Control basado en visión
MT3006 - Robótica 2

¿Por qué?
recordemos uno de los principales resultados del control cinemático de manipuladores
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}^\dagger(\mathbf{q}_k)\mathbf{K}\mathbf{e}(\mathbf{q}_k)
recordemos uno de los principales resultados del control cinemático de manipuladores
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}^\dagger(\mathbf{q}_k)\mathbf{K}\mathbf{e}(\mathbf{q}_k)
\mathbf{e}(\mathbf{q}_{k})=\begin{bmatrix} \mathbf{e}_p(\mathbf{q}_k) \\ \mathbf{e}_o(\mathbf{q}_k) \end{bmatrix} \triangleq \boldsymbol{\xi}_d-{^B}\boldsymbol{\xi}_E(\mathbf{q}_k)
"inversa" del Jacobiano
\succ 0 (=\mathbf{I})
recordemos uno de los principales resultados del control cinemático de manipuladores
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}^\dagger(\mathbf{q}_k)\mathbf{K}\mathbf{e}(\mathbf{q}_k)
\mathbf{e}(\mathbf{q}_{k})=\begin{bmatrix} \mathbf{e}_p(\mathbf{q}_k) \\ \mathbf{e}_o(\mathbf{q}_k) \end{bmatrix} \triangleq \boldsymbol{\xi}_d-{^B}\boldsymbol{\xi}_E(\mathbf{q}_k)
pose deseada
"inversa" del Jacobiano
\succ 0 (=\mathbf{I})
cinemática directa
recordemos uno de los principales resultados del control cinemático de manipuladores
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}^\dagger(\mathbf{q}_k)\mathbf{K}\mathbf{e}(\mathbf{q}_k)
\mathbf{e}(\mathbf{q}_{k})=\begin{bmatrix} \mathbf{e}_p(\mathbf{q}_k) \\ \mathbf{e}_o(\mathbf{q}_k) \end{bmatrix} \triangleq \boldsymbol{\xi}_d-{^B}\boldsymbol{\xi}_E(\mathbf{q}_k)
pose deseada
"inversa" del Jacobiano
\succ 0 (=\mathbf{I})
cinemática directa
¿Cuál es el problema con esto?
no es realmente un sensor
¿Qué podemos hacer al respecto?
Control basado en visión
(visual servoing)
cámara + visión por computadora
Visual servoing basado en posiciones (PBVS)
- planta = robot, sensor = cámara
- problema de control en el espacio de tarea (3D)
Visual servoing basado en imágenes (IBVS)
- planta = robot + cámara
- problema de control en el plano de imagen (2D)
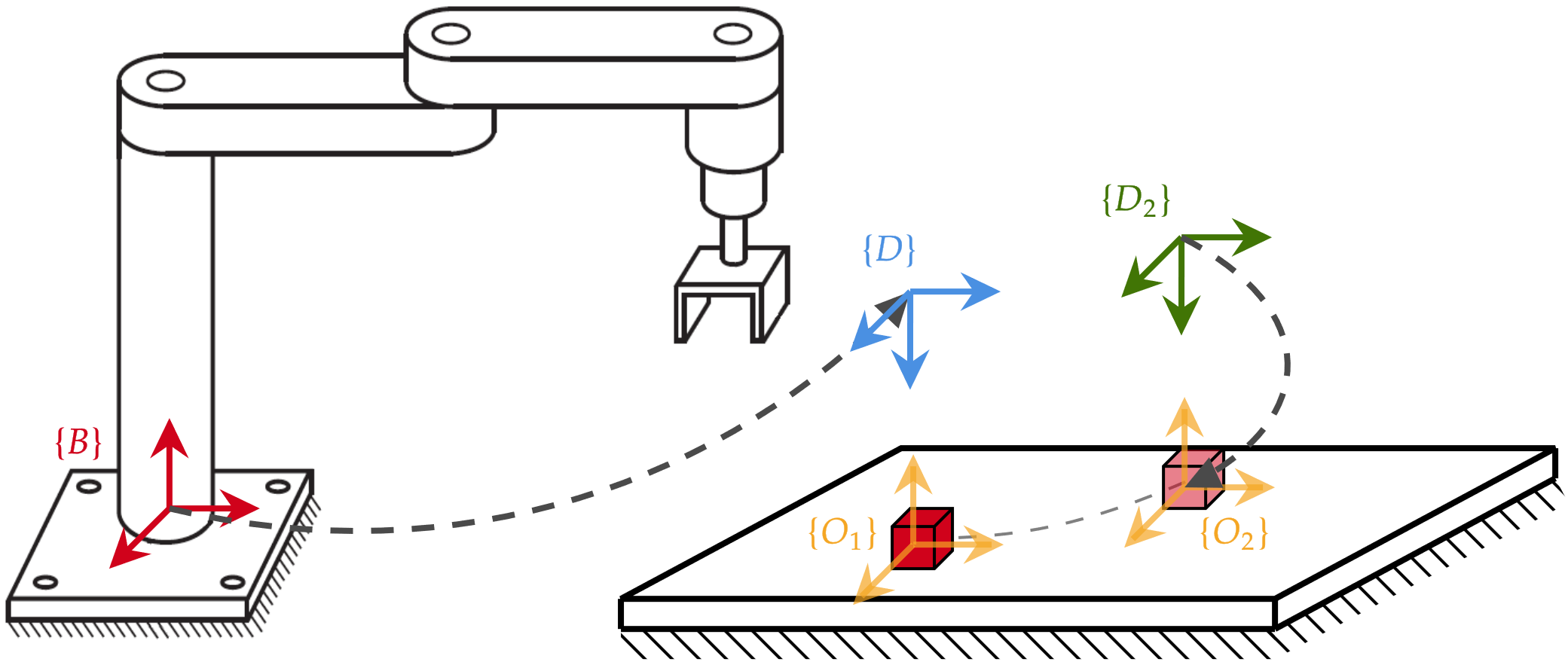
Position Based Visual Servoing (PBVS)
Position Based Visual Servoing (PBVS)
pose deseada del efector final \(\mathbf{T}_d\)
eye-in-hand
Position Based Visual Servoing (PBVS)
pose deseada del efector final \(\mathbf{T}_d\)
\begin{matrix}
\{C\} \to \{D\} \\
{^B}\mathbf{T}_C \to {^B}\mathbf{T}_D \\
{^D}\mathbf{T}_C \to \mathbf{I}
\end{matrix}
objetivo
sin usar poses absolutas
eye-in-hand

\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
...cinemática inversa!
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
\succ 0
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
\mathbf{e}_k \triangleq \mathbf{e}\left({{^D}}\boldsymbol{\xi}_C\right)=-\begin{bmatrix} {^D}\mathbf{o}_C \\ {^D}\boldsymbol{\epsilon}_C \end{bmatrix}
{^D}\boldsymbol{\xi}_C \sim {^D}\mathbf{T}_C=\begin{bmatrix} {^D}\mathbf{R}_C & {^D}\mathbf{o}_C \\ \mathbf{0} & 1 \end{bmatrix}
={^D}\mathbf{T}_{O} \left({^C}\mathbf{T}_{O}\right)^{-1}
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
\mathbf{e}_k \triangleq \mathbf{e}\left({{^D}}\boldsymbol{\xi}_C\right)=-\begin{bmatrix} {^D}\mathbf{o}_C \\ {^D}\boldsymbol{\epsilon}_C \end{bmatrix}
{^D}\boldsymbol{\xi}_C \sim {^D}\mathbf{T}_C=\begin{bmatrix} {^D}\mathbf{R}_C & {^D}\mathbf{o}_C \\ \mathbf{0} & 1 \end{bmatrix}
{^D}\mathcal{Q}_C=\{{^D}\eta_C, {^D}\boldsymbol{\epsilon}_C\}
={^D}\mathbf{T}_{O} \left({^C}\mathbf{T}_{O}\right)^{-1}
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
\mathbf{e}_k \triangleq \mathbf{e}\left({{^D}}\boldsymbol{\xi}_C\right)=-\begin{bmatrix} {^D}\mathbf{o}_C \\ {^D}\boldsymbol{\epsilon}_C \end{bmatrix}
{^D}\boldsymbol{\xi}_C \sim {^D}\mathbf{T}_C=\begin{bmatrix} {^D}\mathbf{R}_C & {^D}\mathbf{o}_C \\ \mathbf{0} & 1 \end{bmatrix}
{^D}\mathcal{Q}_C=\{{^D}\eta_C, {^D}\boldsymbol{\epsilon}_C\}
={^D}\mathbf{T}_{O} \left({^C}\mathbf{T}_{O}\right)^{-1}
{^C}\mathbf{T}_{O}
estimación de pose
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)=\begin{bmatrix} {^B}\mathbf{R}_D^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_D^\top \end{bmatrix} \mathbf{J}(\mathbf{q}_k)
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)=\begin{bmatrix} {^B}\mathbf{R}_D^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_D^\top \end{bmatrix} \mathbf{J}(\mathbf{q}_k)
\({^B}\mathbf{J}\left(\mathbf{q}_k\right)\) Jacobiano "normal"
{^B}\mathbf{T}_D={^B}\mathbf{T}_C \left({^D}\mathbf{T}_C\right)^{-1}={^B}\mathbf{T}_E(\mathbf{q}_k) \left({^D}\mathbf{T}_C\right)^{-1}
\mathbf{q}_{k+1}=\mathbf{q}_k+{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)\mathbf{K}\mathbf{e}_k
{^D}\mathbf{J}^\dagger\left(\mathbf{q}_k, {^D}\boldsymbol{\xi}_C[k] \right)=\begin{bmatrix} {^B}\mathbf{R}_D^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_D^\top \end{bmatrix} \mathbf{J}(\mathbf{q}_k)
{^B}\mathbf{T}_D={^B}\mathbf{T}_C \left({^D}\mathbf{T}_C\right)^{-1}={^B}\mathbf{T}_E(\mathbf{q}_k) \left({^D}\mathbf{T}_C\right)^{-1}
{^B}\mathbf{T}_E(\mathbf{q}_k)
asume \(\{C\}=\{E\}\)
\({^B}\mathbf{J}\left(\mathbf{q}_k\right)\) Jacobiano "normal"
Estimación de pose


Ejemplo: estimación de pose con homografía
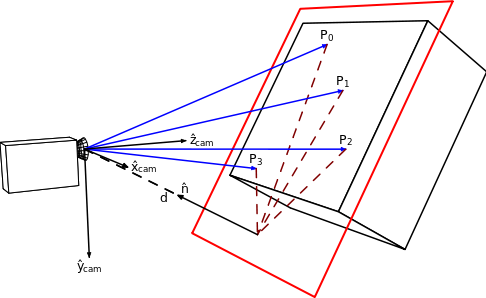

>> mt3006_clase4_estimacion_pose.m
P4P con DLT
Una idea más simple: (fiducial) markers


Image Based Visual Servoing (IBVS)
Image Based Visual Servoing (IBVS)
\mathbf{s}_1
\mathbf{s}_2
\mathbf{s}_3
\mathbf{s}_4
\cdots \mathbf{s}_N
plano de imagen
\mathbf{s}=\begin{bmatrix} \mathbf{s}_1 \\ \vdots \\ \mathbf{s}_N \end{bmatrix}
feature vector
\mathbf{s}_n=\begin{bmatrix} u_n \\ v_n \end{bmatrix}
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
...cinemática inversa otra vez!
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
>> mt3006_clase4_ibvs_manipulador.m
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\succ 0
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\mathbf{J}_L\left(\mathbf{q}, \mathbf{s},{^C}z\right)=\mathbf{L}\left(\mathbf{s},{^C}z\right) \begin{bmatrix} {^B}\mathbf{R}_E^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_E^\top \end{bmatrix} \mathbf{J}(\mathbf{q})
\mathbf{e}_s=\mathbf{s}_d-\mathbf{s}
(asume \(\mathbf{s}_d\) constante)
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\mathbf{J}_L\left(\mathbf{q}, \mathbf{s},{^C}z\right)=\mathbf{L}\left(\mathbf{s},{^C}z\right) \begin{bmatrix} {^B}\mathbf{R}_E^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_E^\top \end{bmatrix} \mathbf{J}(\mathbf{q})
\mathbf{e}_s=\mathbf{s}_d-\mathbf{s}
(asume \(\mathbf{s}_d\) constante)
?
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\dot{\mathbf{s}}=\mathbf{L}\left(\mathbf{s},{^C}z\right)\begin{bmatrix} {^E}\mathbf{v}_E \\ {^E}\boldsymbol{\omega}_{BE} \end{bmatrix}
\dot{\mathbf{s}}=
\mathbf{L}\left(\mathbf{s},{^C}z\right) \begin{bmatrix} {^B}\mathbf{R}_E^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_E^\top \end{bmatrix} \begin{bmatrix} {^B}\mathbf{v}_E \\ {^B}\boldsymbol{\omega}_{BE} \end{bmatrix}
\mathbf{q}_{k+1}=\mathbf{q}_k+\mathbf{J}_L^\dagger\left(\mathbf{q}_k, \mathbf{s}[k], {^C}z[k] \right)\mathbf{K}\mathbf{e}_s[k]
\dot{\mathbf{s}}=\mathbf{L}\left(\mathbf{s},{^C}z\right)\begin{bmatrix} {^E}\mathbf{v}_E \\ {^E}\boldsymbol{\omega}_{BE} \end{bmatrix}
\dot{\mathbf{s}}=
\mathbf{L}\left(\mathbf{s},{^C}z\right) \begin{bmatrix} {^B}\mathbf{R}_E^\top & \mathbf{0} \\ \mathbf{0} & {^B}\mathbf{R}_E^\top \end{bmatrix} \begin{bmatrix} {^B}\mathbf{v}_E \\ {^B}\boldsymbol{\omega}_{BE} \end{bmatrix}
asume \(\{C\}=\{E\}\)
matriz de interacción (depende del tipo de feature)
Feature = punto
\mathbf{L}_p(\mathbf{s},{^C}z)=
\begin{bmatrix} -\frac{f'}{{^C}z} & 0 & \frac{\bar{u}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} & -\frac{{f'}^2+\bar{u}^2}{f'} & \bar{v} \\
0 & -\frac{f'}{{^C}z} & \frac{\bar{v}}{{^C}z} & \frac{{f'}^2+\bar{v}^2}{f'} & -\frac{\bar{u}\bar{v}}{f'} & -\bar{u} \end{bmatrix}
\bar{u}=u-u_0
\bar{v}=v-v_0
f'=\dfrac{f}{\rho_w}=\dfrac{f}{\rho_h}
Feature = línea
\mathbf{L}_\rho(\mathbf{s},a,b,c,d)= \\
\begin{bmatrix} \lambda_\theta\sin\theta & \lambda_\theta\cos\theta & -\rho\lambda_\theta & -\rho\sin\theta & -\rho\cos\theta & -1 \\
\lambda_\rho\sin\theta & \lambda_\rho\cos\theta & -\lambda_\rho\rho & -(1+\rho^2)\cos\theta & (1+\rho^2)\sin\theta & 0 \end{bmatrix}
(\rho,\theta) \leftarrow \text{Transformada de Hough}
a{^C}x+b{^C}y+c{^C}z+d=0
\lambda_\theta=\dfrac{a\cos\theta-b\sin\theta}{d},
\lambda_\rho=-\dfrac{a\rho\sin\theta+b\rho\cos\theta+c}{d}
Feature = línea
\mathbf{L}_\rho(\mathbf{s},a,b,c,d)= \\
\begin{bmatrix} \lambda_\theta\sin\theta & \lambda_\theta\cos\theta & -\rho\lambda_\theta & -\rho\sin\theta & -\rho\cos\theta & -1 \\
\lambda_\rho\sin\theta & \lambda_\rho\cos\theta & -\lambda_\rho\rho & -(1+\rho^2)\cos\theta & (1+\rho^2)\sin\theta & 0 \end{bmatrix}
(\rho,\theta) \leftarrow \text{Transformada de Hough}
a{^C}x+b{^C}y+c{^C}z+d=0
\lambda_\theta=\dfrac{a\cos\theta-b\sin\theta}{d},
\lambda_\rho=-\dfrac{a\rho\sin\theta+b\rho\cos\theta+c}{d}
entre otras, puede revisarse el libro de Corke para ejemplos de más features
Múltiples features
Ejemplo: \(N\) puntos
\mathbf{s}=\begin{bmatrix} \mathbf{s}_1 \\ \vdots \\ \mathbf{s}_N \end{bmatrix} \quad \Rightarrow \quad
\begin{matrix} \mathbf{L}_p\left(\mathbf{s}_1, {^C}z_1\right) \\ \vdots \\ \mathbf{L}_p\left(\mathbf{s}_N, {^C}z_N\right) \end{matrix}
Múltiples features
\dot{\mathbf{s}}=\begin{bmatrix} \mathbf{L}_p\left(\mathbf{s}_1, {^C}z_1\right) \\ \vdots \\ \mathbf{L}_p\left(\mathbf{s}_N, {^C}z_N\right) \end{bmatrix}
\begin{bmatrix} {^E}\mathbf{v}_E \\ {^E}\boldsymbol{\omega}_{BE} \end{bmatrix}
Ejemplo: \(N\) puntos
\mathbf{s}=\begin{bmatrix} \mathbf{s}_1 \\ \vdots \\ \mathbf{s}_N \end{bmatrix} \quad \Rightarrow \quad
\begin{matrix} \mathbf{L}_p\left(\mathbf{s}_1, {^C}z_1\right) \\ \vdots \\ \mathbf{L}_p\left(\mathbf{s}_N, {^C}z_N\right) \end{matrix}
para múltiples features se apilan las matrices de interacción individuales
¿Qué ocurre con los robots móviles con ruedas?
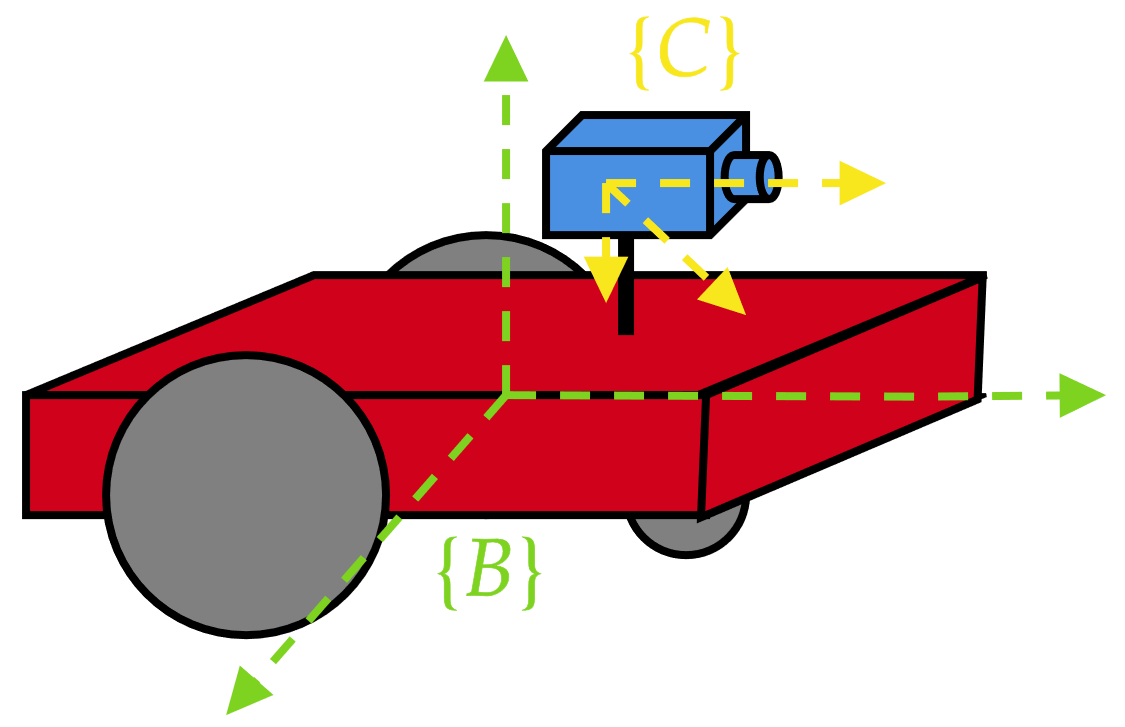
\({^B}\mathbf{v}_B\ne\mathbf{0}\) pero se tiene la ventaja que \({^B}\mathbf{T}_C\) no cambia
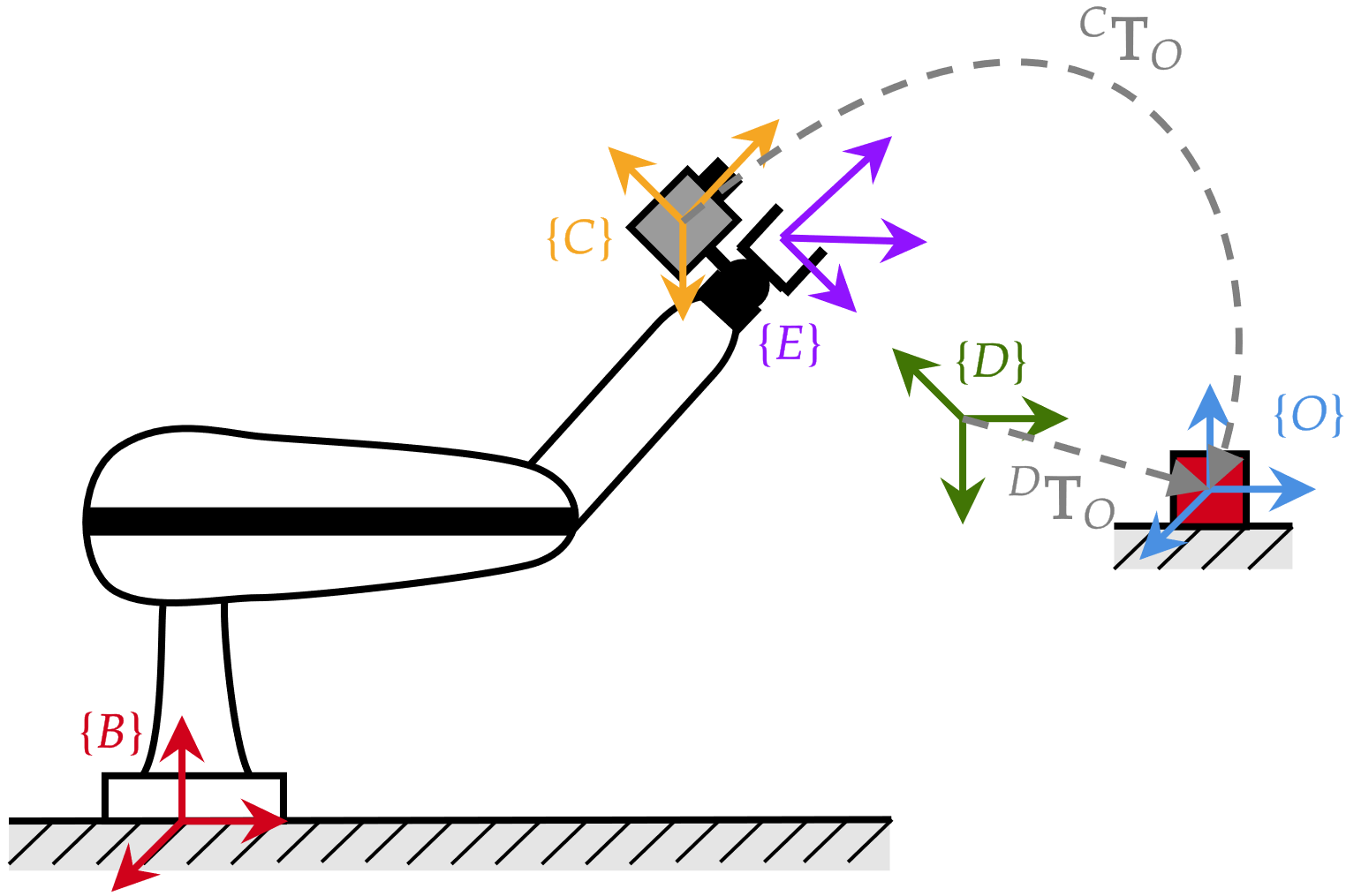
Position Based Visual Servoing (PBVS)
\begin{matrix}
\{B\} \to \{D\} \\
{^I}\mathbf{T}_B \to {^I}\mathbf{T}_D
\end{matrix}
{^I}\mathbf{T}_{D}= {^I}\mathbf{T}_{B} {^B}\mathbf{T}_{C} {^C}\mathbf{T}_{O} \left({^D}\mathbf{T}_{O}\right)^{-1}=
\begin{bmatrix} {^I}\mathbf{R}_D & {^I}\mathbf{o}_D \\ \mathbf{0} & 1 \end{bmatrix}
{^I}\dot{\boldsymbol{\xi}}=\mathbf{f}\left({^I}\boldsymbol{\xi}, \mathbf{v}\right)
\boldsymbol{\xi}=\begin{bmatrix} x \\ y \\ \theta \end{bmatrix}
objetivo
Position Based Visual Servoing (PBVS)
\begin{matrix}
\{B\} \to \{D\} \\
{^I}\mathbf{T}_B \to {^I}\mathbf{T}_D
\end{matrix}
{^I}\mathbf{T}_{D}= {^I}\mathbf{T}_{B} {^B}\mathbf{T}_{C} {^C}\mathbf{T}_{O} \left({^D}\mathbf{T}_{O}\right)^{-1}=
\begin{bmatrix} {^I}\mathbf{R}_D & {^I}\mathbf{o}_D \\ \mathbf{0} & 1 \end{bmatrix}
{^I}\dot{\boldsymbol{\xi}}=\mathbf{f}\left({^I}\boldsymbol{\xi}, \mathbf{v}\right)
\boldsymbol{\xi}=\begin{bmatrix} x \\ y \\ \theta \end{bmatrix}
objetivo
(x_g, y_g)
\(\psi_d\) si se tiene control de pose
Position Based Visual Servoing (PBVS)
\begin{matrix}
\{B\} \to \{D\} \\
{^I}\mathbf{T}_B \to {^I}\mathbf{T}_D
\end{matrix}
{^I}\mathbf{T}_{D}= {^I}\mathbf{T}_{B} {^B}\mathbf{T}_{C} {^C}\mathbf{T}_{O} \left({^D}\mathbf{T}_{O}\right)^{-1}=
\begin{bmatrix} {^I}\mathbf{R}_D & {^I}\mathbf{o}_D \\ \mathbf{0} & 1 \end{bmatrix}
la estimación de pose se hace una única vez si \(\{O\}\) está fijo
{^I}\dot{\boldsymbol{\xi}}=\mathbf{f}\left({^I}\boldsymbol{\xi}, \mathbf{v}\right)
\boldsymbol{\xi}=\begin{bmatrix} x \\ y \\ \theta \end{bmatrix}
objetivo
{^C}\mathbf{T}_{O}
Image Based Visual Servoing (IBVS)
Puede extraerse la dinámica en el plano de imagen desde la matriz de interacción ya que el robot móvil sí puede cambiar directamente sus velocidades
\dot{\mathbf{s}}=
\begin{bmatrix} -\frac{f'}{{^C}z} & 0 & \frac{\bar{u}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} & -\frac{{f'}^2+\bar{u}^2}{f'} & \bar{v} \\
0 & -\frac{f'}{{^C}z} & \frac{\bar{v}}{{^C}z} & \frac{{f'}^2+\bar{v}^2}{f'} & -\frac{\bar{u}\bar{v}}{f'} & -\bar{u} \end{bmatrix}
\begin{bmatrix} {^C} v_x \\ {^C} v_y \\ {^C} v_z \\ {^C} \omega_x \\ {^C} \omega_y \\ {^C} \omega_z \end{bmatrix}
Ejemplo: feature = punto
Image Based Visual Servoing (IBVS)
Puede extraerse la dinámica en el plano de imagen desde la matriz de interacción ya que el robot móvil sí puede cambiar directamente sus velocidades
\dot{\mathbf{s}}=
\begin{bmatrix} -\frac{f'}{{^C}z} & 0 & \frac{\bar{u}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} & -\frac{{f'}^2+\bar{u}^2}{f'} & \bar{v} \\
0 & -\frac{f'}{{^C}z} & \frac{\bar{v}}{{^C}z} & \frac{{f'}^2+\bar{v}^2}{f'} & -\frac{\bar{u}\bar{v}}{f'} & -\bar{u} \end{bmatrix}
\begin{bmatrix} {^C} v_x \\ {^C} v_y \\ {^C} v_z \\ {^C} \omega_x \\ {^C} \omega_y \\ {^C} \omega_z \end{bmatrix}
Image Based Visual Servoing (IBVS)
¿Por qué se seleccionaron esas velocidades?
\Rightarrow \dot{\mathbf{s}}= \begin{bmatrix} \frac{\bar{u}}{{^C}z} & \frac{{f'}^2+\bar{u}^2}{f'} \\ \frac{\bar{v}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} \end{bmatrix} \begin{bmatrix} v \\ \omega \end{bmatrix}
v \equiv {^B}v_x = {^C}v_z \\
\omega \equiv {^B}\omega_z = -{^C}\omega_y
Image Based Visual Servoing (IBVS)
¿Por qué se seleccionaron esas velocidades?
\Rightarrow \dot{\mathbf{s}}= \begin{bmatrix} \frac{\bar{u}}{{^C}z} & \frac{{f'}^2+\bar{u}^2}{f'} \\ \frac{\bar{v}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} \end{bmatrix} \begin{bmatrix} v \\ \omega \end{bmatrix}
v \equiv {^B}v_x = {^C}v_z \\
\omega \equiv {^B}\omega_z = -{^C}\omega_y
cuidado con la notación, ya que se está empleando \(v\) tanto para la coordenada vertical como para la velocidad lineal
Image Based Visual Servoing (IBVS)
¿Por qué se seleccionaron esas velocidades?
\Rightarrow \dot{\mathbf{s}}= \begin{bmatrix} \frac{\bar{u}}{{^C}z} & \frac{{f'}^2+\bar{u}^2}{f'} \\ \frac{\bar{v}}{{^C}z} & \frac{\bar{u}\bar{v}}{f'} \end{bmatrix}
\begin{bmatrix} v \quad\qquad\qquad \\ \omega \quad\qquad\qquad \end{bmatrix}
\begin{matrix} =\mathrm{PID}(\mathbf{e}_s) \\ =\mathrm{PID}(\mathbf{e}_s) \end{matrix}
(por ejemplo)
v \equiv {^B}v_x = {^C}v_z \\
\omega \equiv {^B}\omega_z = -{^C}\omega_y
El único problema al emplear IBVS es que se requiere \({^C}z\), el cual se pierde en el mapeo de la cámara. ¿Qué puede hacerse?
- Asumir un valor cte. para la profundidad.
- Añadir un sensor de distancia.
- Estimar la profundidad mediante mínimos cuadrados (libro de Corke).
Aunque en muchos casos pueden no sólo diseñarse controladores sin conocer los parámetros de la cámara y la profundidad, sino también desacoplar la dinámica de los ejes en el plano de imagen
v=\mathrm{PID}(\bar{v})
\omega=\mathrm{PID}(\bar{u})
Ejemplo: "encarando" a un punto
u
v
(u_0,v_0)
\mathbf{s}=\begin{bmatrix} s_1 \\ s_2 \end{bmatrix}=\begin{bmatrix} \bar{u} \\ \bar{v} \end{bmatrix}
se quiere
\(u\to u_0 \equiv \bar{u}\to 0\)
v^*
*cuidado con la notación
\omega
Ejemplo: "encarando" a un punto
u
v
(u_0,v_0)
\omega_\mathrm{ctrl}=-k\bar{u}=-ks_1
\omega_\mathrm{ctrl}
v_\mathrm{ctrl}=0
>> mt3006_clase4_ibvs_robotmovil.m
Esta forma de trabajar IBVS con robots móviles puede extrapolarse fácilmente a casos más complicados como UAVs o UUVs siempre que la dimensión del vector de features sea mayor o igual al número de velocidades que pueden controlarse
Referencias
- P. Corke, Robotics Vision and Control Fundamental Algorithms in MATLAB, capítulos 15 y 16.
- B. Siciliano, Robotics: Modelling, Planning and Control, capítulo 10.
MT3006 - Lecture 4 (2024)
By Miguel Enrique Zea Arenales



