MongoDB
South America road trip
Matias Cascallares
April 2014
Who am I?
- Matias Cascallares
- Solutions Architect @ MongoDB Inc based in Singapore
- Software Engineer, University of Buenos Aires
- Experience mostly in web environments
- In my toolbox I have Java, Python and Node.js
Where I've been Working?





MONGODB 2.6
What's new?
main improvement areas
- Operations
- Text Search
- Query System Improvements
- Security
- MMS and Automation
Operations

DEVOPS, DEVOPS, DEVOPS!!
new wire protocol


Bulk Writes - ORDERED
var bulk = db.beers.initializeOrderedBulkOp();
// insert three new beers
bulk.insert( { name: "Lagunitas", alcohol: 5.7 } );
bulk.insert( { name: "Leffe", alcohol: 6.5 } );
bulk.insert( { name: "London Pride", alcohol: 4.7 } );
bulk.execute();
BULK WRITES - UNORDERED
var bulk = db.beers.initializeUnorderedBulkOp();
// update one beer
bulk.find( { name: "Corona" } ).update( { $set: { alcohol: 4.3 } } );
// .. and delete another one
bulk.find( { name: "Chimay" } ).remove();
// execute everything as a single bulk operation
bulk.execute();
Max time per query
// expensive query with regex without anchor
db.articles.find( { "description": /August [0-9]+ 1969/ } ).maxTimeMS(30000)
// it also works with aggregation framework!
db.articles.aggregate([ {
"$match": {
"$text": {
"$search": "chien",
"$language": "fr"
}
}
}]).maxTimeMS(100);
Building an index
- Foreground
- Background
building an index on the foreground
- Faster
- More compact
- Blocking operation
// foreground by default
db.beers.ensureIndex( { name: 1} );
Building an index on the background
- Slower
- Sparser
- Non-blocking operation
// background is an optional argument
db.beers.ensureIndex( { name: 1}, { background: true } );
index build in 2.4
FG in primary -> FG in secondary
BG in primary ->
FG
in secondary

index build in 2.6
FG in primary -> FG in primary
BG in primary -> BG in secondary

Storage allocation
- usePowerOf2Sizes will be the default allocation method for new collections

Sharding new commands
- mergeChunks
- cleanupOrphaned
Text search - GA
...Text Search was there in 2.4

Integrated within find
db.articles.ensureIndex( { body: "text" } );
db.articles.insert(
{ body: "the quick brown fox jumped over the lazy dog" }
);
db.articles.find( { "$text" : { $search : "quickly" } } );
INTEGRATED WITHIN AF
db.articles.aggregate([
{ "$match": { "$text": { $search: "bRoWN"} } }
]);
playing with texts
// search for a single word
db.articles.find( { "$text": { "$search": "coffee" } } );
// search for any of these words
db.articles.find( { "$text": { "$search": "bake coffee cake" } } );
// search for a phrase
db.articles.find( { "$text": { "$search": "\"coffee cake\"" } } );
// excluding some terms
db.articles.find( { "$text": { "$search": "bake coffee -cake" } } );
Top 3 relevant documents
db.articles.find(
{ "$text": { "$search": "cake" } },
{ "score": { "$meta": "textScore" } }
).sort( { "score": { "$meta": "textScore" } } ).limit(3)
language support
db.articles.find(
{ "$text": { "$search": "leche", $language: "es" } }
);
language support

Query system
improvements
Aggregation Framework
- Returns a cursor
- Can output to a collection
- New operators
- explain()
Aggregation Framework
// using a cursor
db.beers.aggregate([
{ "$match": { barrels: { "$gte": 10000}} }
],
{ cursor: { batchSize: 1 } }
);
// output to a collection
db.beers.aggregate([
{ "$match" : { barrels : { "$gte": 10000}} },
{ "$out" : "my_output_collection" }
]);
AGGREGAtion framework - explain
db.beers.aggregate(
[
{ "$match": { barrels: { "$gte": 500 } } },
{ "$group": { "_id": "$type", count: { "$sum":1 } } }
],
{ explain: true }
);
aggregation framework - explain
{"stages" : [ // one entry per pipeline stage
{
"$cursor" : {
"query" : { "barrels" : { "$gte" : 500 } },
"fields" : { "type" : 1, "_id" : 0 },
"plan" : {
"cursor" : "BtreeCursor barrels_1",
"isMultiKey" : false,
"scanAndOrder" : false,
"indexBounds" : { "barrels" : [ [500, Infinity] ] }
}
}
],
"ok" : 1
}
update operators - mul
db.beers.insert(
{ _id: 1, name: "Lagunitas", price: 10.99 }
);
// to increase the price by 20%
db.beers.update(
{ _id: 1 },
{ "$mul" : { price: 1.2 } }
);
UPDATE operators - bit
db.beers.update(
{_id: 1},
{ "$bit": { mask: { and: NumberInt(10) } } }
);
db.beers.update(
{_id: 1},
{ "$bit": { mask: { or: NumberInt(10) } } }
);
db.beers.update(
{_id: 1},
{ "$bit": { mask: { xor: NumberInt(10) } } }
);
update operators - min/max
db.scores.insert(
{ _id: 1, low_score: 200, high_score: 400 }
);
db.scores.update(
{ _id: 1 },
{ "$min": { low_score: 250 } }
);
db.scores.update(
{ _id: 1 },
{ "$max": { high_score: 450 } }
);
Index intersection
// index creation
db.beers.ensureIndex( { barrels: 1 } );
db.beers.ensureIndex( { alcohol: 1 } );
// retrieval
db.beers.find( { barrels: { "$gte": 100 }, alcohol: { "$gte": 5.5 } } );
index intersection
-
Less Index Maintenance
-
Smaller Working Set
-
Lower Write Overhead
-
More Adaptive
query optimizer - new concepts
- Query Shape
- Plan Cache
what is a query shape?
db.beers.find(
{ barrels: { "$gte": 300 } },
{ _id: -1, name: 1, barrels: 1}
).sort( { alcohol: -1 } );
db.runCommand( { planCacheListQueryShapes: "beers"});
{
"shapes" : [
{
"query" : { barrels: { "$gte": 300 } },
"sort" : { alcohol: -1 },
"projection" : { _id: -1, name: 1, barrels: 1}
}
]
}
... let's create a plan cache
db.runCommand({
"planCacheSetFilter": "beers",
"query" : { barrels: { "$gte": 300 } },
"sort" : { alcohol: -1 },
"projection" : { _id: -1, name: 1, barrels: 1}
"indexes": [
{ barrels: 1 },
{ alcohol: -1, barrels: 1 }
],
});
what do i get?
- Better control on which indexes are going to be evaluated
- Ability to predefine a set of candidate indexes
- ... but still is an empiric query optimizer
Geospatial enhancements
- Added support for multipart geometries
- MultiPoint
- MultiLineString
- MultiPolygon
- GeometryCollection
GEOSPATIAL ENHANCEMENTS

Security
Authentication
- LDAP (Enterprise)
- x509
Authorization
- User defined roles
creating new roles
db.createRole({
role: "MMSMonitoringRole",
roles: ["clusterAdmin", "readAnyDatabase"]
});
db.createRole({
role: "MMSBackupRole",
roles: ["clusterAdmin", "readAnyDatabase", "userAdminAnyDatabase"]
});
using my new roles
db.addUser({
"user": "mms-monitoring",
"pwd": "abcd1234",
"roles": [
"MMSMonitoringRole"
]
});
db.addUser({
"user": "mms-backup",
"pwd": "efgh5678",
"roles": [
"MMSBackupRole"
]
});
creating custom privileges
db.createRole({
"role": "appUser",
"db": "myApp",
"privileges": [
{
"resource": { "db": "myApp" , "collection": "" },
"actions": [ "find", "dbStats", "collStats" ]
},
{
"resource": { "db": "myApp", "collection": "beers" },
"actions": [ "insert"]
}
]
};
Auditing
- Schema actions
- Replica Set actions
- Authentication & Authorization actions
- Other actions
output
mongod --dbpath data/db --auditDestination syslog
- syslog
- console
- JSON/BSON file
dropping a collection
var auditEntry = { "atype" : "dropCollection", "ts" : { "$date" : "2014-04-08T16:48:34.333+1000" }, "local" : { "ip" : "127.0.0.1", "port" : 27017 }, "remote" : { "ip" : "127.0.0.1", "port" : 55771 }, "users" : [ { "user": "matias", "db": "test" } ], "param" : { "ns" : "test.beers" }, "result" : 0 };
shutting down the server
var auditEntry = {
"atype" : "shutdown",
"ts" : { "$date" : "2014-04-08T16:54:24.373+1000" },
"local" : { "ip" : "127.0.0.1", "port" : 27017 },
"remote" : { "ip" : "127.0.0.1", "port" : 55771 },
"users" : [
{ "user": "matias", "db": "admin" }
],
"param" : {},
"result" : 0
};
MMS & automation
MMS
- Monitoring and backup service
- Cloud-based and on-premise
- Easy to setup
cloud numbers
- Monitoring: 75K updates/sec
- Backup: 100 GB/hr of new data
monitoring

monitoring

monitoring

alerts

BACKUP
- Backup a replica set or sharded cluster
- Initial sync + incremental
- Generated snapshots every 6 hs
- Restore via HTTPS or SCP
- Restore replica sets to point-in-time (last 24hs)
- Restore sharded clusters to any 15 minute (last 24hs)
BACKUP

BACKUP

automation
- Provision, create, upgrade and maintain MongoDB deployments
- Hide complex stuff, just use your browser
- Initial supported platforms: AWS and OpenStack
- Alpha/Beta stage
what can i do?
- Create your deployment (replica set or sharded)
- Add/remove shards and replica sets
- Resize oplog
- Specify users and roles
- Provisioning new machines (only in AWS)
provisioning new servers
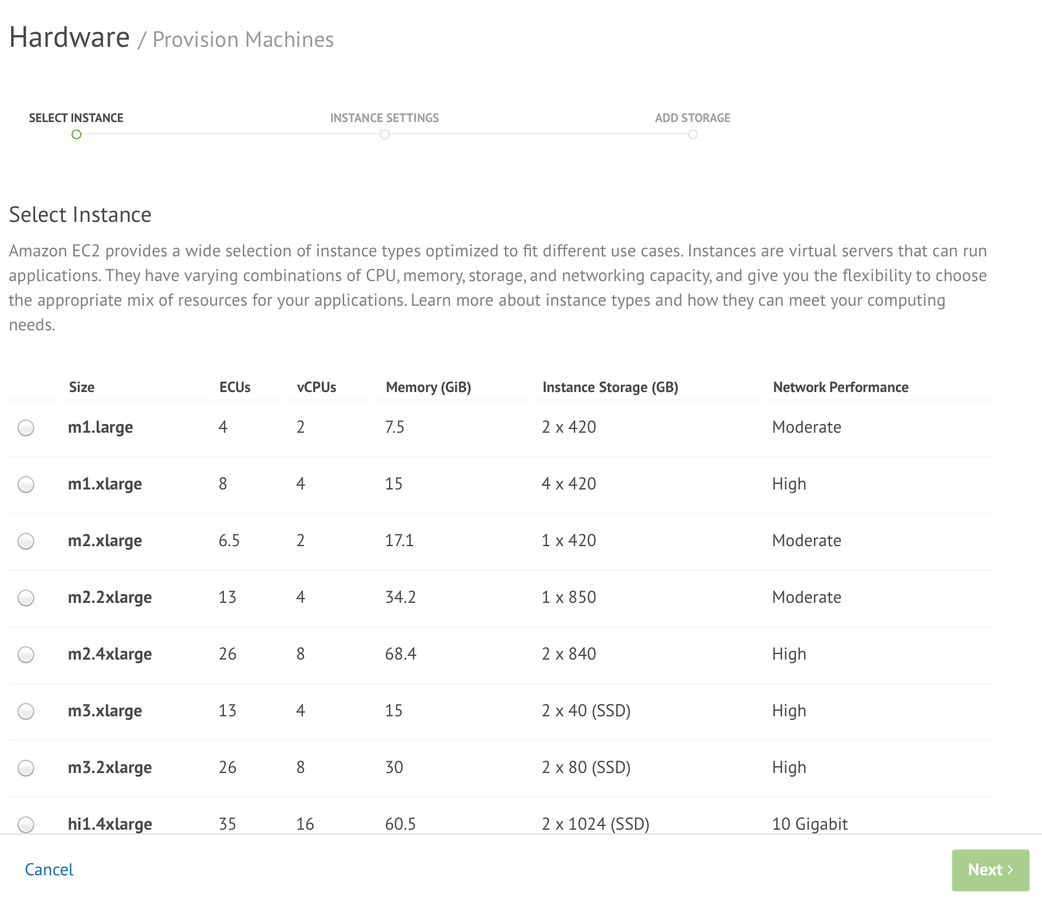
creating your replica set

creating your cluster

50 shards, one click

See it in action..
https://www.youtube.com/watch?v=nSJiVXNsPHk&feature=youtu.be
THE END
Questions?
http://slid.es/mcascallares/mongodb-sa-road-trip
MongoDB - South America Road Trip - Sao Paulo
By Matias Cascallares
