Катим ML в Production

Intro
Buisness PoV
ĦØƁΔЯ°
ĂĮ
ƘႸԒᕊƬჄ₽Δ

Intro
Dictionary
| For customers | For real |
|---|---|
| Deep Learning | Logistic Regression |
| Machine Learning | Logistic Regression |
| NLP | Regular expressions |
| Domain adaptation | Handcrafted hacks |
| Magic | Matrix multiplication |
| AI | Any random sh*t |




Intro
For real
import joblib
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris(return_X_y=True)
clf = LogisticRegression()
clf.fit(X, y)
print(clf.score(X, y))
joblib.dump(clf, "my_deeplearning_model")Okay, what's next?
Requirements
- Data size (KB vs TB)?
- Model size?
- Batch/Online?
Okay, what's next?
Requirements
- Speed (RPS, Latency, SLA)
- Hardware (RAM, CPU, GPU)
- Performance (algorithm)
Okay, what's next?
Problem


PRODUCTION

And what to do?
Solution #1: CLI
$ python3 awesome_predict.py \
--model "my_deeplearning_model" \
--input "1.csv" \
--output "1.predictions.csv"
Solution #1: CLI


- Simple
- Batch
- Hard to use
- Not scalable
- Hard to integrate
- No "real" online
Hm, we need a service!

Services
- Docker ♥
- Cloud ♥
- Redis/RMQ/* as service
Solution #2: REST
GET /info
POST /predict

Solution #2: REST


Solution #2: REST
- Simple usage
- Scalable
- Simple enough to implement
- Useful for demo
- Easy to integrate
- Many tutorials
- Online & Batch
- Performance?
What if bigdata?
Solution #3: PySpark






Solution #3: PySpark
- Batch & ~Online
- Really TB of data
- JVM
- Overhead
- Impossible to apply the large model (>2GB)
- Random crashes
- High support price
- Complicated
Maybe
ВĘԒѺԸNΠΣΔ?

Solution #4: ВĘԒѺԸNПΣΔ
Queue
Storage
Machines
/a/1.csv
/a/2.csv
/a/1.csv
/a/2.csv
/a/1.out.csv
/a/2.out.csv
/a/1.csv
/a/2.csv
/a/1.out.csv
/a/2.out.csv




- No overhead
- Simple to control
- Batch
- Scalable
- Simple enough to implement
- no Online
- Machine managing fully on your side
Solution #4: ВĘԒѺԸNПΣΔ
Solution #5: SageMaker
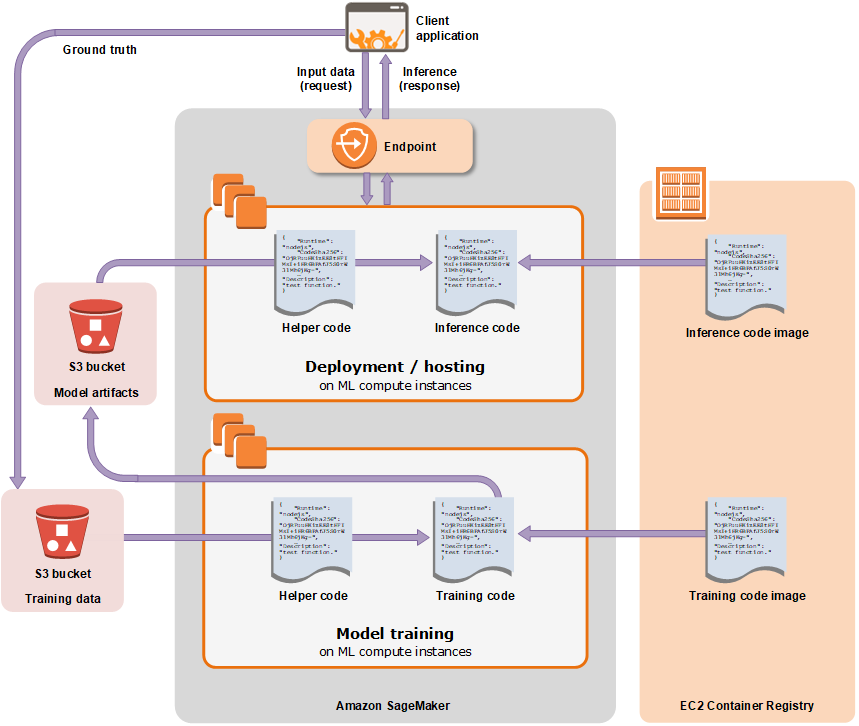
Solution #5: SageMaker
- Batch & Online
- Different APIs for free (REST + SDK)
- Simple usage (if you setup all things properly)
- Price
- Complicated
- Too much marketing
Conclusion
| Data size | Model size | Batch/Online | Pick |
|---|---|---|---|
| Small | Small | Batch | * (even CLI) |
| Small | Small | Online | REST |
| Small | Large | Batch | REST |
| Small | Large | Online | REST |
| Large | Small | Batch | |
| Large | Small | Online |
REST / SageMaker / |
| Large | Large | Batch | ВĘԒѺԸNПΣΔ / REST / SageMaker |
| Large | Large | Online | REST / SageMaker |
0 < Small < 0.5TB
Large >= 0.5TB
0 < Small < 500MB
Large >= 500MB
Conclusion
-
REST is the most universal choice
-
В Ę Ԓ Ѻ Ը N П Σ Д isn't always a bad idea
-
DataSatanist should be able to solve such problems (or at least know about them)
Thanks!




Катим ML в Production
By Ivan Menshikh



