Levenshtein Transformer
Introduction
- Levenshtein distance: insertion, deletion, substitution
- Imitation learning
- Two policies executed alternatively (insertion, deletion)
- Comparable or better results than standard Transformer on MT and summarization while still being parallelisable
- One model for text generation and text post-editing
- Prominent component: learning algorithm
- Dual policy learning -> When training one policy, we use the output from its adversary at the previous iteration as input
Levenshtein Transformer
Contributions
- x5 speed up compared to standard Transformer
- Handles insertion and deletion operations
- Learning algorithm with an imitation learning framework, tackling the complementary and adversarial nature of the dual policies
- Unify sequence generation and refinement, machine translation model applied directly (without fine tuning) to translation post-editing
Levenshtein Transformer
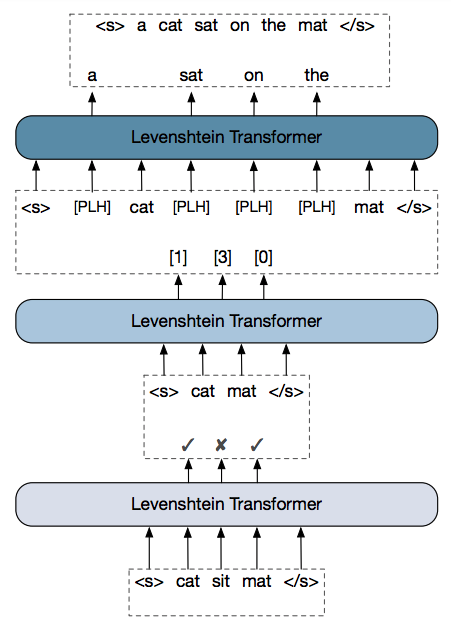
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Y = V^{N_{max}}
Possible sequences
Vocabulary
Max seq length
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Y = V^{N_{max}}
a
Possible sequences
Actions
Vocabulary
Max seq length
: insert or delete
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Y = V^{N_{max}}
a
Environment
Possible sequences
Actions
Vocabulary
Max seq length
: insert or delete
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Y = V^{N_{max}}
a
r
Environment
Possible sequences
Actions
Vocabulary
Max seq length
Reward function
: insert or delete
: reward
(e.g. Levenshtein distance)
R(y) = -D(y, y^*)
Problem Formulation Sequence generation and refinement
(Y, A, \epsilon, R, y_0)
Y = V^{N_{max}}
a
r
Environment
Possible sequences
Actions
Vocabulary
Max seq length
Input sequence (empty or incomplete)
Reward function
: insert or delete
: reward
(e.g. Levenshtein distance)
R(y) = -D(y, y^*)
Problem Formulation Sequence generation and refinement
Agent is modelled by policy , it maps
a sequence over a distribution of actions
\pi
\pi : Y \mapsto P(A)
Problem Formulation Actions: Deletion & Insertion
y^k = (y_1, y_2, ..., y_n)
y^{k+1} = \epsilon(y^k, a^{k+1})
a^{k+1}
= (a_1, a_2, ..., a_n)
<s>
</s>
Problem Formulation Actions: Deletion & Insertion
\pi^{del}(d|i, y)
Deletion policy:
is a binary decision (0 or 1)
d
\pi^{del}(0|1, y) = \pi^{del}(0|n, y) = 0
Can't delete start or end tokens :
Problem Formulation Actions: Deletion & Insertion
\pi^{plh}(p|i, y)
Predict the number of insertions: placeholder policy
a 2 phase insertion process
Predict the token of each insertion: token policy
\pi^{tok}(t|i, y)
Problem Formulation Actions: Deletion & Insertion
Policy alternate combination
a = \{d_0, ..., d_n ; p_0, ..., p_{n-1} ; t_0^1, ..., t_0^{p_0}, ..., t_{n-1}^{p_{n-1}}\}
y = (y_0, ..., y_n)
\pi(a|y) = \prod_{d_i \in d} \pi^{del}(d_i|i, y) \cdot \prod_{p_i \in p} \pi^{plh}(p_i|i, y') \cdot \prod_{t_i \in t} \pi^{tok}(t_i|i, y'')
y' = \epsilon(y, d)
y'' = \epsilon(y', p)
d
p
t
Levenshtein Transformer Model
h_0^{(l+1)}, h_1^{(l+1)}, ..., h_n^{(l+1)} = \{_{TransformerBlock_l(h_0^{(l)}, h_1^{(l)}, ..., h_n^{(l)}), \; l > 0}^{E_{y_0} + P_0, E_{y_1} + P_1, ..., E_{y_n} + P_n \;\;\;\;\;\;\;\;\;\;\;\;\; l=0}
States from l-th block
E \in \R^{|V|\times d_{model}}
P \in \R^{N_{max} \times d_{model}}
: token embedding
E_{y_n}
: position embedding
P_{y_n}
Levenshtein Transformer Model
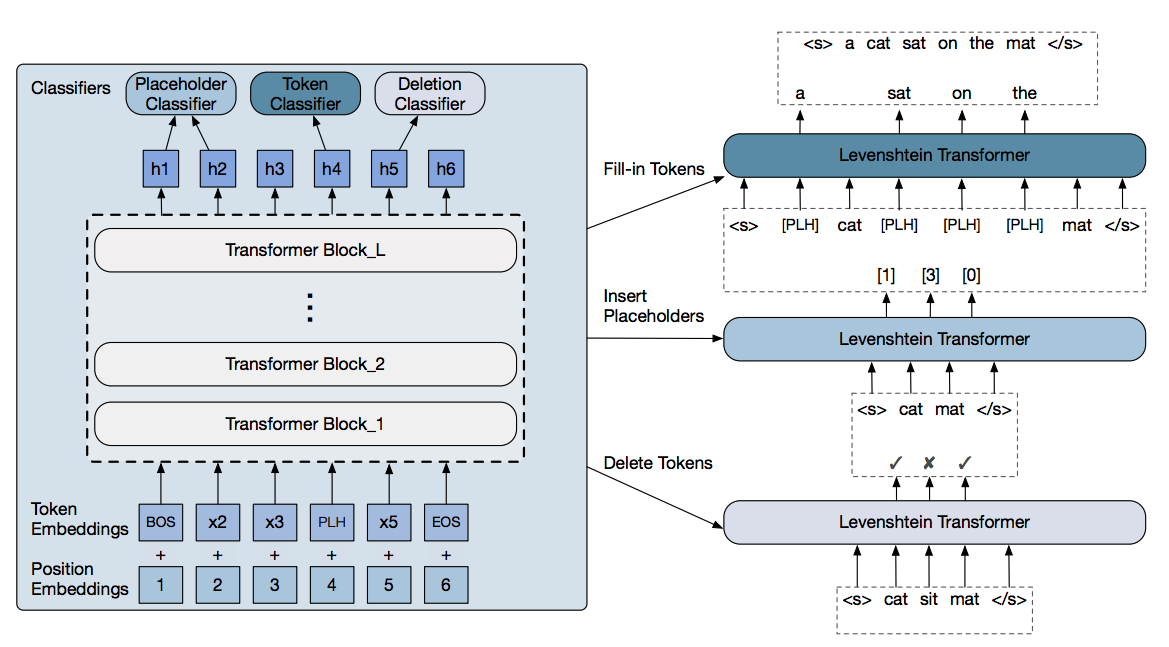
Levenshtein Transformer Model
Deletion classifier outputs 0 or 1
\pi_\theta^{del}(d|i, y) = softmax(h_i \cdot A^\top), \; i=1, ..., n-1,
A \in \R^{2 \times d_{model}}
Levenshtein Transformer Model
Placeholder classifier outputs number of tokens to insert
\pi_\theta^{plh}(p|i, y) = softmax(concat(h_i, h_{i+1}) \cdot B^\top), \; i=0, ..., n-1,
B \in \R^{(K_{max} + 1) \times (2d_{model})}
Levenshtein Transformer Model
Token classifier predicts the likelihood of vocabulary tokens
\pi_\theta^{tok}(t|i, y) = softmax(h_i \cdot C^\top), \; \forall y_i = \langle PLH \rangle,
C \in \R^{|V| \times d_{model}}
Levenshtein Transformer Dual-policy Learning
Learn to imitate an expert policy
y_{del} \sim d_{\widetilde{\pi}_{del}}
Objective:
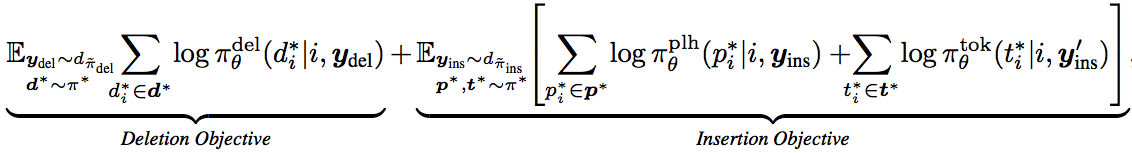
y_{ins} \sim d_{\widetilde{\pi}_{ins}}
and are state distributions
They suggest actions, then we optimise based on these actions
Levenshtein Transformer Dual-policy Learning
Learn to delete
u \sim Uniform[0, 1]
d_{\widetilde{\pi}_{del}} = \{y^0 \;\;\;\;\; u < \alpha \;\;\;\;\;\;\;\;\; \epsilon (\epsilon (y', p^{\ast}), \widetilde{t}), p^{\ast} \sim \pi^{\ast}, \widetilde{t} \sim \pi_{\theta}\}
if
else
\alpha \in [0, 1]
Levenshtein Transformer Dual-policy Learning
Learn to insert
u \sim Uniform[0, 1]
d_{\widetilde{\pi}_{ins}} = \{\epsilon(y^0, d^{\ast}), d^{\ast} \sim \pi^{\ast} \;\;\;\;\; u < \beta \;\;\;\;\;\;\;\; \epsilon(y^{\ast}, \widetilde{d}), \widetilde{d} \sim \pi^{RND}\}
if
else
\beta \in [0, 1]
Levenshtein Transformer Dual-policy Learning
Expert policy
a^{\ast} = argmin_{a} D(y^{\ast}, \epsilon(y, a))
Oracle:
Levenshtein without substitution
Distillation: teacher model as expert policy, replace ground-truth by beam-search results
y^{AR}
Levenshtein Transformer Dual-policy Learning
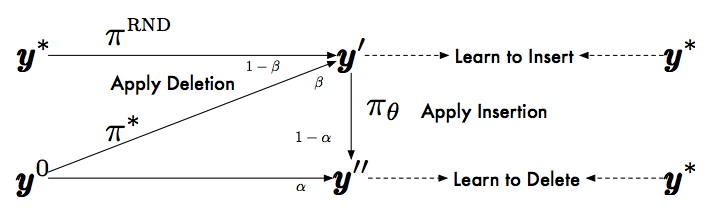

Levenshtein Transformer Inference
Greedy decoding
Training exit:
-
two consecutive iterations with same result
-
max number of iterations
Penalty for empty placeholders
Experiments
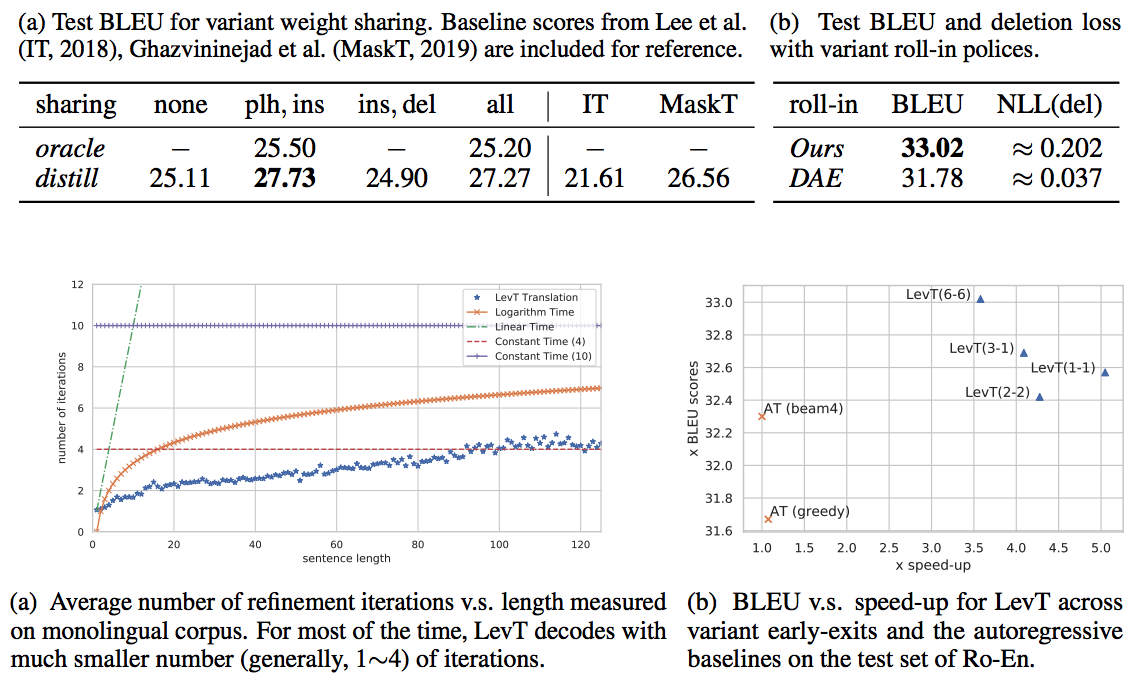
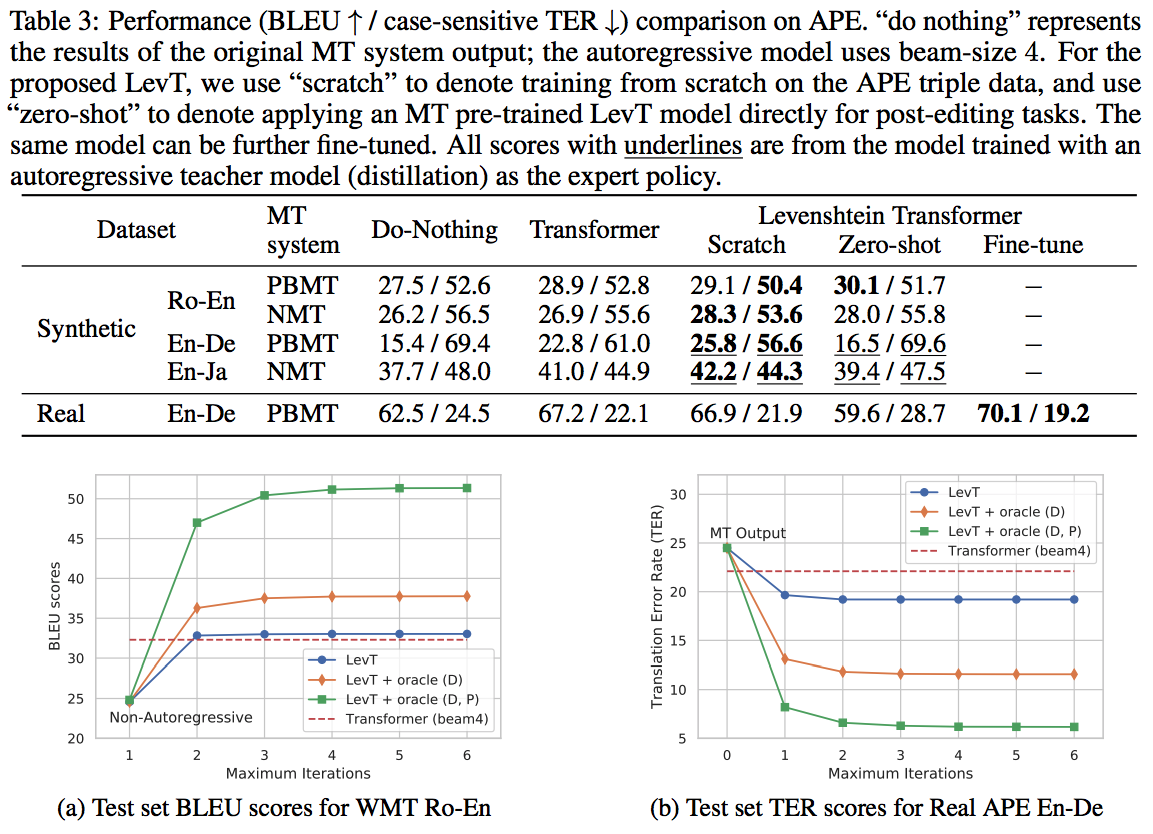
réu trad 15/11/2019
By mb1475963



