PHÂN LOẠI TRANG WEB BẰNG PHƯƠNG PHÁP K-NN VÀ SVM
Nhóm 15
- Nguyễn Tuấn Kiên.
- Hà Minh Công.
- Hà Mạnh Đông.
- Lê Huỳnh Đức.
- Nguyễn Văn Đức.
Nội dung
- Giới thiệu đề tài
- Các bước thực hiện
- Kết quả đạt được
- Hướng phát triển
Giới thiệu đề tài
- Bài toán: Phân loại trang web (page) dựa theo nội dung. Đánh giá hiệu năng từng phương pháp học máy được sử dụng.
- Đầu vào: Nội dung cần phân loại. (Dạng text)
- Đầu ra: Nhãn lớp/Chủ đề của nội dung trên.
- Hướng giải quyết: Sử dụng phương pháp K-NN và SVM để thực hiện phân loại.
Giới thiệu đề tài
- Công nghệ sử dụng
- Ngôn ngữ lập trình: Python.
- Thư viện học máy: sklearn.
- Giao diện xây dựng trên nền tảng web - framework Django.


Giới thiệu đề tài
- Ứng dụng thực tế: Tổ chức, lưu trữ và tìm kiếm thông tin.
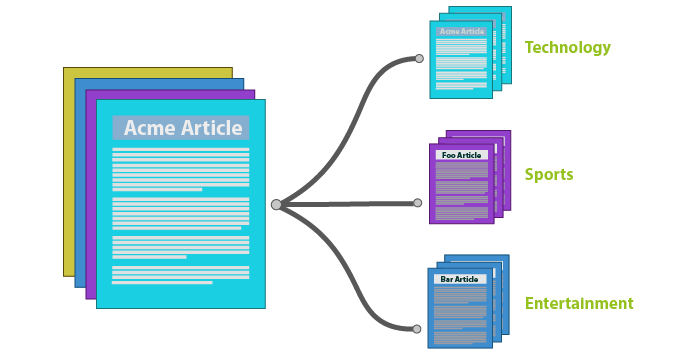
Các bước thực hiện
Training
Websites
Crawl
Train contents
labels
features
Machine Algorithm
Prediction
New content
Text Feature Extractor
Text Feature Extractor
features
Classifier Model
Label
Các bước thực hiện
- Crawl từ những trang web - 330 000 bản ghi
- Los Angeles Times
- CNN
- ABC News
- NBC news
- Telegraph
- USA Today
- Daily News
- NewYork Post
- The Guaradian
- NewYork Times
- Huffington Post
- Washington Post
- Chicago Suntime
- Sử dụng Sqlite để lưu trữ.
Crawl dữ liệu bằng scrapy
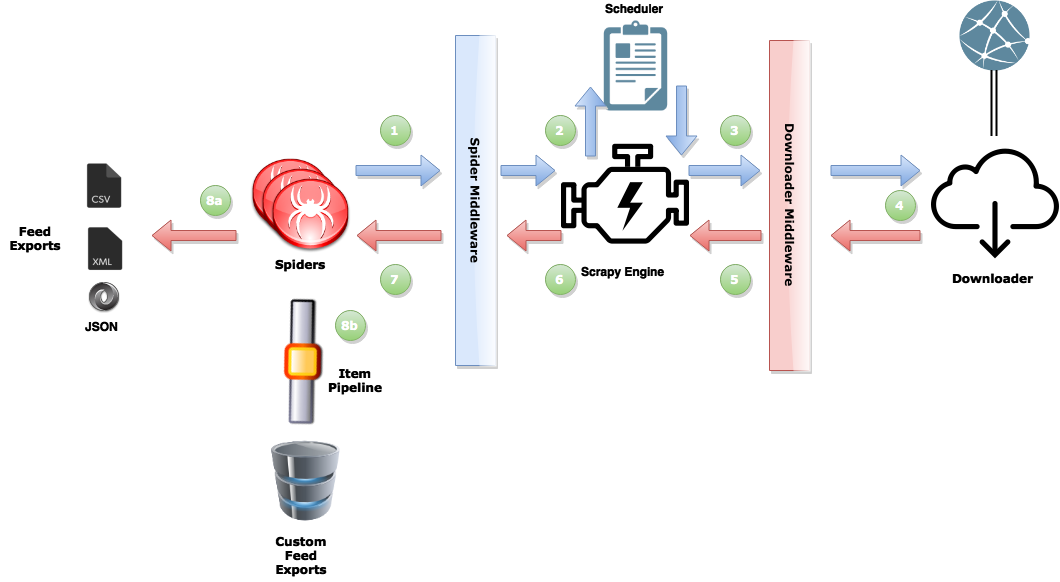
Crawl dữ liệu bằng scrapy
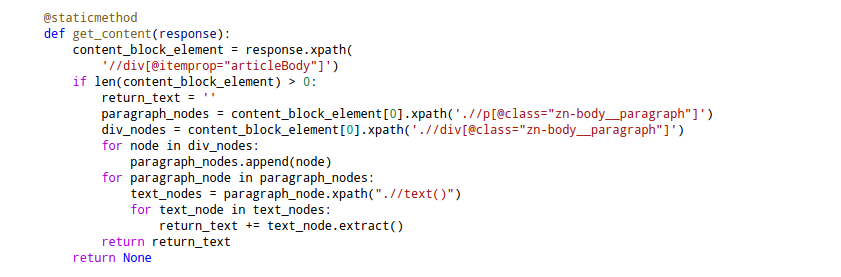
Các dữ liệu quan trọng cần thu thập là: Nội dung bài báo, thể loại bài báo và các đường dẫn tới các bài báo tiếp theo
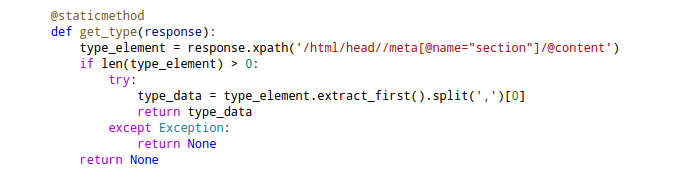
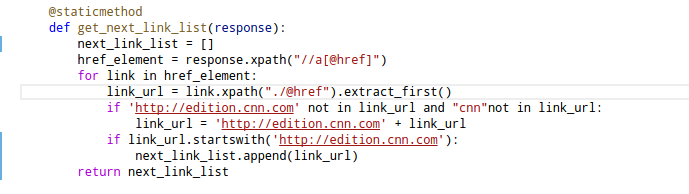
Một số kịch bản sử dụng bộ dữ liệu
Để kiểm tra khả năng cũng như tối ưu bộ dữ liệu cho hệ thống, chúng ta sử dụng các kịch bản sau để test:
Kịch bản 1:
- Sử dụng bộ dữ liệu gồm 12000 bản ghi, không giới hạn thể loại bài báo, không giới hạn số lượng bản ghi trong một thể loại
Kịch bản 2:
- Giới hạn số lượng các thể loại (6 thể loại), số lượng bản ghi mỗi thể loại là như nhau (2500 bản ghi)
Các bước thực hiện
Sau khi xử lý dữ liệu, ta được bộ dữ liệu là một danh sách các bản ghi, trong đó mỗi bản ghi chứa 2 trường quan trọng sau:
+ Thể loại (type)
+ Nội dung bản ghi (content)
Sau đó, ta chia bộ dữ liệu ra thành 2 phần: Phần dùng để training và phần dùng để kiểm tra hệ thống
Các bước thực hiện
Text feature extactor:
- Bag Of Word.
- TF-IDF
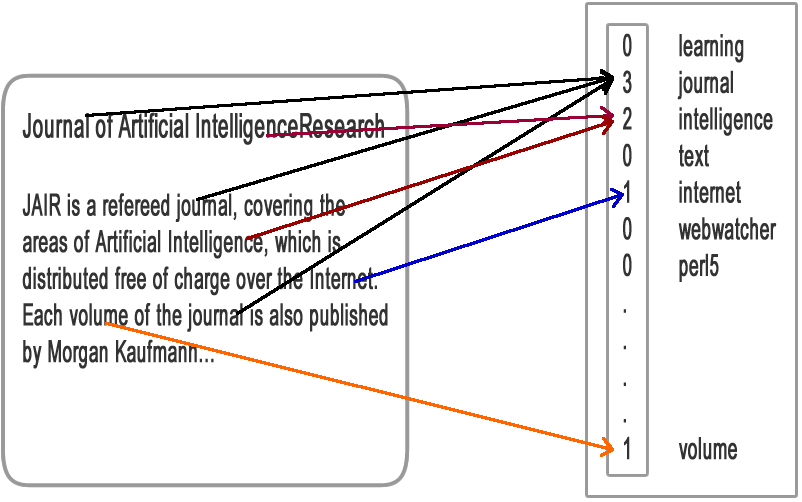
A swimmer like swimming thus he swims
Lọc bỏ từ dừng
A swimmer like swimming thus he swims
Các bước thực hiện
- Tiến hành huấn luyện.
- Tuning tham số cho các thuật toán K-NN và SVM sử dụng GridSearchCV.
- Trả về được ClassifierModel với các tham số tốt nhất.
| 1 | 10 | 1000 | |
|---|---|---|---|
| Linear | |||
| Rbf |
model 1
model 2
model 3
model 4
model 5
model 6
Các bước thực hiện
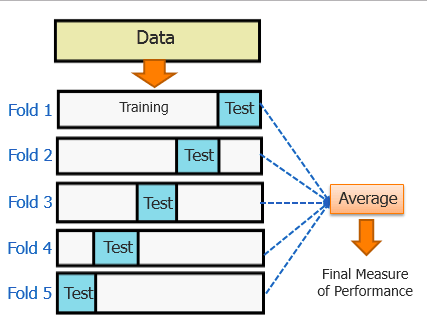
- Dựa trên phương pháp Cross validation và tiêu chí accuracy_score để đánh giá.
- Trả về được ClassifierModel với các tham số tốt nhất.
Các bước thực hiện
- Tiến hành dự đoán.
- Đầu vào: Nội dung dạng text.
- Tiến hành Text Feature Extractor - Chuyển đổi từ dạng text sang dạng vector.
- Đưa vào ClassifierModel để dự đoán nhãn.
- Đầu ra: Đưa ra nhãn thích hợp với nội dung được đưa vào.
Các bước thực hiện
Đánh giá:
- Chia bộ train thành train và test theo tỉ lệ 2/3 - 1/3 theo phương pháp Hold-out
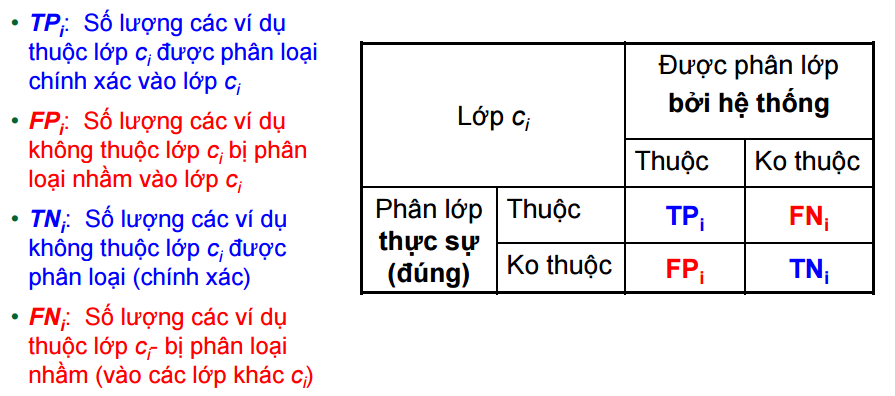
- Tính Precision và Recall.

Các bước thực hiện
Đánh giá:
- Biểu diễn Confusion Matrix.
- Biểu diễn đồ thị PR và ROC.
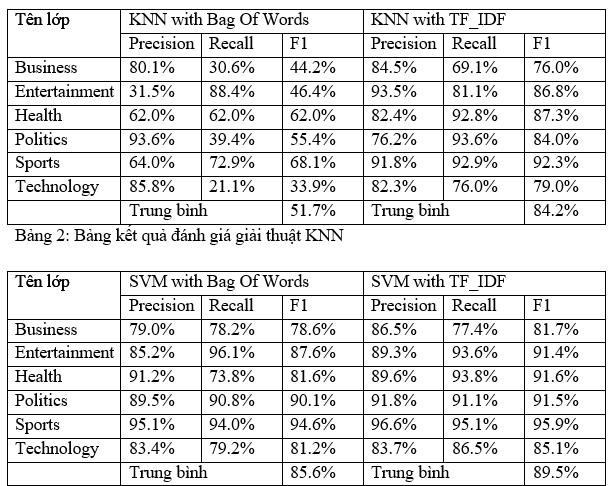
Đánh giá
Kết quả đạt được
DEMO TIME
Hướng phát triển
- Mở rộng các nhãn lớp (Tăng số lượng).
- Tăng độ lớn của tập train.
- Tối ưu hóa.
- Áp dụng để sử dụng cho tập dữ liệu Tiếng Việt.
- Thêm chức năng mở rộng khi có một ví dụ mới không có trong bộ train.
Cám ơn thầy và các bạn đã lắng nghe
deck
By Tuấn Kiên Nguyễn



