Doc Brown
Because every array deserves a loving home.

Brian Davis
image copyright © Kristen Frenzel
The Problem
We have lots of array data.
one-dimensional
two-dimensional

three-dimensional

four-dimensional
etc...
"Big Data" usually looks like this:
{"foo": 1, "bar": 1, "baz": 1}
{"foo": 2, "bar": 2, "baz": 2}
{"foo": 3, "bar": 3, "baz": 3}
{"foo": 4, "bar": 4, "baz": 4}
{"foo": 5, "bar": 5, "baz": 5}
... So we did this:
[[1, 2, 3, ...], ...] ⬇
{"latitude": 0, "longitude": 0, "value": 1}
{"latitude": 1, "longitude": 0, "value": 2}
{"latitude": 2, "longitude": 0, "value": 3}
... But...
storage = expensive
querying = expensive
scalability = poor
new dataset = new code
scientific tools = not supported
Array Databases!
storage = cheap
querying = cheap
scientific tools = supported
But...
operationalization = hard
scalability = vertical
versioning = nope
Our Design
Doc Brown is a library, not a service.
This means:
no servers
=
no bottlenecks*
=
cheap scalability
=
low operational cost
* except for the backing store, of course
Our Design
Doc Brown stores data in chunked,
content-addressable,
binary arrays.
This means:

and...

and...

... all have identical performance.
At a fixed cost.
This also means:

... small updates are cheap.
This also means:
... versioning is cheap.
Interfaces
Doc Brown supports several different points of entry.
Clojure
(ns docbrown-demo (:require [com.climate.docbrown :as db] [com.climate.docbrown.slice :as slice])) (def store-spec "ddb://integration.docbrown.climate.com/demo") (let [reader (-> store-spec db/dataset-reader db/on-last-version (db/variable-reader :foo))];; fetch a 1000x1000x1000 element cube (db/get-slice reader (slice/mk-slice [0 0 0] [1000 1000 1000])))
DAP
from netCDF4 import Dataset url = "http://docbrown.testing.net/foo" dataset = Dataset(url)# fetch a 1000x1000x1000 element cubebar = dataset.variables['bar'][0:1000, 0:1000, 0:1000]
REST + JSON
$ curl -XGET -H "Accept: application/json" \"http://docbrown.testing.net/foo.dods?bar\[0:1:1000\]\[0:1:1000\]\[0:1:1000\]"
TODO
documentation
garbage collection
open source
Credits
Arthur Silva
Alice Liang
Brian Davis
Brian Zimmer
Jeffrey Gerard
Mahsa Eshraghi
Rama Shenai
Sebastian Galkin
Tim Chagnon
So what is Doc Brown?
It's a
standards-compliant,
distributed,
versioning,
N-dimensional
array database.
Wha?
Think of it like a bunch of Rubik's cubes,
wrapped in Git,
sitting in The Cloud...

Why N-Dimensional?
Prior schema struggled to support queries like this:

"Give me the precipitation over the entire Midwest
for the last 48 hours."
Why N-Dimensional?
These are all simple queries in Doc Brown.
Why Versioning?
Data providers change their data all the time.
Existing systems can't easily track these changes.
Why Versioning?
Doc Brown tracks these changes.
Why Versioning?
"Get December's daily temperature at [x, y]."
"Get December's daily temperature at [x, y]
as reported two weeks ago."
Why Distributed?
The data we currently use is small.

Why Distributed?
The data we want to use is BIG.

Why Standards-Compliance?
Writing custom software all the time is wasteful, costly, unsustainable, silly.
Why Standards-Compliance?
Cool analysis tools already exist.
Doc Brown's DAP interface lets us use them.
(And we plan to support more.)
Why Standards-Compliance?
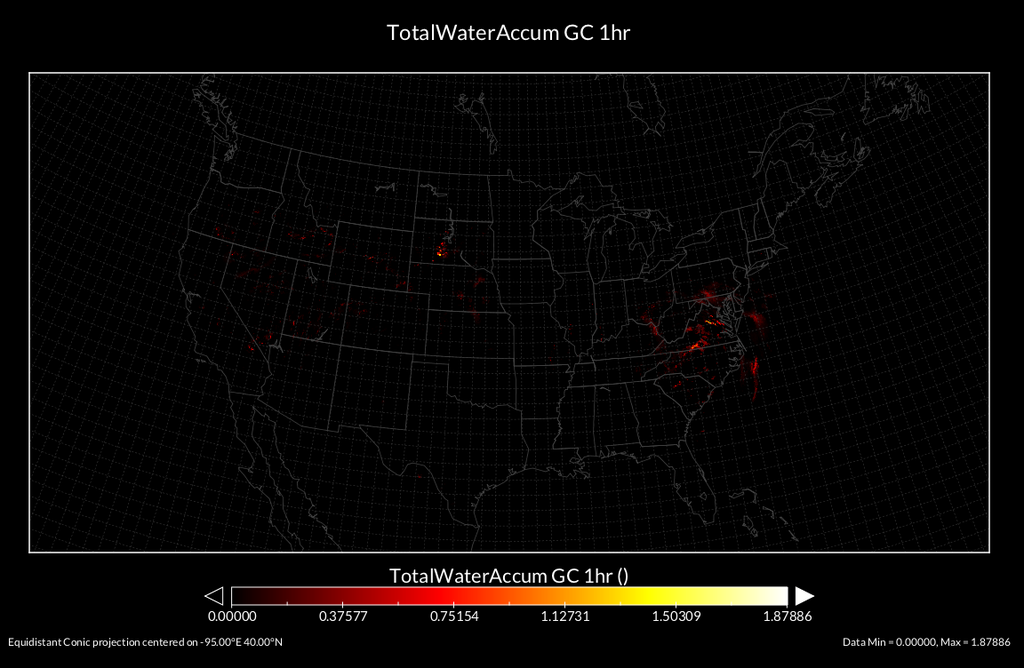
Demo
import numpy as npfrom pydap.client import open_urlfrom videosink import VideoSink# ^^^ We wrote none of those libraries up there.# Get 72 hours of precip data over a ~400x300 km chunk of the midwest.d = open_url("http://docbrown.testing.net/foo")data = d['bar'][0:72,2000:2300,2500:2900]# Rescale the data for 8-bit video.scaled = (255.0/(data.max()-data.min())*(data-data.min())).astype(np.uint8)# Aaaaaaaaand... ACTION!video = VideoSink((300, 400), "test", rate=8, byteorder="Y8")for frame in xrange(72): video.run(data_rescaled[frame,:,:])video.close()
Doc Brown
By monodeldiablo
