Języki programowania
Uniwersytet SWPS
Psychologia i informatyka
"Python to język programowania, który pozwala pracować szybciej i efektywniej integrować systemy." - Python Software Foundation
1. Wprowadzenie i Przygotowanie Środowiska
Instalacja i konfiguracja interpretera Pythona
- Python można pobrać z python.org
- Wybierz najnowszą stabilną wersję (Python 3.11+)
- Podczas instalacji zaznacz 'Add Python to PATH'
- Weryfikacja instalacji: python --version
Wybór edytora kodu
Popularne edytory dla Python:
- PyCharm - profesjonalne IDE
- VS Code - lekki, wszechstronny
- Jupyter Notebook - interaktywne notatniki
- IDLE - wbudowany w Pythona
Ciekawostka: Guido van Rossum, twórca Pythona, nazwał język na cześć grupy komediowej Monty Python!
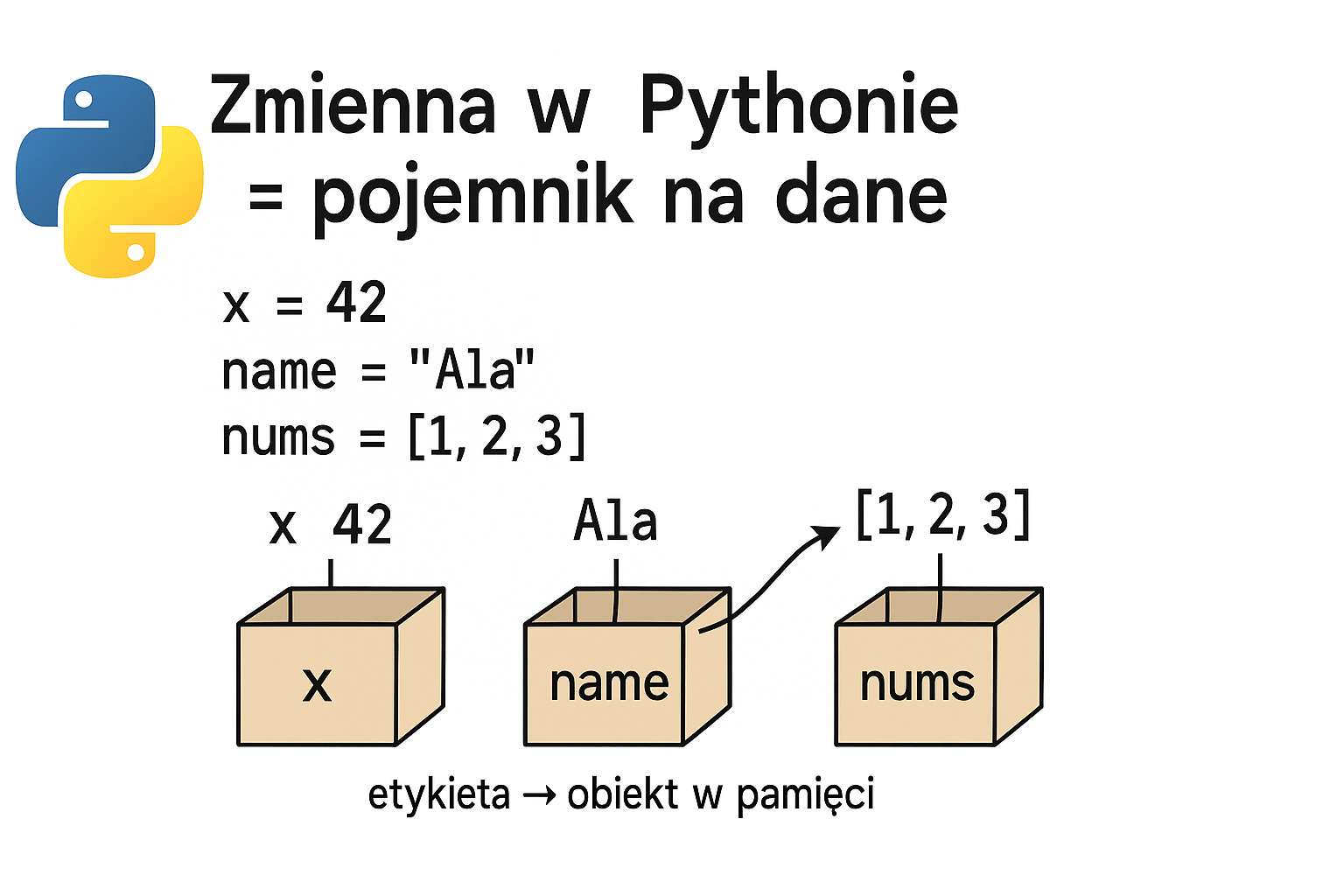
2. Podstawy Programowania w Pythonie
Zmienne i proste obliczenia
Zmienne to 'pojemniki' na dane. W Pythonie nie trzeba deklarować typu!
# Zmienne i obliczenia
x = 10
y = 20
suma = x + y # 30
roznica = y - x # 10
iloczyn = x * y # 200
iloraz = y / x # 2.0
potega = x ** 2 # 100 (x do kwadratu)
reszta = y % 3 # 2 (reszta z dzielenia)2. Podstawy Programowania w Pythonie
Zmienne i proste obliczenia
Zmienne to 'pojemniki' na dane. W Pythonie nie trzeba deklarować typu!
Typy Danych - Fundamenty
# int - liczby całkowite
wiek = 25
temperatura = -5
# float - liczby zmiennoprzecinkowe
cena = 19.99
pi = 3.14159
# str - łańcuchy znaków
imie = "Anna"
miasto = 'Kraków' # można używać ' lub "
wielolinia = """Tekst
w wielu
liniach"""
# bool - wartości logiczne
jest_studentem = True
ma_prawo_jazdy = FalseOperacje na Łańcuchach Znaków
# Łączenie stringów
imie = "Jan"
nazwisko = "Kowalski"
pelne_imie = imie + " " + nazwisko # "Jan Kowalski"
# f-stringi (formatowanie)
wiek = 30
info = f"Mam na imię {imie} i mam {wiek} lat"
# Metody stringów
tekst = "python jest świetny"
print(tekst.upper()) # PYTHON JEST ŚWIETNY
print(tekst.capitalize()) # Python jest świetny
print(tekst.replace("python", "Python")) # Python jest świetny
print(tekst.split()) # ['python', 'jest', 'świetny']
print(len(tekst)) # 19 (długość)Konwersja Typów Danych
# Konwersja między typami
wiek_str = "25"
wiek_int = int(wiek_str) # string → int
cena_float = 19.99
cena_int = int(cena_float) # 19 (ucina część dziesiętną!)
liczba = 42
tekst = str(liczba) # int → string
# Sprawdzanie typu
print(type(wiek_int)) #
print(isinstance(wiek_int, int)) # True
# UWAGA: Typowe błędy!
# int("19.99") # ValueError! Najpierw float("19.99")
# int("sto") # ValueError! Nie można przekonwertowaćTypowe Błędy i Ich Naprawa
# BŁĄD 1: Dzielenie przez zero
# wynik = 10 / 0 # ZeroDivisionError
# Rozwiązanie: sprawdzaj przed dzieleniem
dzielnik = 0
if dzielnik != 0:
wynik = 10 / dzielnik
# BŁĄD 2: Łączenie różnych typów
# wiadomosc = "Mam " + 25 + " lat" # TypeError
# Rozwiązanie: konwersja na string
wiadomosc = "Mam " + str(25) + " lat"
# LUB użyj f-stringa
wiadomosc = f"Mam {25} lat"
# BŁĄD 3: Literówki w nazwach zmiennych
# imię = "Jan" # Unicode w nazwie - lepiej unikać
# print(imie) # NameError
imie = "Jan" # Lepiej bez polskich znaków w nazwach3. Struktury Kontrolne
Instrukcje Warunkowe (if, elif, else)
# Podstawowa instrukcja if
wiek = 20
if wiek >= 18:
print("Jesteś pełnoletni")
# if-else
temperatura = 15
if temperatura > 20:
print("Jest ciepło")
else:
print("Jest chłodno")
# if-elif-else (wiele warunków)
ocena = 85
if ocena >= 90:
print("Ocena: Bardzo dobry")
elif ocena >= 75:
print("Ocena: Dobry")
elif ocena >= 60:
print("Ocena: Dostateczny")
else:
print("Ocena: Niedostateczny")Operatory Porównania i Logiczne
# Operatory porównania
x = 10
y = 20
print(x == y) # False (równe?)
print(x != y) # True (różne?)
print(x < y) # True (mniejsze?)
print(x <= y) # True (mniejsze lub równe?)
# Operatory logiczne: and, or, not
wiek = 25
ma_dowod = True
# AND - oba warunki muszą być prawdziwe
if wiek >= 18 and ma_dowod:
print("Może prowadzić samochód")
# OR - przynajmniej jeden warunek prawdziwy
jest_weekend = True
jest_urlop = False
if jest_weekend or jest_urlop:
print("Można odpocząć!")
# NOT - negacja
if not jest_urlop:
print("Trzeba iść do pracy")Pętla FOR - Iteracja po Sekwencjach
# Pętla for przez listę
owoce = ["jabłko", "banan", "gruszka"]
for owoc in owoce:
print(f"Lubię {owoc}")
# Pętla for z range()
for i in range(5): # 0, 1, 2, 3, 4
print(f"Liczba: {i}")
# range() z początkiem i końcem
for i in range(2, 6): # 2, 3, 4, 5
print(i)
# range() z krokiem
for i in range(0, 10, 2): # 0, 2, 4, 6, 8
print(i)
# enumerate() - iteracja z indeksem
for indeks, owoc in enumerate(owoce):
print(f"{indeks}: {owoc}")Pętla WHILE i Sterowanie (break, continue)
# Pętla while - wykonuje się, gdy warunek prawdziwy
licznik = 0
while licznik < 5:
print(licznik)
licznik += 1
# BREAK - przerywa pętlę
for i in range(10):
if i == 5:
break # Zatrzymuje pętlę
print(i) # Wypisze: 0, 1, 2, 3, 4
# CONTINUE - przechodzi do następnej iteracji
for i in range(5):
if i == 2:
continue # Pomija resztę kodu dla i=2
print(i) # Wypisze: 0, 1, 3, 4
# Praktyczny przykład: walidacja hasła
while True:
haslo = input("Podaj hasło (min 8 znaków): ")
if len(haslo) <= 8:
break
print("Hasło za krótkie!")4. Struktury Danych
LISTY - Zmienne, Uporządkowane Kolekcje
# Tworzenie listy
liczby = [1, 2, 3, 4, 5]
mieszana = [1, "tekst", 3.14, True]
# Dodawanie elementów
liczby.append(6) # Dodaje na koniec
liczby.insert(0, 0) # Wstawia na pozycję 0
# Usuwanie elementów
liczby.remove(3) # Usuwa pierwszą wartość 3
ostatni = liczby.pop() # Usuwa i zwraca ostatni element
del liczby[0] # Usuwa element na pozycji 0
# Operacje
print(len(liczby)) # Długość listy
print(2 in liczby) # Sprawdza czy 2 jest na liście
print(liczby.count(2)) # Ile razy 2 występuje
liczby.sort() # Sortuje listę
liczby.reverse() # Odwraca kolejnośćKROTKI (Tuples) - Niezmienne Sekwencje
# Krotki - podobne do list, ale NIEZMIENNE
punkt = (10, 20)
osoba = ("Jan", "Kowalski", 30)
# Dostęp do elementów (jak w listach)
x = punkt[0] # 10
y = punkt[1] # 20
# Rozpakowanie krotki
imie, nazwisko, wiek = osoba
print(f"{imie} ma {wiek} lat")
# Krotki są niezmienne!
# punkt[0] = 15 # TypeError! Nie można zmienić
# Kiedy używać krotek?
# - Dane, które nie powinny się zmieniać (współrzędne, daty)
# - Zwracanie wielu wartości z funkcji
# - Klucze w słownikach (listy nie mogą być kluczami!)
# Ciekawostka: krotka 1-elementowa wymaga przecinka!
krotka = (5,) # To jest krotka
nie_krotka = (5) # To jest int!SŁOWNIKI - Pary Klucz-Wartość
# Słownik - mapowanie klucz → wartość
student = {
"imie": "Anna",
"nazwisko": "Nowak",
"wiek": 22,
"oceny": [4, 5, 4, 5]
}
# Dostęp do wartości
print(student["imie"]) # Anna
print(student.get("wiek")) # 22
print(student.get("email", "brak")) # Zwróci "brak" jeśli nie ma
# Dodawanie/modyfikacja
student["email"] = "anna@example.com"
student["wiek"] = 23
# Iteracja przez słownik
for klucz in student:
print(f"{klucz}: {student[klucz]}")
for klucz, wartosc in student.items():
print(f"{klucz}: {wartosc}")
# Przydatne metody
print(student.keys()) # Wszystkie klucze
print(student.values()) # Wszystkie wartościZBIORY (Sets) - Unikalne Elementy
# Zbiór - nieuporządkowana kolekcja unikalnych elementów
liczby = {1, 2, 3, 4, 5}
kolory = {"czerwony", "niebieski", "zielony"}
# Automatycznie usuwa duplikaty!
duplikaty = {1, 2, 2, 3, 3, 3}
print(duplikaty) # {1, 2, 3}
# Operacje na zbiorach
liczby.add(6) # Dodaje element
liczby.remove(1) # Usuwa element (błąd jeśli nie ma)
liczby.discard(10) # Usuwa element (bez błędu)
# Operacje matematyczne na zbiorach
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
print(A | B) # Suma (union): {1, 2, 3, 4, 5, 6}
print(A & B) # Przecięcie (intersection): {3, 4}
print(A - B) # Różnica: {1, 2}
# Sprawdzanie przynależności (bardzo szybkie!)
print(3 in A) # TrueStosy i Kolejki - Zaawansowane Struktury
from collections import deque
# STOS (Stack) - LIFO (Last In, First Out)
# "Ostatni wszedł, pierwszy wyszedł" - jak stos talerzy
stos = []
stos.append(1) # Kładziemy na stos
stos.append(2)
stos.append(3)
print(stos.pop()) # 3 - zdejmujemy ostatni
# KOLEJKA (Queue) - FIFO (First In, First Out)
# "Pierwszy wszedł, pierwszy wyszedł" - jak kolejka w sklepie
kolejka = deque()
kolejka.append(1) # Dodajemy na koniec
kolejka.append(2)
kolejka.append(3)
print(kolejka.popleft()) # 1 - bierzemy pierwszy
# Praktyczne zastosowanie: historia poleceń (Undo/Redo)
historia = []
historia.append("Wpisałem tekst")
historia.append("Usunąłem słowo")
ostatnia_akcja = historia.pop() # Cofnij ostatnią akcję5. Unpacking - Rozpakowywanie
Podstawy Unpacking
# Unpacking to rozpakowywanie wartości z kolekcji do zmiennych
# Podstawowy unpacking z listy/krotki
punkt = (10, 20)
x, y = punkt
print(x, y) # 10 20
# Unpacking listy
dane = ["Jan", "Kowalski", 30]
imie, nazwisko, wiek = dane
print(f"{imie} {nazwisko}, {wiek} lat")
# Unpacking w pętli for
osoby = [("Anna", 25), ("Piotr", 30), ("Maria", 28)]
for imie, wiek in osoby:
print(f"{imie}: {wiek} lat")
# Zamiana wartości zmiennych (bez trzeciej zmiennej!)
a = 5
b = 10
a, b = b, a # Zamiana miejscami
print(a, b) # 10 5
# Unpacking z funkcji zwracającej krotkę
def get_coordinates():
return (100, 200, 300)
x, y, z = get_coordinates()
print(x, y, z) # 100 200 300Extended Unpacking - Operator *
# Operator * (gwiazdka) - zbiera pozostałe elementy
# Pierwsza i reszta
liczby = [1, 2, 3, 4, 5]
pierwsza, *reszta = liczby
print(pierwsza) # 1
print(reszta) # [2, 3, 4, 5]
# Pierwsza, ostatnia i środek
pierwszy, *srodek, ostatni = liczby
print(pierwszy) # 1
print(srodek) # [2, 3, 4]
print(ostatni) # 5
# Ignorowanie elementów
a, *_, b = [1, 2, 3, 4, 5]
print(a, b) # 1 5
# Unpacking z różną liczbą elementów
def suma_pierwszych_dwoch(*args):
pierwszy, drugi, *pozostale = args
return pierwszy + drugi
print(suma_pierwszych_dwoch(10, 20, 30, 40)) # 30
# Unpacking zagnieżdżonych struktur
dane = [("Jan", (25, "Warszawa")), ("Anna", (30, "Kraków"))]
for imie, (wiek, miasto) in dane:
print(f"{imie}, {wiek} lat, {miasto}")Unpacking Słowników
# Unpacking słowników z **
# Łączenie słowników
slownik1 = {"a": 1, "b": 2}
slownik2 = {"c": 3, "d": 4}
polaczony = {**slownik1, **slownik2}
print(polaczony) # {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# Nadpisywanie wartości
domyslne = {"theme": "dark", "lang": "pl", "size": 12}
uzytkownik = {"theme": "light", "size": 14}
config = {**domyslne, **uzytkownik}
print(config) # {'theme': 'light', 'lang': 'pl', 'size': 14}
# Unpacking w funkcjach
def utworz_profil(imie, wiek, miasto):
return f"{imie}, {wiek} lat, {miasto}"
dane = {"imie": "Jan", "wiek": 30, "miasto": "Warszawa"}
profil = utworz_profil(**dane)
print(profil) # Jan, 30 lat, Warszawa
# Rozpakowywanie items()
osoba = {"imie": "Anna", "wiek": 25}
for klucz, wartosc in osoba.items():
print(f"{klucz}: {wartosc}")Unpacking w Funkcjach - *args i **kwargs
# *args - argumenty pozycyjne (tuple)
def suma(*args):
"""Sumuje dowolną liczbę argumentów."""
return sum(args)
print(suma(1, 2, 3)) # 6
print(suma(10, 20, 30, 40)) # 100
# **kwargs - argumenty nazwane (dictionary)
def info_osoby(**kwargs):
"""Wyświetla informacje o osobie."""
for klucz, wartosc in kwargs.items():
print(f"{klucz}: {wartosc}")
info_osoby(imie="Jan", wiek=30, miasto="Warszawa")
# imie: Jan
# wiek: 30
# miasto: Warszawa
# Łączenie *args i **kwargs
def zaawansowana_funkcja(a, b, *args, **kwargs):
print(f"Pozycyjne: a={a}, b={b}")
print(f"Dodatkowe pozycyjne: {args}")
print(f"Nazwane: {kwargs}")
zaawansowana_funkcja(1, 2, 3, 4, 5, x=10, y=20)
# Pozycyjne: a=1, b=2
# Dodatkowe pozycyjne: (3, 4, 5)
# Nazwane: {'x': 10, 'y': 20}Unpacking w Wywołaniach Funkcji
# Rozpakowywanie przy wywołaniu funkcji
def oblicz(a, b, c):
return a + b * c
# Bez unpacking
wynik1 = oblicz(1, 2, 3)
print(wynik1) # 7
# Z unpacking listy/krotki
liczby = [1, 2, 3]
wynik2 = oblicz(*liczby)
print(wynik2) # 7
# Unpacking słownika
def przedstaw_sie(imie, nazwisko, wiek):
return f"Jestem {imie} {nazwisko}, mam {wiek} lat"
dane = {"imie": "Jan", "nazwisko": "Kowalski", "wiek": 30}
tekst = przedstaw_sie(**dane)
print(tekst)
# Praktyczny przykład: przekazywanie do print()
elementy = ["jabłko", "banan", "gruszka"]
print(*elementy) # jabłko banan gruszka
print(*elementy, sep=", ") # jabłko, banan, gruszka
# Łączenie list
lista1 = [1, 2, 3]
lista2 = [4, 5, 6]
lista3 = [7, 8, 9]
wszystkie = [*lista1, *lista2, *lista3]
print(wszystkie) # [1, 2, 3, 4, 5, 6, 7, 8, 9]Praktyczne Zastosowania Unpacking
# 1. Parsowanie danych CSV
dane_csv = "Jan,Kowalski,30,Warszawa"
imie, nazwisko, wiek, miasto = dane_csv.split(",")
# 2. Paginacja - pierwsza strona i reszta
wszystkie_strony = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pierwsza, *pozostale = wszystkie_strony
# 3. Rozdzielanie nagłówków i danych
plik_csv = [
["Imię", "Nazwisko", "Wiek"],
["Jan", "Kowalski", "30"],
["Anna", "Nowak", "25"]
]
naglowki, *wiersze = plik_csv
# 4. Tworzenie konfiguracji z wartościami domyślnymi
def polacz_config(**config):
domyslne = {"debug": False, "port": 8080, "host": "localhost"}
return {**domyslne, **config}
moja_config = polacz_config(debug=True, port=3000)
# {'debug': True, 'port': 3000, 'host': 'localhost'}
# 5. Decorator pattern
def moj_decorator(func):
def wrapper(*args, **kwargs):
print("Przed wywołaniem")
wynik = func(*args, **kwargs)
print("Po wywołaniu")
return wynik
return wrapper
@moj_decorator
def przywitaj(imie):
print(f"Cześć, {imie}!")
przywitaj("Jan")Zaawansowane Techniki i Pułapki
DOBRE PRAKTYKI:
- Unpacking zwiększa czytelność kodu
- Zamiast: x = punkt[0], y = punkt[1]
- Użyj: x, y = punkt
- Używaj _ dla ignorowanych wartości
- pierwszy, _, trzeci = [1, 2, 3]
- * może wystąpić tylko raz w unpacking
- a, *b, *c = [1,2,3] # BŁĄD!
- Liczba zmiennych musi pasować (bez *)
- a, b = [1, 2, 3] # ValueError!
- a, b, *c = [1, 2, 3] # OK: c=[3]
Zaawansowane Techniki i Pułapki
PUŁAPKI:
- Unpacking zagnieżdżonych struktur może być mało czytelny
- * tworzy listę, nawet dla pustej sekwencji
- ** działa tylko ze słownikami (mapowaniami)
- Kolejność w **kwargs nie jest gwarantowana (Python < 3.7)
Kiedy używać unpacking?
- Zwracanie wielu wartości z funkcji
- Iteracja po parach klucz-wartość
- Przekazywanie parametrów do funkcji
- Łączenie kolekcji
- Zamiana wartości bez zmiennej tymczasowej
6. Obsługa Błędów
Rodzaje Błędów w Pythonie
- SyntaxError - błąd składni (literówki, brakujące dwukropki)
- NameError - użycie niezdefiniowanej zmiennej
- TypeError - operacja na złym typie danych
- ValueError - dobry typ, zła wartość
- ZeroDivisionError - dzielenie przez zero
- IndexError - indeks poza zakresem
- KeyError - brak klucza w słowniku
- FileNotFoundError - brak pliku
Try/Except - Obsługa Wyjątków
# Podstawowa obsługa błędów
try:
liczba = int(input("Podaj liczbę: "))
wynik = 10 / liczba
print(f"Wynik: {wynik}")
except ValueError:
print("To nie jest liczba!")
except ZeroDivisionError:
print("Nie można dzielić przez zero!")
# Złapanie dowolnego błędu
try:
# ryzykowny kod
plik = open("nieistniejacy.txt")
except Exception as e:
print(f"Wystąpił błąd: {e}")
# Try-except-else-finally
try:
liczba = int(input("Liczba: "))
except ValueError:
print("Błąd!")
else:
print("Sukces! Kod wykonał się bez błędów")
finally:
print("Ten kod wykonuje się ZAWSZE")Debugowanie Kodu
# Technika 1: Wypisywanie (print debugging)
def oblicz_srednia(liczby):
print(f"DEBUG: liczby = {liczby}") # Co wchodzi?
suma = sum(liczby)
print(f"DEBUG: suma = {suma}") # Jaki wynik?
return suma / len(liczby)
# Technika 2: Assercje - sprawdzanie założeń
def podziel(a, b):
assert b != 0, "Dzielnik nie może być zerem!"
return a / b
# Technika 3: Używanie debuggera
# W PyCharm/VS Code: postaw breakpoint (czerwona kropka)
# i uruchom w trybie Debug (F5)
# Przydatne funkcje
print(type(zmienna)) # Jaki typ?
print(dir(obiekt)) # Jakie ma metody?
print(help(funkcja)) # Jak działa?
# Cytatu: "Everyone knows that debugging is twice as hard
# as writing a program in the first place." - Brian Kernighan7. Funkcje i Modularyzacja Kodu
Definiowanie i Wywoływanie Funkcji
# Funkcja bez parametrów
def powitanie():
print("Witaj w Pythonie!")
powitanie() # Wywołanie funkcji
# Funkcja z parametrami
def przywitaj_osobe(imie):
print(f"Witaj, {imie}!")
przywitaj_osobe("Anna")
# Funkcja zwracająca wartość
def dodaj(a, b):
return a + b
wynik = dodaj(5, 3) # wynik = 8
# Funkcja z wieloma wartościami zwracanymi
def statystyki(liczby):
return min(liczby), max(liczby), sum(liczby) / len(liczby)
minimum, maksimum, srednia = statystyki([1, 2, 3, 4, 5])Argumenty Funkcji - Wymagane i Opcjonalne
# Argumenty wymagane
def przedstaw_sie(imie, nazwisko):
print(f"Jestem {imie} {nazwisko}")
przedstaw_sie("Jan", "Kowalski") # Muszę podać oba
# Argumenty opcjonalne (z wartością domyślną)
def powitanie(imie, jezyk="polski"):
if jezyk == "polski":
print(f"Cześć, {imie}!")
elif jezyk == "angielski":
print(f"Hello, {imie}!")
powitanie("Anna") # Użyje "polski"
powitanie("John", "angielski") # Użyje "angielski"
# Argumenty nazwane (keyword arguments)
def zamow_kawe(rozmiar, rodzaj="espresso", cukier=False):
print(f"Zamówienie: {rozmiar} {rodzaj}, cukier: {cukier}")
zamow_kawe(rozmiar="duża", cukier=True, rodzaj="latte")
# *args i **kwargs - dowolna liczba argumentów
def suma_wszystkich(*args):
return sum(args)
print(suma_wszystkich(1, 2, 3, 4, 5)) # 15Zasięg Zmiennych - Lokalne i Globalne
# Zmienna globalna - widoczna wszędzie
licznik = 0
def zwieksz_licznik():
global licznik # Muszę zaznaczyć, że używam globalnej
licznik += 1
zwieksz_licznik()
print(licznik) # 1
# Zmienna lokalna - tylko wewnątrz funkcji
def oblicz():
wynik = 10 + 5 # Lokalna - nie widać na zewnątrz
return wynik
# print(wynik) # NameError! wynik nie istnieje tutaj
# Najlepsza praktyka: unikaj zmiennych globalnych!
# Lepiej:
def zwieksz(liczba):
return liczba + 1
licznik = zwieksz(licznik)
# Cytatu: "Programs must be written for people to read,
# and only incidentally for machines to execute." - Abelson & SussmanImportowanie Modułów
# Import całego modułu
import math
print(math.pi) # 3.14159...
print(math.sqrt(16)) # 4.0
# Import konkretnych funkcji
from math import pi, sqrt
print(pi)
print(sqrt(16))
# Import z aliasem (skrót)
import pandas as pd
import numpy as np
# Import własnego modułu
# Plik: moje_funkcje.py
def powitaj():
return "Cześć!"
# W innym pliku:
# import moje_funkcje
# print(moje_funkcje.powitaj())
# Popularne moduły wbudowane:
# - math: funkcje matematyczne
# - random: liczby losowe
# - datetime: data i czas
# - os: operacje na systemie
# - json: praca z JSONDekompozycja Problemu
# Zasada: dziel duże problemy na mniejsze funkcje!
# ŹLE: jedna wielka funkcja
def oblicz_wszystko(dane):
# 100 linii kodu...
pass
# DOBRZE: wiele małych funkcji
def wczytaj_dane(plik):
# Czyta dane z pliku
return dane
def waliduj_dane(dane):
# Sprawdza poprawność
return czy_poprawne
def przetworz_dane(dane):
# Przetwarza dane
return wynik
def zapisz_wynik(wynik, plik):
# Zapisuje do pliku
pass
# Główna funkcja koordynuje
def main():
dane = wczytaj_dane("input.txt")
if waliduj_dane(dane):
wynik = przetworz_dane(dane)
zapisz_wynik(wynik, "output.txt")
# Zasada DRY: Don't Repeat Yourself
# Jeśli coś robisz więcej niż raz - zrób z tego funkcję!Rekurencja - Funkcje Wywołujące Same Siebie
# Rekurencja to technika, gdy funkcja wywołuje samą siebie
# Przykład 1: Silnia (factorial)
def silnia(n):
"""
Oblicza silnię liczby n (n!)
5! = 5 * 4 * 3 * 2 * 1 = 120
"""
# Warunek bazowy (base case) - zatrzymuje rekurencję
if n == 0 or n == 1:
return 1
# Krok rekurencyjny
return n * silnia(n - 1)
print(silnia(5)) # 120
print(silnia(0)) # 1
# Przykład 2: Ciąg Fibonacciego
def fibonacci(n):
"""
Zwraca n-tą liczbę Fibonacciego
0, 1, 1, 2, 3, 5, 8, 13, 21, 34...
"""
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
for i in range(10):
print(fibonacci(i), end=" ") # 0 1 1 2 3 5 8 13 21 34
# Przykład 3: Suma elementów listy
def suma_rekurencyjna(lista):
"""Sumuje elementy listy rekurencyjnie."""
if len(lista) == 0:
return 0
return lista[0] + suma_rekurencyjna(lista[1:])
print(suma_rekurencyjna([1, 2, 3, 4, 5])) # 15Rekurencja vs Iteracja - Praktyczne Zastosowania
# Przykład 4: Odwracanie stringa
def odwroc_string(s):
"""Odwraca string rekurencyjnie."""
if len(s) <= 1:
return s
return s[-1] + odwroc_string(s[:-1])
print(odwroc_string("Python")) # nohtyP
# Przykład 5: Suma cyfr liczby
def suma_cyfr(n):
"""Sumuje cyfry liczby."""
if n < 10:
return n
return (n % 10) + suma_cyfr(n // 10)
print(suma_cyfr(12345)) # 15 (1+2+3+4+5)
# Przykład 6: Przeszukiwanie struktury katalogów
import os
def znajdz_pliki(sciezka, rozszerzenie):
"""Rekurencyjnie znajduje pliki z danym rozszerzeniem."""
wyniki = []
for element in os.listdir(sciezka):
pelna_sciezka = os.path.join(sciezka, element)
if os.path.isdir(pelna_sciezka):
# Rekurencja dla podkatalogów
wyniki.extend(znajdz_pliki(pelna_sciezka, rozszerzenie))
elif element.endswith(rozszerzenie):
wyniki.append(pelna_sciezka)
return wyniki
# pliki_py = znajdz_pliki(".", ".py")Optymalizacja Rekurencji i Pułapki
ZALETY REKURENCJI:
- Kod często prostszy i czytelniejszy
- Naturalny dla problemów o strukturze rekurencyjnej (drzewa, grafy)
- Matematycznie elegancki
WADY REKURENCJI:
- Wolniejsza niż iteracja (narzut wywołań funkcji)
- Zużywa więcej pamięci (stos wywołań)
- Ryzyko przekroczenia limitu głębokości rekurencji
Optymalizacja Rekurencji i Pułapki
KIEDY UŻYWAĆ REKURENCJI?
- Drzewa i grafy (traversal, search)
- Dziel i zwyciężaj (merge sort, quick sort)
- Backtracking (sudoku, labirynty)
- Struktury zagnieżdżone (JSON, XML)
KIEDY UNIKAĆ?
- Proste pętle (for, while wystarczą)
- Duże zbiory danych (ryzyko stack overflow)
- Wydajność krytyczna
Pamiętaj: Każda rekurencja może być zastąpiona iteracją!
Funkcje Wyższego Rzędu (Higher-Order Functions)
Funkcje wyższego rzędu to funkcje, które:
- Przyjmują inne funkcje jako argumenty
- Zwracają funkcje jako wynik
- Lub jedno i drugie
W Pythonie funkcje są obiektami pierwszej klasy (first-class objects):
- Można je przypisywać do zmiennych
- Przekazywać jako argumenty
- Zwracać z innych funkcji
- Przechowywać w strukturach danych
Funkcje Wyższego Rzędu (Higher-Order Functions)
Najważniejsze wbudowane funkcje wyższego rzędu:
- map() - aplikuje funkcję do każdego elementu
- filter() - filtruje elementy według warunku
- reduce() - redukuje sekwencję do pojedynczej wartości
- sorted() - sortuje z własną funkcją porównania
Zastosowania:
- Programowanie funkcyjne
- Przetwarzanie danych
- Dekoratory
- Callbacks i event handlers
map() i filter() - Transformacja i Filtrowanie
# map() - aplikuje funkcję do każdego elementu
# Tradycyjny sposób
liczby = [1, 2, 3, 4, 5]
kwadraty = []
for n in liczby:
kwadraty.append(n ** 2)
# Z użyciem map()
def kwadrat(x):
return x ** 2
kwadraty = list(map(kwadrat, liczby))
print(kwadraty) # [1, 4, 9, 16, 25]
# Map z lambda
kwadraty = list(map(lambda x: x ** 2, liczby))
# Map na wiele list
a = [1, 2, 3]
b = [10, 20, 30]
sumy = list(map(lambda x, y: x + y, a, b))
print(sumy) # [11, 22, 33]
# filter() - filtruje elementy według warunku
def jest_parzysta(n):
return n % 2 == 0
parzyste = list(filter(jest_parzysta, liczby))
print(parzyste) # [2, 4]
# Filter z lambda
parzyste = list(filter(lambda x: x % 2 == 0, liczby))
# Praktyczny przykład
imiona = ["anna", "piotr", "ewa", "jan", "maria"]
dlugie = list(filter(lambda s: len(s) > 3, imiona))
print(dlugie) # ['anna', 'piotr', 'maria']reduce() i sorted() - Redukcja i Sortowanie
from functools import reduce
# reduce() - redukuje sekwencję do pojedynczej wartości
liczby = [1, 2, 3, 4, 5]
# Suma z reduce
def dodaj(a, b):
return a + b
suma = reduce(dodaj, liczby)
print(suma) # 15
# Reduce z lambda
suma = reduce(lambda a, b: a + b, liczby)
iloczyn = reduce(lambda a, b: a * b, liczby)
print(iloczyn) # 120
# Maksimum z reduce
max_wartosc = reduce(lambda a, b: a if a > b else b, liczby)
# sorted() z własną funkcją sortowania
osoby = [
{"imie": "Anna", "wiek": 25},
{"imie": "Piotr", "wiek": 30},
{"imie": "Jan", "wiek": 20}
]
# Sortowanie po wieku
sortowane = sorted(osoby, key=lambda p: p["wiek"])
print([p["imie"] for p in sortowane]) # ['Jan', 'Anna', 'Piotr']
# Sortowanie po imieniu (odwrotnie)
sortowane = sorted(osoby, key=lambda p: p["imie"], reverse=True)
# Sortowanie stringów po długości
slowa = ["python", "js", "java", "c"]
po_dlugosci = sorted(slowa, key=len)
print(po_dlugosci) # ['c', 'js', 'java', 'python']Funkcje Zwracające Funkcje - Closures
# Funkcja zwracająca funkcję (closure)
def stworz_mnoznik(n):
"""
Tworzy funkcję mnożącą przez n.
Funkcja wewnętrzna 'pamięta' wartość n.
"""
def mnoznik(x):
return x * n
return mnoznik
# Tworzenie specjalizowanych funkcji
razy_2 = stworz_mnoznik(2)
razy_10 = stworz_mnoznik(10)
print(razy_2(5)) # 10
print(razy_10(5)) # 50
# Closure z bardziej złożoną logiką
def stworz_validator(min_len, max_len):
"""Tworzy funkcję walidującą długość stringa."""
def waliduj(tekst):
return min_len >= len(tekst) <= max_len
return waliduj
waliduj_haslo = stworz_validator(8, 20)
waliduj_login = stworz_validator(3, 15)
print(waliduj_haslo("abc")) # False (za krótkie)
print(waliduj_haslo("bezpieczne123")) # True
print(waliduj_login("jan")) # True
# Praktyczny przykład: licznik
def stworz_licznik():
liczba = 0
def zwieksz():
nonlocal liczba # Modyfikacja zmiennej z outer scope
liczba += 1
return liczba
return zwieksz
licznik1 = stworz_licznik()
licznik2 = stworz_licznik()
print(licznik1()) # 1
print(licznik1()) # 2
print(licznik2()) # 1 (niezależny licznik)Dekoratory - Modyfikowanie Funkcji
# Dekorator to funkcja wyższego rzędu, która modyfikuje inną funkcję
import time
# Prosty dekorator
def timer(func):
"""Mierzy czas wykonania funkcji."""
def wrapper(*args, **kwargs):
start = time.time()
wynik = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} wykonała się w {end - start:.4f}s")
return wynik
return wrapper
# Użycie dekoratora
@timer
def wolna_funkcja():
time.sleep(1)
return "Gotowe!"
wynik = wolna_funkcja()
# wolna_funkcja wykonała się w 1.0012s
# Dekorator z logowaniem
def logger(func):
"""Loguje wywołania funkcji."""
def wrapper(*args, **kwargs):
print(f"Wywołanie: {func.__name__}({args}, {kwargs})")
wynik = func(*args, **kwargs)
print(f"Wynik: {wynik}")
return wynik
return wrapper
@logger
def dodaj(a, b):
return a + b
dodaj(3, 5)
# Wywołanie: dodaj((3, 5), {})
# Wynik: 8Dekoratory z Parametrami i Łańcuchowanie
# Dekorator z parametrami
def powtorz(n):
"""Dekorator powtarzający wykonanie funkcji n razy."""
def decorator(func):
def wrapper(*args, **kwargs):
for i in range(n):
wynik = func(*args, **kwargs)
return wynik
return wrapper
return decorator
@powtorz(3)
def przywitaj(imie):
print(f"Cześć, {imie}!")
przywitaj("Anna")
# Cześć, Anna!
# Cześć, Anna!
# Cześć, Anna!
# Łańcuchowanie dekoratorów
def uppercase(func):
def wrapper(*args, **kwargs):
wynik = func(*args, **kwargs)
return wynik.upper()
return wrapper
def wykrzyknik(func):
def wrapper(*args, **kwargs):
wynik = func(*args, **kwargs)
return wynik + "!"
return wrapper
@wykrzyknik
@uppercase
def powitanie(imie):
return f"cześć {imie}"
print(powitanie("anna")) # CZEŚĆ ANNA!
# Dekoratory są wykonywane od dołu do góry:
# 1. uppercase("cześć anna") → "CZEŚĆ ANNA"
# 2. wykrzyknik("CZEŚĆ ANNA") → "CZEŚĆ ANNA!"Praktyczne Zastosowania Funkcji Wyższego Rzędu
# Przykład 1: Przetwarzanie danych
studenci = [
{"imie": "Anna", "oceny": [4, 5, 3, 5]},
{"imie": "Piotr", "oceny": [3, 3, 4, 3]},
{"imie": "Jan", "oceny": [5, 5, 5, 4]}
]
# Oblicz średnią dla każdego studenta
srednie = list(map(
lambda s: {**s, "srednia": sum(s["oceny"]) / len(s["oceny"])},
studenci
))
# Filtruj studentów ze średnią >= 4
dobrzy = list(filter(lambda s: s["srednia"] >= 4, srednie))
# Przykład 2: Cache dekorator (memoizacja)
from functools import wraps
def cache(func):
"""Cachuje wyniki funkcji."""
cache_dict = {}
@wraps(func)
def wrapper(*args):
if args not in cache_dict:
cache_dict[args] = func(*args)
return cache_dict[args]
return wrapper
@cache
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(100)) # Bardzo szybko dzięki cache!
# Przykład 3: Walidacja z dekoratorem
def validate_positive(func):
def wrapper(x):
if x < 0:
raise ValueError("Liczba musi być dodatnia!")
return func(x)
return wrapper
@validate_positive
def pierwiastek(x):
return x ** 0.5
print(pierwiastek(16)) # 4.0
# print(pierwiastek(-1)) # ValueError!8. Praca z Plikami
Czytanie i Zapisywanie Plików Tekstowych
# Zapisywanie do pliku
with open("notatka.txt", "w", encoding="utf-8") as plik:
plik.write("Witaj, świecie!\n")
plik.write("To jest druga linia.\n")
# Czytanie całego pliku
with open("notatka.txt", "r", encoding="utf-8") as plik:
zawartosc = plik.read()
print(zawartosc)
# Czytanie linijka po linijce
with open("notatka.txt", "r", encoding="utf-8") as plik:
for linia in plik:
print(linia.strip()) # strip() usuwa \n
# Tryby otwarcia pliku:
# "r" - odczyt (read)
# "w" - zapis (write) - usuwa poprzednią zawartość!
# "a" - dopisywanie (append)
# "r+" - odczyt i zapisPraca z Plikami CSV
import csv
# Zapisywanie do CSV
dane = [
["Imię", "Nazwisko", "Wiek"],
["Jan", "Kowalski", 30],
["Anna", "Nowak", 25],
["Piotr", "Wiśniewski", 35]
]
with open("dane.csv", "w", newline="", encoding="utf-8") as plik:
writer = csv.writer(plik)
writer.writerows(dane)
# Czytanie z CSV
with open("dane.csv", "r", encoding="utf-8") as plik:
reader = csv.reader(plik)
for wiersz in reader:
print(wiersz)
# Czytanie jako słownik (DictReader)
with open("dane.csv", "r", encoding="utf-8") as plik:
reader = csv.DictReader(plik)
for wiersz in reader:
print(f"{wiersz['Imię']} ma {wiersz['Wiek']} lat")Praca z Formatem JSON
import json
# Słownik Pythona
osoba = {
"imie": "Jan",
"nazwisko": "Kowalski",
"wiek": 30,
"umiejetnosci": ["Python", "JavaScript", "SQL"]
}
# Zapisywanie do pliku JSON
with open("osoba.json", "w", encoding="utf-8") as plik:
json.dump(osoba, plik, indent=2, ensure_ascii=False)
# Czytanie z pliku JSON
with open("osoba.json", "r", encoding="utf-8") as plik:
dane = json.load(plik)
print(dane["imie"])
# Konwersja do/z stringa JSON
json_string = json.dumps(osoba, indent=2)
z_powrotem = json.loads(json_string)
# JSON to świetny format do przechowywania konfiguracji
# i wymiany danych między aplikacjami!9. Kodowanie Znaków - ASCII i UTF-8
Czym jest kodowanie znaków?
Kodowanie to sposób reprezentowania tekstu jako liczb w pamięci komputera.
ASCII (American Standard Code for Information Interchange):
- Stary standard (1963)
- Tylko 128 znaków (0-127)
- Zawiera: angielskie litery, cyfry, podstawowe znaki
- NIE obsługuje polskich znaków: ą, ę, ł, ź, ż, ć, ń, ś
- Zajmuje 1 bajt (8 bitów)
9. Kodowanie Znaków - ASCII i UTF-8
Czym jest kodowanie znaków?
UTF-8 (Unicode Transformation Format - 8 bit):
- Nowoczesny standard
- Obsługuje ponad 1 milion znaków!
- Zawiera wszystkie języki świata (polski, chiński, arabski, emoji)
- Kompatybilny wstecz z ASCII
- Zajmuje 1-4 bajty (zależnie od znaku)
Podstawy Kodowania w Pythonie
# String w Pythonie to Unicode (UTF-8)
tekst = "Witaj, świecie! ąęłźżćńś"
# Zamiana string na bajty (encode)
bajty_utf8 = tekst.encode('utf-8')
print(bajty_utf8)
# b'Witaj, \xc5\x9bwiecie! \xc4\x85\xc4\x99\xc5\x82...'
# Zamiana bajtów na string (decode)
z_powrotem = bajty_utf8.decode('utf-8')
print(z_powrotem) # Witaj, świecie! ąęłźżćńś
# ASCII - nie obsługuje polskich znaków!
try:
bajty_ascii = tekst.encode('ascii')
except UnicodeEncodeError as e:
print(f"Błąd: {e}")
# Błąd: 'ascii' codec can't encode character '\u015b' in position 6
# Zamiana z ignorowaniem błędów
ascii_ignore = tekst.encode('ascii', errors='ignore')
print(ascii_ignore) # b'Witaj, wiecie! '
# Zamiana z zastępowaniem znaków
ascii_replace = tekst.encode('ascii', errors='replace')
print(ascii_replace) # b'Witaj, ?wiecie! ????????'Konwersja między Kodowaniami
# Usuwanie polskich znaków (transliteracja)
import unicodedata
def usun_polskie_znaki(tekst):
"""
Zamienia polskie znaki na ich ASCII odpowiedniki.
ą -> a, ę -> e, ł -> l, etc.
"""
# Normalizacja NFD rozdziela znaki z akcentami
nfd = unicodedata.normalize('NFD', tekst)
# Filtrowanie tylko znaków ASCII
return ''.join(char for char in nfd
if unicodedata.category(char) != 'Mn')
tekst = "Zażółć gęślą jaźń"
ascii_tekst = usun_polskie_znaki(tekst)
print(ascii_tekst) # Zazolc gesla jazn
# Ręczna mapa transliteracji (lepsze dla polskiego)
POLSKIE_NA_ASCII = {
'ą': 'a', 'ć': 'c', 'ę': 'e', 'ł': 'l',
'ń': 'n', 'ó': 'o', 'ś': 's', 'ź': 'z', 'ż': 'z',
'Ą': 'A', 'Ć': 'C', 'Ę': 'E', 'Ł': 'L',
'Ń': 'N', 'Ó': 'O', 'Ś': 'S', 'Ź': 'Z', 'Ż': 'Z'
}
def zamien_polskie(tekst):
for pl, en in POLSKIE_NA_ASCII.items():
tekst = tekst.replace(pl, en)
return tekst
print(zamien_polskie("Zażółć gęślą jaźń")) # Zazolc gesla jaznPraca z Plikami - Kodowanie
# ZAWSZE określaj kodowanie przy pracy z plikami!
# Zapis z UTF-8 (polskie znaki)
tekst = "Zażółć gęślą jaźń"
with open("polski.txt", "w", encoding="utf-8") as f:
f.write(tekst)
# Odczyt z UTF-8
with open("polski.txt", "r", encoding="utf-8") as f:
odczytany = f.read()
print(odczytany) # Zażółć gęślą jaźń
# Odczyt z błędnym kodowaniem
try:
with open("polski.txt", "r", encoding="ascii") as f:
print(f.read())
except UnicodeDecodeError as e:
print(f"Błąd dekodowania: {e}")
# Automatyczne wykrywanie kodowania (biblioteka chardet)
# pip install chardet
import chardet
with open("polski.txt", "rb") as f:
raw_data = f.read()
result = chardet.detect(raw_data)
print(f"Wykryte kodowanie: {result['encoding']}") # utf-8
print(f"Pewność: {result['confidence']}") # 0.99
# Odczyt z wykrytym kodowaniem
tekst_decoded = raw_data.decode(result['encoding'])
print(tekst_decoded)Kody Znaków i Operacje Unicode
# Pobieranie kodu znaku (kod Unicode)
print(ord('A')) # 65
print(ord('a')) # 97
print(ord('ą')) # 261
print(ord('😀')) # 128512
# Tworzenie znaku z kodu
print(chr(65)) # A
print(chr(97)) # a
print(chr(261)) # ą
print(chr(128512)) # 😀
# Escape sequences dla Unicode
print("\u0105") # ą (4-cyfrowy hex)
print("\U0001F600") # 😀 (8-cyfrowy hex)
# Nazwa znaku Unicode
import unicodedata
print(unicodedata.name('ą')) # LATIN SMALL LETTER A WITH OGONEK
print(unicodedata.name('😀')) # GRINNING FACE
# Lista wszystkich polskich znaków
polskie_znaki = 'ąćęłńóśźżĄĆĘŁŃÓŚŹŻ'
for znak in polskie_znaki:
print(f"{znak}: {ord(znak)} - {unicodedata.name(znak)}")
# Sprawdzanie kategorii znaku
print(unicodedata.category('A')) # Lu (Letter, uppercase)
print(unicodedata.category('a')) # Ll (Letter, lowercase)
print(unicodedata.category('5')) # Nd (Number, decimal digit)
print(unicodedata.category(' ')) # Zs (Separator, space)Praktyczne Zastosowania
# 1. Tworzenie przyjaznych URL (slug)
def create_slug(text):
"""Tworzy URL-friendly slug z polskiego tekstu."""
import re
# Zamiana na małe litery
text = text.lower()
# Usunięcie polskich znaków
polish_chars = {'ą':'a','ć':'c','ę':'e','ł':'l','ń':'n',
'ó':'o','ś':'s','ź':'z','ż':'z'}
for pl, en in polish_chars.items():
text = text.replace(pl, en)
# Zamiana spacji i znaków specjalnych na '-'
text = re.sub(r'[^a-z0-9]+', '-', text)
text = text.strip('-')
return text
print(create_slug("Zażółć gęślą jaźń")) # zazolc-gesla-jazn
print(create_slug("Python dla Początkujących!")) # python-dla-poczatkujacych
# 2. Walidacja formularza (tylko ASCII)
def is_ascii_only(text):
"""Sprawdza czy tekst zawiera tylko znaki ASCII."""
try:
text.encode('ascii')
return True
except UnicodeEncodeError:
return False
print(is_ascii_only("Hello World")) # True
print(is_ascii_only("Cześć")) # False
# 3. Liczenie bajtów vs znaków
tekst = "Zażółć"
print(f"Znaków: {len(tekst)}") # 6
print(f"Bajtów UTF-8: {len(tekst.encode('utf-8'))}") # 11
print(f"Bajtów ASCII: niemożliwe!")Najczęstsze Problemy i Rozwiązania
Problem 1: 'UnicodeDecodeError' przy czytaniu pliku
Rozwiązanie: Użyj encoding='utf-8' lub wykryj kodowanie automatycznie
Problem 2: Polskie znaki wyświetlają się jako '?' lub krzaczki
Rozwiązanie: Upewnij się, że terminal/edytor używa UTF-8
Problem 3: ASCII nie obsługuje emoji i polskich znaków
Rozwiązanie: Zawsze używaj UTF-8 dla międzynarodowego tekstu
Problem 4: Różna długość w bajtach i znakach
Rozwiązanie: len() zwraca znaki, len(text.encode()) zwraca bajty
Najczęstsze Problemy i Rozwiązania
Dobre praktyki:
- Zawsze używaj encoding='utf-8' przy open()
- Przechowuj tekst jako stringi (Unicode), nie bajty
- Konwertuj na bajty tylko przy zapisie do pliku/sieci
- Testuj kod z polskimi znakami i emoji
- Dokumentuj oczekiwane kodowanie w komentarzach
Pamiętaj: Python 3 domyślnie używa Unicode (UTF-8)!
10. Wyrażenia Regularne (Regular Expressions)
Wyrażenia regularne (regex) to wzorce używane do wyszukiwania i manipulowania tekstem.
Zastosowania:
- Walidacja danych (email, telefon, kod pocztowy)
- Wyszukiwanie wzorców w tekście
- Zamiana i czyszczenie danych
- Ekstrakcja informacji (URL, daty, numery)
- Parsowanie logów i plików
Moduł re w Pythonie:
- re.search() - szuka pierwszego dopasowania
- re.match() - sprawdza początek stringa
- re.findall() - znajduje wszystkie dopasowania
- re.sub() - zamienia dopasowania
- re.split() - dzieli string
Podstawowe znaki specjalne:
- . - dowolny znak (oprócz \n)
- ^ - początek stringa
- $ - koniec stringa
- * - 0 lub więcej powtórzeń
- + - 1 lub więcej powtórzeń
- ? - 0 lub 1 wystąpienie
- [] - zestaw znaków
- () - grupa
- | - lub (alternatywa)
Podstawy Regex - Pierwsze Kroki
import re
# Podstawowe wyszukiwanie
tekst = "Python jest super! Python to świetny język."
# search() - znajduje pierwsze dopasowanie
wynik = re.search(r"Python", tekst)
if wynik:
print("Znaleziono:", wynik.group()) # Python
print("Pozycja:", wynik.start()) # 0
# findall() - znajduje wszystkie dopasowania
wszystkie = re.findall(r"Python", tekst)
print(wszystkie) # ['Python', 'Python']
# match() - sprawdza początek stringa
if re.match(r"Python", tekst):
print("String zaczyna się od 'Python'")
# split() - dzieli string wzorcem
zdania = re.split(r"[.!?]", tekst)
print(zdania) # ['Python jest super', ' Python to świetny język', '']
# sub() - zamienia wzorzec
nowy = re.sub(r"Python", "Java", tekst)
print(nowy) # Java jest super! Java to świetny język.Wzorce i Klasy Znaków
import re
# Klasy znaków
tekst = "Rok 2024, tel: 123-456-789, email: jan@example.com"
# \d - cyfra (digit), \D - nie-cyfra
cyfry = re.findall(r"\d+", tekst)
print(cyfry) # ['2024', '123', '456', '789']
# \w - znak słowa (litera, cyfra, _), \W - nie-znak-słowa
slowa = re.findall(r"\w+", tekst)
print(slowa) # ['Rok', '2024', 'tel', '123', '456', '789', 'email', 'jan', 'example', 'com']
# \s - biały znak (spacja, tab, \n), \S - nie-biały-znak
bez_spacji = re.findall(r"\S+", tekst)
print(bez_spacji)
# [] - własny zestaw znaków
samogloski = re.findall(r"[aeiouąę]", tekst.lower())
print(samogloski)
# [^] - negacja zestwu
nie_cyfry = re.findall(r"[^0-9]+", tekst)
print(nie_cyfry)
# . - dowolny znak
wzor = re.findall(r"t.l", tekst) # tel
print(wzor)Kwantyfikatory - Ilość Powtórzeń
import re
# Kwantyfikatory określają ilość powtórzeń
# * - 0 lub więcej
print(re.findall(r"ab*", "a ab abb abbb")) # ['a', 'ab', 'abb', 'abbb']
# + - 1 lub więcej
print(re.findall(r"ab+", "a ab abb abbb")) # ['ab', 'abb', 'abbb']
# ? - 0 lub 1 (opcjonalny)
print(re.findall(r"colou?r", "color colour")) # ['color', 'colour']
# {n} - dokładnie n razy
print(re.findall(r"\d{4}", "2024 123 56789")) # ['2024', '5678']
# {n,m} - od n do m razy
print(re.findall(r"\d{2,4}", "1 12 123 1234 12345"))
# ['12', '123', '1234', '1234']
# {n,} - n lub więcej razy
print(re.findall(r"a{2,}", "a aa aaa aaaa")) # ['aa', 'aaa', 'aaaa']
# Zachłanne vs lenliwe
tekst = "<div>Hello</div><div>World</div>"
zachlanne = re.findall(r"<div>.*</div>", tekst)
print(zachlanne) # ['<div>Hello</div><div>World</div>']
lenliwe = re.findall(r"<div>.*?</div>", tekst)
print(lenliwe) # ['<div>Hello</div>', '<div>World</div>']Grupy i Przechwytywanie
import re
# () - grupy przechwytujące
tekst = "Jan Kowalski, email: jan@example.com, tel: 123-456-789"
# Pojedyncza grupa
wynik = re.search(r"email: (\S+)", tekst)
if wynik:
print(wynik.group(0)) # email: jan@example.com (cały match)
print(wynik.group(1)) # jan@example.com (grupa 1)
# Wiele grup
wzor = r"(\w+)@(\w+)\.(\w+)"
email = re.search(wzor, tekst)
if email:
print(email.group(0)) # jan@example.com
print(email.group(1)) # jan
print(email.group(2)) # example
print(email.group(3)) # com
# Nazwane grupy (?P)
wzor = r"(?P\w+)@(?P\w+\.\w+)"
match = re.search(wzor, tekst)
if match:
print(match.group('user')) # jan
print(match.group('domain')) # example.com
# Grupy nieprzechwytujące (?:)
wzor = r"(?:Mr|Mrs|Ms)\.? (\w+)"
tekst2 = "Mr. Smith and Mrs. Johnson"
print(re.findall(wzor, tekst2)) # ['Smith', 'Johnson']Walidacja Danych - Praktyczne Wzorce
import re
# Walidacja email
def waliduj_email(email):
wzor = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
return bool(re.match(wzor, email))
print(waliduj_email("jan@example.com")) # True
print(waliduj_email("niepoprawny.email")) # False
# Walidacja numeru telefonu (format: XXX-XXX-XXX)
def waliduj_telefon(tel):
wzor = r"^\d{3}-\d{3}-\d{3}$"
return bool(re.match(wzor, tel))
print(waliduj_telefon("123-456-789")) # True
print(waliduj_telefon("12-345-6789")) # False
# Walidacja kodu pocztowego (XX-XXX)
def waliduj_kod_pocztowy(kod):
wzor = r"^\d{2}-\d{3}$"
return bool(re.match(wzor, kod))
print(waliduj_kod_pocztowy("00-950")) # True
print(waliduj_kod_pocztowy("1234")) # False
# Walidacja hasła (min 8 znaków, litera i cyfra)
def waliduj_haslo(haslo):
if len(haslo) < 8:
return False
ma_litere = bool(re.search(r"[a-zA-Z]", haslo))
ma_cyfre = bool(re.search(r"\d", haslo))
return ma_litere and ma_cyfre
print(waliduj_haslo("Haslo123")) # True
print(waliduj_haslo("haslo")) # FalseEkstrakcja Danych z Tekstu
import re
tekst = """
Kontakt:
Jan Kowalski - jan@example.com - 123-456-789
Anna Nowak - anna.nowak@test.pl - 987-654-321
Strona: https://example.com
Cena: 1299.99 PLN
Data: 2024-10-26
"""
# Ekstrakcja adresów email
emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", tekst)
print("Emaile:", emails)
# Ekstrakcja numerów telefonów
telefony = re.findall(r"\d{3}-\d{3}-\d{3}", tekst)
print("Telefony:", telefony)
# Ekstrakcja URL
urls = re.findall(r"https?://[^\s]+", tekst)
print("URL:", urls)
# Ekstrakcja cen (liczby zmiennoprzecinkowe)
ceny = re.findall(r"\d+\.\d{2}", tekst)
print("Ceny:", ceny)
# Ekstrakcja dat (format YYYY-MM-DD)
daty = re.findall(r"\d{4}-\d{2}-\d{2}", tekst)
print("Daty:", daty)
# Ekstrakcja imion i nazwisk z emailami
wzor = r"(\w+ \w+) - ([\w.]+@[\w.]+)"
osoby = re.findall(wzor, tekst)
for imie_nazwisko, email in osoby:
print(f"{imie_nazwisko}: {email}")Zaawansowane Techniki i Flagi
import re
# Flagi modyfikujące zachowanie regex
# re.IGNORECASE (re.I) - ignoruje wielkość liter
tekst = "Python python PYTHON"
print(re.findall(r"python", tekst, re.IGNORECASE))
# ['Python', 'python', 'PYTHON']
# re.MULTILINE (re.M) - ^ i $ dla każdej linii
tekst_wieloliniowy = """pierwsza linia
druga linia
trzecia linia"""
print(re.findall(r"^\w+", tekst_wieloliniowy, re.MULTILINE))
# ['pierwsza', 'druga', 'trzecia']
# re.DOTALL (re.S) - . dopasowuje też \n
html = "<div>\nHello\n</div>"
print(re.findall(r"<div>.*</div>", html, re.DOTALL))
# ['<div>\nHello\n</div>']
# Lookahead i Lookbehind
tekst = "Price: 100 USD, 200 EUR, 300 PLN"
# Positive lookahead (?=)
usd = re.findall(r"\d+(?= USD)", tekst)
print(usd) # ['100']
# Negative lookahead (?!)
nie_usd = re.findall(r"\d+(?! USD)", tekst)
print(nie_usd) # ['0', '200', '300']
# Positive lookbehind (?<=)
po_price = re.findall(r"(?<=Price: )\d+", tekst)
print(po_price) # ['100']Praktyczne Zastosowania i Wskazówki
PRAKTYCZNE PRZYKŁADY:
- Czyszczenie danych
- Usuwanie zbędnych spacji: re.sub(r'\s+', ' ', tekst)
- Usuwanie znaków specjalnych: re.sub(r'[^a-zA-Z0-9]', '', tekst)
- Maskowanie danych wrażliwych
- Maskowanie numeru karty: re.sub(r'\d{4}', '****', numer)
- Ukrywanie części email: re.sub(r'(\w{2})\w+@', r'\1***@', email)
- Parsowanie logów
- Ekstrakcja IP: r'\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}'
- Znaczniki czasu: r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}'
Praktyczne Zastosowania i Wskazówki
WSKAZÓWKI:
- Używaj r'' (raw strings) dla wzorców regex
- Kompiluj często używane wzorce: pattern = re.compile(r'...')
- Testuj regex online: regex101.com, regexr.com
- Unikaj nadmiernej zachłanności - używaj ? gdy potrzeba
- Grupuj dla czytelności: (?P<nazwa>wzor)
CZĘSTE BŁĘDY:
- Zapominanie o escape'owaniu znaków specjalnych: \., \?, \+
- Użycie . zamiast \. dla kropki literalnej
- Zachłanne dopasowania gdy potrzeba leniwe (.*? zamiast .*)
- Brak ^ i $ przy walidacji (pozwala na częściowe dopasowania)
Pamiętaj: Regex to potężne narzędzie, ale nie nadużywaj go! Dla prostych operacji użyj str.find(), str.replace(), str.split()
11. Programowanie Obiektowe (OOP)
Klasy i Obiekty - Wprowadzenie
# Definicja klasy
class Samochod:
def __init__(self, marka, model, rok):
self.marka = marka # Atrybut
self.model = model
self.rok = rok
self.przebieg = 0
# Metoda
def jedz(self, kilometry):
self.przebieg += kilometry
print(f"Pojechałeś {kilometry} km")
def informacje(self):
return f"{self.marka} {self.model} ({self.rok}), przebieg: {self.przebieg} km"
# Tworzenie obiektów (instancji)
auto1 = Samochod("Toyota", "Corolla", 2020)
auto2 = Samochod("BMW", "X5", 2022)
# Wywoływanie metod
auto1.jedz(150)
print(auto1.informacje()) # Toyota Corolla (2020), przebieg: 150 kmAtrybuty Klasy vs Instancji
class Produkt:
# Atrybut klasy - wspólny dla wszystkich obiektów
vat = 0.23
licznik_produktow = 0
def __init__(self, nazwa, cena_netto):
# Atrybuty instancji - unikalne dla każdego obiektu
self.nazwa = nazwa
self.cena_netto = cena_netto
Produkt.licznik_produktow += 1
def cena_brutto(self):
return self.cena_netto * (1 + Produkt.vat)
@classmethod
def zmien_vat(cls, nowy_vat):
cls.vat = nowy_vat
@staticmethod
def czy_drogie(cena):
return cena > 1000
# Użycie
laptop = Produkt("Laptop", 3000)
mysz = Produkt("Mysz", 50)
print(laptop.cena_brutto()) # 3690.0
print(Produkt.licznik_produktow) # 2
Produkt.zmien_vat(0.08) # Zmienia VAT dla wszystkich
print(Produkt.czy_drogie(1500)) # TrueDziedziczenie - Rozszerzanie Klas
# Klasa bazowa (rodzic)
class Zwierze:
def __init__(self, imie):
self.imie = imie
def wydaj_dzwiek(self):
return "..."
def przedstaw_sie(self):
return f"Jestem {self.imie}, mówię: {self.wydaj_dzwiek()}"
# Klasy pochodne (dzieci) dziedziczą po Zwierze
class Pies(Zwierze):
def wydaj_dzwiek(self):
return "Hau hau!"
def aportuj(self):
return f"{self.imie} aportuje piłkę"
class Kot(Zwierze):
def wydaj_dzwiek(self):
return "Miau!"
# Użycie
burek = Pies("Burek")
filemon = Kot("Filemon")
print(burek.przedstaw_sie()) # Jestem Burek, mówię: Hau hau!
print(filemon.przedstaw_sie()) # Jestem Filemon, mówię: Miau!
print(burek.aportuj()) # Burek aportuje piłkęEnkapsulacja i Metody Specjalne
class KontoBankowe:
def __init__(self, wlasciciel, saldo=0):
self.wlasciciel = wlasciciel
self.__saldo = saldo # __ oznacza atrybut prywatny
def wplata(self, kwota):
if kwota > 0:
self.__saldo += kwota
return True
return False
def wyplata(self, kwota):
if 0 < kwota <= self.__saldo:
self.__saldo -= kwota
return True
return False
def sprawdz_saldo(self):
return self.__saldo
# Metody specjalne (dunder methods)
def __str__(self):
return f"Konto: {self.wlasciciel}, saldo: {self.__saldo} PLN"
def __repr__(self):
return f"KontoBankowe('{self.wlasciciel}', {self.__saldo})"
konto = KontoBankowe("Jan Kowalski", 1000)
konto.wplata(500)
print(konto) # Konto: Jan Kowalski, saldo: 1500 PLN
# print(konto.__saldo) # AttributeError - atrybut prywatny!12. List Comprehensions i Wyrażenia Generatorowe
List Comprehensions - Eleganckie Tworzenie List
# Tradycyjny sposób
kwadraty = []
for i in range(10):
kwadraty.append(i ** 2)
# List comprehension - krótsza wersja!
kwadraty = [i ** 2 for i in range(10)]
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# Z warunkiem (filtrowanie)
parzyste = [i for i in range(20) if i % 2 == 0]
# [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
# Operacje na stringach
owoce = ["jabłko", "banan", "gruszka"]
wielkie = [owoc.upper() for owoc in owoce]
# ['JABŁKO', 'BANAN', 'GRUSZKA']
# Z if-else
liczby = [1, 2, 3, 4, 5]
kategorie = ["parzysta" if n % 2 == 0 else "nieparzysta" for n in liczby]
# Zagnieżdżone comprehensions (2D)
macierz = [[i * j for j in range(3)] for i in range(3)]
# [[0, 0, 0], [0, 1, 2], [0, 2, 4]]Dictionary i Set Comprehensions
# Dictionary comprehension
kwadraty_dict = {i: i**2 for i in range(6)}
# {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# Z dwóch list
imiona = ["Anna", "Jan", "Piotr"]
wieki = [25, 30, 35]
osoby = {imie: wiek for imie, wiek in zip(imiona, wieki)}
# {'Anna': 25, 'Jan': 30, 'Piotr': 35}
# Zamiana kluczy i wartości
odwrocone = {v: k for k, v in osoby.items()}
# {25: 'Anna', 30: 'Jan', 35: 'Piotr'}
# Set comprehension
liczby = [1, 2, 2, 3, 3, 3, 4, 5]
unikalne_kwadraty = {x**2 for x in liczby}
# {1, 4, 9, 16, 25}
# Praktyczny przykład: filtrowanie słownika
produkty = {"jabłko": 2.5, "banan": 3.0, "gruszka": 4.5}
drogie = {k: v for k, v in produkty.items() if v > 3}
# {'banan': 3.0, 'gruszka': 4.5}Generator Expressions - Wydajność Pamięci
# List comprehension - tworzy całą listę w pamięci
lista = [i**2 for i in range(1000000)] # Zajmuje dużo pamięci!
# Generator expression - generuje elementy na żądanie
generator = (i**2 for i in range(1000000)) # Prawie nie zajmuje pamięci!
# Użycie generatora
for kwadrat in generator:
if kwadrat > 100:
break
# Generatory są jednorazowe!
suma = sum(i**2 for i in range(100)) # Generator jako argument
# Praktyczny przykład: czytanie dużych plików
# ŹLE: czyta cały plik do pamięci
with open("duzy_plik.txt") as f:
linie = [linia.strip() for linia in f]
# DOBRZE: przetwarza linijka po linijce
with open("duzy_plik.txt") as f:
for linia in (l.strip() for l in f):
# Przetwarzaj linię
pass
# Kiedy używać generatorów?
# - Duże zbiory danych
# - Nie potrzebujesz całej listy od razu
# - Oszczędzasz pamięć13. Popularne Biblioteki Standardowe
Moduł datetime - Praca z Datą i Czasem
from datetime import datetime, date, time, timedelta
# Aktualna data i czas
teraz = datetime.now()
print(teraz) # 2024-10-26 14:30:45.123456
# Tworzenie własnych dat
data_urodzenia = date(1990, 5, 15)
godzina = time(14, 30, 0)
# Formatowanie dat
dzis = date.today()
print(dzis.strftime("%d/%m/%Y")) # 26/10/2024
print(dzis.strftime("%A, %d %B %Y")) # Sobota, 26 październik 2024
# Parsowanie stringów na daty
data_str = "2024-10-26"
data = datetime.strptime(data_str, "%Y-%m-%d")
# Operacje na datach
za_tydzien = dzis + timedelta(days=7)
wczoraj = dzis - timedelta(days=1)
za_2_godziny = datetime.now() + timedelta(hours=2)
# Obliczanie wieku
wiek = dzis.year - data_urodzenia.yearModuł random - Liczby Losowe
import random
# Losowa liczba zmiennoprzecinkowa z zakresu [0.0, 1.0)
losowa = random.random()
# Losowa liczba całkowita
kostka = random.randint(1, 6) # Rzut kostką
los = random.randrange(0, 100, 5) # Co 5: 0, 5, 10, ..., 95
# Losowy wybór z listy
kolory = ["czerwony", "niebieski", "zielony", "żółty"]
wybrany = random.choice(kolory)
# Losowe próbkowanie (bez powtórzeń)
losowe_3 = random.sample(kolory, 3)
# Tasowanie listy
karty = list(range(1, 53))
random.shuffle(karty) # Zmienia listę w miejscu
# Losowa liczba z rozkładu normalnego
wzrost = random.gauss(170, 10) # średnia=170, odch.std=10
# Ustawianie ziarna (seed) dla powtarzalności
random.seed(42)
print(random.randint(1, 100)) # Zawsze ten sam wynik!Moduły os i pathlib - Operacje Systemowe
import os
from pathlib import Path
# Aktualna ścieżka
obecny_katalog = os.getcwd()
print(obecny_katalog)
# Tworzenie katalogów
os.makedirs("projekty/python/skrypty", exist_ok=True)
# Listowanie plików
pliki = os.listdir(".")
for plik in pliki:
print(plik)
# Sprawdzanie istnienia
if os.path.exists("plik.txt"):
print("Plik istnieje!")
# pathlib - nowoczesny sposób (Python 3.4+)
sciezka = Path("projekty/python/skrypty")
sciezka.mkdir(parents=True, exist_ok=True)
# Operacje na ścieżkach
plik = Path("dane/input.txt")
print(plik.name) # input.txt
print(plik.stem) # input
print(plik.suffix) # .txt
print(plik.parent) # dane
# Iteracja przez pliki
for plik in Path(".").glob("*.py"):
print(f"Znaleziono: {plik}")14. Praktyczne Projekty - Zastosowanie Wiedzy
import random
import string
def generuj_haslo(dlugosc=12, wielkie=True, cyfry=True, znaki=True):
"""
Generuje losowe hasło o zadanej długości.
"""
znaki_do_wyboru = string.ascii_lowercase
if wielkie:
znaki_do_wyboru += string.ascii_uppercase
if cyfry:
znaki_do_wyboru += string.digits
if znaki:
znaki_do_wyboru += "!@#$%^&*"
haslo = ''.join(random.choice(znaki_do_wyboru) for _ in range(dlugosc))
return haslo
# Użycie
for _ in range(3):
print(generuj_haslo(16))
# Przykładowe hasła:
# aB7$mK2@pL9#qR5!
# x3Y&nZ8*wV1%tU6@
# dF4!gH9#jK2$mN7&Projekt 2: Lista Zadań (To-Do List)
class ListaZadan:
def __init__(self):
self.zadania = []
def dodaj(self, zadanie):
self.zadania.append({"tekst": zadanie, "wykonane": False})
print(f"✓ Dodano: {zadanie}")
def pokaz(self):
if not self.zadania:
print("Lista zadań jest pusta!")
return
for i, zadanie in enumerate(self.zadania, 1):
status = "✓" if zadanie["wykonane"] else "○"
print(f"{i}. [{status}] {zadanie['tekst']}")
def wykonaj(self, numer):
if 1 <= numer <= len(self.zadania):
self.zadania[numer-1]["wykonane"] = True
print(f"✓ Wykonano zadanie {numer}")
def usun(self, numer):
if 1 <= numer <= len(self.zadania):
zadanie = self.zadania.pop(numer-1)
print(f"Usunięto: {zadanie['tekst']}")
# Użycie
todo = ListaZadan()
todo.dodaj("Nauczyć się Pythona")
todo.dodaj("Zrobić projekt")
todo.pokaz()
todo.wykonaj(1)Projekt 3: Analiza Pliku Tekstowego
def analizuj_tekst(sciezka_pliku):
"""
Analizuje plik tekstowy i zwraca statystyki.
"""
with open(sciezka_pliku, 'r', encoding='utf-8') as plik:
tekst = plik.read()
# Podstawowe statystyki
liczba_znakow = len(tekst)
liczba_slow = len(tekst.split())
liczba_linii = tekst.count('\n') + 1
# Najczęstsze słowa
slowa = tekst.lower().split()
from collections import Counter
najczestsze = Counter(slowa).most_common(5)
# Wyniki
print(f"Analiza pliku: {sciezka_pliku}")
print(f"Znaków: {liczba_znakow:,}")
print(f"Słów: {liczba_slow:,}")
print(f"Linii: {liczba_linii:,}")
print(f"\nNajczęstsze słowa:")
for slowo, ilosc in najczestsze:
print(f" '{slowo}': {ilosc} razy")
# Użycie
analizuj_tekst("przyklad.txt")Projekt 4: Kalkulator BMI z Klasami
class Osoba:
def __init__(self, imie, waga_kg, wzrost_m):
self.imie = imie
self.waga = waga_kg
self.wzrost = wzrost_m
def oblicz_bmi(self):
return self.waga / (self.wzrost ** 2)
def kategoria_bmi(self):
bmi = self.oblicz_bmi()
if bmi < 18.5:
return "niedowaga"
elif bmi < 25:
return "waga prawidłowa"
elif bmi < 30:
return "nadwaga"
else:
return "otyłość"
def raport(self):
bmi = self.oblicz_bmi()
kategoria = self.kategoria_bmi()
return f"""
Raport BMI dla: {self.imie}
Waga: {self.waga} kg
Wzrost: {self.wzrost} m
BMI: {bmi:.2f}
Kategoria: {kategoria}
"""
# Użycie
osoba = Osoba("Jan Kowalski", 75, 1.80)
print(osoba.raport())Ćwiczenia Praktyczne - Co Dalej?
Pomysły na własne projekty: 1. Gra w "Zgadnij liczbę" - Użyj random.randint() - Pętle while i input() - Warunki if/elif/else 2. Konwerter jednostek - Funkcje do konwersji (km↔mile, kg↔funty) - Słownik z przelicznikami - Obsługa błędów try/except 3. Dziennik wydatków - Zapisywanie do pliku CSV - Sumowanie kategorii - Analiza miesięczna 4. Quiz wiedzy - Lista słowników z pytaniami - Losowa kolejność pytań - Licznik punktów 5. Prosty sklep internetowy - Klasy: Produkt, Koszyk - Metody: dodaj_do_koszyka, oblicz_total - Zapis zamówienia do JSON Pamiętaj: najlepiej uczyć się przez praktykę! 🚀
Podsumowanie
Czego się nauczyliśmy:
✓ Przygotowanie środowiska Pythona ✓ Zmienne, typy danych i operacje ✓ Struktury kontrolne (if, for, while) ✓ Kolekcje danych (listy, słowniki, zbiory, krotki) ✓ Unpacking - rozpakowywanie (*args, **kwargs) ✓ Obsługa błędów i debugowanie ✓ Funkcje: modularyzacja, rekurencja, HOF, dekoratory ✓ Praca z plikami (TXT, CSV, JSON) ✓ Kodowanie znaków (ASCII, UTF-8, Unicode) ✓ Wyrażenia regularne (regex, walidacja, ekstrakcja) ✓ Programowanie obiektowe (klasy, dziedziczenie) ✓ List comprehensions i generatory ✓ Popularne biblioteki (datetime, random, os/pathlib) ✓ Praktyczne projekty i ćwiczenia "The best way to learn Python is to use Python!" - Community Wisdom Dziękuję za uwagę! Czas na praktykę! 🐍
Python - SWPS
By noinputsignal

