Repaso de álgebra lineal
BE3027 - Robótica Médica
el alto grado de movilidad que presenta la gran mayoría de robots hace prácticamente imposible resolver analíticamente problemas de aplicación no triviales
¿Por qué
¿Por qué
debe recurrirse frecuentemente a métodos numéricos que implican múltiples operaciones entre matrices y vectores, por ende, álgebra lineal
el álgebra lineal también estudia a los espacios vectoriales y las transformaciones lineales que pueden realizarse sobre ellos, lo cual brindará una notación estándar de importancia en robótica
¿Por qué
Vectores y espacios vectoriales
un vector \(\mathbf{v}\) es una lista ordenada de números reales (escalares) \(v_1,v_2,...,v_n\) apilados verticalmente de la forma:
\mathbf{v}=\begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix}=\begin{bmatrix} v_1 & v_2 & \cdots & v_n \end{bmatrix}^\top \in\mathbb{R}^n
puede emplearse la transpuesta para obtener un vector fila a partir de un vector columna.
gráficamente, puede representarse a un vector como una flecha dirigida desde el origen hasta el punto situado en las coordenadas dadas por los elementos del vector

\mathbf{v}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}
\mathbf{s}=\begin{bmatrix} 3 & 4 & 5 \end{bmatrix}^\top
gráficamente, puede representarse a un vector como una flecha dirigida desde el origen hasta el punto situado en las coordenadas dadas por los elementos del vector
\mathbf{v}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}
\mathbf{s}=\begin{bmatrix} 3 & 4 & 5 \end{bmatrix}^\top
sin embargo, puede considerarse también al vector como un objeto (el punto mismo) dentro de algún espacio \(n\)-dimensional
se reparte el escalar, \(\alpha\in\mathbb{R}\), elemento por elemento

Escalamiento
se reparte el escalar, \(\alpha\in\mathbb{R}\), elemento por elemento
Escalamiento
si \(\alpha>0\) entonces la operación sólo cambia el tamaño del vector, mientras que si \(\alpha<0\) también le cambia el sentido
elemento por elemento, sólo está definida entre vectores de la misma dimensión
\mathbf{v}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}, \qquad \mathbf{w}=\begin{bmatrix} -1 \\ 0 \\ 2 \end{bmatrix}, \qquad \mathbf{z}=\begin{bmatrix} 3 \\ 2 \end{bmatrix}
\mathbf{v}+\mathbf{z}=\begin{bmatrix} 1 \\ 2 \end{bmatrix}+\begin{bmatrix} 3 \\ 2 \end{bmatrix}=\begin{bmatrix} 4 \\ 4 \end{bmatrix}
Suma y resta
claramente \(\mathbf{v}+\mathbf{w}\) no está definido, sin embargo

se define como la suma de los productos, elemento por elemento, de dos vectores \(\mathbf{v}, \mathbf{w} \in \mathbb{R}^n\) de la misma dimensión
\mathbf{v} \cdot \mathbf{w}\equiv \langle \mathbf{v}, \mathbf{w} \rangle\equiv \mathbf{v}^\top\mathbf{w}=\displaystyle\sum_{i=1}^{n} v_iw_i
\begin{bmatrix} 1 \\ 2 \\ 5\end{bmatrix} \cdot \begin{bmatrix} 3 \\ 4 \\ -1 \end{bmatrix}=(1)(3)+(2)(4)+(5)(-1)=6
Producto interno
el producto interno de un vector consigo mismo brinda una noción de magnitud denominada norma, la más común es la norma Euclideana (longitud del vector) y se denota como
\|\mathbf{v}\|_2 \equiv \|\mathbf{v}\|=\sqrt{\mathbf{v} \cdot \mathbf{v}}=\displaystyle \sqrt{\sum_{i=1}^{n}v_i^2}
\mathbf{x}=\begin{bmatrix} 1 & 2 & 3 \end{bmatrix}^\top, \quad \|\mathbf{x}\|=\sqrt{1^2+2^2+3^2}=\sqrt{14}
Norma
existen otras normas además de la Euclideana y se emplea el sub-índice para diferenciarlas entre sí
norma del valor absoluto:
\|\mathbf{v}\|_1 =\displaystyle \sum_{i=1}^{n} |v_i|
\|\mathbf{v}\|_\infty =\displaystyle \max_{1\le i \le n} |v_i|
norma uniforme (o del supremo):
\(\mathbf{v} \cdot \mathbf{w}=\mathbf{w} \cdot \mathbf{v}\)
\(\mathbf{v} \cdot (\alpha\mathbf{w})=\alpha(\mathbf{v} \cdot \mathbf{w})\)
\(\mathbf{u} \cdot (\mathbf{v}+\mathbf{w})=\mathbf{u} \cdot \mathbf{v}+\mathbf{u} \cdot \mathbf{w}\)
\( \|\mathbf{v} + \mathbf{w}\|^2 = \|\mathbf{v}\|^2+2(\mathbf{v}\cdot\mathbf{w})+\|\mathbf{w}\|^2\)
\( \|\mathbf{v} + \mathbf{w}\|\le \|\mathbf{v}\|+\|\mathbf{w}\|\)
\(\mathbf{v} \cdot \mathbf{w}=\|\mathbf{v}\|\|\mathbf{w}\|\cos\theta\)

Propiedades del producto interno
si \(\mathbf{v}\in\mathbb{R}^n\) presenta \(\|\mathbf{v}\|=1\) entonces se conoce como vector unitario y puede denotarse como \(\hat{\mathbf{v}}\)
puede obtenerse un vector unitario a partir de cualquier vector mediante la normalización \(\hat{\mathbf{w}}=\mathbf{w}/\|\mathbf{w}\|\)
Ortogonalidad
si el producto interno entre dos vectores es cero, entonces se dice que estos son ortogonales
si, adicionalmente, dos vectores ortogonales tienen norma unitaria se dice que estos son ortonormales
Ortogonalidad

ortogonales más no ortonormales
ortonormales
el resultado es un vector que es ortogonal a los vectores empleados para generarlo, esta operación se encuentra definida exclusivamente para vectores en \(\mathbb{R}^3\) de la forma
\mathbf{u}=\begin{bmatrix} u_1 & u_2 & u_3 \end{bmatrix}^\top, \qquad \mathbf{v}=\begin{bmatrix} v_1 & v_2 & v_3 \end{bmatrix}^\top
\mathbf{u}=\mathbf{u}\times \mathbf{v}=\begin{bmatrix} u_2v_3-u_3v_2 \\ u_3v_1-u_1v_3 \\ u_1v_2-u_2v_1 \end{bmatrix}
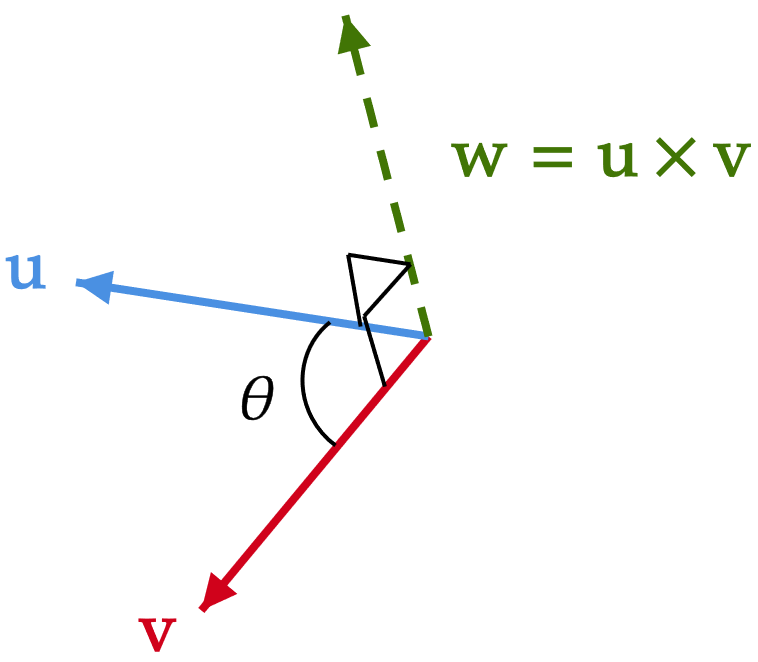
Producto cruz
\|\mathbf{u}\times \mathbf{v}\|=\|\mathbf{u}\|\|\mathbf{v}\|\sin\theta
por ejemplo:
\begin{bmatrix} 4 \\ -2 \\ 1 \end{bmatrix} \times \begin{bmatrix} 1 \\ -1 \\ 3 \end{bmatrix}=\begin{bmatrix} (-2)(3)-(1)(-1) \\ (1)(1)-(4)(3) \\ (4)(-1)-(-2)(1) \end{bmatrix}=\begin{bmatrix} -5 \\ -11 \\ -2 \end{bmatrix}
\begin{bmatrix} 4 \\ -2 \\ 1 \end{bmatrix} \cdot \begin{bmatrix} -5 \\ -11 \\ -2 \end{bmatrix}=0, \qquad \begin{bmatrix} 1 \\ -1 \\ 3 \end{bmatrix} \cdot \begin{bmatrix} -5 \\ -11 \\ -2 \end{bmatrix}=0
en donde puede verse que:
las operaciones de suma y escalamiento toman uno o mas vectores en \(\mathbb{R}^n\) y retornan otro vector en \(\mathbb{R}^n\), el concepto abstracto detrás de esto nos permite defnir una estructura llamada grupo, el cual requiere un conjunto de objetos \(\mathcal{G}\) y una operación entre ellos \(\cdot\) que cumplan con los llamados axiomas de grupo
Grupos
clausura
para todo \(a,b \in \mathcal{G}\), el resultado de la operación \(a \cdot b\) también se encuentra dentro de \(\mathcal{G}\)
asociatividad
para todo \(a, b, c \in \mathcal{G}\) se cumple que \((a \cdot b)\cdot c=a \cdot (b \cdot c)\)
Grupos
identidad
existe un unico elemento \(e \in \mathcal{G}\) tal que \(a \cdot e=e \cdot a=a\)
inversa
para cada \(a \in \mathcal{G}\) existe un elemento \(b \in \mathcal{G}\), denotado
\(b = a^{-1}\) (o \(b = -a\) si se emplea la suma), tal que
\(a \cdot b=b \cdot a = e\)
Grupos
toma lo observado con vectores, su adición y su escalamiento para refinar la definición de grupo
se define un espacio vectorial (sobre los reales) como un conjunto \(\mathcal{V}\) para el cual se definen dos operaciones, la multiplicación por un escalar y la suma de vectores, que cumplan con las siguientes 10 propiedades
Espacios vectoriales
1. \(\mathbf{x} + \mathbf{y} \in \mathcal{V}\) para todo \(\mathbf{x}, \mathbf{y} \in \mathcal{V}\).
2. \(\mathbf{x} + \mathbf{y} = \mathbf{y} + \mathbf{x}\) para todo \(\mathbf{x}, \mathbf{y} \in \mathcal{V}\).
3. \((\mathbf{x} + \mathbf{y}) + \mathbf{z} = \mathbf{x} + (\mathbf{y} + \mathbf{z})\) para todo \(\mathbf{x}, \mathbf{y}, \mathbf{z} \in \mathcal{V}\).
4. Existe un elemento \(\mathbf{0} \in \mathcal{V}\) tal que \(\mathbf{x} + \mathbf{0} = \mathbf{x}\) para todo \(\mathbf{x} \in \mathcal{V}\).
5. Para cada \(\mathbf{x} \in \mathcal{V}\), existe un elemento \(-\mathbf{x} \in \mathcal{V}\) tal que \(\mathbf{x} + (-\mathbf{x}) = \mathbf{0}\).
6. \(\alpha\mathbf{x} \in \mathcal{V}\) para todo \(\alpha \in \mathbb{R}\) y todo \(\mathbf{x} \in \mathcal{V}\).
7. \((\alpha\beta)\mathbf{x}=\alpha(\beta\mathbf{x})\) para todo \(\alpha,\beta \in \mathbb{R}\) y todo \(\mathbf{x} \in \mathcal{V}\).
8. \((\alpha+\beta)\mathbf{x}=\alpha\mathbf{x}+\beta\mathbf{x}\) para todo \(\alpha,\beta \in \mathbb{R}\) y todo \(\mathbf{x} \in \mathcal{V}\).
9. \(\alpha(\mathbf{x}+\mathbf{y})=\alpha\mathbf{x}+\alpha\mathbf{y}\) para todo \(\alpha \in \mathbb{R}\) y todo \(\mathbf{x},\mathbf{y} \in \mathcal{V}\).
10. \(1\mathbf{x}=\mathbf{x}\) para todo \(\mathbf{x}\in\mathcal{V}\).
nótese que el conjunto de vectores en \(\mathbb{R}^n\) corresponde, junto con la suma vectorial y el escalamiento, a un espacio vectorial canónico
se denomina subespacio (ya que también es un espacio vectorial) a un subconjunto de un espacio vectorial más grande
un conjunto de vectores \(\mathbf{x}_1,...,\mathbf{x}_k\) es linealmente independiente si (\(\alpha_j\in\mathbb{R}\))
\displaystyle \sum_{j=1}^{k}\alpha_j\mathbf{x}_j=0 \Leftrightarrow \alpha_j=0 \ \forall j
Independencia lineal
NOTA: \(\mathbf{x}_1,...,\mathbf{x}_k\) NO pueden ser el vector cero \(\mathbf{0}\)
dado un conjunto de vectores \(\{\mathbf{x}_1,...,\mathbf{x}_k\}\) en \(\mathbb{R}^n\), el conjunto generador o span de los vectores, denotado como \(\mathrm{span}\{\mathbf{x}_1,...,\mathbf{x}_k\}\), es el set de vectores \(\mathbf{y}\) en \(\mathbb{R}^n\) tal que
\mathbf{y}=\displaystyle \sum_{i=1}^{k}\alpha_i\mathbf{x}_i=\mathrm{span}\{\mathbf{x}_1,...,\mathbf{x}_k\}
Conjunto generador
para \(\alpha_1,...,\alpha_k\) escalares
en general es un subespacio de \(\mathbb{R}^n\), con dimensión \(\mathrm{dim}(\mathcal{V})\) igual al número de vectores linealmente independientes dentro del conjunto de vectores
sólo es igual a \(\mathbb{R}^n\) cuando \(k=n\) y todos los vectores son linealmente independientes, en cuyo caso los vectores conforman una base para \(\mathbb{R}^n\)
dentro de un espacio vectorial, es posible expresar vectores mediante una combinación lineal de otros vectores
por ejemplo, el vector \(\begin{bmatrix} x & y \end{bmatrix}^\top\in\mathbb{R}^2\) puede representarse como:
\begin{bmatrix} x \\ y \end{bmatrix}=x\underbrace{\begin{bmatrix} 1 \\ 0 \end{bmatrix}}_{\mathbf{e}_1}+y\underbrace{\begin{bmatrix} 0 \\ 1 \end{bmatrix}}_{\mathbf{e}_2}
Bases
en donde \(\mathbf{e}_1,\mathbf{e}_2\) son los vectores de base
nos referimos al conjunto \(\{\mathbf{e}_1,\mathbf{e}_2\}\) como una base para \(\mathbb{R}^2\) ya que al variar los escalares \(x, y\) en la combinación lineal puede generarse todo vector contenido dentro de \(\mathbb{R}^2\)
en este caso particular, los vectores \(\mathbf{e}_1, \mathbf{e}_2\) forman una base ortonormal
Matrices y transformaciones lineales
se define una matriz como un arreglo rectangular de elementos con \(m\) filas y \(n\) columnas, estas pueden considerarse como una generalización para los vectores
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix} \in\mathbb{R}^{m \times n}
para cada elemento: \(a_{ij}\in\mathbb{R}\)
si \(m=n\) se dice que la matriz es cuadrada
si ya sea \(n=1\) o \(m=1\) entonces se obtiene un vector columna o fila respectivamente
las operaciones de suma, resta y escalamiento funcionan igual para matrices que con vectores
la operación de transposición intercambia las filas con las columnas de la matriz
si \(\mathbf{A}\in\mathbb{R}^{m \times n}\) entonces \(\mathbf{A}^\top\in\mathbb{R}^{n \times m}\) y recibe el nombre de la transpuesta de \(\mathbf{A}\)
\mathbf{A}=\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} \in\mathbb{R}^{2 \times 3}
\mathbf{A}^\top=\begin{bmatrix} 1 & 4 \\ 2 & 5 \\ 3 & 6 \end{bmatrix} \in\mathbb{R}^{3\times 2}
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix}\in\mathbb{R}^{m \times n}\equiv \begin{bmatrix} \mathbf{a}_1 \\ \mathbf{a}_2 \\ \vdots \\ \mathbf{a}_m \end{bmatrix}, \quad \mathbf{a}_i=\begin{bmatrix} a_{i1} & a_{i2} & \cdots & a_{in} \end{bmatrix}
\mathbf{B}=\begin{bmatrix} b_{11} & b_{12} & \cdots & b_{1p} \\ b_{21} & b_{22} & \cdots & b_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ b_{n1} & b_{n2} & \cdots & b_{np} \end{bmatrix}\in\mathbb{R}^{n \times p}\equiv \begin{bmatrix} \mathbf{b}_1 & \mathbf{b}_2 & \cdots & \mathbf{b}_p \end{bmatrix}, \quad \mathbf{b}_j=\begin{bmatrix} b_{j1} \\ b_{j2} \\ \vdots \\ b_{jn} \end{bmatrix}
Multiplicación de matrices
se define la multiplicación \(\mathbf{A}\mathbf{B}\) entre matrices como
\mathbf{AB}=\begin{bmatrix} \mathbf{a}_1 \cdot \mathbf{b}_1 & \mathbf{a}_1 \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_1 \cdot \mathbf{b}_p \\ \mathbf{a}_2 \cdot \mathbf{b}_1 & \mathbf{a}_2 \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_2 \cdot \mathbf{b}_p \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{a}_m \cdot \mathbf{b}_1 & \mathbf{a}_m \cdot \mathbf{b}_2 & \cdots & \mathbf{a}_m \cdot \mathbf{b}_p \end{bmatrix}\in\mathbb{R}^{m \times p}
es decir, se efectúa el producto interno de cada fila de \(\mathbf{A}\) con cada columna de \(\mathbf{B}\)
por lo tanto, para que la multiplicación entre matrices esté definida, el número de columnas de \(\mathbf{A}\) debe ser igual al número de filas de \(\mathbf{B}\)
de esto se concluye que la multiplicación entre matrices no es conmutativa
por ejemplo, si se tienen las matrices
\mathbf{C}=\begin{bmatrix} 3 & 1 & -2 \\ 4 & 0 & 6 \end{bmatrix}\in\mathbb{R}^{2 \times 3}, \qquad \mathbf{D}=\begin{bmatrix} 1 & 0 \\ -1 & 1 \end{bmatrix}\in\mathbb{R}^{2 \times 2}

\mathbf{D}\mathbf{C}
claramente \(\mathbf{C}\mathbf{D}\) no está definida, sin embargo
"división entre matrices" pero bajo la definición de un recíproco o inverso multiplicativo, que cumple con
\mathbf{A}\mathbf{A}^{-1}=\mathbf{A}^{-1}\mathbf{A}=\mathbf{I}
Inversa
donde \(\mathbf{A}^{-1}\) se denomina la inversa de \(\mathbf{A}\)
dado que la multiplicación por la inversa es conmutativa, se concluye que esta existe sólo para matrices cuadradas
"división entre matrices" pero bajo la definición de un recíproco o inverso multiplicativo, que cumple con
\mathbf{A}\mathbf{A}^{-1}=\mathbf{A}^{-1}\mathbf{A}=\mathbf{I}
Inversa
donde \(\mathbf{A}^{-1}\) se denomina la inversa de \(\mathbf{A}\)
sin embargo, no toda matriz cuadrada posee inversa y se refiere a ellas como singulares
en general, los procedimientos analíticos para encontrar la inversa de una matriz son tediosos y complicados, especialmente para matrices de dimensiones superiores
por esta razón, a menos que se trate de una matriz de \(2 \times 2\), se acudirá frecuentemente a métodos numéricos para determinarla
\mathbf{A}=\begin{bmatrix} a & b \\ c & d \end{bmatrix}, \qquad \mathbf{A}^{-1}=\dfrac{1}{\mathrm{det}(\mathbf{A})}\begin{bmatrix} d & -b \\ -c & a \end{bmatrix}
\mathbf{0}=\begin{bmatrix} 0 & 0 & \cdots & 0 \\ 0 & 0 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 0 \end{bmatrix}
\mathbf{I}=\begin{bmatrix} 1 & 0 & \cdots & 0 \\ 0 & 1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \end{bmatrix}
Matrices cuadradas de importancia
matriz cero
matriz identidad
matrices diagonales
matrices simétricas
\mathbf{A}=\begin{bmatrix} a_{11} & 0 & \cdots & 0 \\ 0 & a_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & a_{nn} \end{bmatrix}
\mathbf{A}^\top=\mathbf{A}
matrices antisimétricas
\mathbf{A}^\top=-\mathbf{A}
matrices ortogonales
\mathbf{A}^\top=\mathbf{A} \newline
\mathbf{A}\mathbf{A}^\top=\mathbf{A}^\top\mathbf{A}=\mathbf{I} \newline
\mathbf{A}^{-1}=\mathbf{A}^\top
matrices triangulares superiores
matrices triangulares inferiores
\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ 0 & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & a_{nn} \end{bmatrix}
\mathbf{A}=\begin{bmatrix} a_{11} & 0 & \cdots & 0 \\ a_{21} & a_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \end{bmatrix}
permite obtener un escalar a partir de una matriz cuadrada
se emplea en la solucion de sistemas de ecuaciones lineales, para definir una fórmula general para invertir matrices y para determinar el factor de escalamiento de una transformación lineal
Determinante
no existe una fórmula general para el determinante ya que la complejidad de determinar el mismo depende de la dimensión de la matriz, sin embargo, existen las siguientes fórmulas
\mathbf{A}=\begin{bmatrix} a & b \\ c & d \end{bmatrix}
\mathrm{det}(\mathbf{A})\equiv|A|=ad-bc
\mathbf{B}=\begin{bmatrix} a & b & c \\ d & e & f \\ g & h & i \end{bmatrix}
\mathrm{det}(\mathbf{B})=aei+bfg+cdh-(gec+hfa+idb)
\(\mathbf{A}+\mathbf{B}=\mathbf{B}+\mathbf{A}\).
\(\mathbf{A}\mathbf{B}\ne \mathbf{B}\mathbf{A}\).
\(\mathbf{A}+(\mathbf{B}+\mathbf{C})=(\mathbf{A}+\mathbf{B})+\mathbf{C}\).
\(\mathbf{A}(\mathbf{B}\mathbf{C})=(\mathbf{A}\mathbf{B})\mathbf{C}\).
\((\mathbf{A}+\mathbf{B})^\top=\mathbf{A}^\top+\mathbf{B}^\top\).
\((\mathbf{A}\mathbf{B})^\top=\mathbf{B}^\top\mathbf{A}^\top\).
Algunas identidades
\((\mathbf{A}+\mathbf{B})^{-1}\ne \mathbf{A}^{-1}+\mathbf{B}^{-1}\).
\((\mathbf{A}\mathbf{B})^{-1}=\mathbf{B}^{-1}\mathbf{A}^{-1}\).
\(\left(\mathbf{A}^{-1}\right)^{-1}=\mathbf{A}\).
\(\mathrm{det}(\mathbf{A}\mathbf{B})=\mathrm{det}(\mathbf{A})\mathrm{det}(\mathbf{B})\).
\(\mathrm{det}\left(\mathbf{A}^\top\right)=\mathrm{det}(\mathbf{A})\).
\(\mathrm{det}\left(\mathbf{A}^{-1}\right)=1/\mathrm{det}(\mathbf{A})\).
una transformación lineal es una función \(\mathcal{T}: \mathcal{V}_1 \to \mathcal{V}_2\), es decir, una función que toma elementos del espacio vectorial \(\mathcal{V}_1\) y los mapea a elementos del espacio vectorial \(\mathcal{V}_2\), que satisface:
\mathcal{T}\{\alpha\mathbf{v}+\beta\mathbf{w}\}=\alpha\mathcal{T}\{\mathbf{v}\}+\beta\mathcal{T}\{\mathbf{w}\}
Transformaciones lineales
para todos \(\alpha,\beta\in\mathbb{R}\) y \(\mathbf{v},\mathbf{w}\in\mathcal{V}_1\)
\(\mathcal{T}\{\mathbf{v}\}\) y \(\mathcal{T}\{\mathbf{w}\}\) son entonces elementos que pertenecen al espacio vectorial \(\mathcal{V}_2\)
algunos ejemplos
escalamiento
proyección
reflección
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=\begin{bmatrix} \alpha x \\ \beta y \end{bmatrix}
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=x+y
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=\begin{bmatrix} y \\ x \end{bmatrix}
una observación importante sobre las transformaciones lineales es que si se representa un vector (que pertenece a un espacio vectorial) mediante una base para el mismo, por ejemplo \(\mathbb{R}^n\)
\mathbf{v}=\begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix}=v_1\mathbf{e}_1+v_2\mathbf{e}_2+\cdots+v_n\mathbf{e}_n
es posible emplear la definición para determinar que
\mathcal{T}\{\mathbf{v}\}=v_1\mathcal{T}\{\mathbf{e}_1\}+v_2\mathcal{T}\{\mathbf{e}_2\}+\cdots+v_n\mathcal{T}\{\mathbf{e}_n\}
\(\mathcal{T}\{\mathbf{e}_1\},\mathcal{T}\{\mathbf{e}_2\},...,\mathcal{T}\{\mathbf{e}_n\}\) son vectores (columna) que pertenecen a otro espacio vectorial
por lo tanto, puede definirse una matriz \(\mathbf{T}\) tal que
\mathbf{T}=\begin{bmatrix} \mathcal{T}\{\mathbf{e}_1\} & \mathcal{T}\{\mathbf{e}_2\} & \cdots & \mathcal{T}\{\mathbf{e}_n\} \end{bmatrix}
por lo que se llega a la conclusión que
\mathcal{T}\{\mathbf{v}\}\equiv \mathbf{T}\mathbf{v}, \qquad \mathcal{T}\sim \mathbf{T}
es decir, una transformacion lineal \(\mathcal{T}\) siempre tendrá asociada una matriz \(\mathbf{T}\) y la aplicación de la primera es equivalente a una multiplicación matriz-vector con la segunda
de manera sencilla, las transformaciones lineales son matrices
por ejemplo, si se tiene la siguiente transformación lineal
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=\begin{bmatrix} 2x+3y \\ 3x-4y \end{bmatrix},
\begin{bmatrix} x \\ y \end{bmatrix}=x\begin{bmatrix} 1 \\ 0 \end{bmatrix}+y\begin{bmatrix} 0 \\ 1 \end{bmatrix},
y se representa al vector \(\begin{bmatrix} x & y \end{bmatrix}^\top\) mediante la base canónica de \(\mathbb{R}^2\), es decir, si
entonces
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=
x \mathcal{T}\left\{\begin{bmatrix} 1 \\ 0 \end{bmatrix}\right\} + y \mathcal{T}\left\{\begin{bmatrix} 0 \\ 1 \end{bmatrix}\right\}
\underbrace{\begin{bmatrix} 2 & 3 \\ 3 & -4 \end{bmatrix}}_{\mathbf{T}} \begin{bmatrix} x \\ y \end{bmatrix}=
\begin{bmatrix} 2x+3y \\ 3x-4y \end{bmatrix}
lo cual es equivalente a
\mathcal{T}\left\{ \begin{bmatrix} x \\ y \end{bmatrix} \right\}=
x \begin{bmatrix} 2 \\ 3 \end{bmatrix}+y\begin{bmatrix} 3 \\ -4 \end{bmatrix}=\begin{bmatrix} 2x+3y \\ 3x-4y \end{bmatrix}
sabiendo que las transformaciones lineales tienen matrices asociadas es sencillo definir la composición entre ellas mediante multiplicación de matrices
\left(\mathcal{T}_1 \circ \mathcal{T}_2\right)\left\{ \mathbf{v} \right\}=
\mathcal{T}_1 \left\{ \mathcal{T}_2\left\{ \mathbf{v} \right\} \right\}
\equiv\mathbf{T}_1\mathbf{T}_2\mathbf{v},
adicionalmente, se denomina rígida a toda transformación lineal (puede ser también afín) que no modifica la norma del vector al que transforma, es decir \(\mathrm{det}(\mathbf{T})\)=1
si \(\mathbf{V}\in\mathbb{R}^{n \times n}\) y \(\mathbf{x}\in\mathbb{R}^n\) entonces pueden definirse ciertos subespacios de importancia según los resultados del mapeo de la transformación lineal
espacio nulo: el subespacio de todos los vectores que son mapeados al vector cero
\mathcal{N}(\mathbf{V})=\left\{ \mathbf{x} \ | \ \mathbf{V}\mathbf{x}=\mathbf{0} \right\}
Subespacios de importancia
espacio imagen: el subespacio de todos los vectores (distintos de cero) producidos por la aplicación de la transformación lineal
\mathcal{R}(\mathbf{V})=\left\{ \mathbf{y} \ | \ \exists \mathbf{x} \text{ t.q. } \mathbf{y}=\mathbf{V}\mathbf{x} \right\}
se cumple que
\underbrace{\mathrm{dim}\left(\mathcal{N}\right)}_{\nu\equiv\mathrm{nulidad}}+\underbrace{\mathrm{dim}\left(\mathcal{R}\right)}_{\rho\equiv\mathrm{rango }}=n
y se obtiene uno de los resultados más importantes del álgebra lineal
\(\mathbf{V}\) es invertible \(\Leftrightarrow \mathcal{N}(\mathbf{V})=\{\mathbf{0}\} \Leftrightarrow \mathcal{R}\{\mathbf{V}\}=\mathbb{R}^n\)
\(\Leftrightarrow \) las columnas de \(\mathbf{V}\) son linealmente independientes \(\Leftrightarrow \mathrm{det}(\mathbf{V})\ne0\)
Referencia MATLAB
\mathbf{x}=\begin{bmatrix} x_1 \\ x_2 \\ x_3 \end{bmatrix}=\begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}
\mathbf{v}=\begin{bmatrix} -1 & 0 & 1 & 2 \end{bmatrix}
\mathbf{w}=\begin{bmatrix} 0.5 & -8 & 1 \end{bmatrix}^\top
x = [1; 2; 3]v = [-1, 0, 1, 2]w = [0.5, -8, 1]'x_2
x(2)x(1:2)\begin{bmatrix} x_1 \\ x_2 \end{bmatrix}
x_3
x(end)\mathbf{x}+\mathbf{w}
x + w\langle\mathbf{x},\mathbf{w}\rangle
x' * w\|\mathbf{x}\|_2
norm(x, 2)\mathbf{x}\times \mathbf{w}
cross(x, w)\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix}=
\begin{bmatrix} 1 & 0 & -1 \\ -2 & 3 & 0 \\ 0 & 0 & -0.5 \end{bmatrix}
A = [1, 0, -1; -2, 3, 0; 0, 0, -0.5]a_{23}
A(2, 3)\begin{bmatrix} a_{12} & a_{13} \\ a_{22} & a_{23} \\ a_{32} & a_{33} \end{bmatrix}
A(:, 2:end)\mathbf{A}^\top
A'\det(\mathbf{A})
det(A)\mathbf{I}
I = eye(3)\mathbf{0}
zeros(2, 5)\mathbf{A}^{-1}
A^(-1)
I/A
inv(A)\mathbf{A}\mathbf{I}
A * I\mathbf{A}=\begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix}=
\begin{bmatrix} 1 & 0 & -1 \\ -2 & 3 & 0 \\ 0 & 0 & -0.5 \end{bmatrix}
A = [1, 0, -1; -2, 3, 0; 0, 0, -0.5]\mathcal{N}(\mathbf{A})
null(A)\mathcal{R}(\mathbf{A})
orth(A)\rho(\mathbf{A})=\mathrm{rank}(\mathbf{A})
rank(A)BE3027 - Lecture 0 (2024)
By Miguel Enrique Zea Arenales



