



ngoldin@imubit.com

The Imubit Story
- 2-5 SW releases / month
- We train 100s of DL models / week
- Software and DL models are tightly coupled.
- We don't know in advance which model will be used
- Software is constantly updated in Production (CD)
- Models are constantly deployed to Production
- We're a startup - everything must happen fast
No privileges

Where we're at
Agenda
- Whats the problem?
- Our 4-steps solution
- Example
- Questions
Software "thinking"
- Robustness
- Maintainability
- Readability
- Good Design
- "Long term effort"
Whats the problem?
Research "thinking"
- Exploring new ways to solve the problem
- Any new algorithmic method that gives a better result is valid
- "One time effort"

Whats the problem 2 ?
- New SW features can break DL models
- New DL models can break the SW
- Unneeded restrictions when training models - "Does SW support this?"
- Unneeded restrictions when developing new features - "Does model support this?"
Must streamline the process -> Full automation

What makes DL different?
- Predictability - can't know in advance what will work. Knowing which model goes to production happens at the end
- Technological explosion:
- New DL methodologies constantly being developed
- Frameworks rapidly changing: TensorFlow, PyTorch, etc.
Re-write is Impractical
The 4-steps solution
- Serialize your model, "batteries included"
- Add metadata to the model
- Create a shared Interface
- Create an architecture that supports development
The 4 steps
Lets see some code
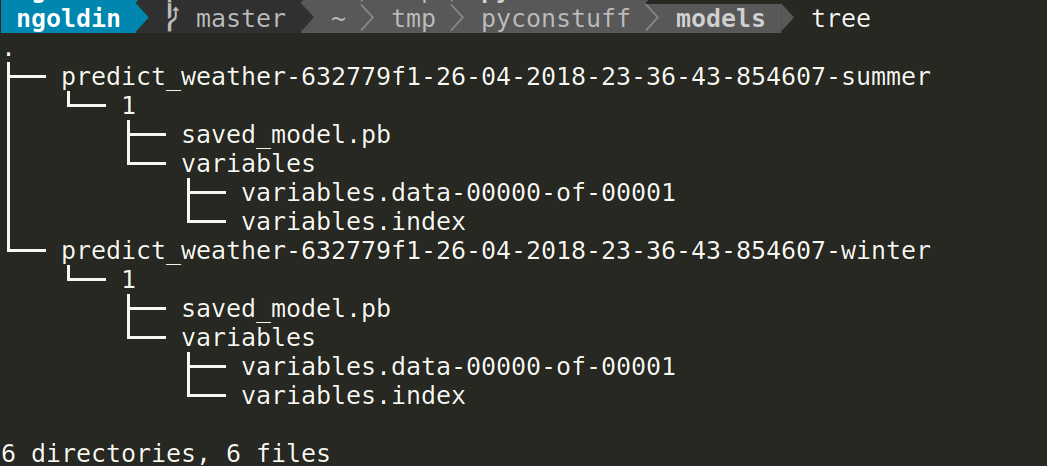
Serialize your model!
# At the end of training
def serialize_model(session, inputs, outputs, export_path):
builder = SavedModelBuilder(export_path)
signature = build_signature_def(inputs=inputs,
outputs=outputs)
builder.add_meta_graph_and_variables(
session,
signature_def_map={'model_signature':
signature})
builder.save()
return export_pathSerialize your model!
Protocol Buffer
Data
Serialize your model!
- Becomes (almost) a platform independent model
- How the model was trained, which methods were used - becomes .. history!
- The model is now a "binary":
- Well defined inputs
- Well defined outputs
... but is it enough?
Add the metadata
- Information needed for Runtime:
- Inputs, Outputs, Dimensions
- Model capabilities:
- "I can predict the weather in Jerusalem and Hebron"
- "My accuracy is 99.5% for ..."
- Runtime behaviors that SW needs to be aware of, examples:
- "If temperature > 100C - don't use me"
- How to reproduce:
- Which data was used to train, maybe more
Add the metadata
def create_model_metadata(context,
session,
inputs,
outputs):
metadata = {}
metadata['topic'] = 'One week weather predictor'
metadata['area'] = ['Jerusalem', 'Beit-Shemesh']
metadata['train_end_time'] = pd.to_datetime('now')
metadata['author'] = context.user
metadata['max_temperature_seen'] = tf.max(...)
metadata['inputs'] = {...}
...
return json.dumps(metadata)Ship them together!
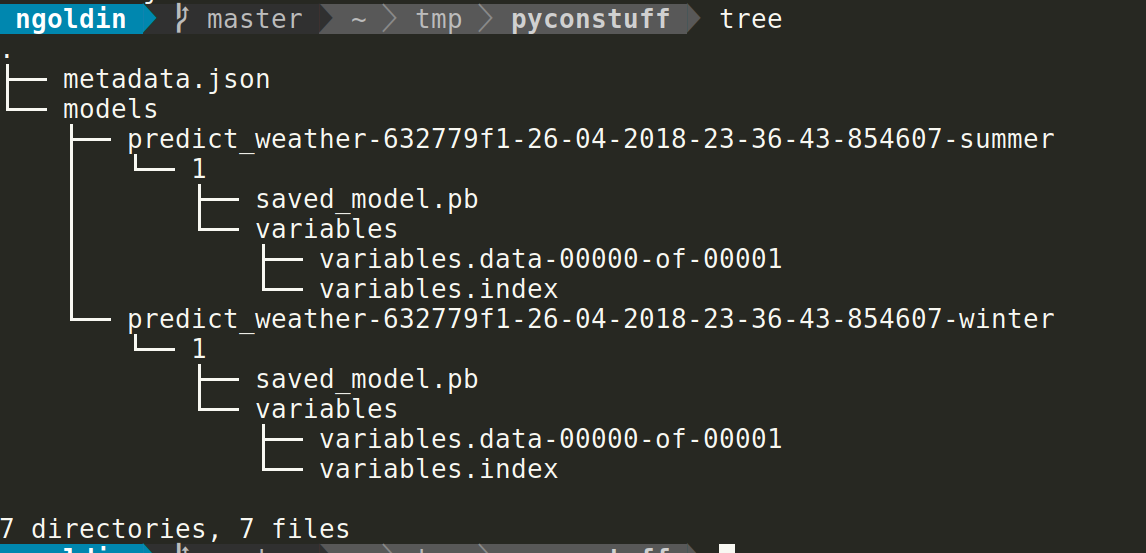

The delivery
Ship them together!
- Serialized model + metadata is your delivery.
- Ensure this is the only way possible to train and deliver a model.
- Ensure the delivery is unique - hash, uuid, etc.
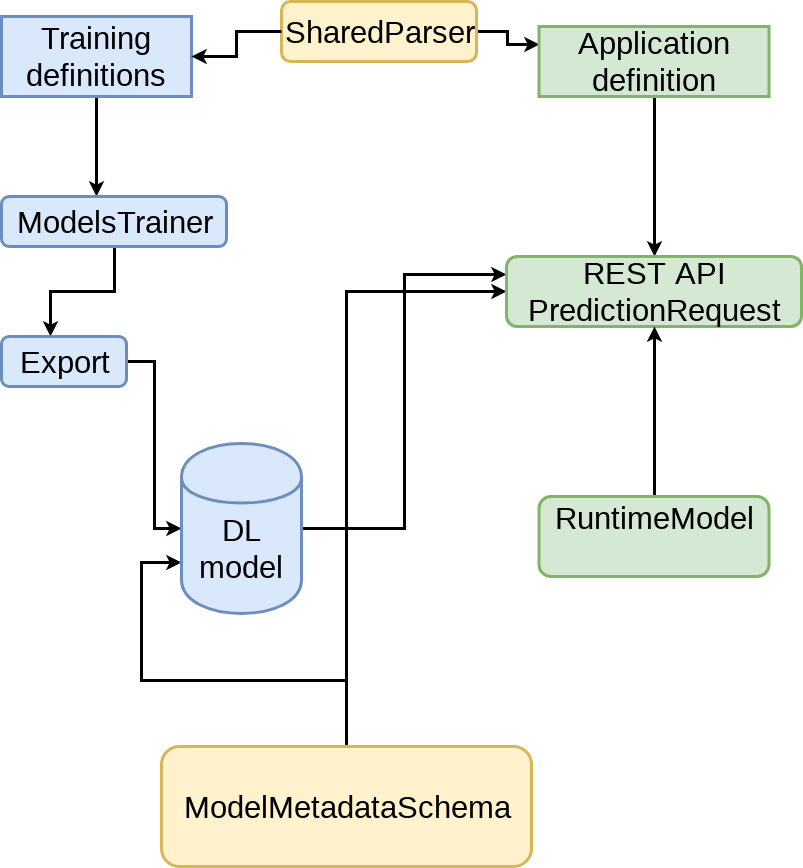
Create a shared interface
- This is a contract between the Software and the DL Model
- It should be minimal
- No implementation details
- It should be easily tested
Shared Interface
import marshmallow as ma
...
class ModelType(Enum):
SummerHumidityPredictor = auto()
WinterPredictor = auto()
class ModelMetadataSchema(ma.Schema):
model_type = EnumField(ModelType, required=True)
schema_version = ma.fields.String('0.2')
author = ma.fields.String(required=True)
max_humidity_seen = ma.fields.Float(required=False)
...Shared Interface - change?
# Inside your application
if model.schema_version > Version('0.2'):
use_new_capabilities()
else:
use_old_one()
- Requires discussion - like any other standard software
- ... but easy to test and track:
-
Should support parallel development of DL models and Software
-
Split to different git repositories:
-
Research - responsible of training and delivering models - a single way to train models
-
Shared Interface - holds the interface definitions
-
Software - Your application and the interface implementation
-
-
Define clear ownership
Architecture
Architecture
Research
Software
Shared
Example: Dummy Weather App
Example Assumptions
- We have a models backend that can run predictions requests: this can be with TensorFlow serving, PyTorch, etc.
- We have a research library for training models
- We have a REST API that the frontend uses
Example - Shared definitions
## YAML Format
application:
area: Israel
training:
required_inputs:
- humidity
period: '30 days'
sample_rate: '1 minute'
- temperature:
area: 'Israel'
period: '30 days'
sample_rate: '5 minutes'Application RuntimeModel
from models_backend import ModelsBackend, find_best_model
from utils import override_cities
class RuntimeModel(object):
def __init__(self, app_context, model_id):
self.model = ModelsBackend.load_by_id(model_id)
self.app_context = app_context
@property
def required_inputs(self):
return self.model.required_inputs
@property
def areas(self):
return self.model.areas
...
Application REST API
from models_backend import find_best_model, get_inputs
from api_service import api
class PredictionRequest(object):
@api('/weather/predict')
def get(self, app_context, data):
model = find_best_model(data['area'], app_context)
dataframe = utils.get_inputs(model.required_inputs)
return json.jsonify((model.predict(dataframe))Breaking change?
- Lets say we now want to predict the weather for Hebron as well
- No model was trained for Hebron..
Quick & Dirty solution
def find_best_model(area, app_context):
for model in ModelsBackend.models:
if area == 'Hebron' and 'JLM' in model.areas:
# their pretty close no?
return model
...
Better than quick & dirty
- Train a new model
- Declare it's new supported cities
# train a model and..
def create_model_metadata(context,
session,
inputs,
outputs):
...
metadata['area'] = ['Jerusalem',
'Beit-Shemesh',
'Hebron']
...
return json.dumps(metadata)When to do what?
- If the change is not user-facing:
- Do it in a new DL Model
- Very complex logic can be built inside TensorFlow: for example multiplexing models based on run time data
- If change is user-facing:
- Normally would require a SW change as well
Key takeaways
- Train every model as if it goes to Production
- ... and that should be the only way to train
- Create SW<->Model interface
- Define clear ownership of components
- Create architecture that supports streamlined deployment of SW and models
"In the face of ambiguity, refuse the temptation to guess." - The Zen of Python
Questions?
Some stuff we didn't cover..
- How to add breaking changes
- What to test?
- Whats a ModelBackend?
We're hiring!
ngoldin@imubit.com
When Deep Learning meets Production
By Nadav Goldin
When Deep Learning meets Production
A practical guideline for creating interfaces between Deep Learning models and Python web applications