El filtro de Kalman y sus variantes
MT3006 - Robótica 2

¿Por qué no es suficiente el filtro complementario?
Necesitamos una herramienta que lidie directamente con la naturaleza estocástica del problema
Un flashback a control moderno
\mathbf{B}
\boldsymbol{+}
\boldsymbol{\int}
\mathbf{C}
\mathbf{A}
\mathbf{u}
\mathbf{y}
\dot{\mathbf{x}}
\mathbf{x}
\mathbf{K}
\mathbf{x}
(-1)
controlador lineal
state feedback
retroalimentación negativa
\boldsymbol{???}
observador de estado
\hat{\mathbf{x}} \approx \mathbf{x}
¿Qué es?
¿Cuándo funciona?
(valor) estimado del estado
Un flashback a control moderno
\mathbf{y}
\hat{\mathbf{x}} \approx \mathbf{x}
es un estimador
???
sistema que genera estimados | estimaciones
\triangleq
Según Luenberger
\dot{\hat{\mathbf{x}}}=\mathbf{A}\hat{\mathbf{x}}+\mathbf{B}\mathbf{u}+\mathbf{L}\left(\mathbf{y}-\hat{\mathbf{y}}\right)
Un flashback a control moderno
Observadores de Luenberger
\dot{\hat{\mathbf{x}}}=\mathbf{A}\hat{\mathbf{x}}+\mathbf{B}\mathbf{u}+\mathbf{L}\left(\mathbf{y}-\hat{\mathbf{y}}\right)
predicción
emplea lo que se conoce del sistema
corrección
emplea las mediciones para corregir la predicción
matriz de ganancias \(\in\mathbb{R}^{n \times p}\)
mediciones
salida según el modelo LTI \(\hat{\mathbf{y}}=\mathbf{C}\hat{\mathbf{x}}\)
Pero existe otra manera de interpretar el problema, desde una perspectiva de estimación
¿Estimación?
considera dos problemas
P\left( \mathbf{x}_{1:N},\theta | \mathbf{y}_{1:N} \right)
P\left( \mathbf{x}_t | \mathbf{y}_{1:t} \right)
considera dos problemas
\hat{\mathbf{x}}
P\left( \mathbf{x}_{1:N},\theta | \mathbf{y}_{1:N} \right)
P\left( \mathbf{x}_t | \mathbf{y}_{1:t} \right)
smoothing
¿Estimación?
considera dos problemas
\hat{\mathbf{x}}
P\left( \mathbf{x}_{1:N},\theta | \mathbf{y}_{1:N} \right)
P\left( \mathbf{x}_t | \mathbf{y}_{1:t} \right)
smoothing
filtering
¿Estimación?
considera dos problemas
\hat{\mathbf{x}}
P\left( \mathbf{x}_{1:N},\theta | \mathbf{y}_{1:N} \right)
P\left( \mathbf{x}_t | \mathbf{y}_{1:t} \right)
smoothing
filtering
queremos que sea en tiempo real
¿Estimación?
puede ser una ventana
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
toda la información del pasado está contenida en el estado (memoria)
permite entonces mediante la regla de Bayes
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
toda la información del pasado está contenida en el estado (memoria)
P\left(\mathbf{x}_t | \mathbf{y}_{1:t} \right) \propto P\left(\mathbf{y}_t | \mathbf{x}_t \right) P\left(\mathbf{x}_t | \mathbf{y}_{1:t-1} \right)
permite entonces mediante la regla de Bayes
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
toda la información del pasado está contenida en el estado (memoria)
P\left(\mathbf{x}_t | \mathbf{y}_{1:t} \right) \propto P\left(\mathbf{y}_t | \mathbf{x}_t \right) P\left(\mathbf{x}_t | \mathbf{y}_{1:t-1} \right)
modelo de medición
permite entonces mediante la regla de Bayes
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
toda la información del pasado está contenida en el estado (memoria)
P\left(\mathbf{x}_t | \mathbf{y}_{1:t-1} \right) = \displaystyle \int P\left(\mathbf{x}_t | \mathbf{x}_{t-1} \right)
P\left(\mathbf{x}_{t-1} | \mathbf{y}_{1:t-1} \right) d\mathbf{x}_{t-1}
permite entonces mediante la regla de Bayes
Filtrado bajo la propiedad de Markov
\mathbf{x}_1
\mathbf{x}_2
\mathbf{x}_{t-1}
\mathbf{x}_t
\mathbf{y}_1
\mathbf{y}_2
\mathbf{y}_{t-1}
\mathbf{y}_t
toda la información del pasado está contenida en el estado (memoria)
P\left(\mathbf{x}_t | \mathbf{y}_{1:t-1} \right) = \displaystyle \int P\left(\mathbf{x}_t | \mathbf{x}_{t-1} \right)
P\left(\mathbf{x}_{t-1} | \mathbf{y}_{1:t-1} \right) d\mathbf{x}_{t-1}
dinámica o modelo de proceso
Entonces, el filtro de Kalman puede interpretarse tanto como un observador de estado como un filtro Bayesiano
Entonces, el filtro de Kalman puede interpretarse tanto como un observador de estado como un filtro Bayesiano
veamos los detalles...
Una situación familiar...
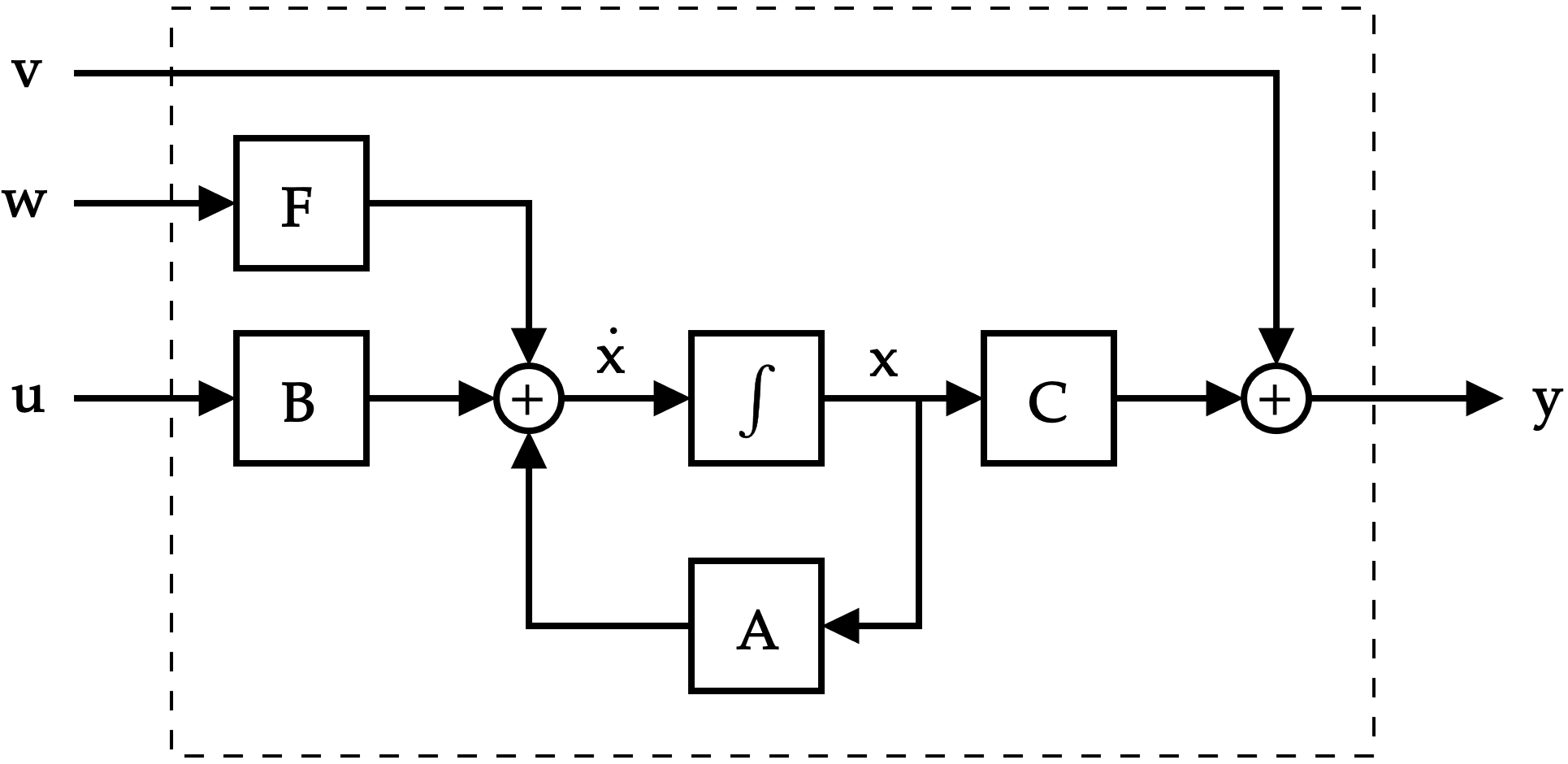
Una situación familiar...
\dot{\mathbf{x}}=\mathbf{A}\mathbf{x}+\mathbf{B}\mathbf{u}+\mathbf{F}\mathbf{w} \\
\mathbf{y}=\mathbf{C}\mathbf{x}+\mathbf{v}
...pero en tiempo discreto
\mathbf{x}_{k+1}=\mathbf{A}[k]\mathbf{x}_k+\mathbf{B}[k]\mathbf{u}_k+\mathbf{F}[k]\mathbf{w}_k \\
\mathbf{y}_k=\mathbf{C}[k]\mathbf{x}_k+\mathbf{v}_k
permite matrices variantes en el tiempo
...pero en tiempo discreto
ruido de proceso
vector de ruido blanco
ruido de medición
vector de ruido blanco
\mathbf{x}_{k+1}=\mathbf{A}[k]\mathbf{x}_k+\mathbf{B}[k]\mathbf{u}_k+\mathbf{F}[k]\mathbf{w}_k \\
\mathbf{y}_k=\mathbf{C}[k]\mathbf{x}_k+\mathbf{v}_k
...pero en tiempo discreto
\mathbf{w}_k \sim \mathcal{N}\left(\mathbf{0}, \mathbf{Q}_w[k]\right)
\mathbf{v}_k \sim \mathcal{N}\left(\mathbf{0}, \mathbf{Q}_v[k]\right)
aunque se permite que cambie la varianza en el tiempo, no es lo típico
\mathbf{x}_{k+1}=\mathbf{A}[k]\mathbf{x}_k+\mathbf{B}[k]\mathbf{u}_k+\mathbf{F}[k]\mathbf{w}_k \\
\mathbf{y}_k=\mathbf{C}[k]\mathbf{x}_k+\mathbf{v}_k
...pero en tiempo discreto
\mathbf{w}_k \sim \mathcal{N}\left(\mathbf{0}, \mathbf{Q}_w[k]\right)
\mathbf{v}_k \sim \mathcal{N}\left(\mathbf{0}, \mathbf{Q}_v[k]\right)
aunque se permite que cambie la varianza en el tiempo, no es lo típico
\mathbf{x}_{k+1}=\mathbf{A}[k]\mathbf{x}_k+\mathbf{B}[k]\mathbf{u}_k+\mathbf{F}[k]\mathbf{w}_k \\
\mathbf{y}_k=\mathbf{C}[k]\mathbf{x}_k+\mathbf{v}_k
¿Por qué tiempo discreto?
Porque el filtro puede separarse en etapas: predicción + corrección

el filtro devuelve
\hat{\mathbf{x}}_k \approx \mathbf{x}_k
el filtro devuelve
\hat{\mathbf{x}}_k \approx \mathbf{x}_k
E\left\{\hat{\mathbf{x}}_k\right\}= \mathbf{x}_k
\hat{\mathbf{x}}_k \sim \mathcal{N}\left( \mathbf{x}_k, \mathbf{P}_k \right)
\mathbf{P}_k=E\left\{\left(\hat{\mathbf{x}}_k-\mathbf{x}_k\right) \left(\hat{\mathbf{x}}_k-\mathbf{x}_k\right)^\top\right\}
encontrando la ganancia de Kalman \(\mathbf{L}_k\) que minimiza la varianza \(\mathbf{P}_k\) del error de estimación
\(\mathbf{e}_k=\hat{\mathbf{x}}-\mathbf{x}_k\)
se separa a \(\hat{\mathbf{x}}_k\) en dos (igual que a \(\mathbf{P}_k\)):
\(\hat{\mathbf{x}}_{k|k-1}\) a-priori (sin mediciones)
\(\hat{\mathbf{x}}_{k|k}\) a-posteriori (con mediciones)
condición inicial (si se conoce) o un estimado de la misma
certeza con la que se conoce la condición inicial
\(\mathbf{P}_{0|0}=E\left\{\mathbf{x}_0\mathbf{x}_0^\top\right\}=\sigma_e^2\mathbf{I}\)
innovación
\(\mathbf{z}_k=\mathbf{y}_k-\mathbf{C}[k]\hat{\mathbf{x}}_{k|k-1}\)
covarianza de la innovación
\(\mathbf{S}[k]=\mathbf{Q}_v[k]+\mathbf{C}[k]\mathbf{P}_{k|k-1}\mathbf{C}[k]^\top\)
intuición: >> mt3006_clase11_kalman1d.m
ejemplo: >> mt3006_clase11_kalman_fusion.mlx
El filtro de Kalman Extendido (EKF)
extiende el filtro al caso no lineal
\mathbf{x}_{k+1}=\boldsymbol{\mathcal{F}}\left(\mathbf{x}_k,\mathbf{u}_k,\mathbf{w}_k\right) \newline
\mathbf{y}_k=\boldsymbol{\mathcal{H}}\left(\mathbf{x}_k\right)+\mathbf{v}_k
redefiniendo la predicción y corrección de estado y generando las matrices \(\mathbf{A}, \mathbf{B}, \mathbf{F}, \mathbf{C}\) mediante linealización (jacobianos)
\mathbf{A}[k]=\dfrac{ \boldsymbol{\mathcal{F}}\left( \hat{\mathbf{x}}_{k-1 | k-1}, \mathbf{u}_{k-1}, \mathbf{0} \right)} {\mathbf{x}_k}
\mathbf{B}[k]=\dfrac{ \boldsymbol{\mathcal{F}}\left( \hat{\mathbf{x}}_{k-1 | k-1}, \mathbf{u}_{k-1}, \mathbf{0} \right)} {\mathbf{u}_k}
\mathbf{F}[k]=\dfrac{ \boldsymbol{\mathcal{F}}\left( \hat{\mathbf{x}}_{k-1 | k-1}, \mathbf{u}_{k-1}, \mathbf{0} \right)} {\mathbf{w}_k}
\mathbf{C}[k]=\dfrac{ \boldsymbol{\mathcal{H}}\left( \hat{\mathbf{x}}_{k | k-1} \right)} {\mathbf{x}_k}
\hat{\mathbf{x}}_{k|k-1}=\boldsymbol{\mathcal{F}}\left(\hat{\mathbf{x}}_{k-1|k-1},\mathbf{u}_{k-1},\mathbf{0}\right)
\hat{\mathbf{x}}_{k|k}=\hat{\mathbf{x}}_{k|k-1}+\mathbf{L}_k\left(\mathbf{y}_k-\boldsymbol{\mathcal{H}}\left(\hat{\mathbf{x}}_{k|k-1}\right)\right)
Regresando a fusión de sensores
Predicción
Corrección
medición
sensores propioceptivos
sensores exteroceptivos
filtro de Kalman
Predicción
Corrección
medición
sensores propioceptivos
sensores exteroceptivos
filtro de Kalman
ambos son modelos de medición (sensores)*
ambos son modelos de medición (sensores)*
Predicción
Corrección
medición
sensores propioceptivos
sensores exteroceptivos
filtro de Kalman
* se colocan los propioceptivos en la predicción dado que estos típicamente miden cantidades diferenciales | incrementales, por lo mismo presentan "dinámica".
supongamos que quiere encontrarse cierta cantidad \(z\) y la misma se mide con dos sensores
Ejemplo
Referencias
- MT3006 - Localización y mapeo en robótica móvil.pdf
- Kok et. al, Using Inertial Sensors for Position and Orientation Estimation.
Predicción
Corrección
medición
sensores propioceptivos
sensores exteroceptivos
filtro de Kalman
IMPORTANTE: diferenciar el uso del filtro como filtro vs como observador
MT3006 - Lecture 11 (2024)
By Miguel Enrique Zea Arenales



