Lección 9: De la Función de Transferencia al Espacio de Estados
BE3024 - Sistemas de Control 1 (Biomédica)
2do ciclo, 2024
¿Dónde se ha quedado corta nuestra perspectiva actual de control?
Múltiples entradas y salidas
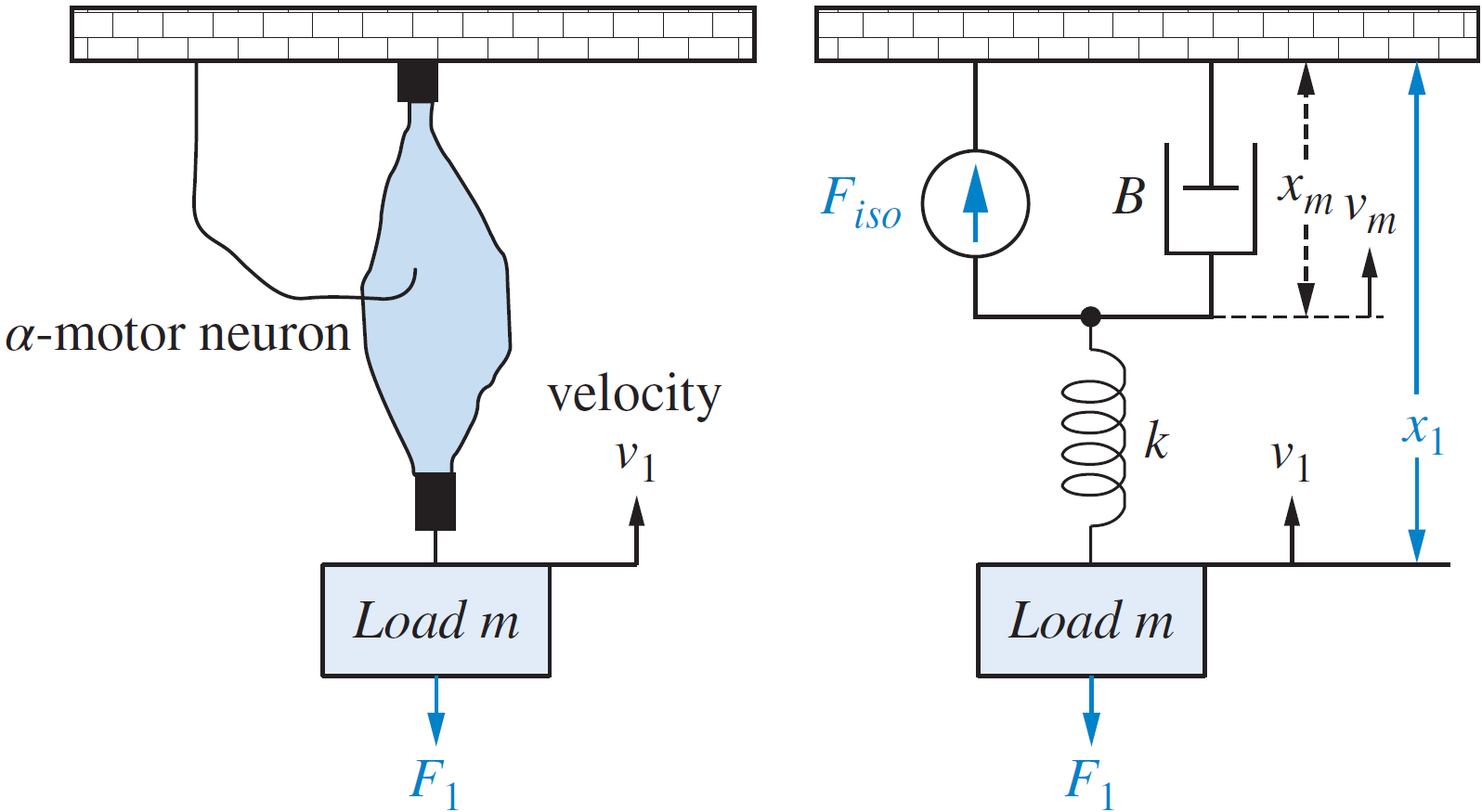
(ms^2+k)X_1(s)-kX_2(s)=F_1(s) \\
(Bs+k)X_2(s)-kX_1(s)=F_{iso}(s)
G_1(s)=\dfrac{X_1(s)}{F_1(s)}=\dfrac{Bs+k}{Bms^3+kms^2+Bks}
G_2(s)=\dfrac{X_1(s)}{F_{iso}(s)}=\dfrac{k}{Bms^3+kms^2+Bks}
(ms^2+k)X_1(s)-kX_2(s)=F_1(s) \\
(Bs+k)X_2(s)-kX_1(s)=F_{iso}(s)
G_1(s)=\dfrac{X_1(s)}{F_1(s)}=\dfrac{Bs+k}{Bms^3+kms^2+Bks}
G_2(s)=\dfrac{X_1(s)}{F_{iso}(s)}=\dfrac{k}{Bms^3+kms^2+Bks}
pero fue necesario hacer \(F_{iso}=0\)
pero fue necesario hacer \(F_1=0\)
(ms^2+k)X_1(s)-kX_2(s)=F_1(s) \\
(Bs+k)X_2(s)-kX_1(s)=F_{iso}(s)
G_1(s)=\dfrac{X_1(s)}{F_1(s)}=\dfrac{Bs+k}{Bms^3+kms^2+Bks}
G_2(s)=\dfrac{X_1(s)}{F_{iso}(s)}=\dfrac{k}{Bms^3+kms^2+Bks}
pero fue necesario hacer \(F_{iso}=0\)
pero fue necesario hacer \(F_1=0\)
¿Y si queremos considerar ambas fuerzas? ¿O quisiéramos analizar qué pasa con \(x_1\) tanto como con \(x_2\)?
Problema: la perspectiva clásica sólo permite una entrada y una salida.
Información oculta
modelo mínimo de Bergman
glucemia
tasa de ingreso de insulina
ingesta de glucosa
Información oculta
modelo mínimo de Bergman
glucemia
tasa de ingreso de insulina
ingesta de glucosa
\begin{aligned}
\dot{x}_1(t) = & -p_1(x_1(t)-G_b)-x_1(t)x_2(t)+D(t)+w(t)\\
\dot{x}_2(t) = & -p_2x_2(t)+p_3(x_3(t)-I_b)\\
\dot{x}_3(t) = & -n(x_3(t)-I_b)+\gamma\max(0, x_1(t)-\sigma)t+u(t)
\end{aligned}
\begin{aligned}
\dot{x}_1(t) = & -p_1(x_1(t)-G_b)-x_1(t)x_2(t)+D(t)+w(t)\\
\dot{x}_2(t) = & -p_2x_2(t)+p_3(x_3(t)-I_b)\\
\dot{x}_3(t) = & -n(x_3(t)-I_b)+\gamma\max(0, x_1(t)-\sigma)t+u(t)
\end{aligned}
glucemia
tasa de ingreso de insulina
ingesta de glucosa
¿Y el resto de información?
\begin{aligned}
\dot{x}_1(t) = & -p_1(x_1(t)-G_b)-x_1(t)x_2(t)+D(t)+w(t)\\
\dot{x}_2(t) = & -p_2x_2(t)+p_3(x_3(t)-I_b)\\
\dot{x}_3(t) = & -n(x_3(t)-I_b)+\gamma\max(0, x_1(t)-\sigma)t+u(t)
\end{aligned}
glucemia
tasa de ingreso de insulina
ingesta de glucosa
¿Y el resto de información?
Problema: al plantear modelos entrada-salida, la perspectiva clásica se pierde de información interna del sistema.
Condiciones iniciales
modelo mínimo de Bergman
glucemia
tasa de ingreso de insulina
ingesta de glucosa
U(s)
Y(s)
G(s)=\dfrac{Y(s)}{U(s)}=\dfrac{-0.01789}{s^3 + 0.2956 s^2 + 0.003996 s}
Con condiciones iniciales iguales a cero.
G(s)=\dfrac{Y(s)}{U(s)}=\dfrac{-0.01789}{s^3 + 0.2956 s^2 + 0.003996 s}
Con condiciones iniciales iguales a cero.
\Rightarrow y(0)=\text{glucemia}=0 \text{ mg/dL}
¡El paciente está muerto!
G(s)=\dfrac{Y(s)}{U(s)}=\dfrac{-0.01789}{s^3 + 0.2956 s^2 + 0.003996 s}
con condiciones iniciales iguales a cero
\Rightarrow y(0)=\text{glucemia}=0 \text{ mg/dL}
el paciente está muerto!
Problema: la perspectiva clásica no puede (o tiene una forma extraña de) lidiar con condiciones iniciales distintas a cero.
La abstracción de \(\mathcal{L}\)
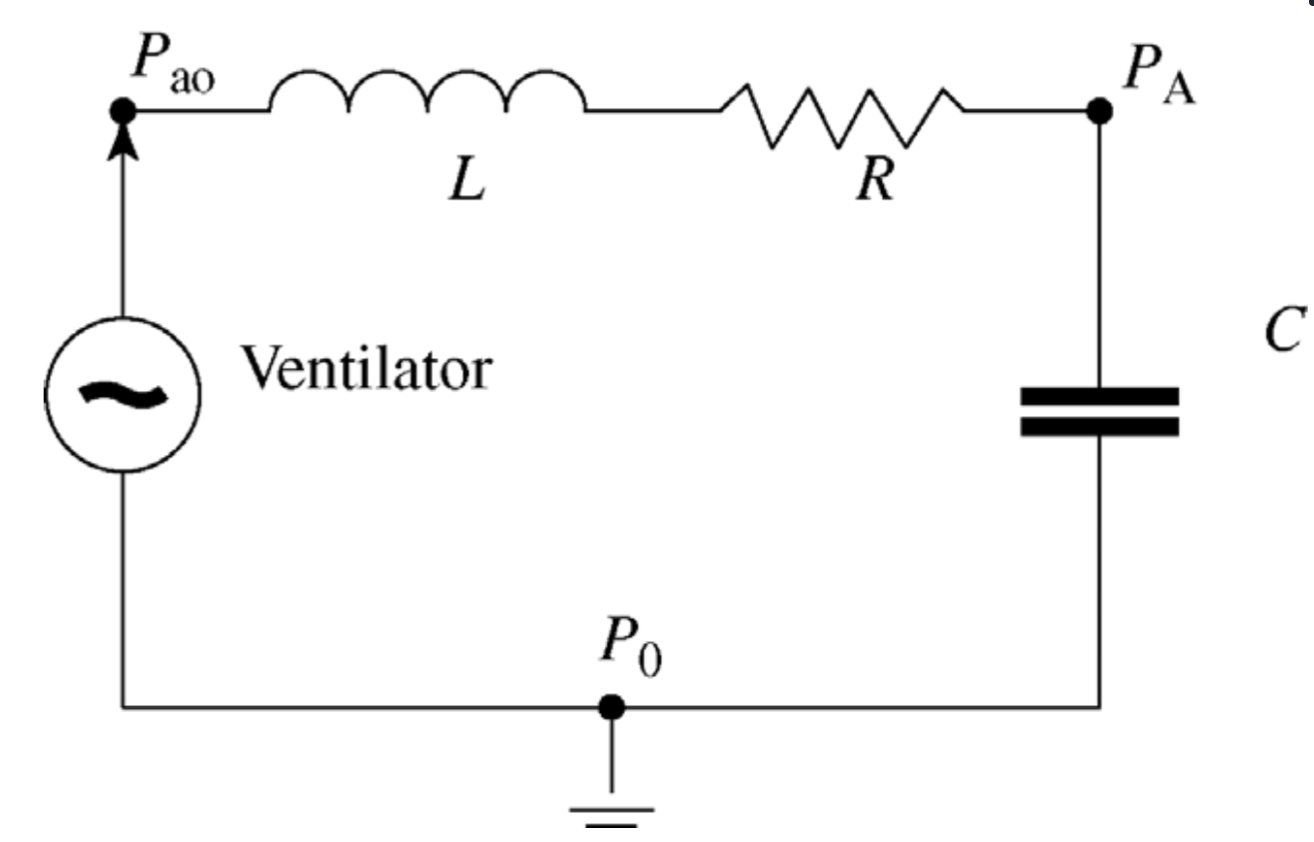
L_1
R_1
G_1(s)=\dfrac{Q(s)}{P_{ao}(s)}
Para diseñar esquema de ventilación \(C_1(s)\) para paciente con neumonía severa.
Cap_1
L_2
R_2
El paciente presentó una mejoría significativa.
Cap_2
G_1(s) \to G_2(s)
L_2
R_2
Sin embargo, luego de unos días, el esquema \(C_1(s)\) le causa hiperoxia.
G_1(s) \to G_2(s)
El paciente presentó una mejoría significativa.
Cap_2
L_2
R_2
¿Qué pasó?
\(C_1(s)\) debería haber cambiado cuando el paciente pasó de \(G_1(s)\) a \(G_2(s)\).
G_1(s) \to G_2(s)
El paciente presentó una mejoría significativa.
Sin embargo, luego de unos días, el esquema \(C_1(s)\) le causa hiperoxia.
Cap_2
C_1(s)=\displaystyle\int_{-\infty}^{\infty}c_1(t)e^{-st}dt
C_1(s)=\displaystyle\int_{-\infty}^{\infty}c_1(t)e^{-st}dt
Laplace se "come" al dominio de tiempo
C_1(s)=\displaystyle\int_{-\infty}^{\infty}c_1(t)e^{-st}dt
Laplace se "come" al dominio de tiempo
Problema: la transformada de Laplace asume que los sistemas presentan un mismo comportamiento desde el inicio hasta el final del universo en términos de tiempo.
¿Cómo resolvemos estos problemas?
G = tf(-0.017892, [1, 0.2956, 0.00399588, 0]);
sys = ss(G)G = tf(-0.017892, [1, 0.2956, 0.00399588, 0]);
sys = ss(G)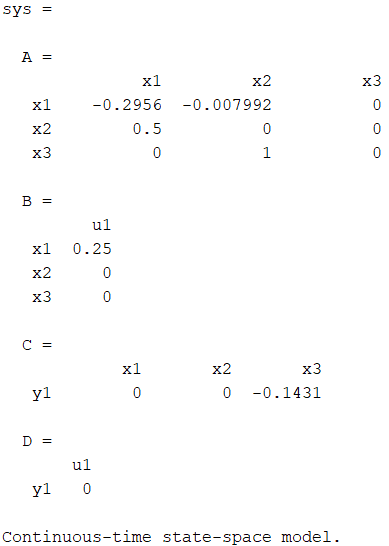
G = tf(-0.017892, [1, 0.2956, 0.00399588, 0]);
sys = ss(G)¿Qué es esto?
Es el mismo sistema pero en una representación distinta.
Representación en el Espacio de Estados
G(s)=\dfrac{Y(s)}{U(s)}
\begin{cases}
\dot{\mathbf{x}}(t)=\mathbf{A}\mathbf{x}(t)+\mathbf{B}\mathbf{u}(t) \\
\mathbf{y}(t)=\mathbf{C}\mathbf{x}(t)+\mathbf{D}\mathbf{u}(t)
\end{cases}
\begin{cases}
\dot{\mathbf{x}}(t)=\mathbf{A}\mathbf{x}(t)+\mathbf{B}\mathbf{u}(t) \\
\mathbf{y}(t)=\mathbf{C}\mathbf{x}(t)+\mathbf{D}\mathbf{u}(t)
\end{cases}
\mathbf{u}=\begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_m \end{bmatrix}
vector de entradas
\mathbf{y}=\begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_p \end{bmatrix}
vector de salidas
\begin{cases}
\dot{\mathbf{x}}(t)=\mathbf{A}\mathbf{x}(t)+\mathbf{B}\mathbf{u}(t) \\
\mathbf{y}(t)=\mathbf{C}\mathbf{x}(t)+\mathbf{D}\mathbf{u}(t)
\end{cases}
\mathbf{x}=\begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ \vdots \\ x_n \end{bmatrix}
vector de estado
variables de estado
matrices del sistema
El estado de un sistema es una colección de variables (de estado) o cantidades físicas que caracteriza completamente (en la ausencia de excitaciones externas) su comportamiento actual y puede usarse para predecir su comportamiento futuro.
¿Ventajas de esta representación?
- Multivariable
- Perspectiva completa
- Condiciones iniciales arbitrarias
- Permite sistemas que varían en el tiempo
- Permite sistemas no lineales
- Se presta mejor a métodos computacionales
Repaso de conceptos matemáticos necesarios
Vectores
Un vector \(\mathbf{v}\) es una lista ordenada de números reales (escalares) \(v_1,v_2,...,v_n\) apilados verticalmente de la forma: $$\qquad$$ $$\mathbf{v}=\begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix}=\begin{bmatrix} v_1 & v_2 & \cdots & v_n \end{bmatrix}^\top \in\mathbb{R}^n$$ $$\qquad$$
Puede emplearse la transpuesta para obtener un vector fila a partir de un vector columna.
Gráficamente, puede representarse a un vector como una flecha dirigida desde el origen hasta el punto situado en las coordenadas dadas por los elementos del vector.
Sin embargo, puede considerarse también al vector como el punto mismo dentro de algún espacio \(n\)-dimensional.

\mathbf{v}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}
\mathbf{s}=\begin{bmatrix} 3 & 4 & 5 \end{bmatrix}^\top
Escalamiento
Se reparte el escalar, \(\alpha\in\mathbb{R}\), elemento por elemento.
Si \(\alpha>0\) entonces la operación sólo cambia el tamaño del vector, mientras que si \(\alpha<0\) también le cambia el sentido.

Suma y resta
Se realiza elemento por elemento, sólo está definida entre vectores de la misma dimensión.
Claramente \(\mathbf{v}+\mathbf{w}\) no está definido, sin embargo
\mathbf{v}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}, \qquad \mathbf{w}=\begin{bmatrix} -1 \\ 0 \\ 2 \end{bmatrix}, \qquad \mathbf{z}=\begin{bmatrix} 3 \\ 2 \end{bmatrix}
\mathbf{v}+\mathbf{z}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}+\begin{bmatrix} 3 \\ 2 \end{bmatrix}=\begin{bmatrix} 4 \\ 4 \end{bmatrix}

Producto interno
El producto interno entre dos vectores de la misma dimensión se define como la suma de los productos, elemento por elemento, de dos vectores \(\mathbf{v}, \mathbf{w} \in \mathbb{R}^n\).
\mathbf{v} \cdot \mathbf{w}\equiv \langle \mathbf{v}, \mathbf{w} \rangle\equiv \mathbf{v}^\top\mathbf{w}=\displaystyle\sum_{i=1}^{n} v_iw_i
\begin{bmatrix} 1 \\ 2 \\ 5\end{bmatrix} \cdot \begin{bmatrix} 3 \\ 4 \\ -1 \end{bmatrix}=(1)(3)+(2)(4)+(5)(-1)=6
Norma
El producto interno de un vector consigo mismo brinda una noción de magnitud denominada norma.
La más común es la norma Euclideana, la cual corresponde a la longitud del vector y se denota como:
\|\mathbf{v}\|_2 \equiv \|\mathbf{v}\|=\sqrt{\mathbf{v} \cdot \mathbf{v}}=\displaystyle \sqrt{\sum_{i=1}^{n}v_i^2}
\mathbf{x}=\begin{bmatrix} 1 & 2 & 3 \end{bmatrix}^\top, \quad \|\mathbf{x}\|=\sqrt{1^2+2^2+3^2}=\sqrt{14}
Existen otras normas además de la Euclideana.
Se emplea el sub-índice para diferenciarlas entre sí.
Norma del valor absoluto (o Manhattan):
Norma infinito (o del supremo):
\|\mathbf{v}\|_1 =\displaystyle \sum_{i=1}^{n} |v_i|
\|\mathbf{v}\|_\infty =\displaystyle \max_{1\le i \le n} |v_i|
Propiedades del producto interno
\(\mathbf{v} \cdot \mathbf{w}=\mathbf{w} \cdot \mathbf{v}\)
\(\mathbf{v} \cdot (\alpha\mathbf{w})=\alpha(\mathbf{v} \cdot \mathbf{w})\)
\(\mathbf{u} \cdot (\mathbf{v}+\mathbf{w})=\mathbf{u} \cdot \mathbf{v}+\mathbf{u} \cdot \mathbf{w}\)
\( \|\mathbf{v} + \mathbf{w}\|^2 = \|\mathbf{v}\|^2+2(\mathbf{v}\cdot\mathbf{w})+\|\mathbf{w}\|^2\)
\( \|\mathbf{v} + \mathbf{w}\|\le \|\mathbf{v}\|+\|\mathbf{w}\|\) (desigualdad triangular)
\(\mathbf{v} \cdot \mathbf{w}=\|\mathbf{v}\|\|\mathbf{w}\|\cos\theta\)

Ortogonalidad
Si \(\mathbf{v}\in\mathbb{R}^n\) presenta \(\|\mathbf{v}\|=1\) entonces se conoce como vector unitario y puede denotarse como \(\hat{\mathbf{v}}\).
Puede obtenerse un vector unitario a partir de cualquier vector mediante la normalización \(\hat{\mathbf{w}}=\mathbf{w}/\|\mathbf{w}\|\).
Si el producto interno entre dos vectores es cero, entonces se dice que estos son ortogonales (si y sólo si).
Si, adicionalmente, dos vectores ortogonales tienen norma unitaria se dice que estos son ortonormales.

ortogonales más no ortonormales
ortonormales
Matrices
El segundo objeto de interés en el algebra lineal corresponde a las matrices, las cuales pueden considerarse como una generalización para los vectores.
Se define una matriz como un arreglo rectangular de elementos con \(m\) filas y \(n\) columnas.
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix} \in\mathbb{R}^{m \times n}
Para cada elemento: \(a_{ij}\in\mathbb{R}\).
Si \(m=n\) se dice que la matriz es cuadrada.
Si ya sea \(n=1\) o \(m=1\) entonces se obtiene un vector columna o fila respectivamente.
Las operaciones de suma, resta y escalamiento funcionan igual para matrices que con vectores.
La operación de transposición intercambia las filas con las columnas de la matriz. Si \(\mathbf{A}\in\mathbb{R}^{m \times n}\) entonces \(\mathbf{A}^\top\in\mathbb{R}^{n \times m}\) y recibe el nombre de la transpuesta de \(\mathbf{A}\).
Multiplicación de matrices
Es una operación poco intuitiva ya que tiene que tomar en consideración la diversidad de dimensiones de las matrices.
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix}\in\mathbb{R}^{m \times n}\equiv \begin{bmatrix} \mathbf{a}_1 \\ \mathbf{a}_2 \\ \vdots \\ \mathbf{a}_m \end{bmatrix}, \quad \mathbf{a}_i=\begin{bmatrix} a_{i1} & a_{i2} & \cdots & a_{in} \end{bmatrix}
\mathbf{B}=\begin{bmatrix} b_{11} & b_{12} & \cdots & b_{1p} \\ b_{21} & b_{22} & \cdots & b_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ b_{n1} & b_{n2} & \cdots & b_{np} \end{bmatrix}\in\mathbb{R}^{n \times p}\equiv \begin{bmatrix} \mathbf{b}_1 & \mathbf{b}_2 & \cdots & \mathbf{b}_p \end{bmatrix}, \quad \mathbf{b}_j=\begin{bmatrix} b_{j1} \\ b_{j2} \\ \vdots \\ b_{jn} \end{bmatrix}
Entonces se define la multiplicación \(\mathbf{A}\mathbf{B}\) entre matrices como
es decir, se efectúa el producto interno de cada fila de \(\mathbf{A}\) con cada columna de \(\mathbf{B}\).
Por lo tanto, para que la multiplicación entre matrices esté definida, el número de columnas de \(\mathbf{A}\) debe ser igual al número de filas de \(\mathbf{B}\).
De esto se concluye que la multiplicación entre matrices no es conmutativa.
\mathbf{AB}=\begin{bmatrix} \mathbf{a}_1 \cdot \mathbf{b}_1 & \mathbf{a}_1 \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_1 \cdot \mathbf{b}_p \\ \mathbf{a}_2 \cdot \mathbf{b}_1 & \mathbf{a}_2 \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_2 \cdot \mathbf{b}_p \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{a}_m \cdot \mathbf{b}_1 & \mathbf{a}_m \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_m \cdot \mathbf{b}_p \end{bmatrix}\in\mathbb{R}^{m \times p}
Por ejemplo, si se tienen las matrices
claramente \(\mathbf{C}\mathbf{D}\) no está definida, sin embargo
\mathbf{C}=\begin{bmatrix} 3 & 1 & -2 \\ 4 & 0 & 6 \end{bmatrix}\in\mathbb{R}^{2 \times 3}, \qquad \mathbf{D}=\begin{bmatrix} 1 & 0 \\ -1 & 1 \end{bmatrix}\in\mathbb{R}^{2 \times 2}

\mathbf{D}\mathbf{C}
Inversa de una matriz
Operación análoga a la división para escalares, bajo la definición de un recíproco o inverso multiplicativo.
Cumple con la relación
donde \(\mathbf{A}^{-1}\) se denomina la inversa de \(\mathbf{A}\).
Dado que la multiplicación por la inversa es conmutativa, se concluye que esta existe sólo para matrices cuadradas.
Sin embargo, no toda matriz cuadrada posee inversa y se refiere a ellas como singulares.
\mathbf{A}\mathbf{A}^{-1}=\mathbf{A}^{-1}\mathbf{A}=\mathbf{I}
En general, los procedimientos analíticos para encontrar la inversa de una matriz son tediosos y complicados, especialmente para matrices de dimensiones superiores. Por esta razón, a menos que se trate de una matriz de \(2 \times 2\), se acudirá frecuentemente a métodos numéricos para determinarla.
Para una matriz de \(2 \times 2\) puede emplearse la fórmula:
\mathbf{A}=\begin{bmatrix} a & b \\ c & d \end{bmatrix}, \qquad \mathbf{A}^{-1}=\dfrac{1}{\mathrm{det}(\mathbf{A})}\begin{bmatrix} d & -b \\ -c & a \end{bmatrix}
Matrices cuadradas de importancia
Matriz cero
Matrices diagonales
Matriz identidad (el "uno" matricial)
Matrices simétricas
Matrices antisimétricas
\mathbf{0}=\begin{bmatrix} 0 & 0 & \cdots & 0 \\ 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 0 \end{bmatrix}
\mathbf{I}=\begin{bmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \end{bmatrix}
\mathbf{A}=\begin{bmatrix} a_{11} & 0 & \cdots & 0 \\ 0 & a_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & a_{nn} \end{bmatrix}
\mathbf{A}^\top=\mathbf{A}
\mathbf{A}^\top=-\mathbf{A}
Matrices triangulares superiores
Matrices ortogonales
Matrices triangulares inferiores
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ 0 & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & a_{nn} \end{bmatrix}
\mathbf{A}=\begin{bmatrix} a_{11} & 0 & \cdots & 0 \\ a_{21} & a_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \end{bmatrix}
\mathbf{A}^\top=\mathbf{A} \newline
\mathbf{A}\mathbf{A}^\top=\mathbf{A}^\top\mathbf{A}=\mathbf{I} \newline
\mathbf{A}^{-1}=\mathbf{A}^\top
Determinante
Permite obtener un escalar a partir de una matriz cuadrada.
Se emplea en la solucion de sistemas de ecuaciones lineales, para definir una fórmula general para invertir matrices y para determinar el factor de escalamiento de una transformación lineal.
No existe una fórmula general para el determinante ya que la complejidad de determinar el mismo depende de la dimensión de la matriz.
Sin embargo, existen las siguientes fórmulas:
\mathbf{A}=\begin{bmatrix} a & b \\ c & d \end{bmatrix}, \qquad \mathrm{det}(\mathbf{A})\equiv|A|=ad-bc \newline
\mathbf{B}=\begin{bmatrix} a & b & c \\ d & e & f \\ g & h & i \end{bmatrix}, \qquad \mathrm{det}(\mathbf{B})=aei+bfg+cdh-(gec+hfa+idb)
Algunas identidades
\(\mathbf{A}+\mathbf{B}=\mathbf{B}+\mathbf{A}\)
\(\mathbf{A}\mathbf{B}\ne \mathbf{B}\mathbf{A}\)
\(\mathbf{A}+(\mathbf{B}+\mathbf{C})=(\mathbf{A}+\mathbf{B})+\mathbf{C}\)
\(\mathbf{A}(\mathbf{B}\mathbf{C})=(\mathbf{A}\mathbf{B})\mathbf{C}\)
\((\mathbf{A}+\mathbf{B})^\top=\mathbf{A}^\top+\mathbf{B}^\top\)
\((\mathbf{A}\mathbf{B})^\top=\mathbf{B}^\top\mathbf{A}^\top\)
\((\mathbf{A}+\mathbf{B})^{-1}\ne \mathbf{A}^{-1}+\mathbf{B}^{-1}\)
\((\mathbf{A}\mathbf{B})^{-1}=\mathbf{B}^{-1}\mathbf{A}^{-1}\)
\(\left(\mathbf{A}^{-1}\right)^{-1}=\mathbf{A}\)
\(\mathrm{det}(\mathbf{A}\mathbf{B})=\mathrm{det}(\mathbf{A})\mathrm{det}(\mathbf{B})\)
\(\mathrm{det}\left(\mathbf{A}^\top\right)=\mathrm{det}(\mathbf{A})\)
\(\mathrm{det}\left(\mathbf{A}^{-1}\right)=1/\mathrm{det}(\mathbf{A})\)
Eigenvalores y eigenvectores
Si se tiene una matriz \(\mathbf{A}\in\mathbb{R}^{n\times n}\) entonces su polinomio característico está dado por:
Los eigenvalores de \(\mathbf{A}\) son las soluciones de la ecuación característica:
son por lo general complejos y \(\mathbf{A}\) (en este caso) siempre tendrá \(n\) eigenvalores (puede que algunos se repitan).
\chi_\mathbf{A}(\lambda)=\det(\lambda\mathbf{I}-\mathbf{A})=\lambda^n+\alpha_{n-1}\lambda^{n-1}+\cdots+\alpha_0
\chi_\mathbf{A}(\lambda)=\det(\lambda\mathbf{I}-\mathbf{A})=0
Se llama espectro de \(\mathbf{A}\) al conjunto formado por todos los eigenvalores de \(\mathbf{A}\) y se denota como
Los eigenvalores resuelven el problema de eigenvalores en álgebra lineal:
donde \(\mathbf{v}_i\in\mathbb{R}^n\) se conocen como eigenvectores y hay uno asociado a cada eigenvalor de \(\mathbf{A}\). En otras palabras, los eigenvectores son aquellos a los cuales la aplicación de la matriz \(\mathbf{A}\) es equivalente a un escalamiento de magnitud igual a los eigenvalores.
\sigma\left(\mathbf{A}\right)=\left\{ \lambda_1, \lambda_2, ..., \lambda_n\right\}
\mathbf{A}\mathbf{v}_i=\lambda_i\mathbf{v}_i
Cálculo vectorial y matricial
Sea \(\mathbf{x}\in \mathbb{R}^n\). Una función escalar multivariable está definida como \(f:\mathbb{R}^n \to \mathbb{R}\) tal que
f(\mathbf{x})=f(x_1,x_2,...,x_n)
donde \(x_i\) corresponde a los elementos de \(\mathbf{x}\). Se define el gradiente de la función escalar como el vector columna dado por:
\nabla f(\mathbf{x})=\begin{bmatrix} \frac{\partial f(\mathbf{x})}{\partial x_1} \\ \frac{\partial f(\mathbf{x})}{\partial x_2} \\ \vdots \\ \frac{\partial f(\mathbf{x})}{\partial x_n} \end{bmatrix} \in\mathbb{R}^n
Un campo vectorial (o función vectorial) está definido como
\(\mathbf{f}:\mathbb{R}^n \to \mathbb{R}^m\) tal que
\mathbf{f}(\mathbf{x})=\mathbf{f}(x_1,x_2,...,x_n)=
\begin{bmatrix} f_1(\mathbf{x}) \\ f_2(\mathbf{x}) \\ \vdots \\ f_m(\mathbf{x}) \end{bmatrix}=
\begin{bmatrix} f_1(x_1,x_2,...,x_n) \\ f_2(x_1,x_2,...,x_n) \\ \vdots \\ f_m(x_1,x_2,...,x_n) \end{bmatrix}\in\mathbb{R}^m
en donde \(f_1,f_2,...,f_m\) son funciones escalares multivariable.
Se define el jacobiano del campo vectorial como la matriz tal que
D\mathbf{f}(\mathbf{x})=\mathbf{f}'(\mathbf{x})=\dfrac{d \mathbf{f}(\mathbf{x})}{d \mathbf{x}}=
\begin{bmatrix} \frac{\partial f_1(\mathbf{x})}{\partial x_1} & \cdots & \frac{\partial f_1(\mathbf{x})}{\partial x_n} \\
\vdots & \ddots & \vdots \\ \frac{\partial f_m(\mathbf{x})}{\partial x_1} & \cdots & \frac{\partial f_m(\mathbf{x})}{\partial x_n} \end{bmatrix}\in\mathbb{R}^{m \times n}
El jacobiano es, efectivamente, la derivada del campo vectorial.
Si \(\mathbf{A}(t)\) es una matriz que depende del tiempo tal que
\mathbf{A}(t)=\begin{bmatrix} f_{11}(t) & \cdots & f_{1n}(t) \\
\vdots & \ddots & \vdots \\ f_{m1}(t) & \cdots & f_{mn}(t) \end{bmatrix}\in\mathbb{R}^{m \times n}
entonces, se definen
\dfrac{d \mathbf{A}(t)}{dt}=\begin{bmatrix} \frac{d f_{11}(t)}{dt} & \cdots & \frac{d f_{1n}(t)}{dt} \\
\vdots & \ddots & \vdots \\ \frac{d f_{m1}(t)}{dt} & \cdots & \frac{d f_{mn}(t)}{dt} \end{bmatrix}
\displaystyle \int \mathbf{A}(t) dt=\begin{bmatrix} \int f_{11}(t) dt & \cdots & \int f_{1n}(t) dt \\
\vdots & \ddots & \vdots \\ \int f_{m1}(t) dt & \cdots & \int f_{mn}(t) dt \end{bmatrix}
BE3024 - Lecture 9 (2024)
By Miguel Enrique Zea Arenales



