Archival Crawlers and JavaScript: Discover More Stuff but Crawl More Slowly
Justin F. Brunelle
The MITRE Corporation jbrunelle@mitre.org
Michele C. Weigle
Old Dominion University,
Department of Computer Science
mweigle@cs.odu.edu
Michael L. Nelson
Old Dominion University,
Department of Computer Science
mln@cs.odu.edu
Digital libraries and archives

Introduction
-
Ukrainian separatists
- Malaysian Airlines Flight 17 (MH17)
- Stop Online Piracy Act (SOPA)
- Nondeferred representation
- Deferred representation
- Heritrix
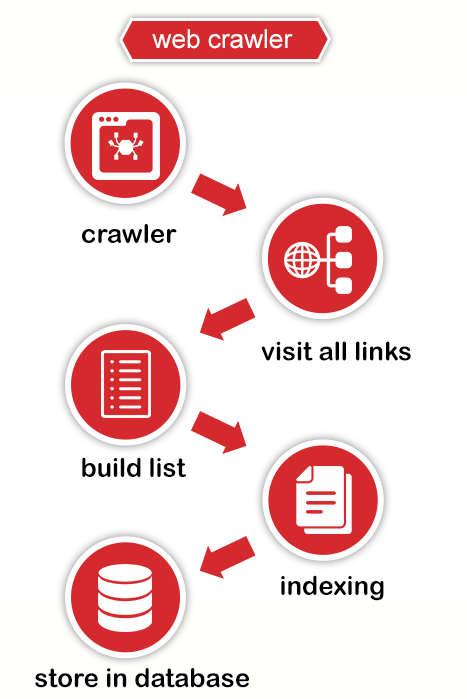
- does not execute any client-side scripts or use headless or headful browsing technologies.
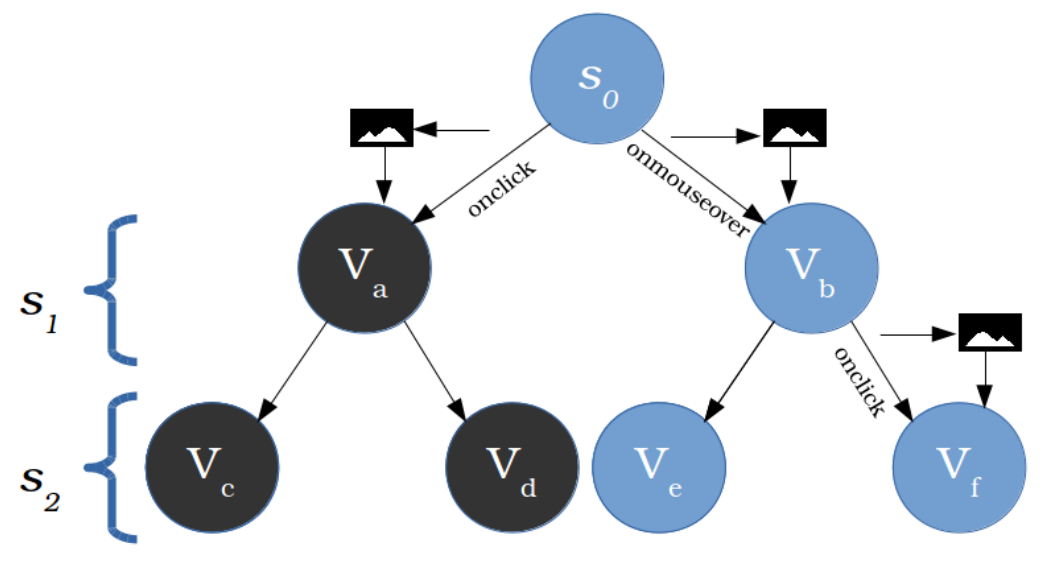
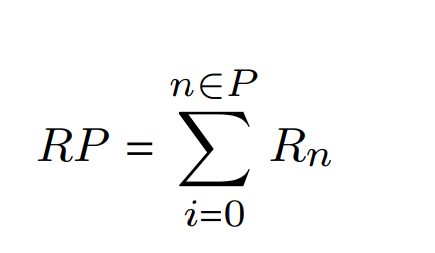
DESCENDANT MODEL
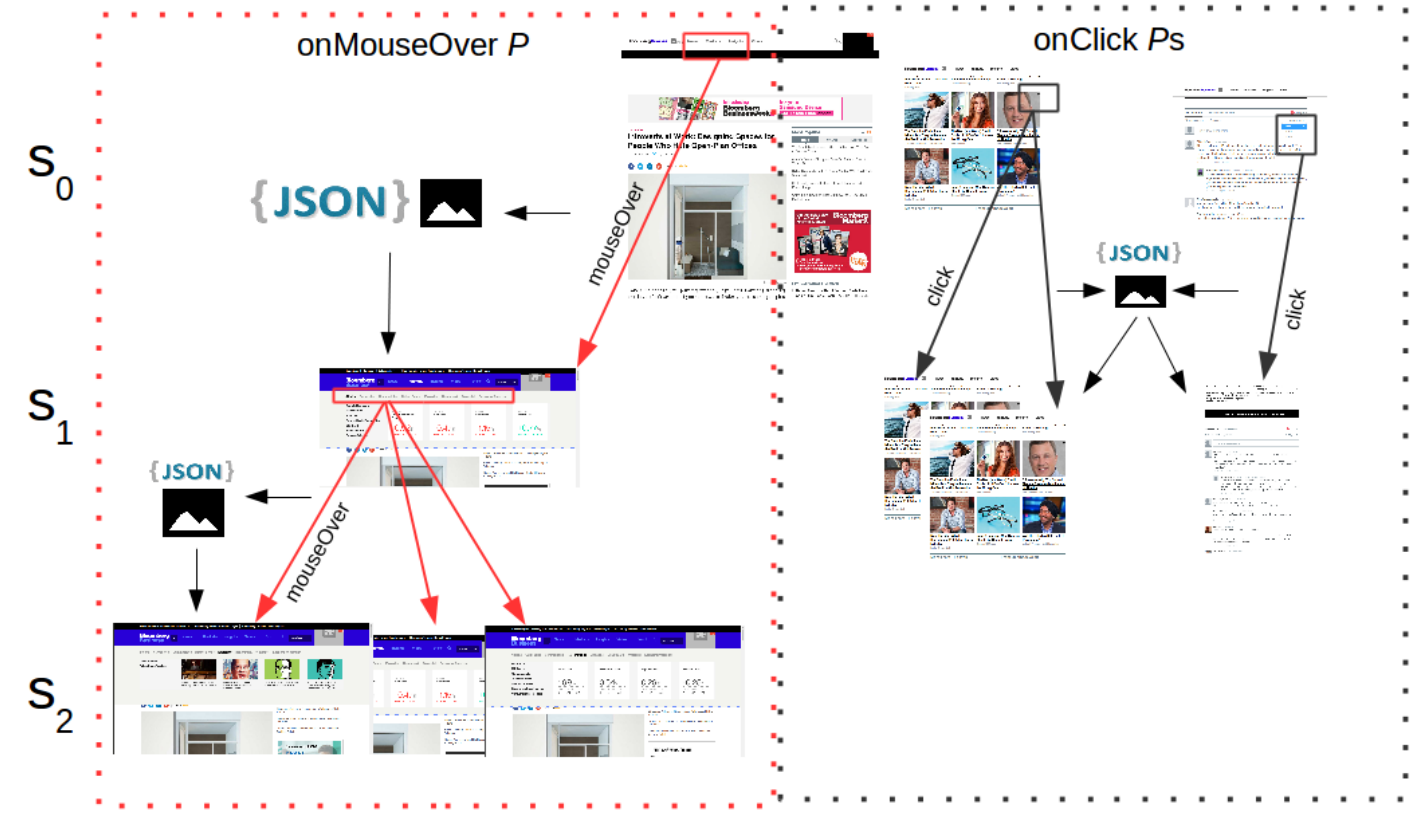
Approach
- PhantomJS
- Headless WebKit scriptable with a JavaScript API. It has fast and native support for various web standards.
- VisualEvent
- Open source Javascript bookmarklet which provides debugging information about events that have been attached to DOM elements
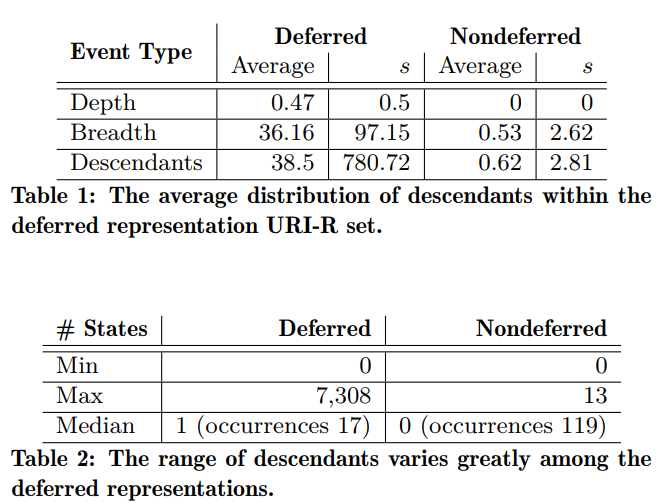
Dataset Differences
Conclusions
- Crawling all descendants is 38.9 times slower than crawling with only Heritrix, but adds 15.60 times more data to the crawl frontier than Heritrix alone
- 92% unarchived, and assumed to be undiscovered, at s1 and 96% at s2
- Help understand how much web archives and crawlers are missing by not accurately crawling deferred representations
- The increased frontier size and associated metadata will introduce storage challenges with deferred representations requiring 5.12 times more storage.
References
F. BRUNELLE, J., C. WEIGLE, M. AND L. NELSON, M.
Archival Crawlers and JavaScript: Discover More Stuff but Crawl More Slowly
F. Brunelle, J., C. Weigle, M. and L. Nelson, M. (2016). Archival Crawlers and JavaScript: Discover More Stuff but Crawl More Slowly. IEEE.
Archival Crawlers and JavaScript: Discover More Stuff but Crawl More Slowly
By Nifled -


