
Miguel Amaya Camacho
Ingeniero Informático. Socio fundador de Tallanix S.A.C y de Xprende Tech. Activista del Software Libre y miembro fundador de la Comunidad Piurana de Software Libre VICUX y de la Comunidad de Programadores Python Piura.
Ing. José Miguel Amaya Camacho
miguel.amaya99@gmail.com
Los modelos de lenguaje a gran escala (LLMs) son avanzados modelos de machine learning que sobresalen en tareas relacionadas con el lenguaje, como generación de texto, traducción, resumen, respuesta a preguntas, entre otras.
Suelen utilizarse a través de una interfaz de modelo de chat que toma como entrada una lista de mensajes y devuelve un mensaje como salida.
La última generación de LLMs ofrece capacidades adicionales:
Llamadas a herramientas: Muchos modelos populares ofrecen una API para interactuar con herramientas externas, servicios, APIs y bases de datos.
Salida estructurada: Hacer que el modelo responda en un formato estructurado, como JSON que cumple con un esquema definido.
Multimodalidad: La capacidad de trabajar con datos distintos al texto, como imágenes, audio y video.
Integraciones con múltiples proveedores: Anthropic, OpenAI, Ollama, Microsoft Azure, Google Vertex, Amazon Bedrock, Hugging Face, Cohere, y más.
Salida estructurada: Soporte para estructurar salidas.
Soporte para programación asíncrona: Incluye manejo eficiente por lotes, una API de transmisión avanzada y más.
Monitoreo y depuración con LangSmith: Ideal para aplicaciones en producción basadas en LLMs.
Funcionalidades adicionales como uso estandarizado de tokens, limitación de tasas, almacenamiento en caché, entre otros.
langchain-core: Abstracciones base y el Lenguaje de Expresión LangChain.
Paquetes de integración (e.g., langchain-openai, langchain-anthropic).
langchain: Cadenas, agentes y estrategias de recuperación que forman la arquitectura cognitiva de la aplicación.
langchain-community: Integraciones de terceros mantenidas por la comunidad.
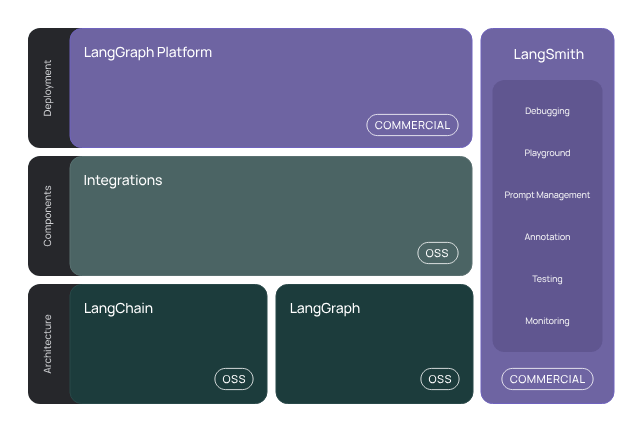
LangGraph: permite crear aplicaciones robustas y con estado para múltiples actores utilizando LLMs, modelando pasos como nodos y bordes en un gráfico. Se integra con LangChain, pero también puede usarse por separado.
LangGraphPlatform: permite desplegar aplicaciones LLM construidas con LangGraph en producción.
LangSmith: Plataforma para desarrolladores que permite depurar, probar, evaluar y monitorear aplicaciones LLM.
Esta aplicación traducirá texto del inglés a otro idioma. Se trata de una aplicación LLM relativamente simple: solo se trata de una única llamada LLM más algunas indicaciones.
Son configuraciones predefinidas que controlan su comportamiento:
Cada mensaje tiene un rol, que define quién "habla" en el contexto del chat:
system: Proporciona instrucciones generales al modelo (por ejemplo, "Eres un asistente que responde con formalidad").
human: Representa lo que el usuario solicita.
assistant: Respuestas generadas por el modelo.
Los mensajes pueden incluir contenido adicional como imágenes o videos, permitiendo interacciones multimodales.
Ayudan a transformar la entrada del usuario y ciertos parámetros en instrucciones para el modelo.
Reciben como entrada un diccionario, donde cada clave representa una variable que se rellenará en la plantilla.
El resultado es un PromptValue, que se puede pasar directamente a un modelo de chat. Este PromptValue también puede convertirse a una cadena de texto (string) o a una lista de mensajes.
String PromptTemplates: Estas plantillas se usan para formatear una sola cadena de texto y suelen aplicarse en entradas más simples.
ChatPromptTemplates: Estas plantillas formatean una lista de mensajes. Consisten en una lista de plantillas individuales.
MessagesPlaceholder: Esta plantilla se usa para insertar una lista de mensajes en un lugar específico dentro de un prompt.
Asignaremos etiquetas a un texto según diferentes categorías o características que puedan ser relevantes para su análisis o clasificación.
Sentimiento
Idioma
Estilo
Temas tratados
Tendencias políticas
Garantizan que los LLMs generen respuestas en un formato estructurado, como JSON, que sigue un esquema definido. Esto facilita la integración de las salidas del modelo en aplicaciones que necesitan formatos específicos.
Proporciona consistencia y confiabilidad en las respuestas del modelo, especialmente útil para aplicaciones complejas que dependen de datos estructurados.
Uso de Modelos Pydantic: Los esquemas se pueden definir usando Pydantic para validar las respuestas.
Parsers de Salida: LangChain incluye parsers específicos para analizar las salidas del modelo y transformarlas según el esquema definido.
Integración con APIs: Uso de métodos como with_structured_output para interactuar directamente con modelos que soporten este tipo de funcionalidad.
En este tutorial, extraeremos información estructurada de texto no estructurado.
En este tutorial, construiremos un motor de búsqueda para un documento PDF. Esto nos permitirá recuperar fragmentos del PDF que sean similares a una consulta de entrada.
Es un sistema que busca y recupera información basada en el significado o contexto de una consulta, en lugar de simplemente buscar palabras exactas. Por ejemplo, si buscas "formas de aumentar ingresos", el sistema puede identificar fragmentos relacionados con "estrategias de crecimiento empresarial" aunque esas palabras exactas no aparezcan en el texto.
Document loader: Se usa para cargar documentos (como PDF, texto, bases de datos, etc.) en un formato que pueda ser procesado por el modelo.
Embeddings: Son representaciones vectoriales del texto, donde el contenido se convierte en un vector numérico que captura su significado. Esto permite comparar textos según su similitud semántica.
Vector store (almacenamiento vectorial): Es una base de datos especializada en guardar estos vectores, lo que permite realizar búsquedas rápidas y eficientes basadas en similitudes entre los embeddings.
Es un enfoque donde el modelo de lenguaje utiliza información recuperada de fuentes externas (como bases de datos o documentos) para generar respuestas más relevantes y precisas. Por ejemplo, un modelo puede combinar su conocimiento general con datos específicos de un documento para responder preguntas sobre ese documento.
By Miguel Amaya Camacho




