Data Wrangling I

Outline
Mapping questions to operations
Operations with data.frames
The dplyr package
{mapping questions to operations}
Steps for analysis
Articulate question of interest
Translate your question into code
Execute your program
Vehicle data
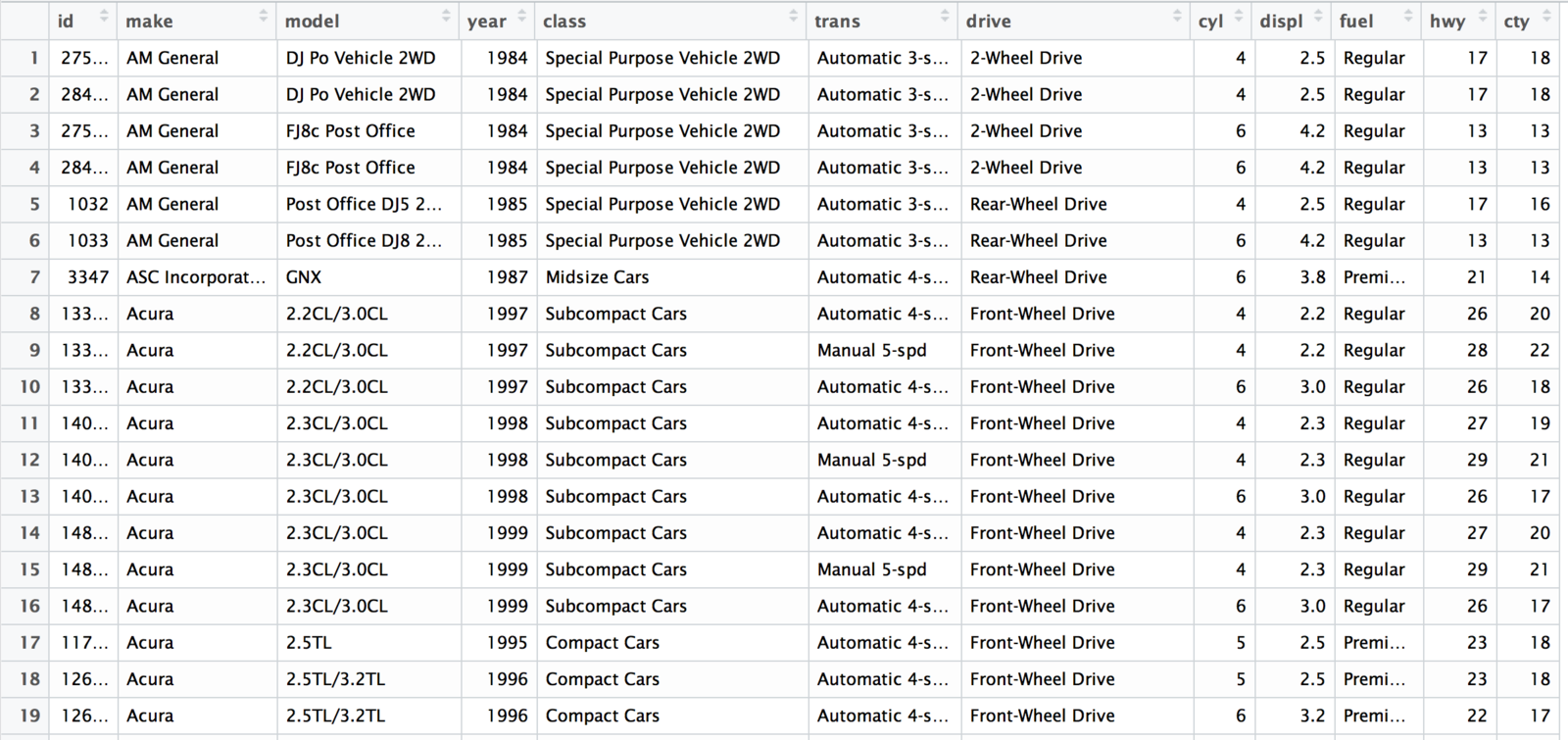
Write down 5 questions you have about this dataset
Questions
Which model car had the highest highway MPG?
What were the makes of the top 5 MPG cars in 1997?
What type of fuel is used by the car with the lowest city MPG?
What is the class of 2-Wheel Drive vehicles that get > 20 miles/gallon?
Select a column
Which model car had the highest highway MPG?
What were the makes of the top 5 MPG cars in 1997?
What type of fuel is used by the car with the lowest city MPG?
What is the class of 2-Wheel Drive vehicles that get > 20 miles/gallon?
Filter rows
Which model car had the highest highway MPG?
What were the makes of the top 5 MPG cars in 1997?
What type of fuel is used by the car with the lowest city MPG?
What is the class of 2-Wheel Drive vehicles that get > 20 miles/gallon?
A Grammar of Data Manipulation
Select particular columns
Filter down to specific rows
Arrange (sort) your dataset by values
Mutate your dataframe to add a column
Summarise your dataframe (calculate summary info, mean)
{exercise 1: operations with data.frames}
{dplyr}
DPLYR
"A grammar for data manipulation"
Provides verbs for common tasks
More readable, efficient code
Written by Hadley Wickham

Common Verbs
Select the columns of interest
Filter down to rows of interest
Mutate new columns
# Arguments are data.frame, then comma separated column names
my_cols <- select(df, col1, col2, col3)# Arguments are data.frame, then comma separated boolean operators
my_rows <- filter(df, col1 > col2, col2 < col3, col4 == "hello")# Arguments are data.frame, then comma separated sorting columns
sorted_df <- arrange(df, col1, desc(col2))Arrange your data by a column's values
# Arguments are data.frame, then comma separated new columns
new_df <- mutate(df, combined = col1 + col2, diff = col1 - col2)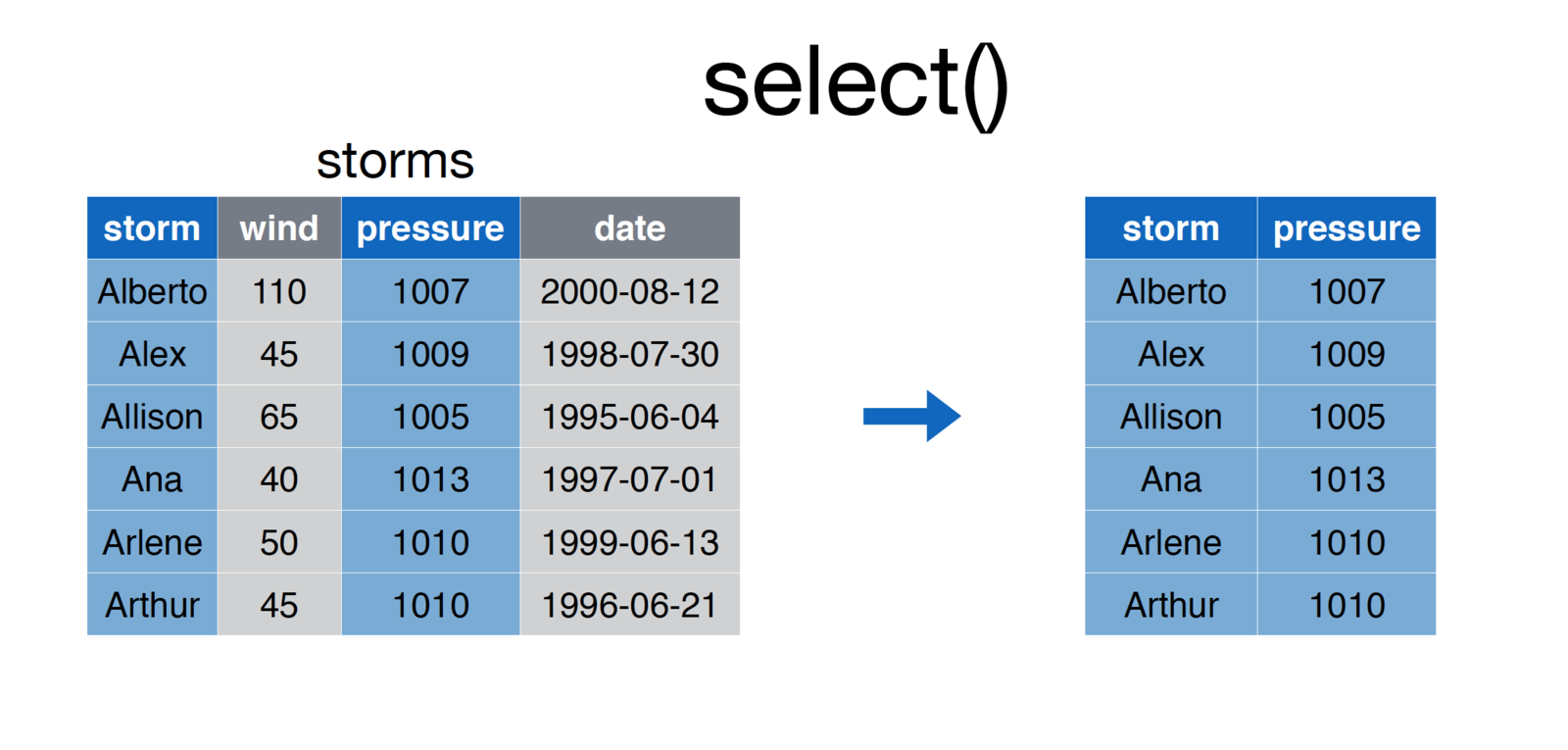
credit: Nathan Stephens, Rstudio
# Select storm and pressure columns from storms dataframe
storms <- select(storms, storm, pressure)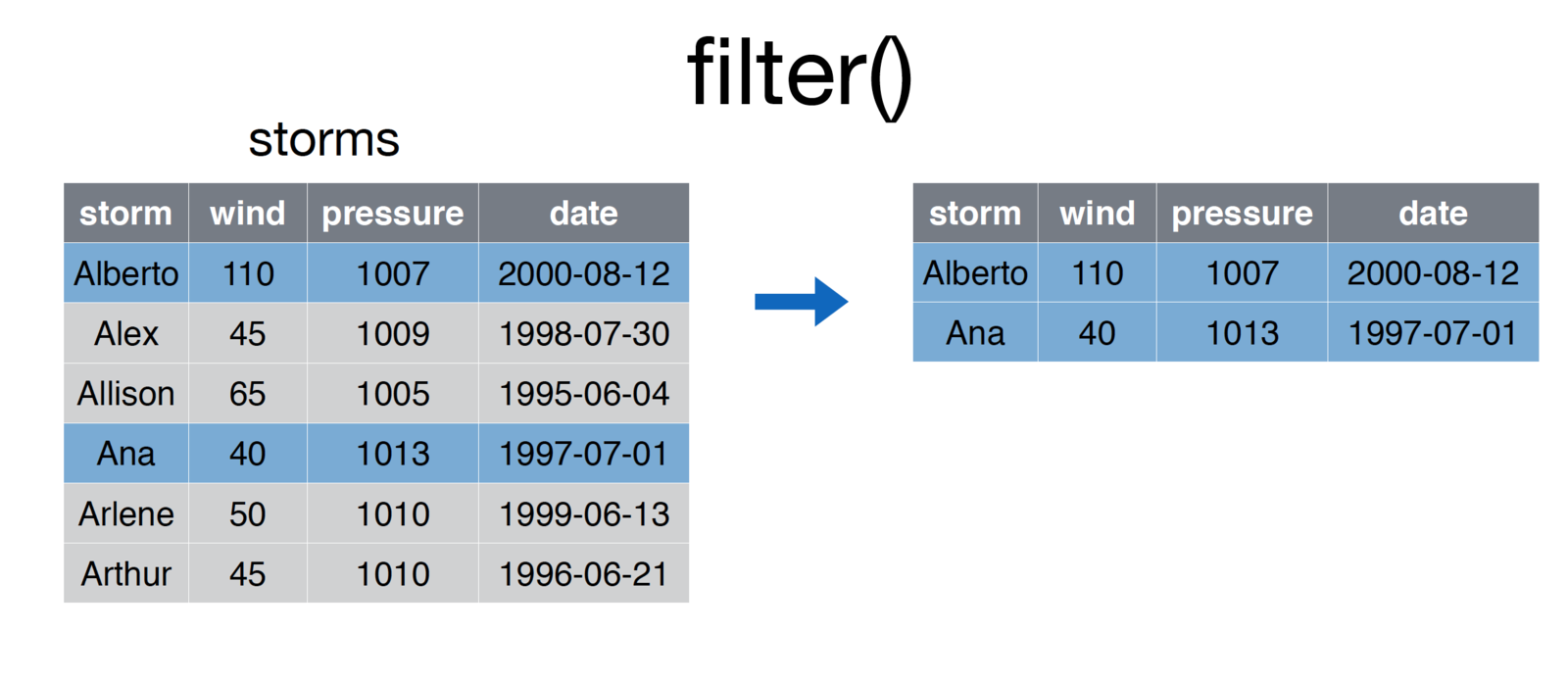
credit: Nathan Stephens, Rstudio
# Filter down storms to storms with name Ana or Alberto
storms <- filter(storms, storm %in% c('Ana', 'Alberto')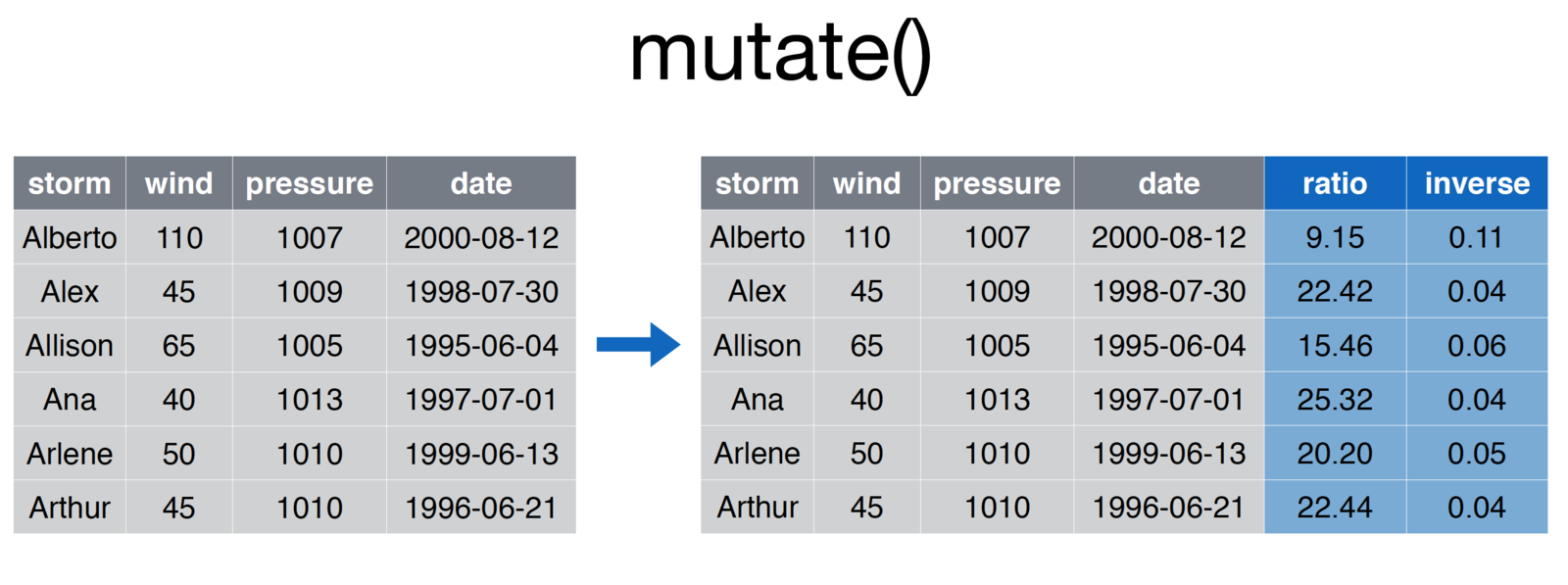
credit: Nathan Stephens, Rstudio
# Add ratio and inverse ratio columns
storms <- mutate(storms, ratio = pressure/wind, inverse = 1/ratio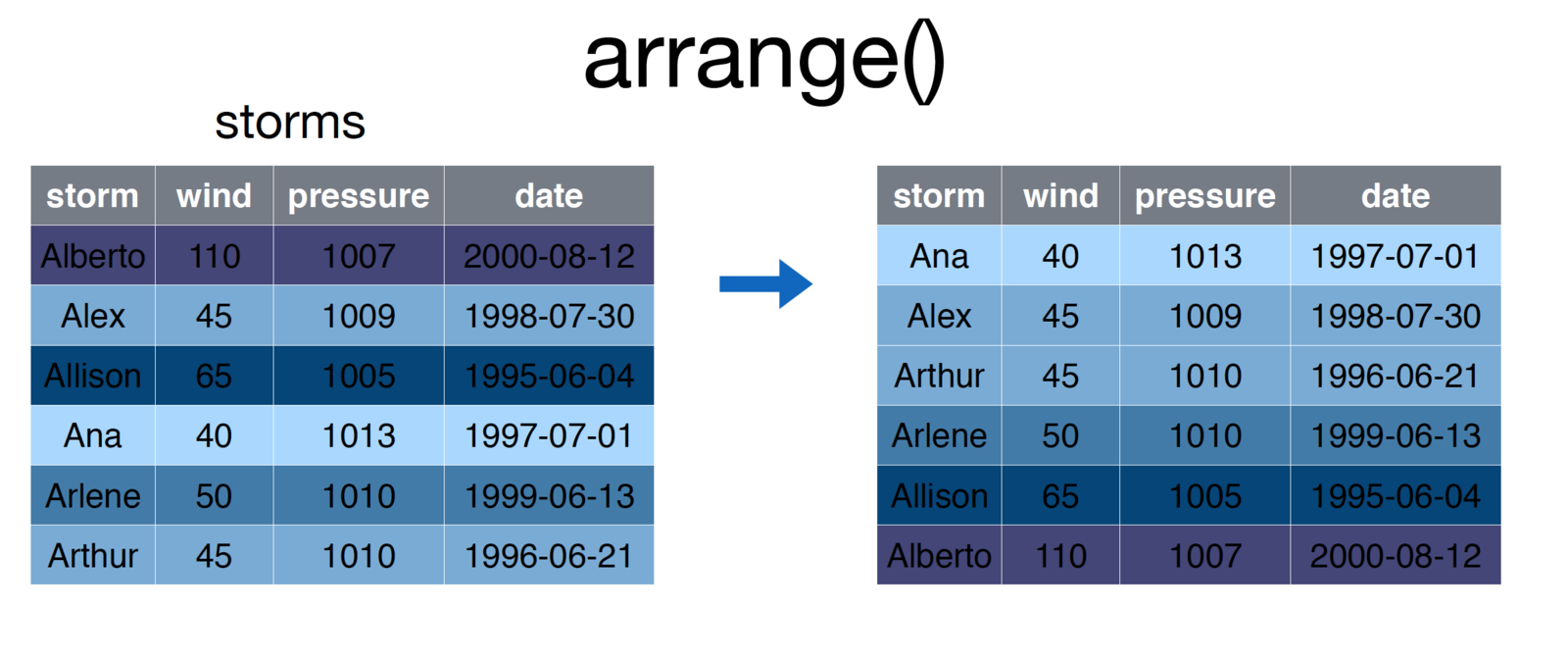
credit: Nathan Stephens, Rstudio
# Arrange storms by wind
storms <- arrange(storms, wind)An example
Some sample data
Who got raises?
# Create a vector of 100 employees ("Employee 1", "Employee 2")
employees <- paste('Employee', 1:100)
# Create a vector of 2014 salaries using the runif function
salaries_2014 <- runif(100, 40000, 50000)
# Create a vector of 2015 salaries that are typically higher 2014
salaries_2015 <- salaries_2014 + runif(100, -5000, 10000)
# Create a data.frame 'salaries' by combining these vectors
salaries <- data.frame(employees, salaries_2014, salaries_2015)# Mutate to calculate raises
salaries <- mutate(salaries, raise = salaries_2015 > salaries_2014)
filter(salaries, raise==TRUE){exercise 2}
Chaining methods
What we've been doing
# What is the class of the vehicle with the best hwy mpg in 1996?
best_car_96 <- filter(vehicles,
year == 1996,
hwy == max(hwy[year == 1996])
)
class_name <- select(best_car_96, class)Chaining methods
Nesting functions
# What is the class of the vehicle with the best hwy mpg in 1996?
class_name <- select(
filter(vehicles,
year == 1996,
hwy == max(hwy[year == 1996])
),
class
)best_car_1996
Chaining methods

The pipe operator
%>%
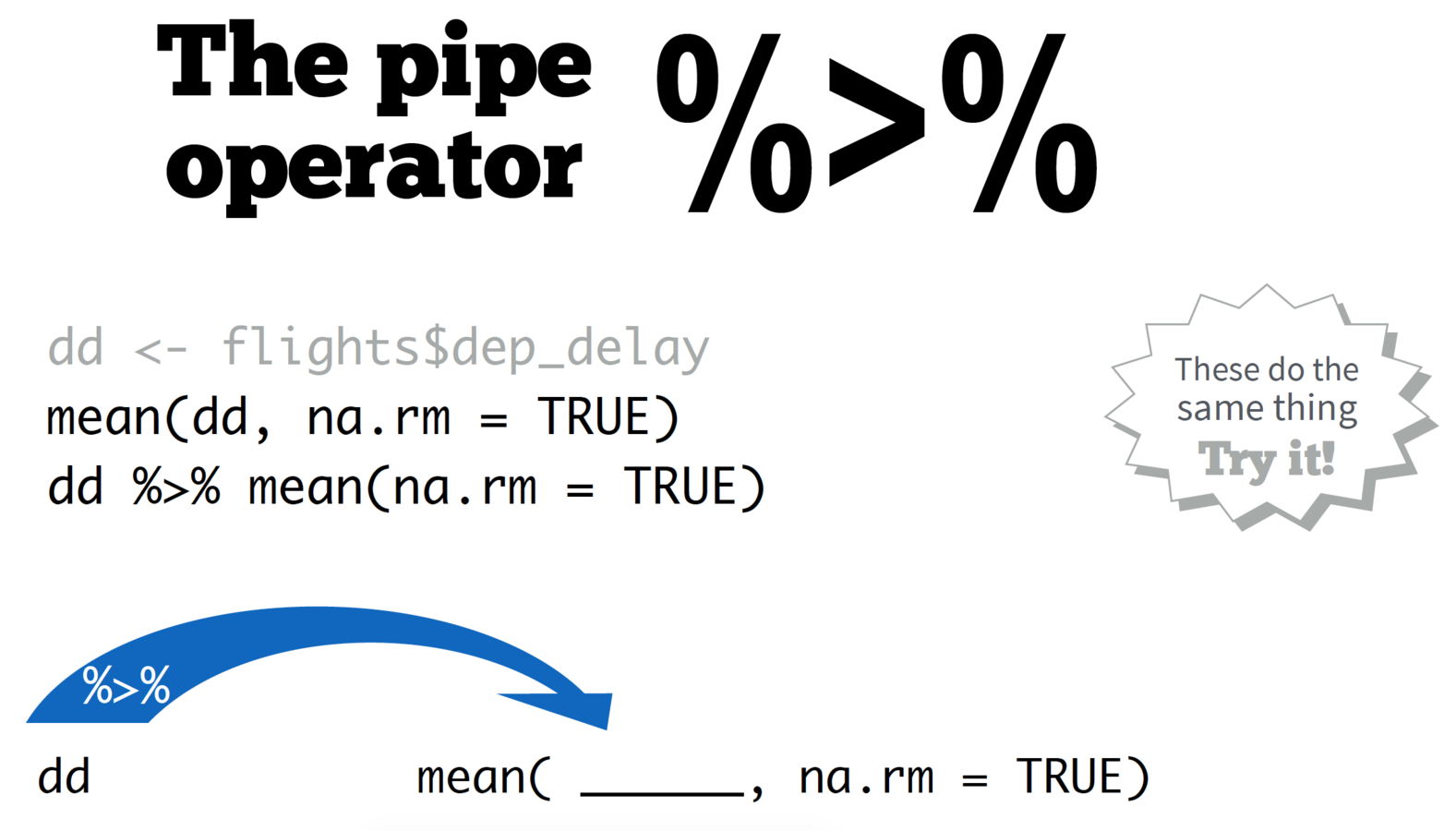
credit: Nathan Stephens, Rstudio
Chaining methods
The pipe operater
# What is the class of the vehicle with the best hwy mpg in 1996?
best_car_96 <- filter(vehicles,
year == 1996,
hwy == max(hwy[year == 1996])
) %>%
select(class)Pass the results in as the first argument to the next function
{exercise 3}
Assignments
Assignment-4: Data wrangling (due Wed. 2/3)
data-wrangling-1
By Michael Freeman




