
Conjugate Gradient Method
for solving Ax = b
PHPC project
Nicolas Stucki
August 20th 2020
Theoretical Analysis
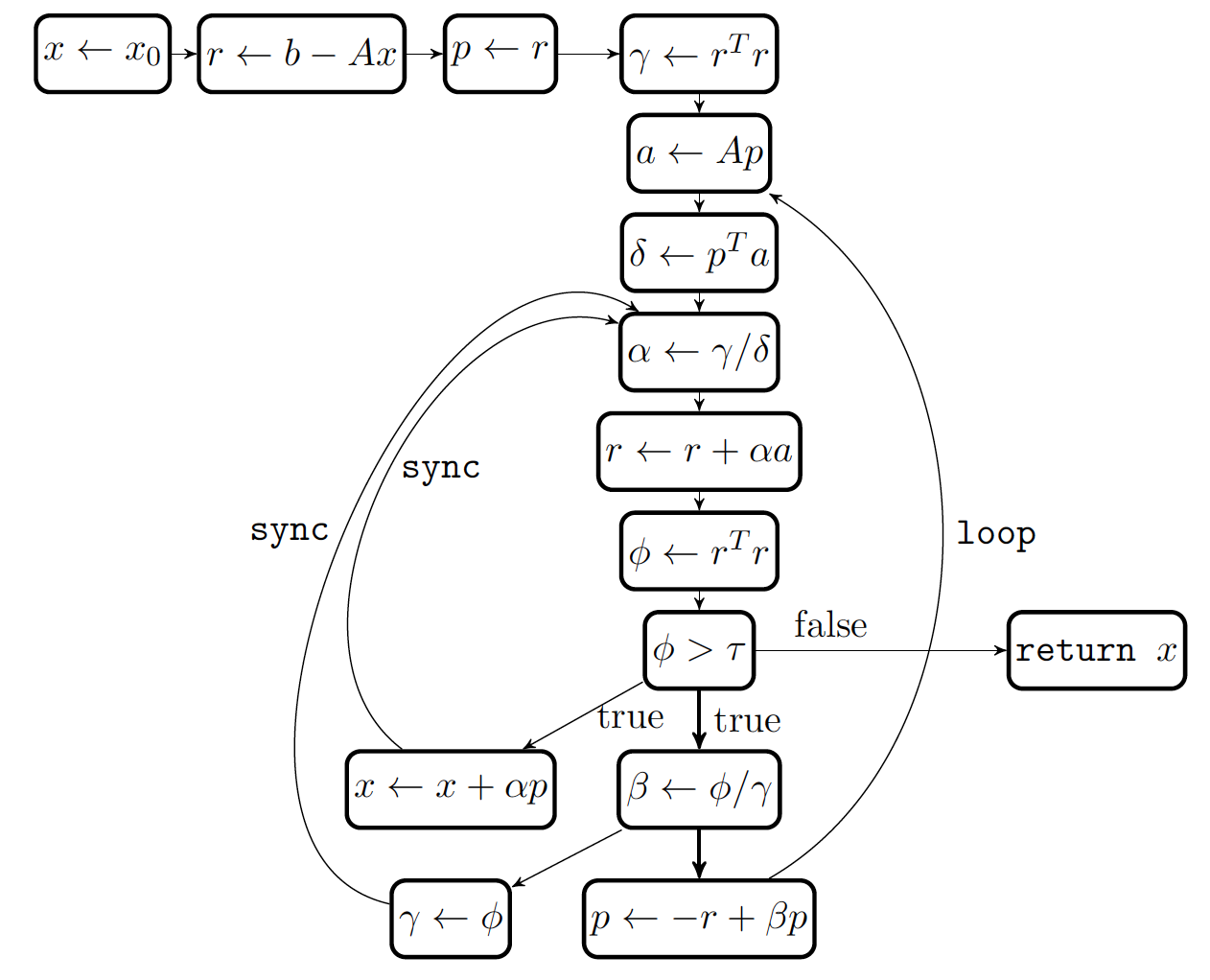
Algorithm
- Θ(1)
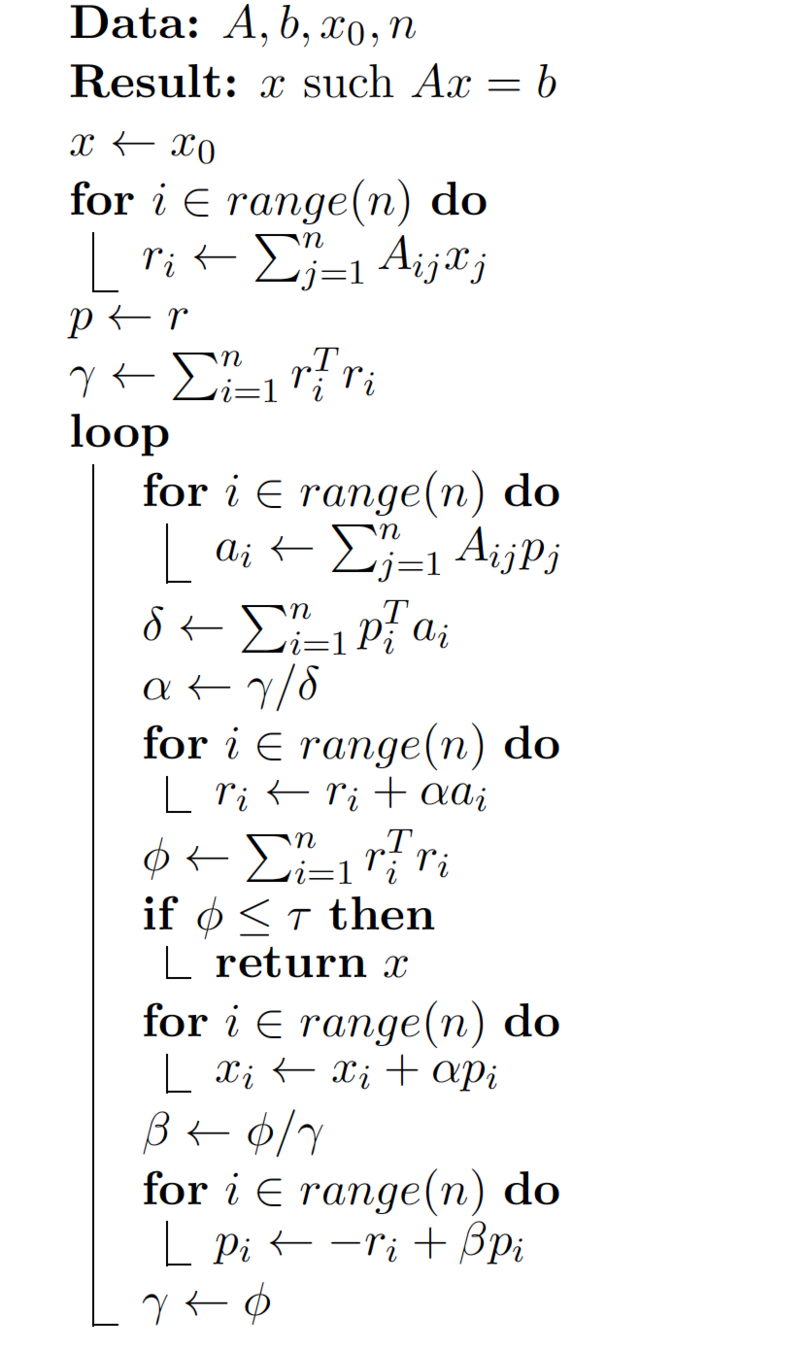
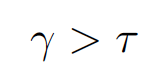
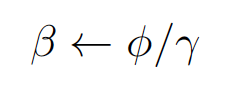
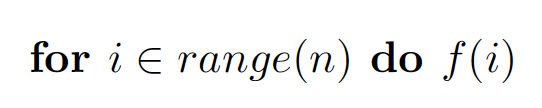
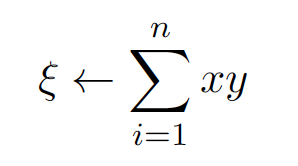
- Θ(log n): Parallel reduction
- Θ(m): In parallel over n
Complexity
- Sequential
Memory
Θ(k·\frac{n^2}{p})
Θ(k·(\frac{n^2}{p} + \log_2{\frac{p}{n}}))
p \leq n
n < p \leq n^2
- Parallel
Θ(k·n^2)
(2k + 2)·n^2 + (9·k − 3)·n + (k − 2)
- FLOPs
Θ(n^2)
- Total
Θ(\frac{n^2}{p})
- Per parallel task
Θ(k·n)
- Syncronization
p \leq n
Concurrency
- Two operations
- Two operations
- Asynchronous memory copies
Θ(n)
Θ(1)
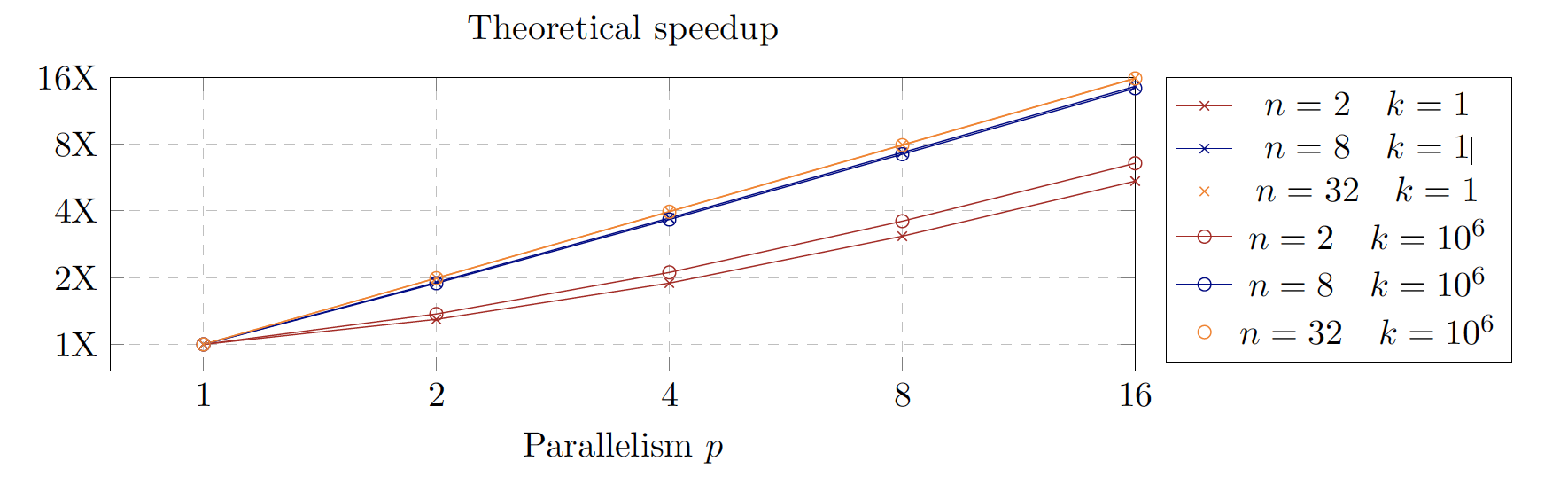
Speedup
- Amdahl’s law: ✘
- Gustafson’s law:
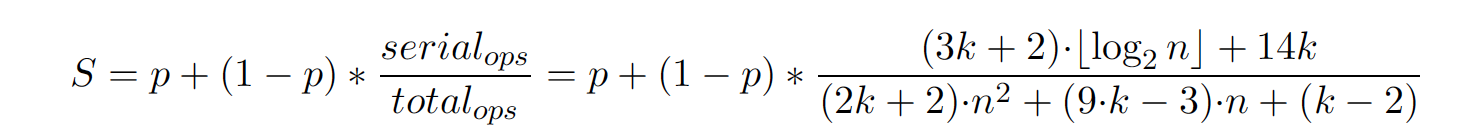
MPI
MPI implementation
- Use p nodes
- Split matrix and vector into p
- Initialization
- Matrix: MPI_Iscatter
- Vectors: MPI_Ibcast
- Iterations:
- Sync: MPI_Alltoall
- Reduce: MPI_Allreduce
- Rest done sequentially
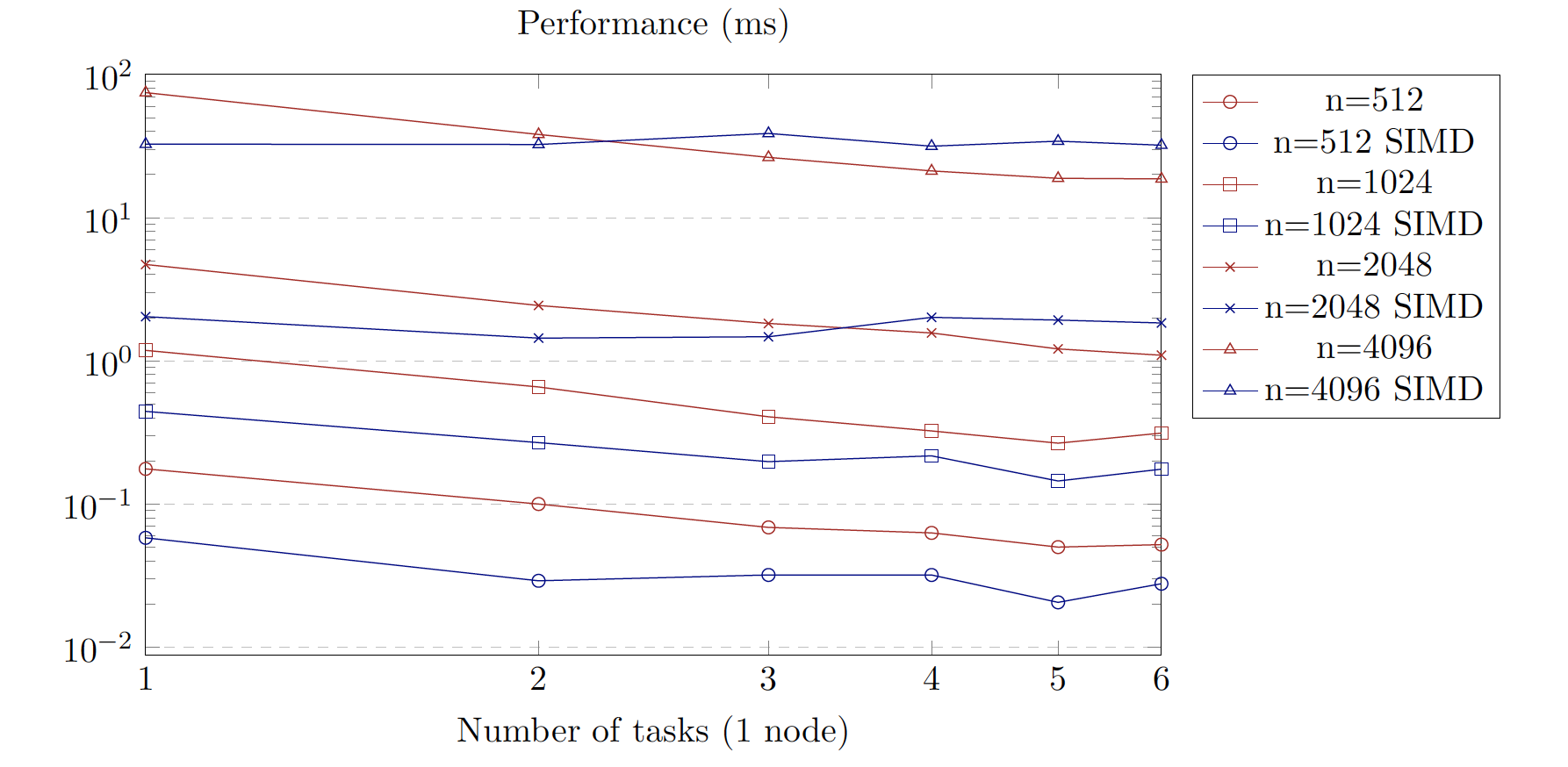
- Also experimented with SIMD
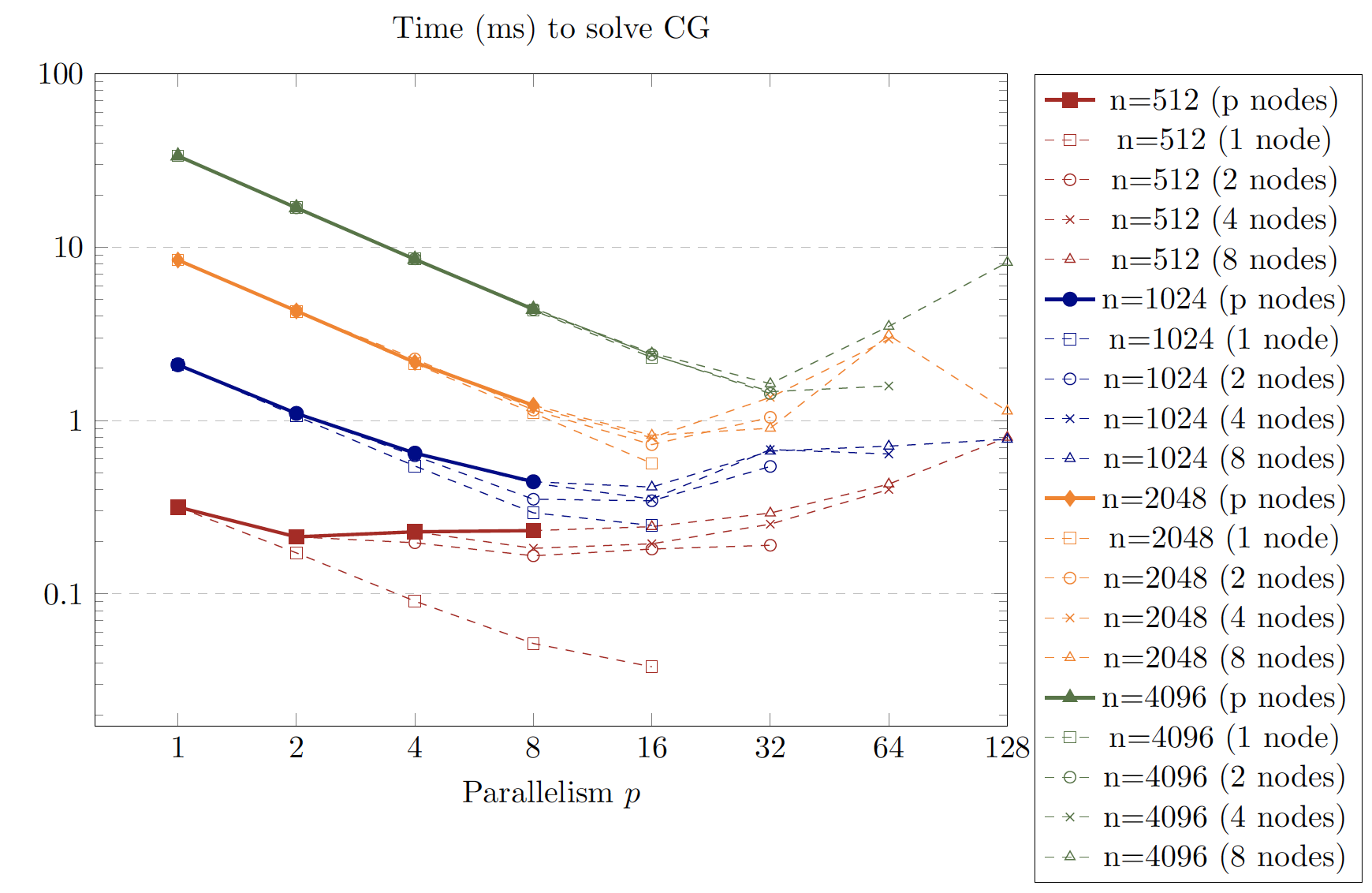
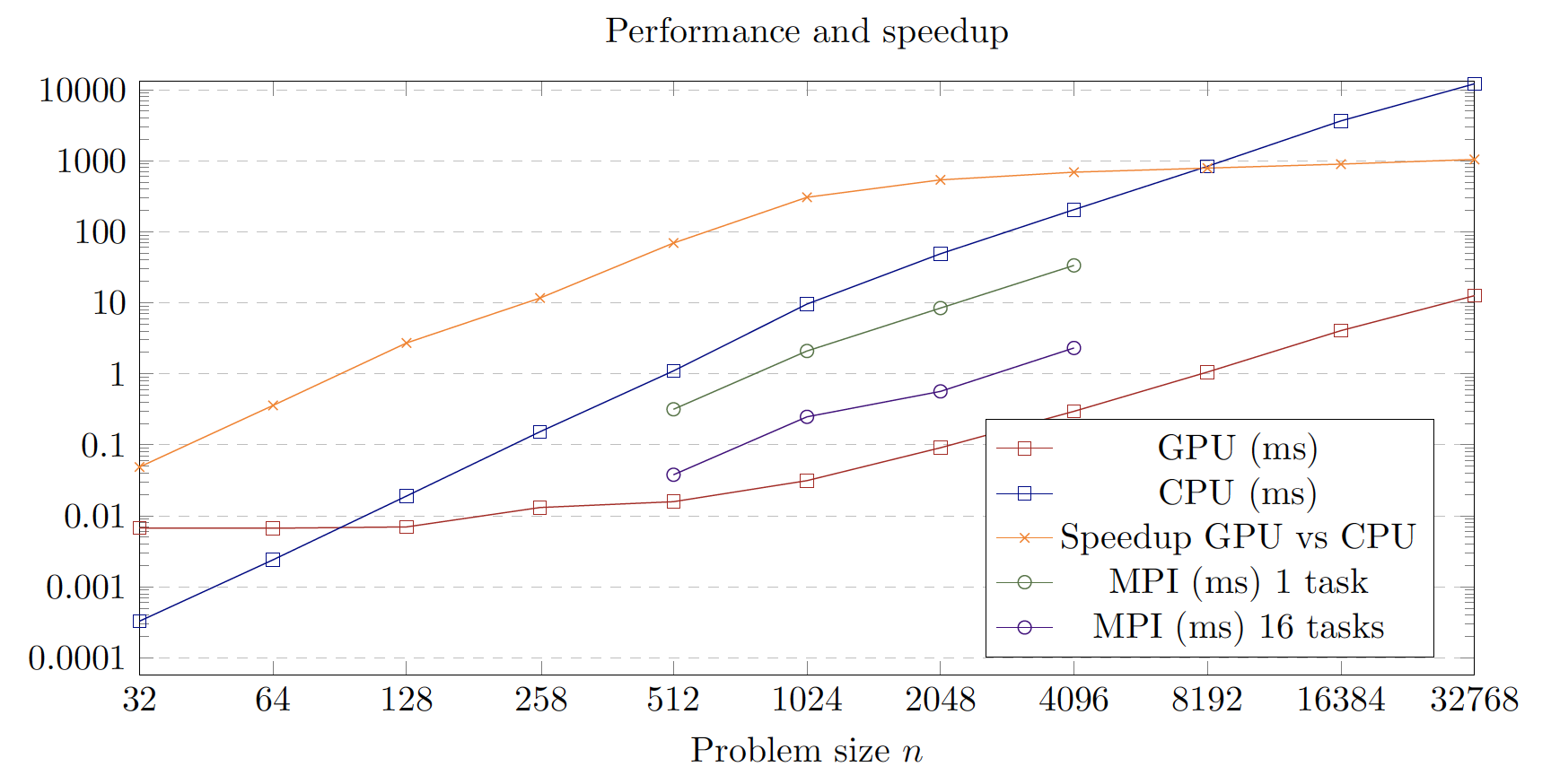
MPI benckmakrs
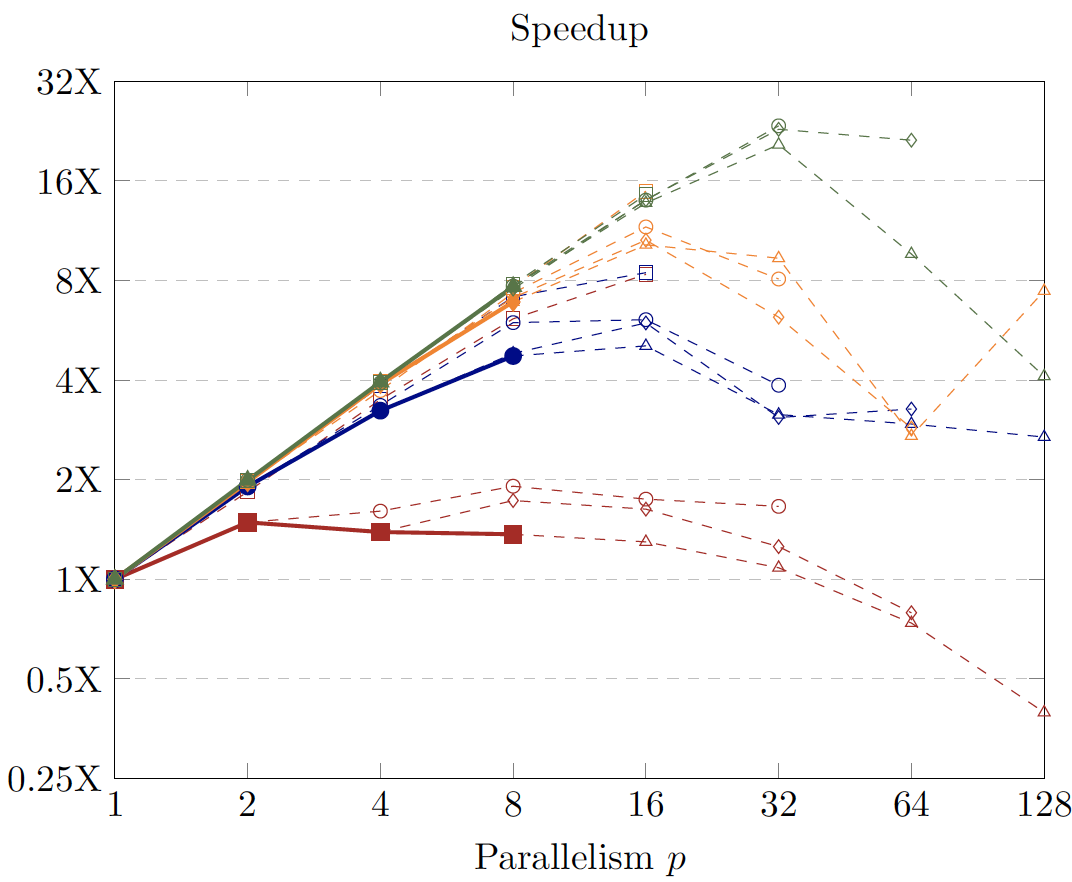
MPI + SIMD
On one machine
MPI speedup
MPI performance

CUDA
- Initialization
- Initialize GPU
- Copy all memory to GPU
- Iterations
- Asynchronously start all operations
- Sync with GPU once per iteration
- 1 double copied from GPU to CPU
- End
- Copy result to CPU
CUDA implementation
CUDA implementation
- Tiled matrix multiplication
- Using CUDA blocks and grids
- Aligned atomic addition operations
- Dot products
- Using standard parallel reduction
- Scalars on single threaded kernel
-
Use 2 streams
- Async memory copies
- Kernel concurrency
- Kernel atomicity and events
CUDA benchmarks

MPI + CUDA Budget
- Matrix of size:
- Sequential: 156 minutes
- CUDA with GeForce GTX 1080 Ti:
- 8.7 seconds if would fit in memory
- 91 distributed GPUs
- 107 ms with an efficiency of 0.9
- 9.6 seconds with an efficiency of 0.1
n=10^6
End
PHPC - Conjugate Gradient
By Nicolas Stucki


