
Wan Razali
dream to be rich business man in technology and properties
| Version | Hadoop 1 | Hadoop 2 | Hadoop 3 |
|---|---|---|---|
| Release | Dec 2011 | May 2012 (2.0.0 Alpha) | Dec 2017 |
| Hadoop Common, HFDS, Map Reduce | |||
| Resource Management | N/A | YARN | YARN |
| Namenode | Single | Multiple | Multiple |
| Containers like Dockers | N/A | N/A | Yes |
| Erasure Coding | N/A | N/A | Yes |
| Support GPU for processing | N/A | N/A | Yes |
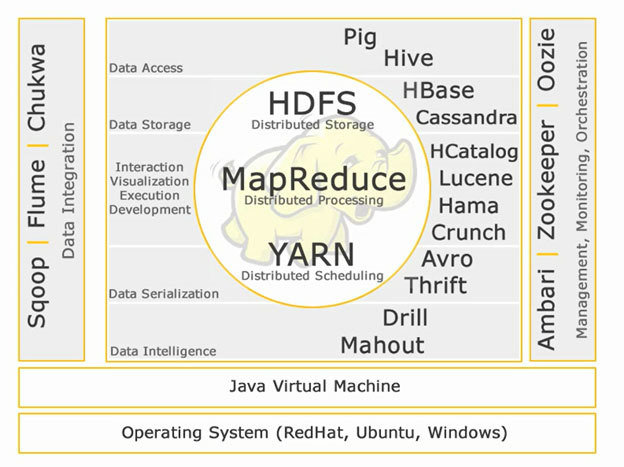
YARN
HDFS
MapReduce
Data Integration Comparison Matrix
| Data Ingest | Flume | Sqoop | Kafka |
|---|---|---|---|
| Release | Jan 2019 (v1.9.0) | Jan 2019 (v1.99.7) | March 2019 (v2.2.0) |
| Use | The main design goal of flume is to ingest huge log data generated by application servers into HDFS at a higher speed. | To move data between Hadoop and other databases and it can transfer data in parallel for performance. | It is used for building real-time data pipelines and streaming apps. |
| Use case | Online analytics | Bulk data transfer | Event Streaming platform (MQ, publishers and producers, process and manipulate data) |
| Scalable | Horizontally | Horizonally | |
| Data Source | Logs data generated by application or web server | RDBMS e.g Oracle, MariaDB | any realtime streaming application data |
| Data Destination | HFDS / HBase | Hadoop (HDFS, HBASE etc) | any Hadoop, Oracle, Twitter etc |
| Require Agent | Yes to be installed at application and web server | No | No |
Information updated as of Apr 2019
Database comparison matrix
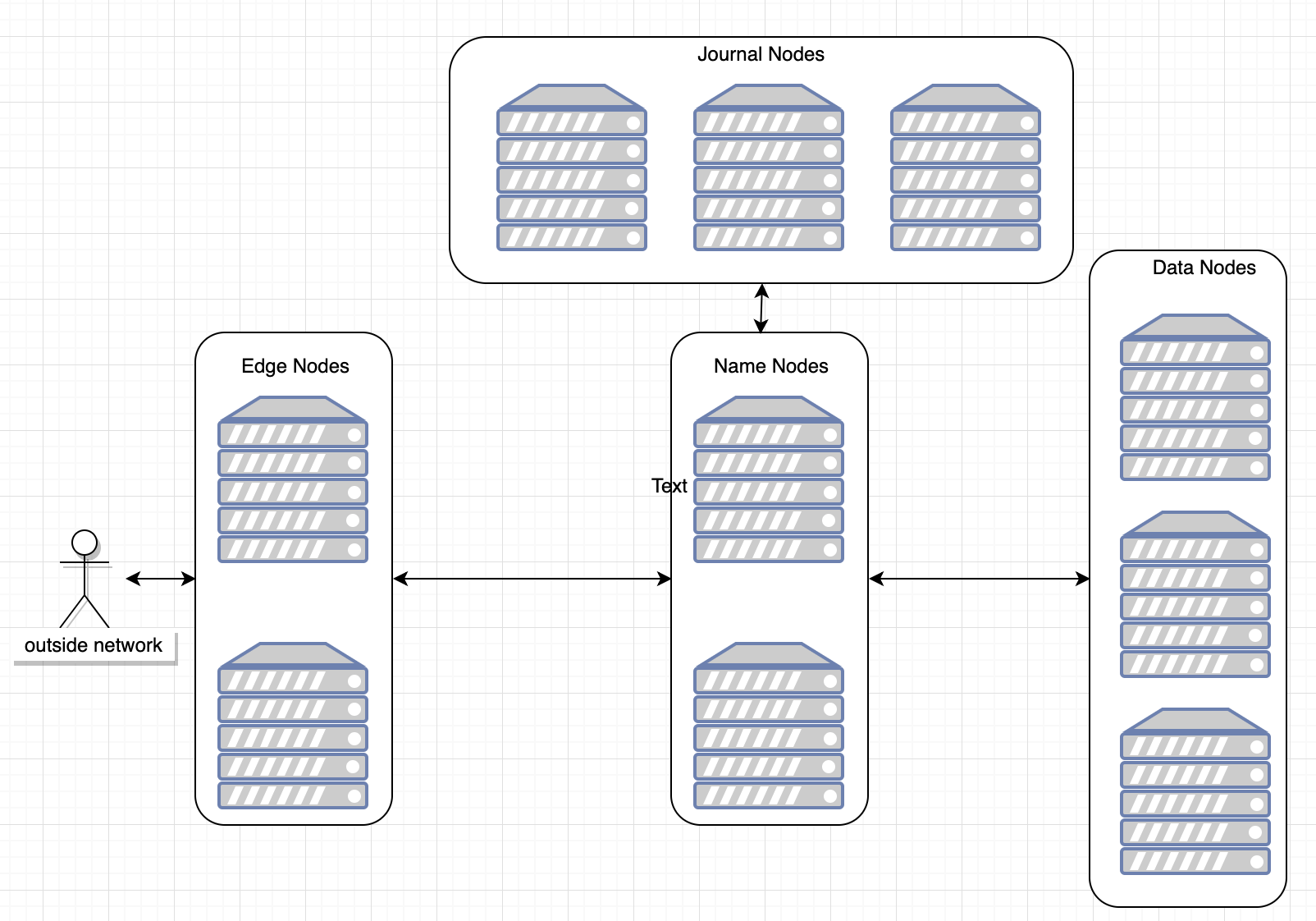
Hadoop Hardware Components
Name Node
Data Node
Edge Node / Gateway Node
Journal Node
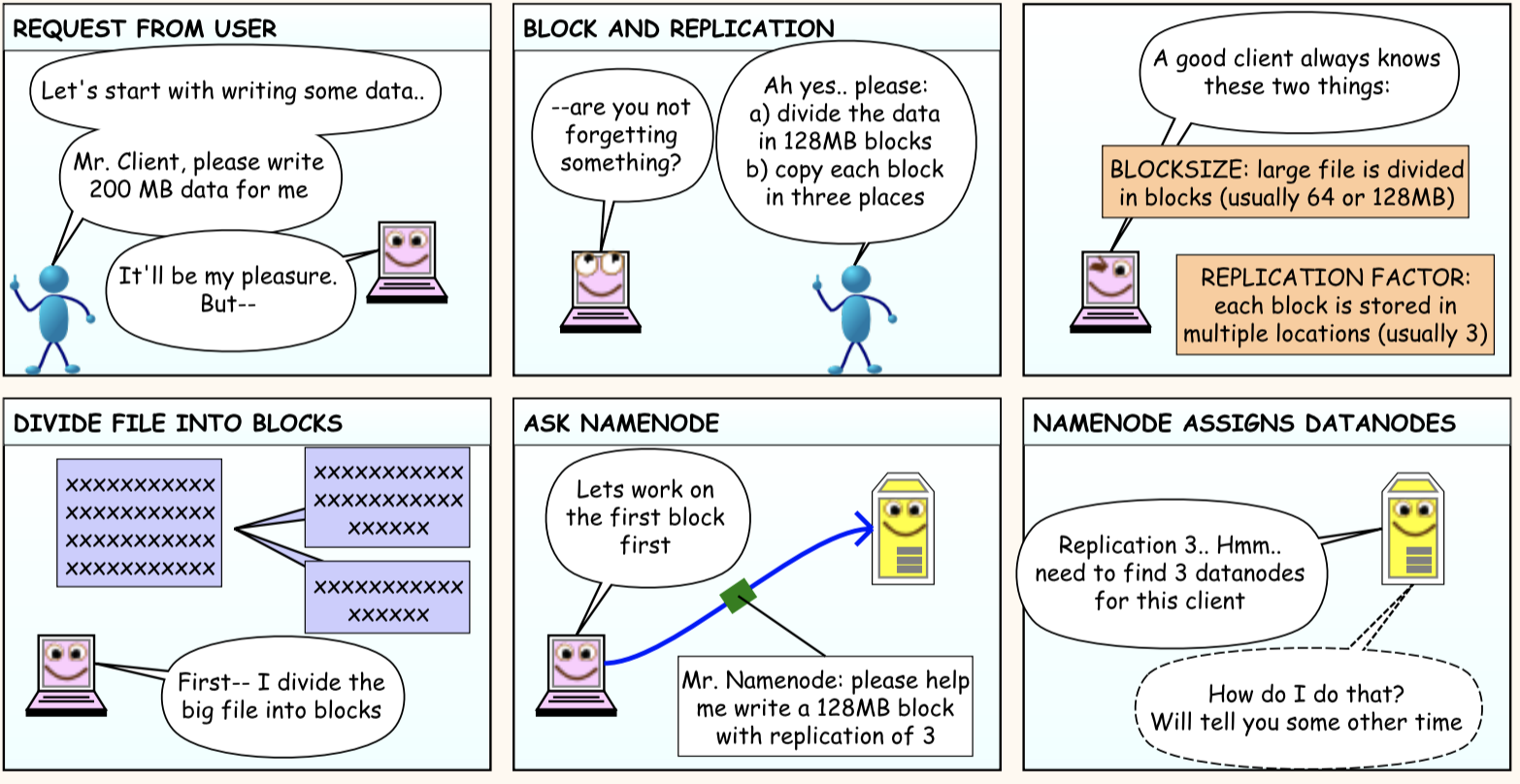
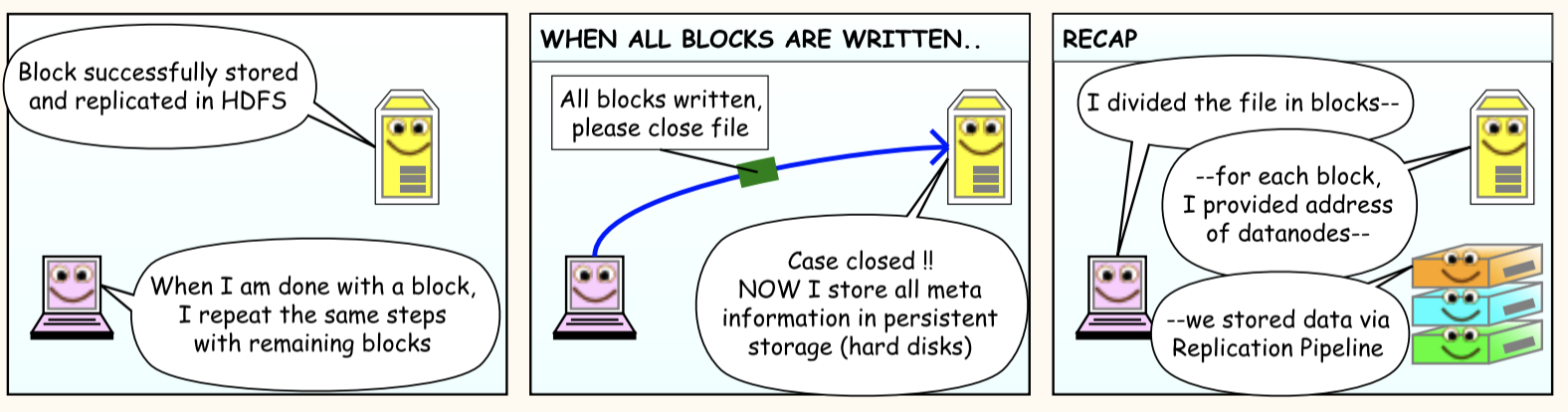
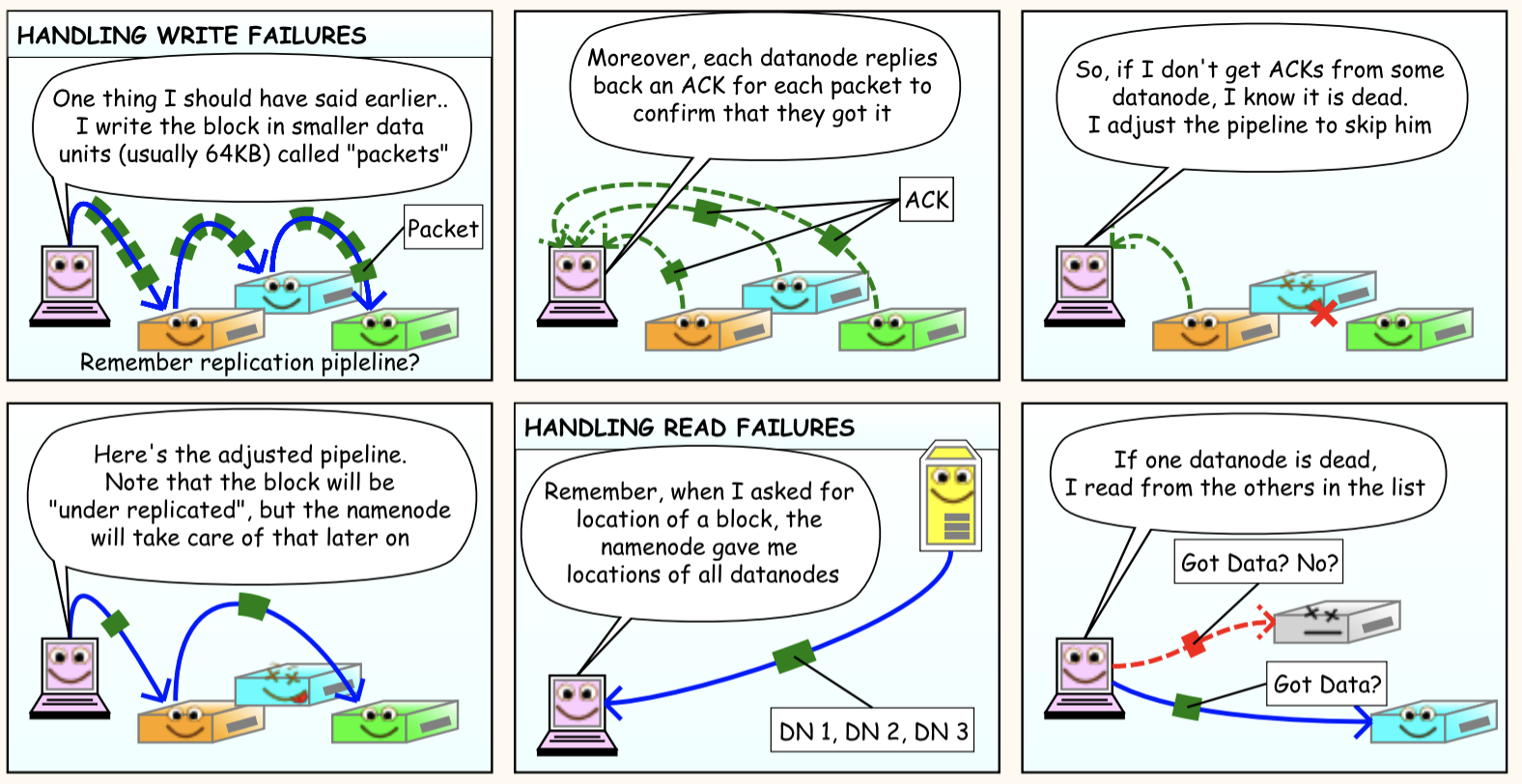
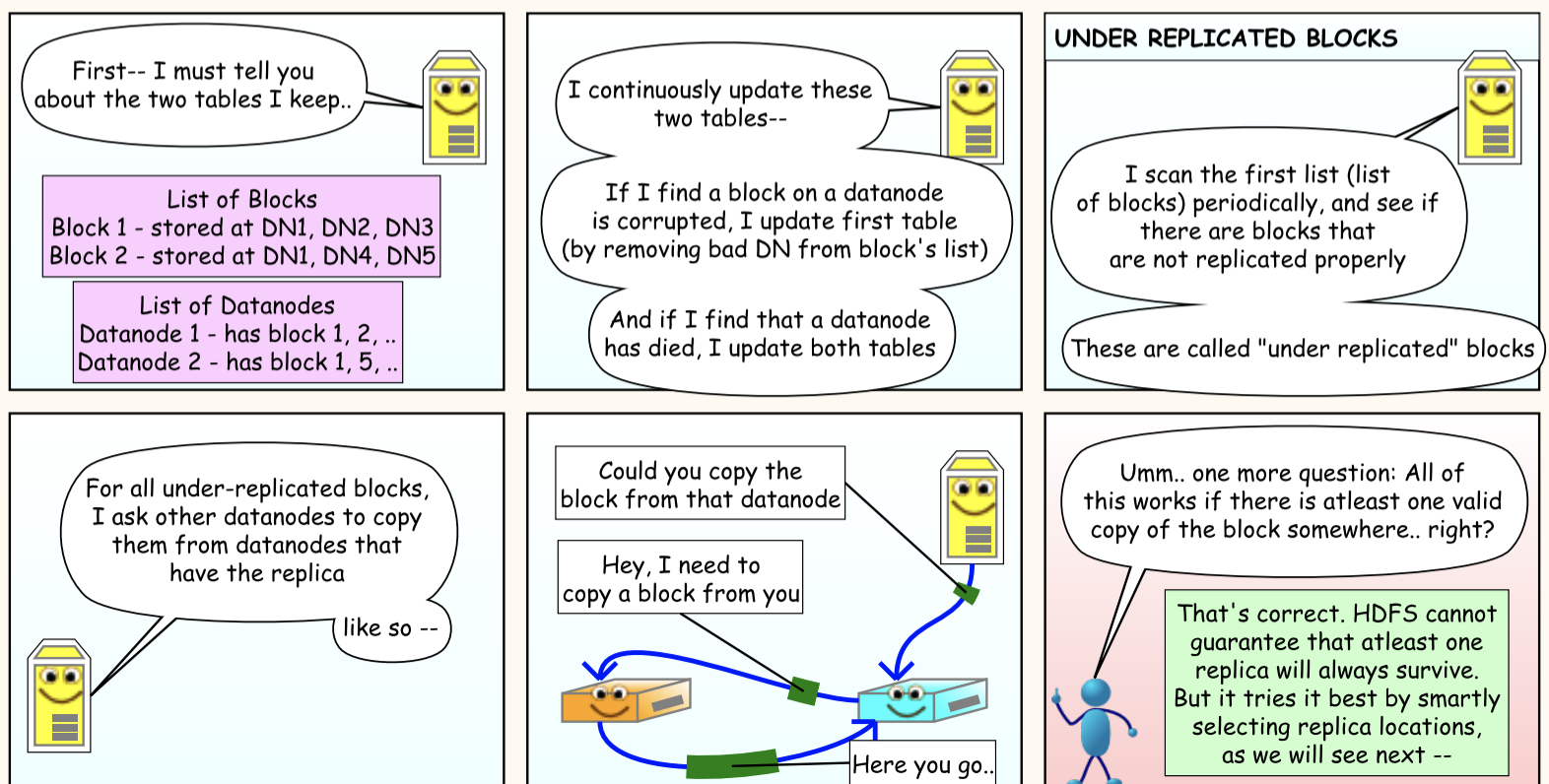
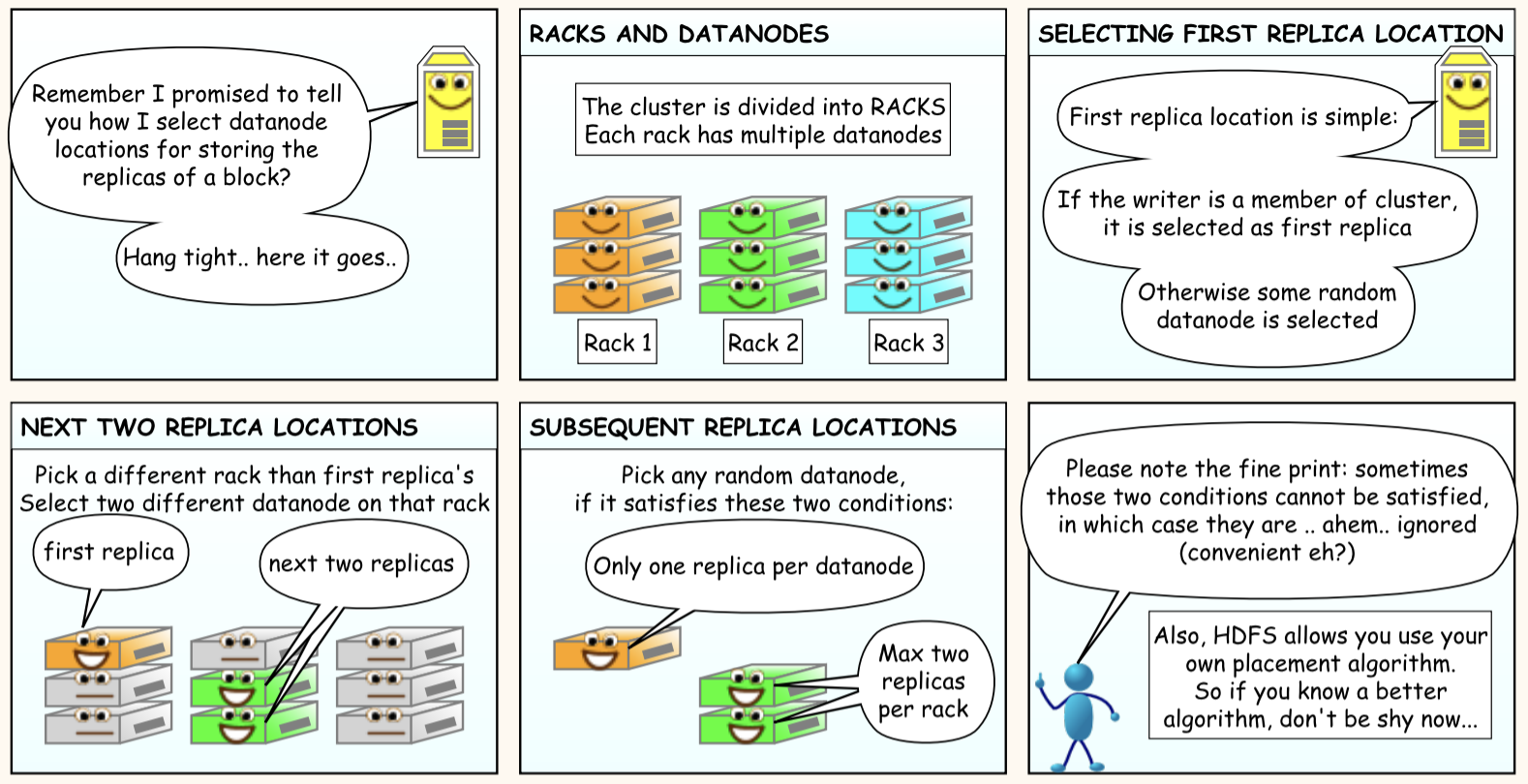
Hadoop Distributed File System - a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster.
File data divided into blocks of 64MB or 128MB
B1
B2
B3
B1, B2 & B3 blocks min and max size 64MB or 128MB
References:
By Wan Razali



