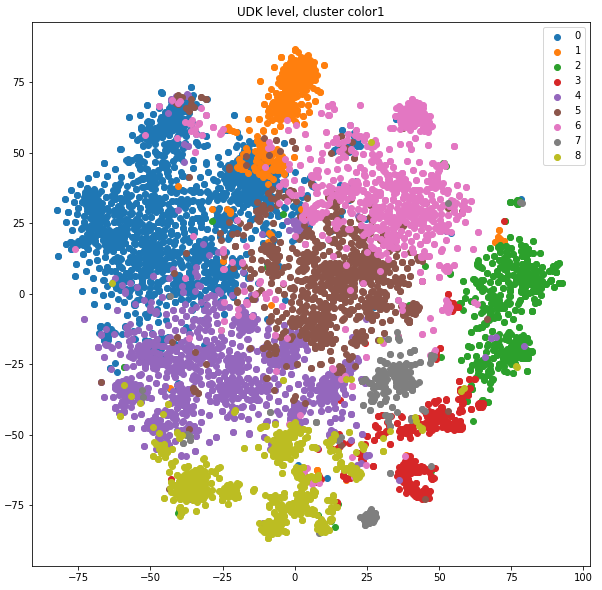
- znanstvena besedila
- UDK določen v metapodatkih
- iščemo UDK na nivoju 1
- k-means (k=9)
Podatkovno rudarjenje - raziskava
Nenadzorovano učenje (clustering, k-means)
- znanstvena besedila
- UDK določen v metapodatkih
- iščemo UDK na nivoju 2
- k-means (k=?) zakaj?
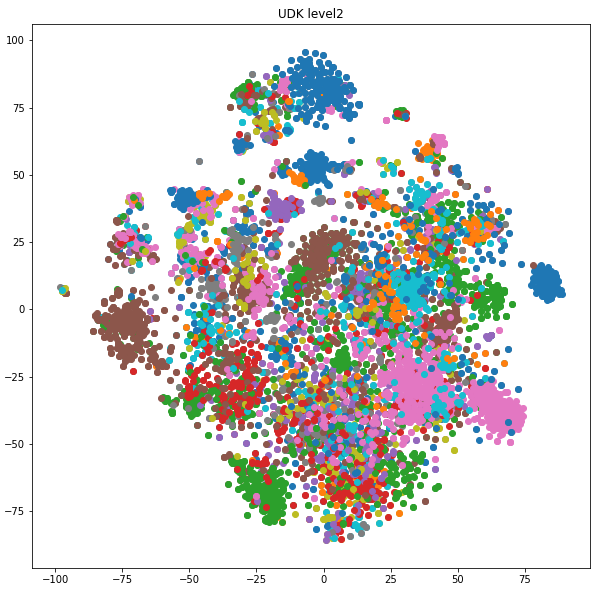
Podatkovno rudarjenje - raziskava
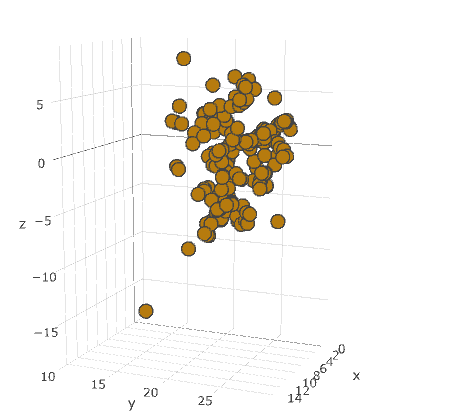
Nenadzorovano učenje (k-means 3d predstavitev):
Podatkovno rudarjenje - raziskava
Nenadzorovano učenje (k-means 3d predstavitev):
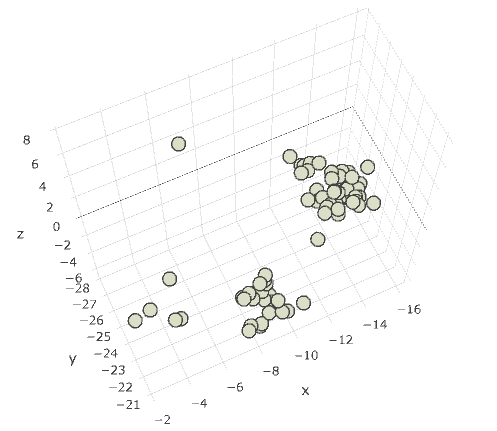
"čista" skupina: 27 - Krščanstvo
več kot 90% elementov ima UDK skupino 27
gruča (cluster) sili na dva dela
58 - botanika
59 - zoologija
Podatkovno rudarjenje - raziskava
Algoritem uči stroj s podanimi pari vhodnih in želenih izhodnih podatkov. Pri tem želene izhodne vrednosti določa učitelj, oz. človek - nadzornik.
Algoritem nadzorovanega učenja analizira podatke o vadbi in izdela sklepano funkcijo, ki jo lahko uporabimo za preslikavo novih primerov. Optimalni scenarij bo omogočil algoritmu, da pravilno določi oznake razredov za nove primerke.
Nadzorovano učenje (supervised learning):
Nadzorovano učenje - TFIDF matrika
podatki: 70.000+ znanstvenih dokumentov
razmerje učna / testna množica: 80% - 20%
- uporabimo prog. jezik Python, jupyter notebook, knjižnice in funkcije paketa Scikitlearn
- očistimo besedilo
(stop words, uporabimo zgolj besede, ki so v našem slovarju) - kreiramo matriko (tfidfVectorizer, fasttext)
- uporabljeni algoritmi za klasifikacijo:
- Support Vector Machines (SVM)
- Multilayer Perceptron (MLP)
- Logistic Regression
- Naive Bayes Classifier
Nadzorovano učenje
Večina znanstvenih člankov ima dodeljen več kot en UDK vrstilec.
Ko testiramo naučen model, dobimo navadno dodeljenih več kot en UDK za posamezen članek (v testni množici).
Spremenimo / dopolnimo hipotezo:
Ali lahko zagotovimo, z verjetnostjo vsaj 0.8, da bo naključni primerek iz testne množice "padel" v enega izmed prvih štirih (max. frequency) predlaganih UDK s strani modela?
Nadzorovano učenje
|
Support Vector Machine: natančnost: 0.963, f1: 0.8489 |
|
Multilayer Perceptron: natančnost: 0.944, f1: 0.8046 |
|
Logistic regression: natančnost: 0.940, f1: 0.6561 |
|
Naive Bayes: natančnost: 0.872, f1: 0.7427 |
Precision - Precision is the ratio of correctly predicted positive observations to the total predicted positive observations. The question that this metric answer is of all passengers that labeled as survived, how many actually survived? High precision relates to the low false positive rate.
Recall (Sensitivity) - Recall is the ratio of correctly predicted positive observations to the all observations in actual class - yes. The question recall answers is: Of all the passengers that truly survived, how many did we label? We have got recall of 0.631 which is good for this model as it’s above 0.5.

A confusion matrix (za MLP algoritem)

Nadzorovano učenje - fasttext
podatki: 70.000+ znanstvenih dokumentov
razmerje učna / testna množica: 80% - 20%
- uporabimo prog. jezik Python, jupyter notebook, knjižnice in funkcije paketa Scikitlearn
- očistimo besedilo
(stop words, uporabimo zgolj besede, ki so v našem slovarju) - kreiramo matriko (slovar fasttext - ni potrebno kreirati tfidf,
besedišče je Wikipedia, bazo razvili na Facebooku. - uporabljeni algoritmi za klasifikacijo:
- Support Vector Machines (SVM)
- Multilayer Perceptron (MLP)
- Logistic Regression
- Naive Bayes Classifier
Nadzorovano učenje - fasttext
|
Support Vector Machine: natančnost: 0.931, f1: 0.7823 |
|
Multilayer Perceptron: natančnost: 0.943, f1: 0.8142 |
|
Logistic regression: natančnost: 0.839, f1: 0.4206 |
|
Naive Bayes: natančnost: 0.753, f1: 0.5901 |
Precision - Precision is the ratio of correctly predicted positive observations to the total predicted positive observations. The question that this metric answer is of all passengers that labeled as survived, how many actually survived? High precision relates to the low false positive rate.
Recall (Sensitivity) - Recall is the ratio of correctly predicted positive observations to the all observations in actual class - yes. The question recall answers is: Of all the passengers that truly survived, how many did we label? We have got recall of 0.631 which is good for this model as it’s above 0.5.
Nadzorovano učenje - stara besedila
obstoječi model (na 70.000 člankih) bomo uporabili za klasifikacijo
200.000+ starih člankov, besedil
ponovimo:
- članki niso bibliografsko obdelani
- imajo lahko tudi zgolj en UDK (od nadrejenega zapisa - celotne revije)
- struktura članka varira
- dolžina članka varira (od nekaj vrstic - npr. osmrtnica, do novele)
- jezik besedil je drugačen kot današnji
- članki so digitalizirani, niso digitalni (napake pri OCR)
Uporabljeni algoritmi:
Support Vector Machines (SVM), Multilayer Perceptron (MLP), Logistic Regression (LOG), Naive Bayes Classifier (NB) in K-nearest neighbors algorithm (k-NN).
Nadzorovano učenje - rezultati
- izmed 200.000+ publikacij jih sistem avtomatično umesti v isti UDK, kot ga ima nadrejeni zapis - cca. 40.000 člankov
Izberemo testni nabor (naključno izbrani članki) - cca. 100 člankov - članke posredujemo bibliotekarjem, spet uporabimo max. top 4 izračunane UDK
|
PRIMER: |
|
LOG: [('02', 0.2588), ('070', 0.1872), ('027', 0.0485), ('821', 0.0482), ('930', 0.04372932160459208), ('908', 0.0207), ('27', 0.01577), ('81', 0.0149), ('655', 0.0126), ('050', 0.0117)] |
|
SVM: [('070', 0.4878), ('02', 0.3359), ('027', 0.0866), ('929', 0.0128), ('821', 0.0073), ('026', 0.0062), ('025', 0.0052), ('016', 0.0043), ('930', 0.0036), ('002', 0.0035)] |
|
KNN: [('070', 0.5039), ('02', 0.2984), ('027', 0.1976)] in sorodno za ostale algoritme |
|
|
Nadzorovano učenje - rezultati
še dva primera:
-
Ruski jezik in njegovi stvaritelji
https://www.dlib.si/details/URN:NBN:SI:DOC-IGJY1XPD, iz časopisa Dom in svet (1929),
UDK – 8 ( Jeziki. Lingvistika. Literatura)- Izračunani UDK: 81 - Jezikoslovje in jeziki
- Izračunani UDK: 811 - Languages
-
Razstava šolskih glasil
https://www.dlib.si/details/URN:NBN:SI:DOC-PX196IA1, iz časopisa Naša skupnost (1978),
UDK – 352 (najnižje ravni uprave. lokalna uprava. občinska, mestna uprava. lokalne oblasti)- Computed UDC: 373 - Vzgoja in izobraževanje
- Computed UDC: 37 - Vrste šol, ki zagotavljajo splošno izobrazbo
- Computed UDC: 821 - Književnost posameznih jezikov in jezikovnih družin
Nadzorovano učenje - rezultati
Bibliotekar "pobarva / potrdi" predlagani UDK, če je:
- pravi
- lahko bi bil pravi
- je boljši, kot UDK revije (nadrejenega zapisa)
PRIMER članka: ELEKTRIČNI ROBOT, Slovenski gospodar, 1938
V Preravi na češkoslovaškem so uvedli mehanično napravo, ki avtomatično regulira prižiganje in ugašanje luči.
Robot sestoji iz dveh celic. Prva je v poslopju mestne elektrarne, druga pa na transformatorju, čim se znoči, reagirata obe celici na spremembo svetlobe s tem, da zažarijo povsod električne luči.
UDK nadrejenega zapisa: 070 - Časopisi. Tisk. Novinarstvo.
Nadzorovano učenje - rezultati
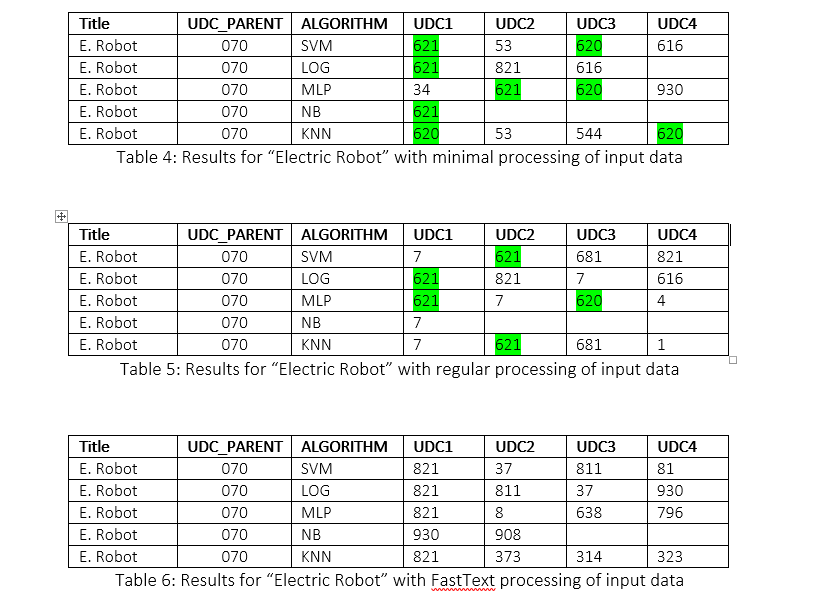
Nadzorovano učenje - rezultati
Med predlaganimi UDK sta:
620: Preiskava materiala. Blagoznanstvo. Energetske centrale. Energetika.
621: Splošno o strojništvu. Jedrska tehnika. Elektrotehnika.
Mehanska tehnologija nasploh
Nadzorovano učenje - rezultati
Primer: Deželni zbor, Slovenski gospodar, 1899
V predzadnji seji je utemeljeval poslanec Hagenhofer svoj predlog za ustanovitev deželne hipotečne banke. Povedal je, da je deželni zbor že od leta 1862 sem mnogokra sklepal o tej zadevi, da je pa stvar vednc obtičala. Skušal je dokazati, da bi dolžnik vknjiženih dolgov gotovo nad 1 milijon gld obresti vsako leto manje plačevali, če imamc tak deželni denarni zavod. Stvar se je izročila posebnemu gospodarskemu odseku, kis« bo izvolil v seji 14. aprila in bo štel lš udov. Nemški naprednjaki in narodnjaki se vložili predlog, da ima ustavoverni odsek obstoječ iz 12 udov, presoditi krivico, ki s« baje Nemcem godi vsled tega, da vlada zda na podlagi znanega § 14 temeljnega zakon* opravlja vse državine posle. V seji 11. aprje Poš vtemeljeval ta predlog ter zopet ii zopet tarnal nad zatiranjem Nemcev v Avstriji. Kdo se mu ne bi smejal? Saj ti ljudje sami sebi ne morejo verjeti, ko kričijo o zatiranji nemštva v Avstriji! V seji 12 aprila je vtemeljeval poslanec Hagenhofer svoj predlog, naj se odpravijo vse mitnice na nedržavnih cestah in mostih; poslanec Kurz pa predlog o zatiranji škodljivih mrčesov; poslanec Mosdorfer stavi predlog, da prevzame dežela v svojo skrb vse ceste po deželi in poslanec Žička r predlog, da se ima popraviti struga Sotle v okrajih Rogatec, Šmarje, Kozje in Brežice. Vsi štirje predlogi so se izročili odseku za deželno kulturo v presojo. Finančni odsek je v seji 11. aprila sklenil zboljSati plačilo profesorjem na višji deželni realki v Gradcu in na 5razredni gimnaziji v Ptuju. To zboljšanje se ima pričeti s 1. januarjem 1899. Profesorji na državnih gimnazijah zavživajo zboljšanje že od 1. oktobra 1898. Tudi meščanskim učiteljem se je zboljšala plača (po večini glasov) od 1. januvarija t. 1. Ob enem je sklenil finančni odsek deželnemu zboru priporočati predlog, da se višja deželna realka v Gradcu podržavi. Oskrbovalna vsprejetišča prizadevajo deželi leto za letom več stroškov. Že lani je sklenil finančni odsek, naj se odpravijo vsaj nekatera vsprejetišča; a vlada ni pritrdila temu predlogu. Letos se je ta predlog ponovil in se je nasvetovalo marsikaj, da se znižajo ti stroški, ki so preračunjeni za 1. 1899 na 114.000 gold. Ko so se ta vsprejetišča od liberalne nemške | večine deželnega zbora vstanovila, se je reklo: ljudje, ki bodo semkaj zahajali, naj ali delajo kot obrtniki ali pa pomagajo pri poljedelstvu. A liberalci s« se zmotili. Iz teh vsprejetišč ne dobiš lahko kakšnega delavca. Vlada se pa protivi zategavoljo odpravi kakšnega vsprejetišča, ker se boji, da se po tistem kraju začne potem beračenje.
UDK nadrejenega zapisa: 070 - Časopisi. Tisk. Novinarstvo.
Nadzorovano učenje - rezultati
Primer: Deželni zbor, Slovenski gospodar, 1899
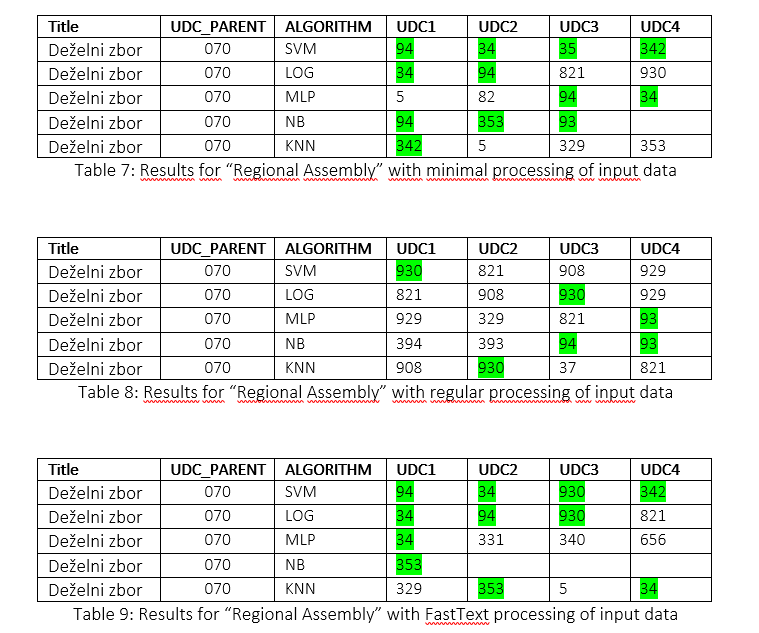
Nadzorovano učenje - rezultati
Zaključek in predlogi za nadalnje delo:
- Bibliotekarji so uspeli za vsak članek (staro besedilo) potrditi / izbrati vsaj enega izmed predlaganih UDK vrstilcev.
- za boljšo potrditev bi potrebovali več dela na strani bibliotekarjev - več pregledanih besedil.
- boljše rezultate (manj različnih predlaganih UDK vrstilcev) bi dobili z večanjem baze znanja - učne množice starih besedil (sedaj znanstveni članki)
- crowdsourcing
Nadzorovano učenje - uporaba
Možna uporaba:
- klasificirati vsa starejša (bibliografsko neobdelena) besedila
- ponuditi bibliotekarju pri klasifikaciji novega dokumenta "drugo mnenje"
- iz klasifikacij tujih publikacij ugotoviti tematiko besedila
Hvala za pozornost.
Matjaž Kragelj, študent
dr. Mirjana Kljajić Borštnar, mentorica
RAZVOJ METODOLOGIJE ZA AVTOMATIČNO KLASIFIKACIJO ELEKTRONSKIH PUBLIKACIJ V UNIVERZALNO DECIMALNO KLASIFIKACIJO - UDK
By Matjaž Kragelj
