Rabble Recommender Research Report & Roadmap
Noah Ó Donnaile | November 2018
https://slides.com/noahodonnaile/recommender-systems
Recommender systems use the opinions of a community of users to help individuals in that community more effectively identify content of interest from a potentially overwhelming set of choices
Resnick and Varian, 1997
Recommender systems are information filtering systems that deal with the problem of information overload by filtering vital information fragment out of large amount of dynamically generated information according to user’s preferences, interest, or observed behavior about item
F.O. Isinkaye et al., 2015
An Scéal Rabble
Rabble recommender recap
What does Rabble need to recommend?
In order of importance, in my opinion:
- Who should I follow?
- What article should I read next after finishing this article?
- On my home feed, what content (from authors I may or may not follow) might interest me?
- What users are similar to this user I'm looking at?
Rabble-specific constraints
- Do not get in the way of an author building a brand. Recommendations for other author's content shouldn't get in the way of the author's own content and brand.
- "Ease of hosting an instance" was a goal; this implies resource use should be kept reasonably low (or that it can be configured to be so) so a beefy server is not needed.
- Should be possible for an admin to switch out the recommender used, or to turn it off. Algorithms & recommendations are not always wanted.
- ACLs, etc. should be kept in mind in recommendations. We shouldn't tell the user they're missing out on interesting content from a private account.
Rabble-specific features
- Reader enjoyment is an explicit success metric of the project. => We should try and give good recommendations!
- Transparency: Giving specific reasons why something was recommended to you is nice UX.
- Surfacing old-but-good content might be nice at some stage.
- Recommending content on other instances may increase network connectivity and lessen the echo chamber problem (which federated networks suffer more heavily from)
- Sharing recommendations across the federation is something that is interesting. // TODO(iandioch): another presentation sometime about this.
Recommender systems, how do they work?
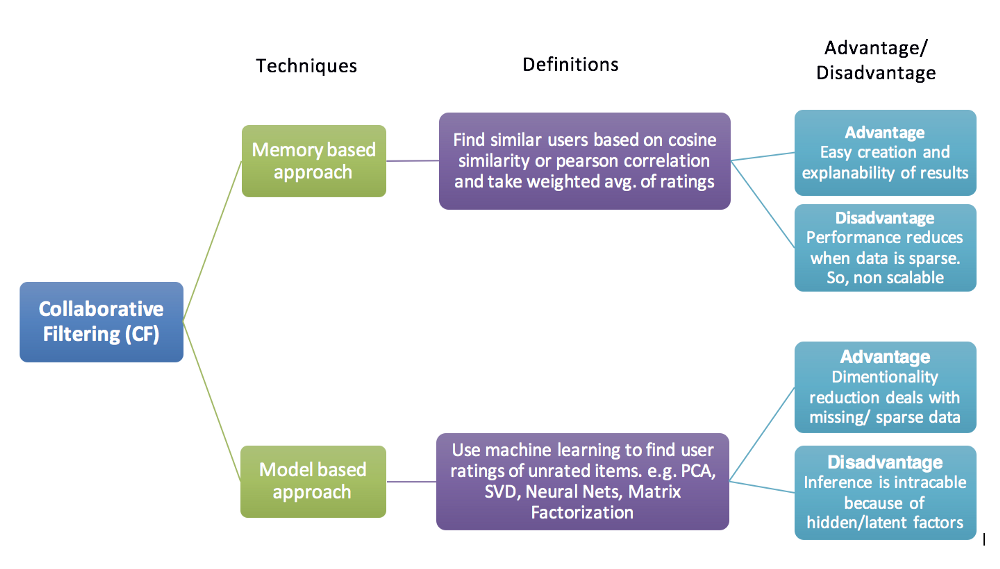
Collaborative Filtering
Assumption:
Users who had similar preferences in the past are likely to have similar preferences in the future
Memory-based
Memory-based algorithms approach the collaborative filtering problem by using the entire database. A memory-based system tries to find users that are similar to the active user (i.e. the users we want to make predictions for), and uses their preferences to predict ratings for the active user.
Edited from: Computer Science Comprehensive Exercise, Carleton College
How to calculate similarity?
There are a good number of different algorithms used in memory-based collaborative filtering to calculate the similarity between users.
Eg. Euclidean Distance, Pearsson coefficient, Cosine-based vector similarity, k-Nearest Neighbours, Jaccard similarity coefficient.
Pros
- High-quality predictions
- Relatively easy to implement
- Easy to update the database, since it uses the entire database every time it makes a prediction.
Cons
- Very slow, as it uses the entire database with every prediction.
- If a user has no items in common with all people who have rated the target item, it can't predict.
- Overfits the data. Memory-based systems do not generalize the data at all.
Improvements
- Default Voting: Correlation does not work very well on sparse data sets. That is, when two users have few items in common, their weights tend to be over-emphasized. Default voting simply adds a number of imaginary items that both have rated in common in order to smooth the votes.
- Inverse User Frequency: Commonly enjoyed items are less important to weight than rarer items. Just transform each vote when weighting two users such that commonly rated items are given less importance.
- Case Amplification: Amplify each weight by an exponent so that higher weights get higher and lower ones get lower.
Model-based
Model-based recommendation systems involve building a model based on the dataset of ratings.
We extract some information from the dataset, and use that as a "model" to make recommendations (without having to use the complete dataset every time).
Approaches
Probability problem: The problem of predicting a rating for a user-item pair is seen as the problem of predicting the probability of the rating being a particular value. See: Bayesian networks, clustering.
Linear algebra: Consider the matrices of users and ratings available to us and perform linear algebra operations on them. Eg. Singular Value Decomposition.
Pros
- Scales pretty well, as the models are smaller than the actual dataset.
- Predictions take less time to compute than in memory-based systems.
- Can generalise the dataset and not overfit as much as memory-based systems.
Cons
- Building a model can be time- and resource-consuming. Adding data to the model is therefore difficult.
- Predictions may not be as good as in memory-based systems, as information in the data may be lost when building the model.
Limitations of collaborative filtering
-
Cold start problem
New users have no relations to other users. -
New item problem
Users will have no opinions on new items. -
Sparcity
If there are not many connections in the graph, then it is difficult to find similar users who have an opinion on a particular item. -
Transparency
It is difficult to say why a particular item is strongly recommended.
Dangers
-
Positive feedback
Collaborative filters are expected to increase diversity because they help us discover new products. Some algorithms, however, may unintentionally do the opposite. Because collaborative filters recommend products based on past sales or ratings, they cannot usually recommend products with limited historical data. This can create a rich-get-richer effect for popular products, akin to positive feedback.
Content-based recommender systems
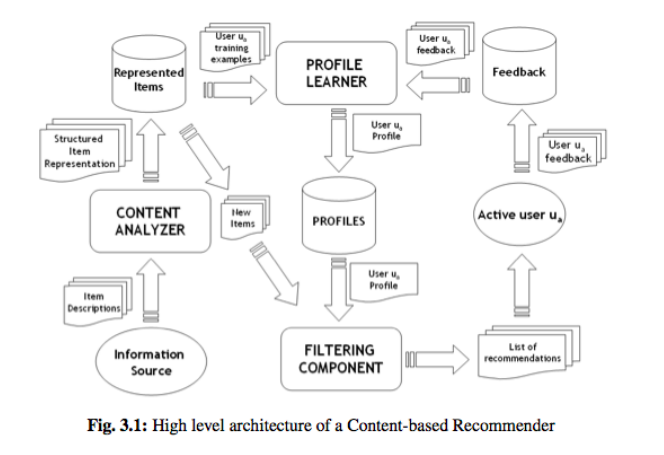
Content-based
Content-Based recommender systems are born from the idea of using the content of each item for recommending purposes, and trying to solve the problems with collaborative filtering (eg. cold start, dealing with sparcity, transparency, etc.).
Method
In a system tailored for text, a bag-of-words method (eg. TF-IDF) can be used to find terms that are common between two items but rare across the dataset as a whole. This implies these documents are related.
Limitations
A recommender system should recommend things people would not find otherwise; ie. incremental sales. Content-based systems often just find extremely similar items that the user already knew about, or is not interested in.
"If a customer is looking at the product details page for Harry Potter and the Chamber of Secrets, and your recommender shows Prisoner of Azkaban, and the customer buys it, the data scientists back at Random House HQ should not be high-fiving.
It's a safe bet that that customer already knew there were more than two books in the series and would have bought Prisoner of Azkaban anyway"
Limitations
Content-based recommenders are not good at capturing inter-dependencies or complex behaviours.
Eg. I like articles on ML only when they include practical application along with the theory, and not just theory. A content-based recommender will miss this.
Limitations
Over-specialisation
A content-based filtering system will not select items if the previous user behaviour does not provide evidence for this. Additional techniques have to be added to give the system the capability to make suggestion outside the scope of what the user has already shown interest in.
Related: Creation of an echo-chamber.
Hybrid models
A system that combines content-based filtering and collaborative filtering could take advantage from both the representation of the content as well as the similarities among users.
Collaboration via Content
Chosen characteristics of a decentralised recommender system
Towards Decentralized Recommender Systems; Cai-Nicolas Ziegler 2005

Evaluating a recommender
Online methods (ie. asking users how useful a recommendation was) are infeasible. Offline methods (run on historical data) must be used.
Accuracy refers to how much predicted ratings differ from real ratings. Eg: mean absolute error (MAE), mean squared error (MSE), RMSE, etc.
Decision-support metrics judge how relevant a ranked set of recommendations is for a user. Eg: precision, recall, F1, Breese score/weighted recall, etc.
Misc. problems to consider
- Cold start problem
- Content in different forms
- Text in other languages
- Video / photo blogs
- Microblogs
- Content behind ACLs
- Spread the computation of recommendations across the federation
- Do not create feedback which reinforces an echo chamber.
Recommender Systems Research for Rabble
By Noah Ó Donnaile

