Machine Learning
Machine Learning
Wat is het?
En wat is het niet?
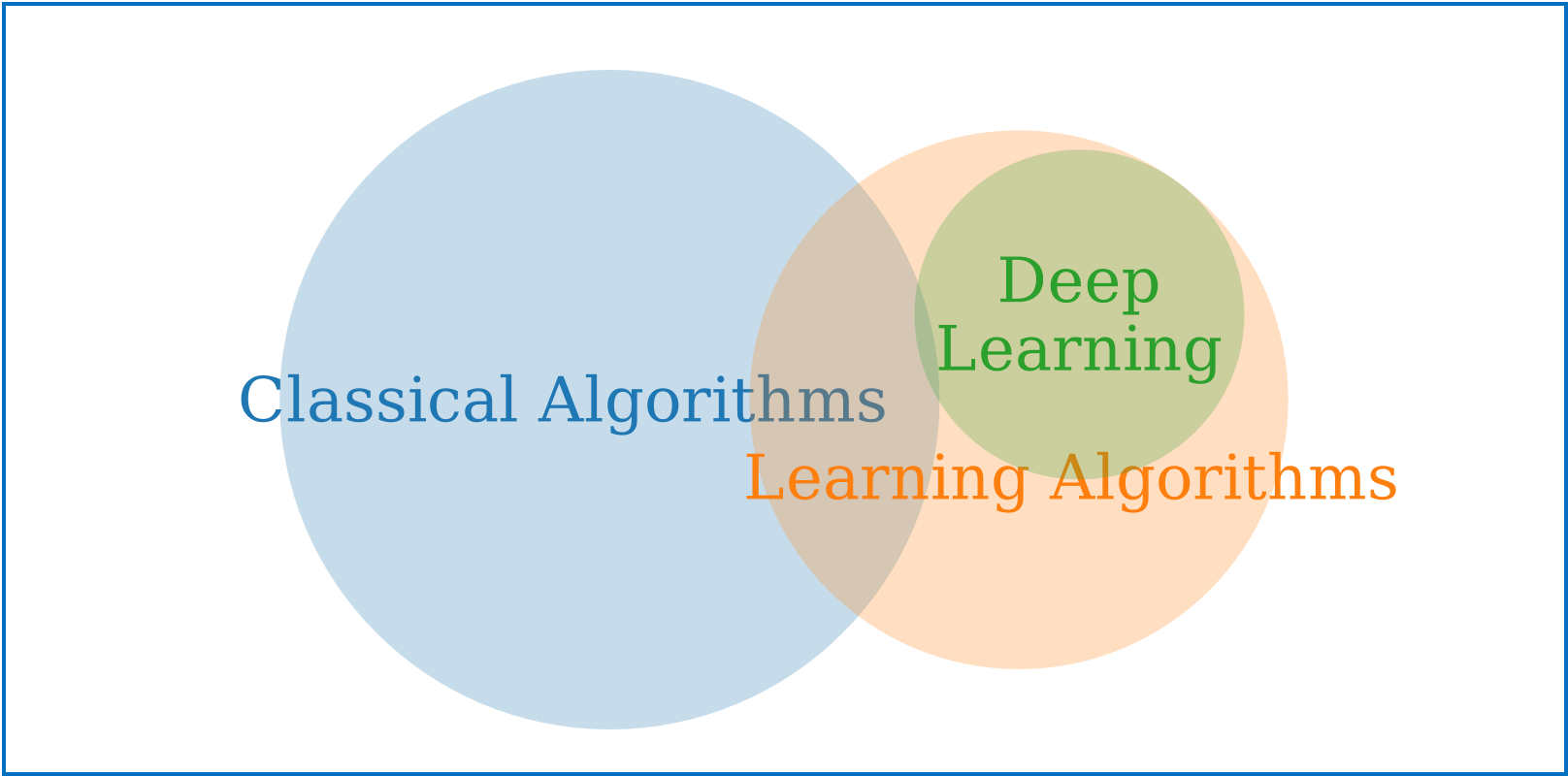
Klassieke algoritmen
- Geeft optimale oplossingen
- Looptijd algoritme makkelijk te schatten
- Niet altijd schaalbaar in tijd
- Gebaseerd op voorkennis (expert)
- Makkelijk verifieerbaar
- Optimale parameters van tevoren specificeren
- Heuristieke beslissingen zelf inprogrammeren
Zelflerende algoritmen
- Oplossingen nooit optimaal
- Looptijd algoritme moeilijk te schatten
- Schalen kan door vroegtijdig te stoppen met trainen
- Gebaseerd op data
- Black box
- Parameters kunnen getraind worden
- Heuristieke beslissingen worden uit de data geëxtrapoleerd
Wat werkt beter?
Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke

Image inpainting

Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Image generation
/cdn.vox-cdn.com/uploads/chorus_asset/file/15972196/nvidia_gaugan_gif.gif)
Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Virtual movement
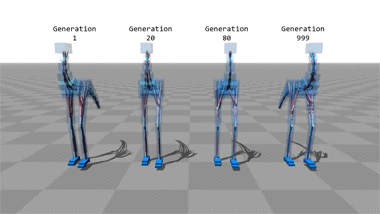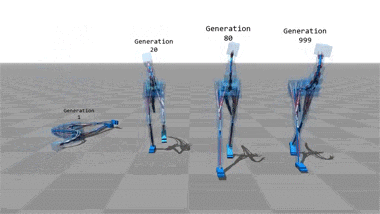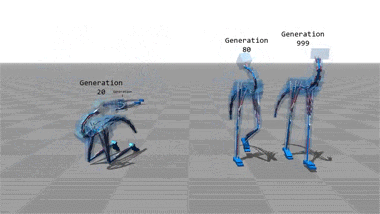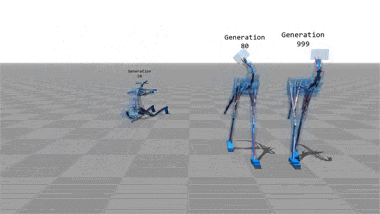
Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Deepfakes



Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Image sharpening - ENHANCE!
Any sufficiently advanced technology is indistinguishable from magic...
~ Arthur C. Clarke
Andere voorbeelden:
- Competitive gaming
- Text translations
- Physics simulations
- Music synthesis
- Protein folding
- Gene expression prediction
- Text-to-speech
- Network security
- Autonomous driving
- Natural Language Processing
- Code creation
- Crime prediction
Soorten:
- Classification
- class(data[x]) = A of B
- Prediction
- f(t+3) = ?
- Translation
- to_image("cats with light sabers") =

Hoe werkt het?
Hoe werkt het?
Input
Hoe werkt het?
Input
Parameters
Hoe werkt het?
Input
Parameters
Model
Hoe werkt het?
Input
Parameters
Model
Training
Hoe werkt het?
Input
Parameters
Model
Training
More training
Hoe werkt het?
Input
Hyperparameters
Model
Training
More training
Output
Wat houdt deep learning in?
In het kort:
- Minder structuur in model
- Opgebouwd uit veel lagen
- Soms combinaties van modellen
- Leert minder snel
- Heeft meer input data nodig
- Kan betere resultaten behalen
Is het echt zo eenvoudig?
Input
Hyperparameters
Model
Training
More training
Output
Ja en nee...
Is het echt zo eenvoudig?
Input
Hyperparameters
Model
Training
More training
Output
Ja en nee...
Ja, want:
De logica wordt door trainen automatisch verwerkt in het model
Is het echt zo eenvoudig?
Input
Hyperparameters
Model
Training
More training
Output
Ja en nee...
Ja, want:
De logica wordt door trainen automatisch verwerkt in het model
Nee, want:
We moeten ervoor zorgen dat het model de logica op de juiste manier leert...
Letten op:
- Input data
- Trainingsproces
- Interpreteren output
Input data
- Genoeg data nodig, 10k, 100k, 1M
- Gebalanceerd
- Gecleaned
- Geformatteerd
- Garbage in, garbage out
Voorbeeld model
- Stel: Data afkomstig van IC van ziekenhuizen, 100k records
- Doel: A.h.v. symptomen voorspellen of iemand Corona heeft
Hoesten?
Niezen?
Koorts?
Secundaire infecties?
Zuurstof nodig?
Vocht in longen?
Model
Corona?
Input data
Trainingsproces
- "Requirements" voor model
- Aannames over distributie data
Trainingsproces
- "Requirements" voor model
- Fitness of error metric nodig
- Sum of absolute errors
- Sum of squared errors
- Distance
Gradient descent

Trainingsproces
- "Requirements" voor model
- Fitness of error metric nodig
- Sum of absolute errors
- Sum of squared errors
- Distance
Trainingsproces
- "Requirements" voor model
- Fitness of error metric nodig
- Overfitting tegengaan
Over overfitting...
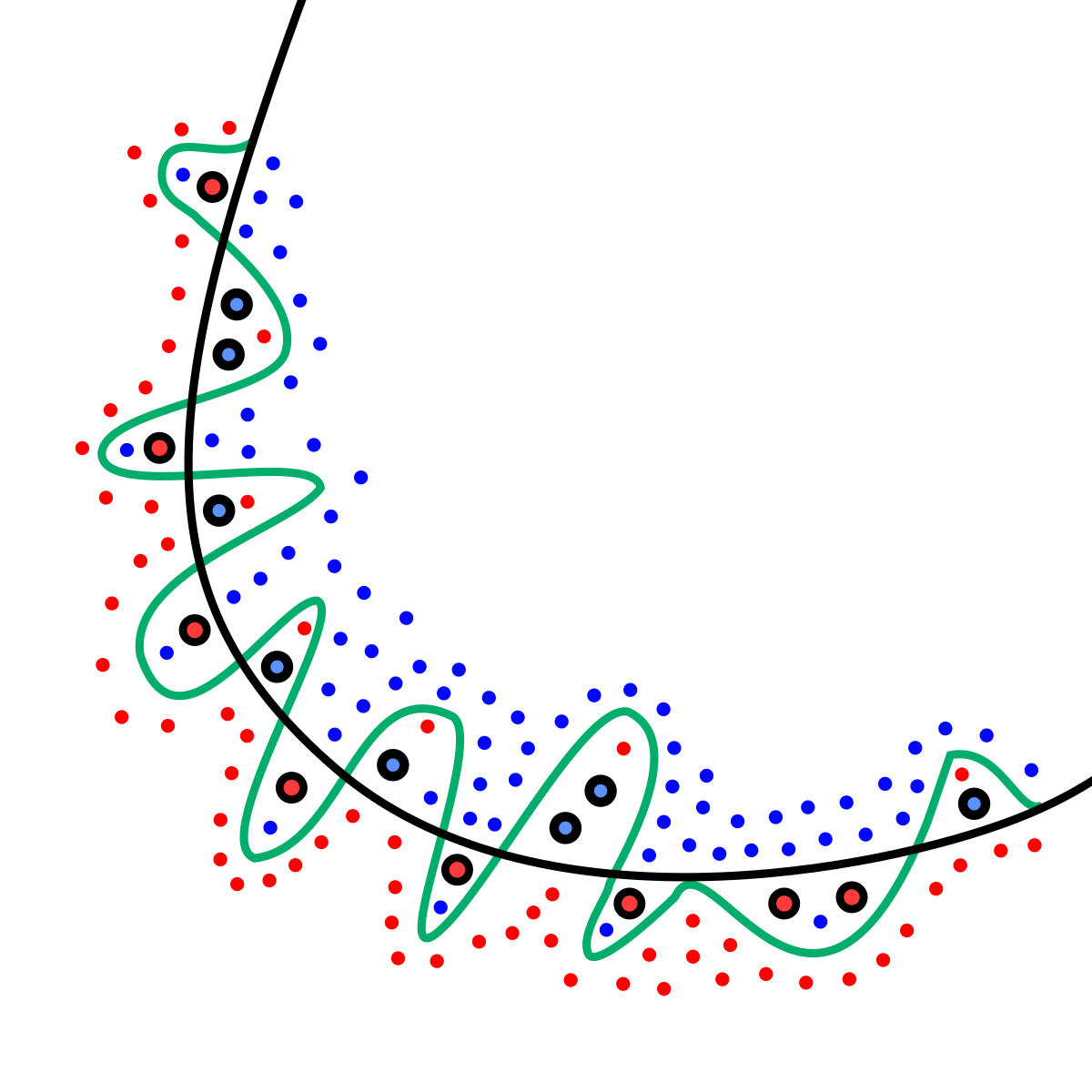
Over overfitting...

Interpreteren output
- Confidence
Interpreteren output
- Confidence
- Incorrecte waarden
Interpreteren output
- Confidence
- Incorrecte waarden
- Limieten van model
- Bijv. lineaire verbanden
Best practices
- Data inspecteren, visualiseren
- N-fold cross validation tegen overfitten
5-fold cross validation
Data set
5-fold cross validation
Data set 1
Data set 2
Data set 3
Data set 4
Data set 5
5-fold cross validation
Data set 1
Data set 2
Data set 3
Data set 4
Data set 5
Training
Training
Training
Validation
Testing
5-fold cross validation
Data set 1
Data set 2
Data set 3
Data set 4
Data set 5
Training
Training
Training
Validation
Testing
5-fold cross validation

Best practices
- Data inspecteren, visualiseren
- N-fold cross validation tegen overfitten
Best practices
- Data inspecteren, visualiseren
- N-fold cross validation tegen overfitten
- Regularization penalty tegen overfitten
- Specificity, sensitivity, accuracy, recall
Best practices
- Data inspecteren, visualiseren
- N-fold cross validation tegen overfitten
- Regularization penalty tegen overfitten
- Specificity, sensitivity, accuracy, recall
- Trainen: GPU of TPU ipv CPU gebruiken
- Trainen: Cloud services
- Pre-trained model gebruiken
Best practices
- Data inspecteren, visualiseren
- N-fold cross validation tegen overfitten
- Regularization penalty tegen overfitten
- Specificity, sensitivity, accuracy, recall
- Trainen: GPU of TPU ipv CPU gebruiken
- Trainen: Cloud services
- Pre-trained model gebruiken
- Confidence interval berekenen bij result
Hoe kunnen wij machine learning gebruiken?
Hoe kunnen wij machine learning gebruiken?
- Pre-trained models en services
- Zelf een model trainen
Wat voor soort problemen kunnen we tacklen?
- Oplossen met klassiek algoritme is moeilijk
- Veel data/pre-trained model beschikbaar
- Herkenbaar patroon in data
- Fitness of error metric/functie
- Incorrecte output is toelaatbaar
- Uitleg over berekende resultaat is niet nodig
Vragen?

Machine Learning
By mjorden




