XPath
Krzysztof "noisy" Szumny
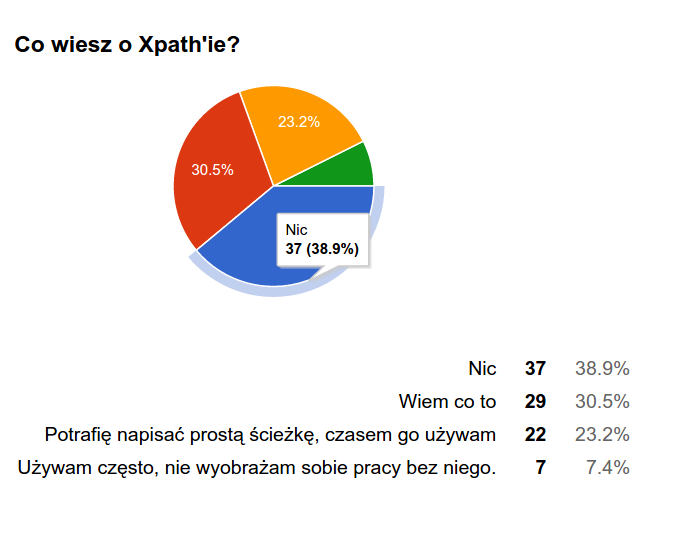
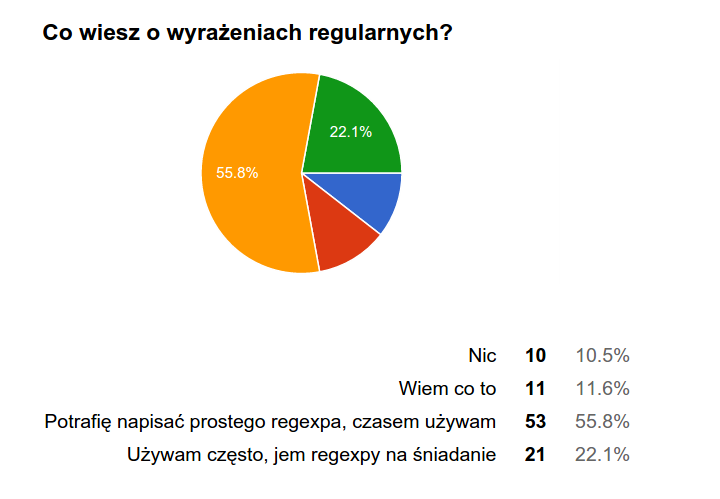
source: http://www.wykop.pl/wpis/13367209/, #programowanie
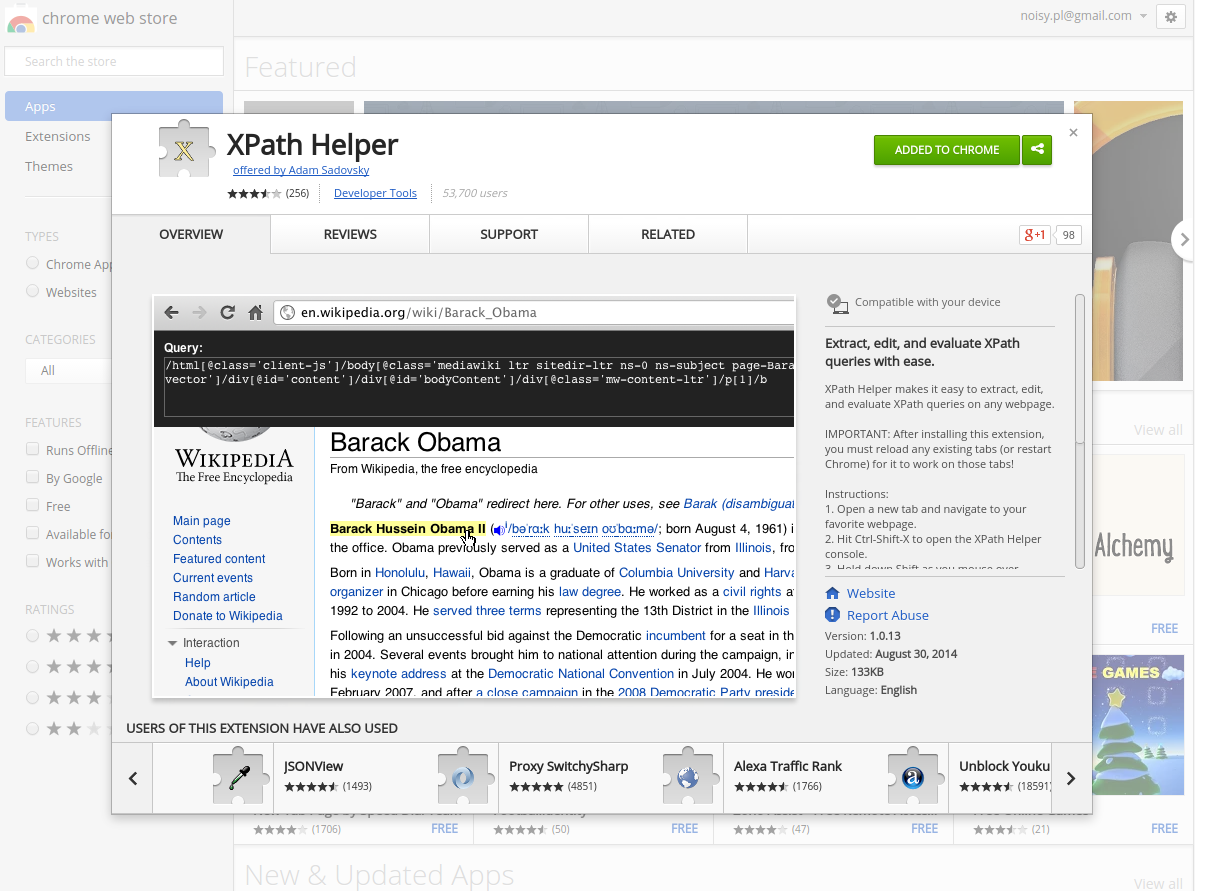
Quick demo
# Title of repositories
//*[@id="site-container"]/div/div/div[2]/div[2]/div/ul/li/h3/a
# Information whether repository was forked
//*[@id="site-container"]/div/div/div[2]/div[2]/div/ul/li/p[@class='repo-list-info']
# filtering by forked repositories
//*[@id="site-container"]/div/div/div[2]/div[2]/div/ul/li[p[@class='repo-list-info']]/h3/a
# filtering by not forked repositories
//*[@id="site-container"]/div/div/div[2]/div[2]/div/ul/li[not(p[@class='repo-list-info'])]/h3/aHTML, Xpath and Python
import urllib2
from lxml import etree
from lxml.etree import tostring
url = "https://github.com/noisy?tab=repositories"
response = urllib2.urlopen(url)
tree = etree.parse(response, etree.HTMLParser())
xpath_selector1 = '//div/ul/li/h3/a'
xpath_selector2 = '//div/ul/li/p[@class="repo-list-info"]'
xpath_selector3 = '//div/ul/li[p[@class="repo-list-info"]]/h3/a'
xpath_selector4 = '//div/ul/li[not(p[@class="repo-list-info"])]/h3/a'
elements = tree.xpath(xpath_selector4)
for elem in elements:
# print tostring(elem)
print elem.textCase Study - parsing XMLs
<offers xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="1">
<group name="books">
<o id="28" price="34.58" url="https://bookstore2.pl/44334002/33">
<name>Czeski underground></name>
<desc></desc>
<cat>Księgarnia/Książki/Pozostałe książki></cat>
<imgs>
<main url="http://bookstore2.pl/gfx2/logo.jpg"/>
</imgs>
<attrs>
<a name="Autor">Martin Machovec></a>
<a name="ISBN">9788374323581</a>
<a name="Ilosc_stron">408</a>
<a name="Wydawnictwo">Oficyna Wydawnicza Atut</a>
<a name="Rok_wydania">2008</a>
</attrs>
</o>
</group>
</offers>
from spistresci.connectors.common import Ceneo
class Bookstore2(Ceneo):
xml_tag_dict = {
'external_id': "@id",
'price': "@price",
'url': "@url",
'title': "./name",
'description': "./desc",
'category': "./cat",
'cover': "./imgs/main/@url",
'authors': "./attrs/a[@name='Autor']",
'isbns': "./attrs/a[@name='ISBN']",
'page_count': "./attrs/a[@name='Ilosc_stron']",
'publisher': "./attrs/a[@name='Wydawnictwo']",
'date': "./attrs/a[@name='Rok_wydania']",
}
Case Study - parsing XMLs
<offers>
<offer>
<id>a-tale-of-two-cities</id>
<name>A Tale Of Two Cities></name>
<price>12,00</price>
<url>http://some-bookstore.pl/37f416,,1a881,,,</url>
<categoryId>Księgarnia,Powiesc></categoryId>
<description/>
<image>http://some-bookstore.pl/37f416.jpg</image>
<attributes>
<attribute>
<name>Wydawca</name>
<value>Macmillan></value>
</attribute>
<attribute>
<name>Autor</name>
<value>Charles Dickens></value>
</attribute>
<attribute>
<name>Dugość</name>
<value>1 godz. 9 min.></value>
</attribute>
</attributes>
</offer>
<offer>...</offer>
<offer>...</offer>
<offer>...</offer>
</offers>
from connectors.common import Afiliant
from connectors.generic import GenericBook
class SomeBookstore(Afiliant):
xml_tag_dict = dict(Afiliant.xml_tag_dict.items() + [
('cover', u"./image"),
('publisher', u"./attributes/attribute[name='Wydawca']/value"),
('authors', u"./attributes/attribute[name='Autor']/value"),
('audio_time', u"./attributes/attribute[name='Dugość']/value"),
])
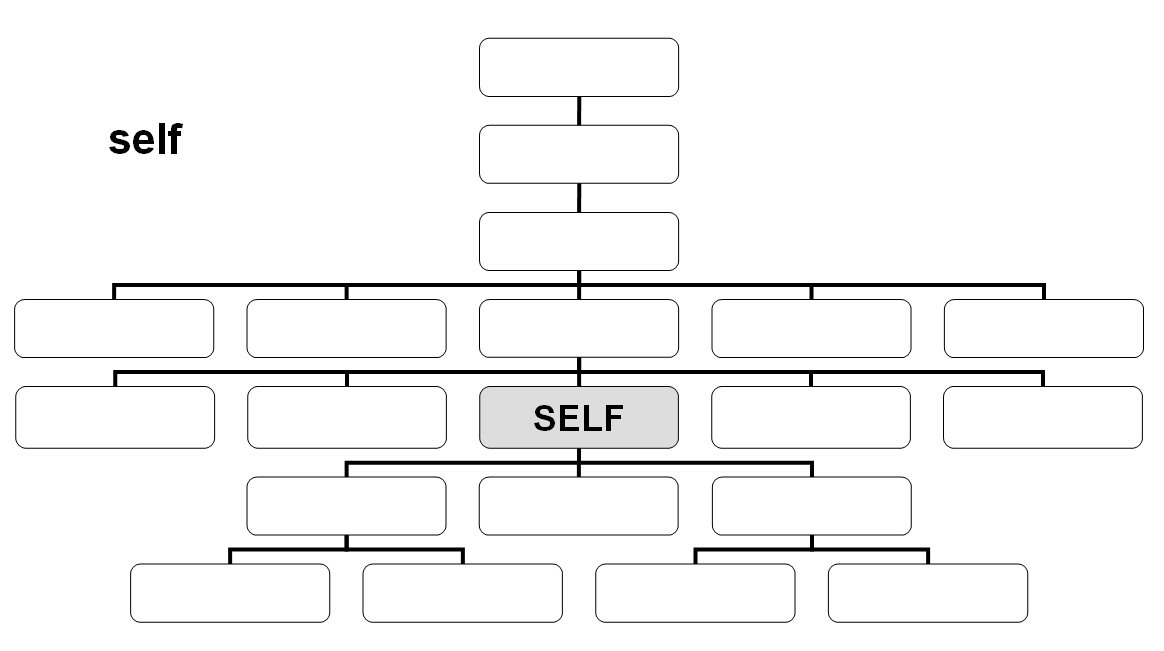
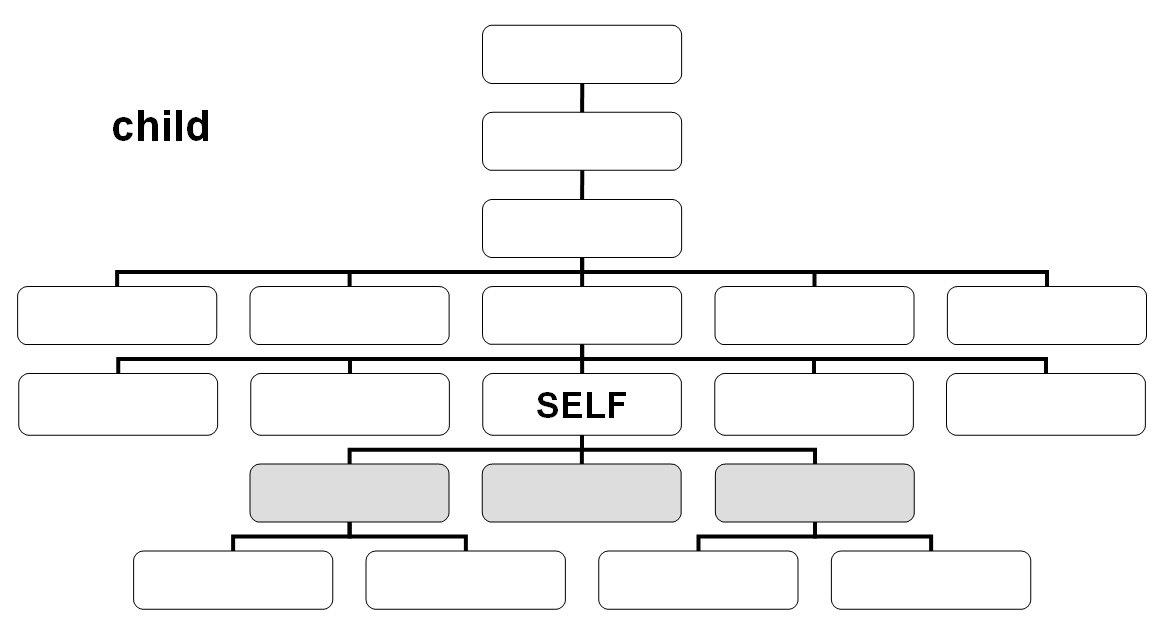
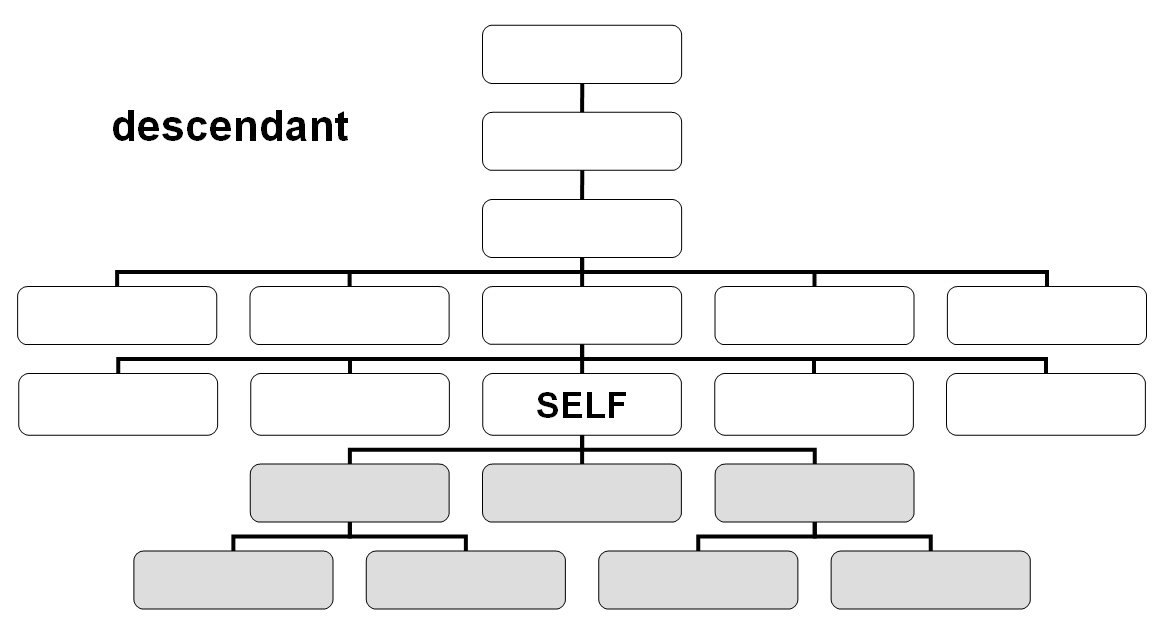
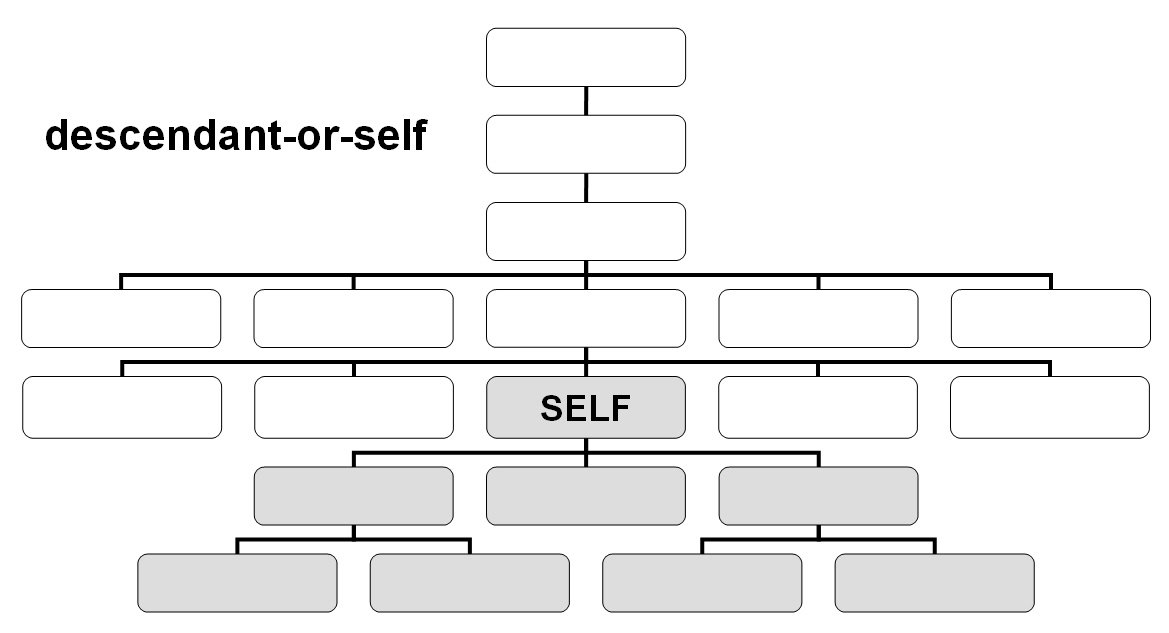
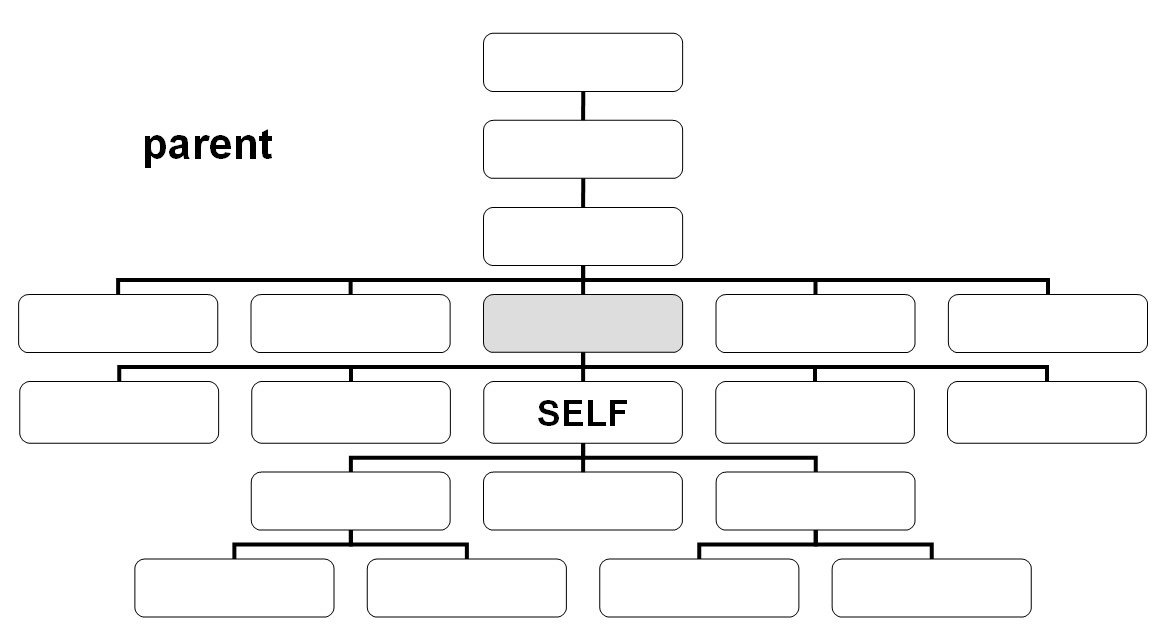
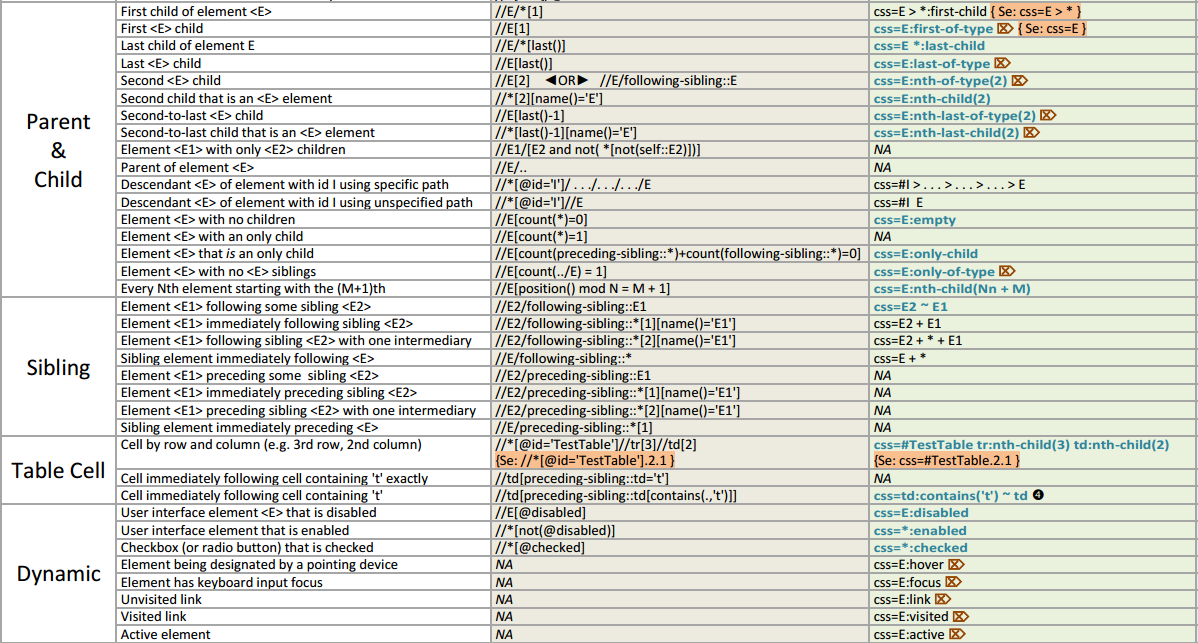
Axes
- child::
/child::foo/child::bar/child::baz - /foo/bar/baz - attribute::
/child::foo/attribute::bar - /foo/@bar - descendant::
- parent::
- ancestor::
- following-sibling::
- preceding-sibling::
- following::
- preceding::
- namespace::
- self::
- descendand-or-self::
- ancestor-or-self::
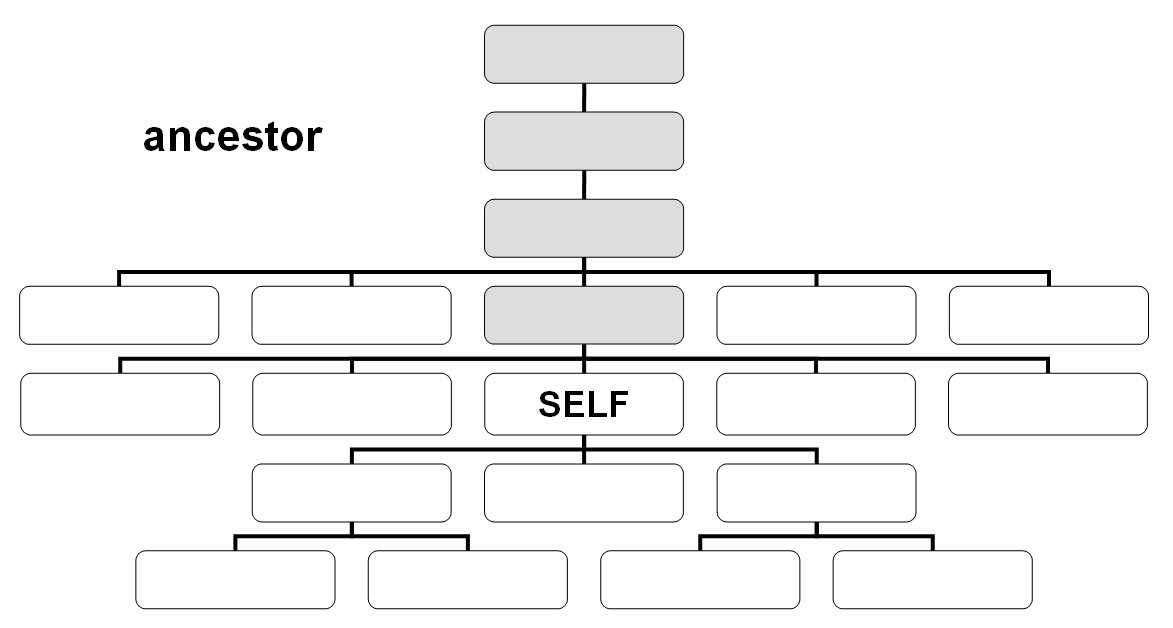
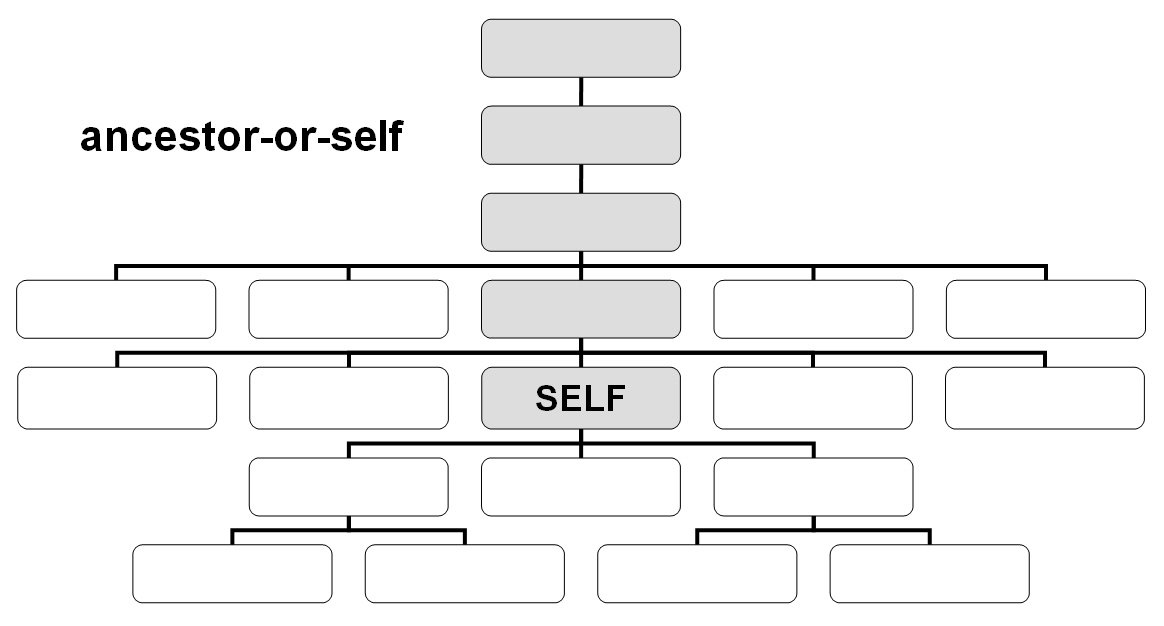
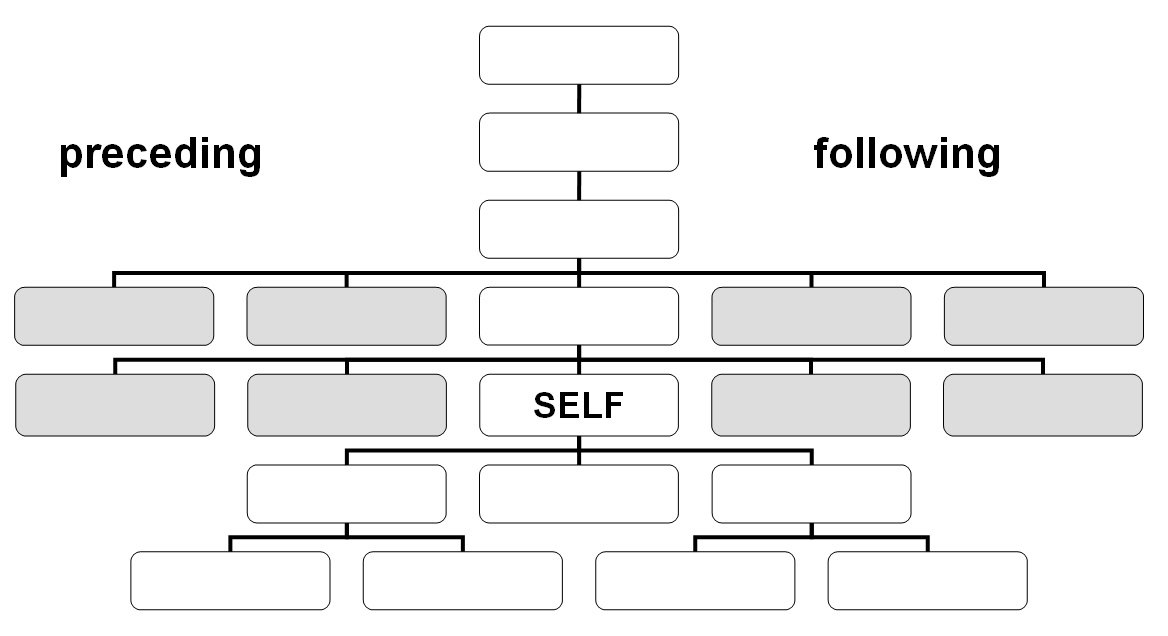
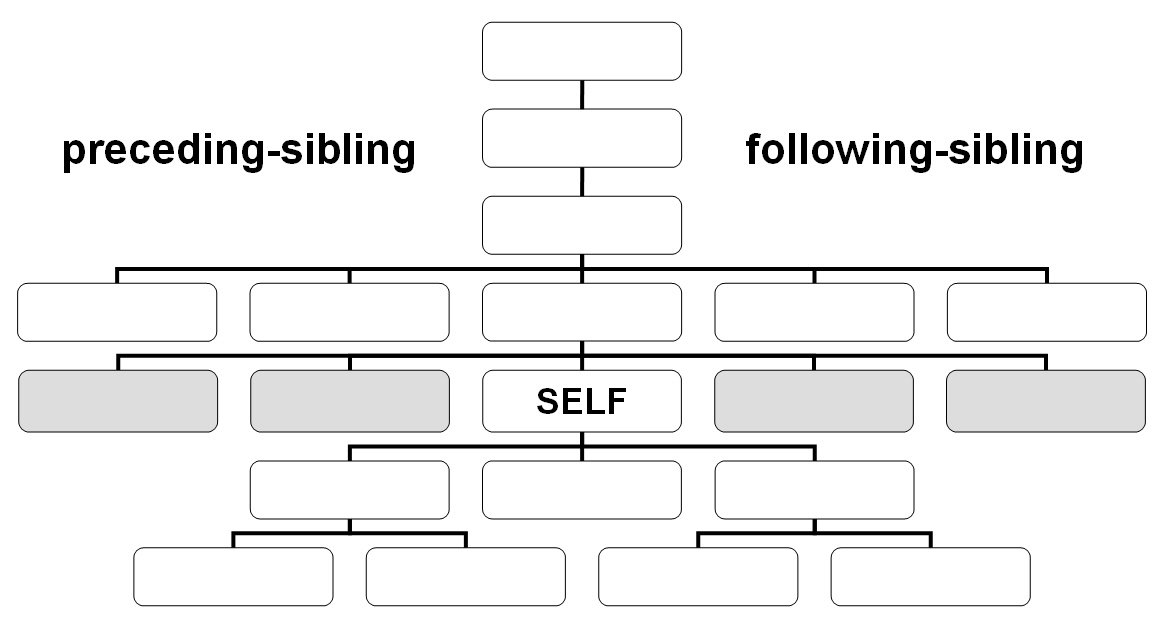
XPath Tutorials
Useful Cheat Sheets


link do slajdów: http://slides.com/noisy/xpath/

XPath
By noisy



