Nicolas Gonzalvez
Software Engineer @ Sophilabs

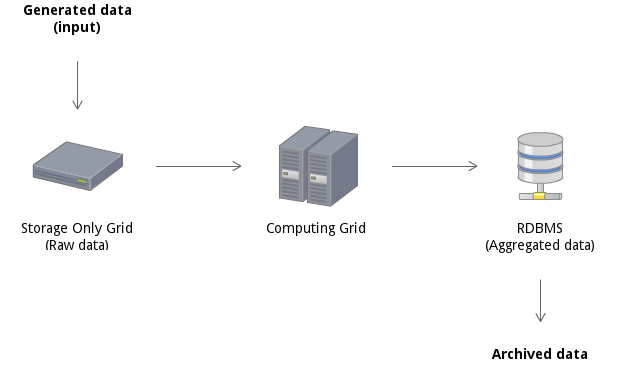
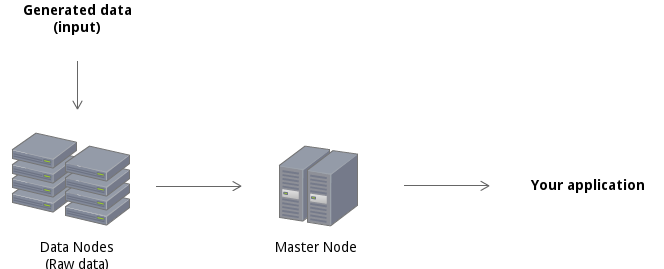
Highly scalable (storage, processing, bandwidth)
Runs on commodity servers
Allow parallel read/processing of data
Bandwidth scales linearly
1 Hard Drive (HD) - 100MB/s
Server (12 HD) - 1.2GB/s
Rack (20 servers) - 24GB/s
Average Cluster (6 racks) - 144GB/s
Large Cluster (200 racks) - 4.8TB/s
Key value store
(row key, column family, column, timestamp) -> value
Fast random access
Scales up to billions of rows and millions of columns
Multidimensional
Programming model for parallel data processing
The mapper process a piece of data and the reducer combines all the partial results.
Based on Google papers
Started by Doug Cutting in 2007
It's open source (under the Apache license)
It is a yellow elephant toy

Schema on write VS Schema on read
Fast indexing
Fast joins
Can't add new data structure
High fidelity data
Flexibility
Fast load of new data structure
Files split into blocks and those blocks are replicated in the DataNodes.
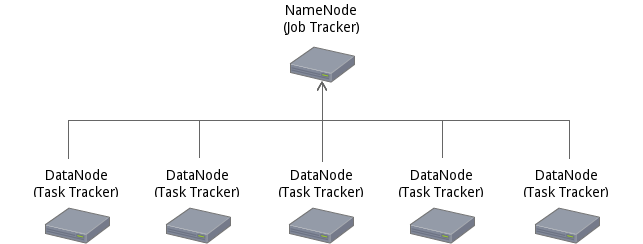
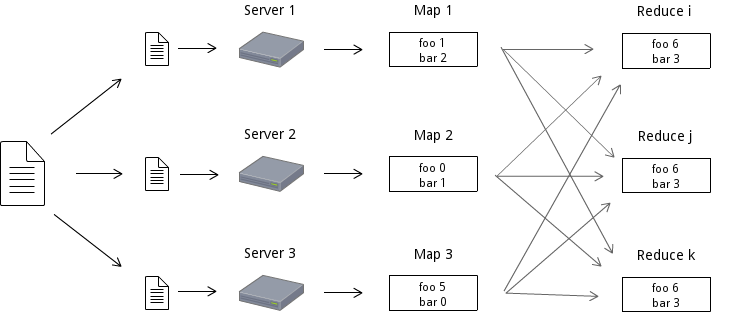
Java Map Reduce: High performance and flexibility.
Streaming MapReduce: Allows implementing MapReduce in any programming language.
Crunch: Tool for creating MapReduce pipelines.
Pig Latin: High level language for data processing
Oozie: Allows creating a workflow with the previous tools.
Hive: Converts SQL to MapReduce jobs.
HBase: Big Table implementation for Hadoop.
By Nicolas Gonzalvez




