









One Fourth Labs
We deliver courseware in AI and related areas
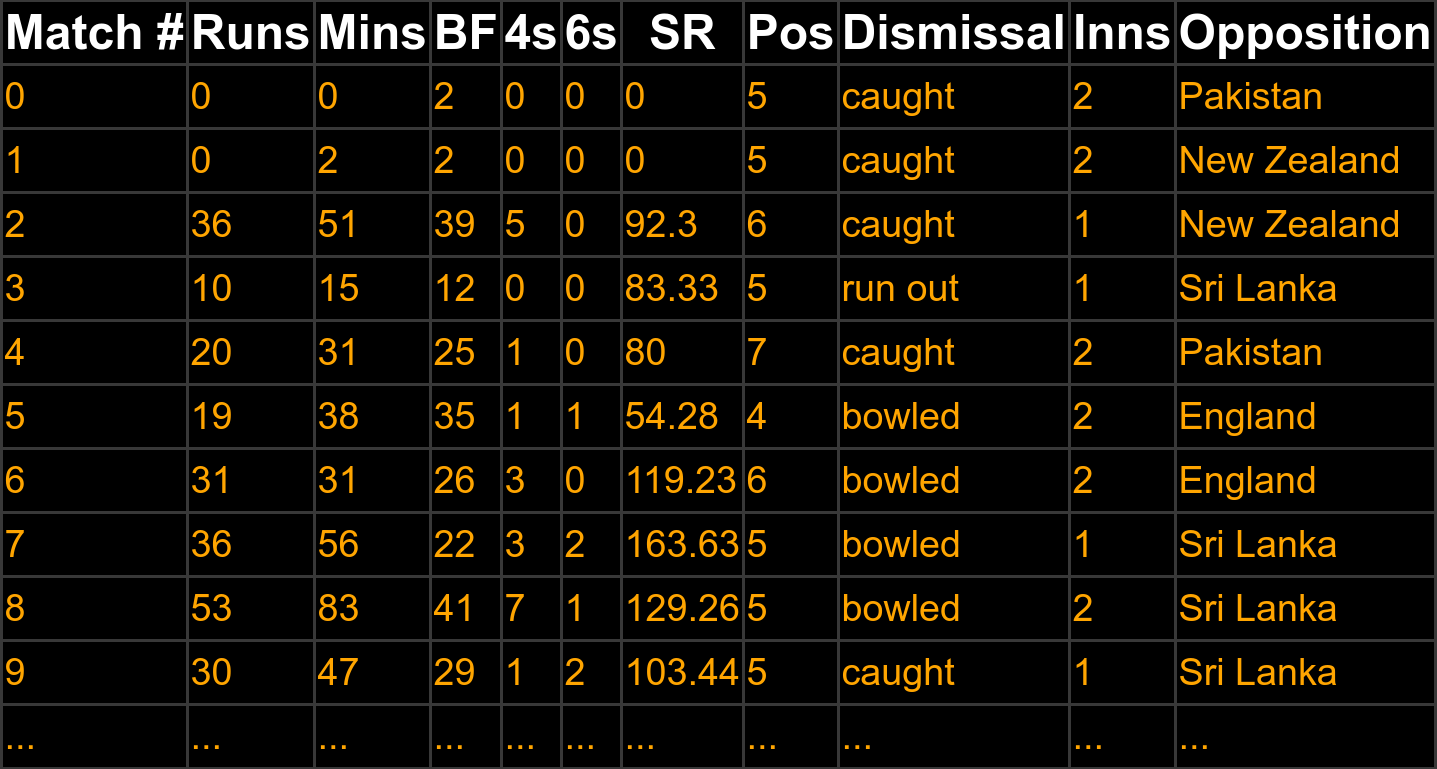
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
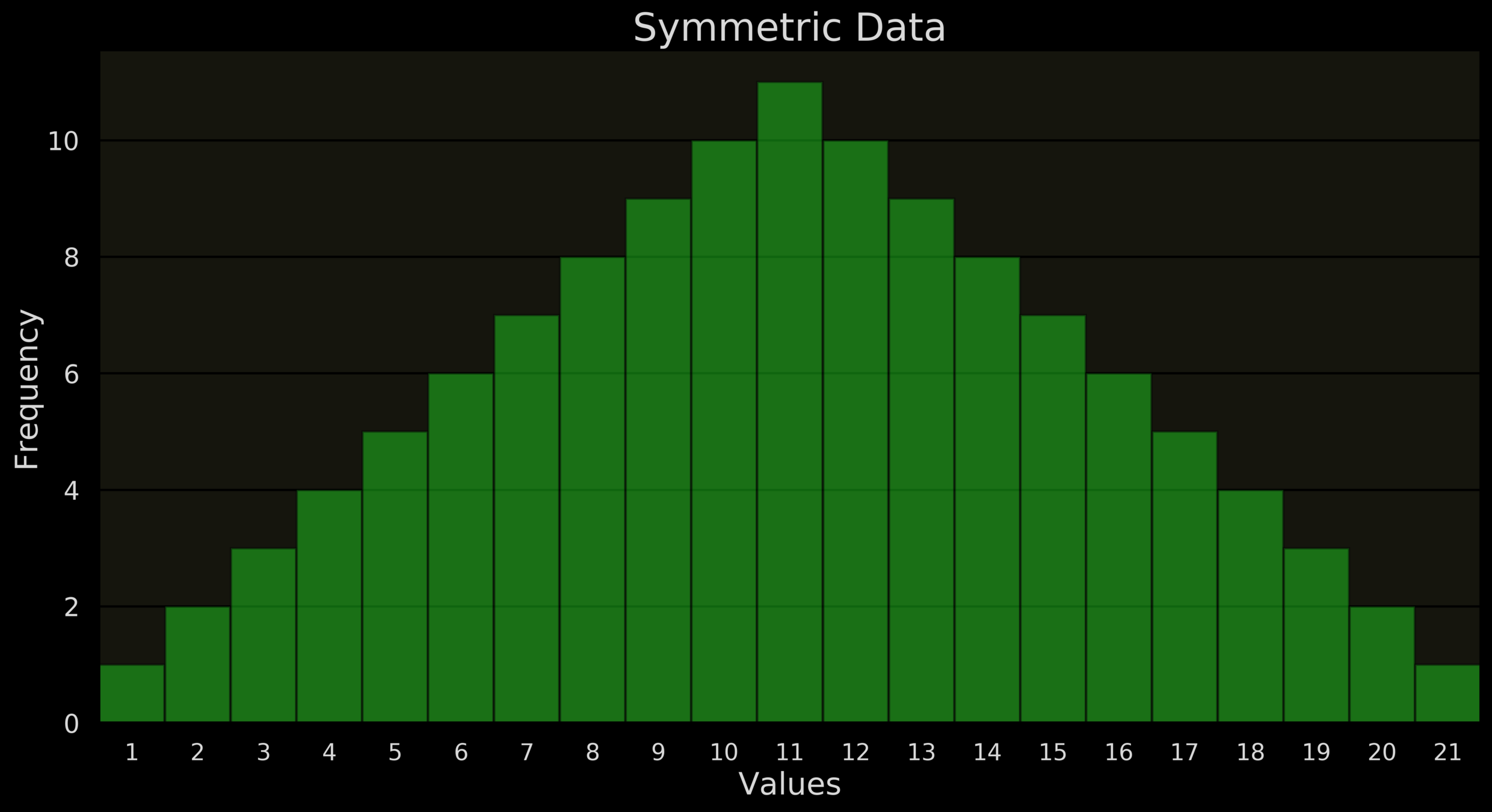
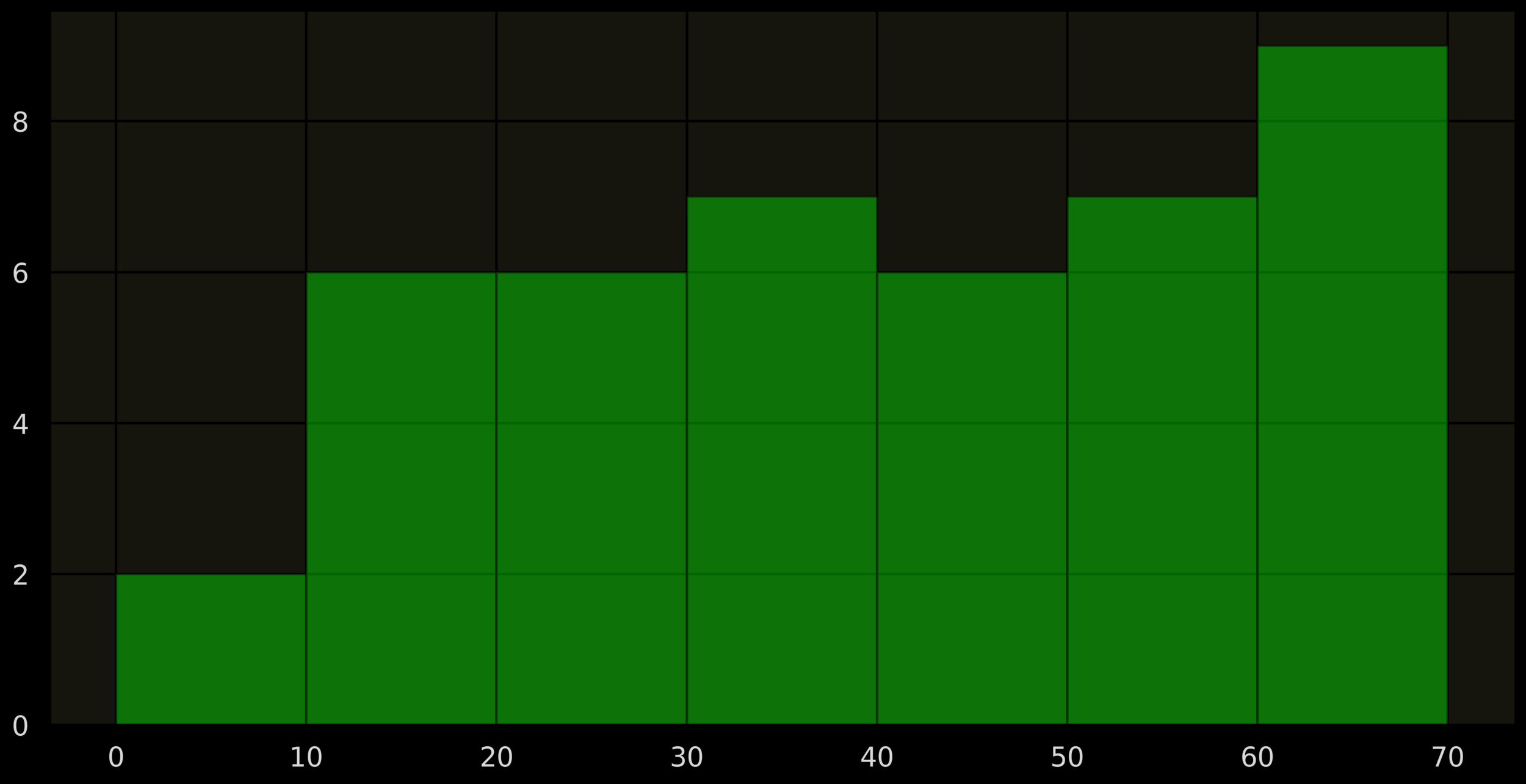
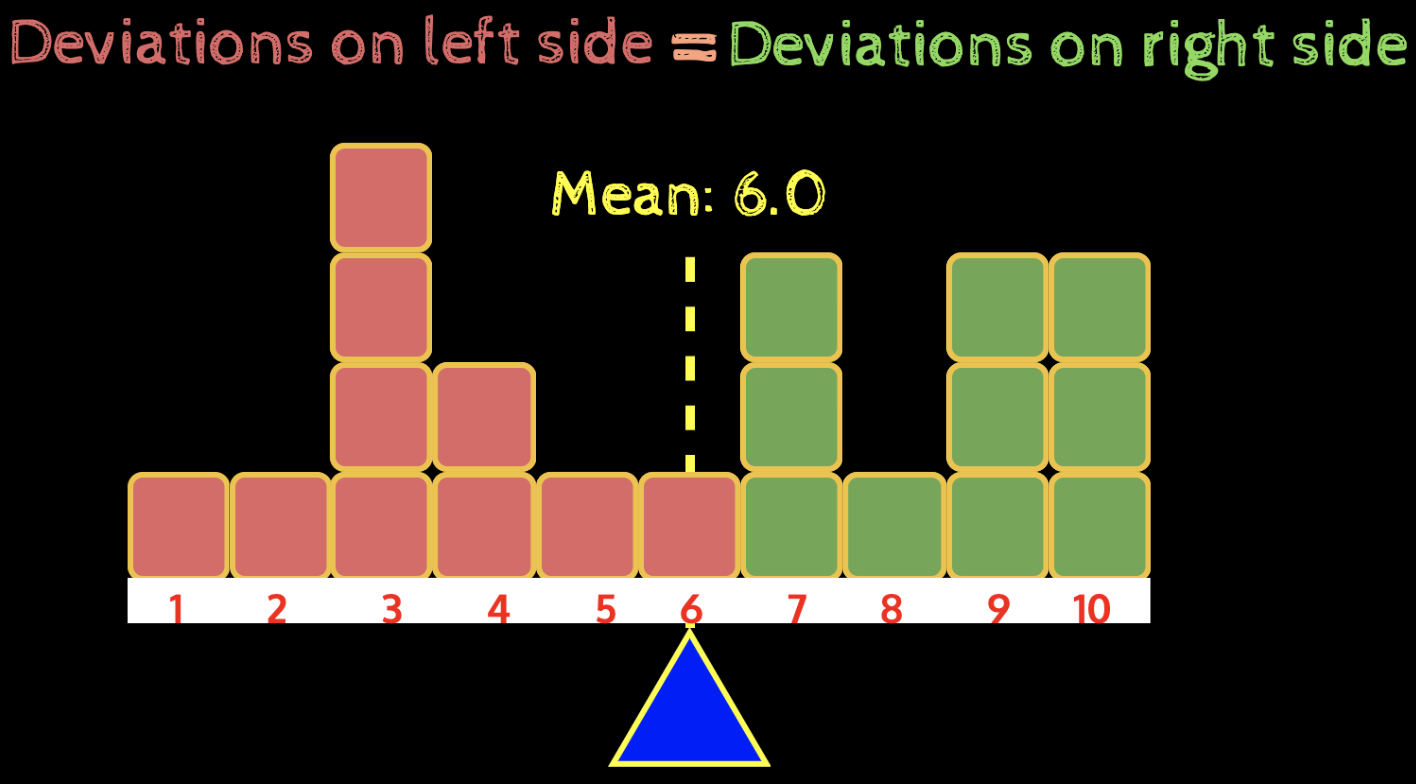
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
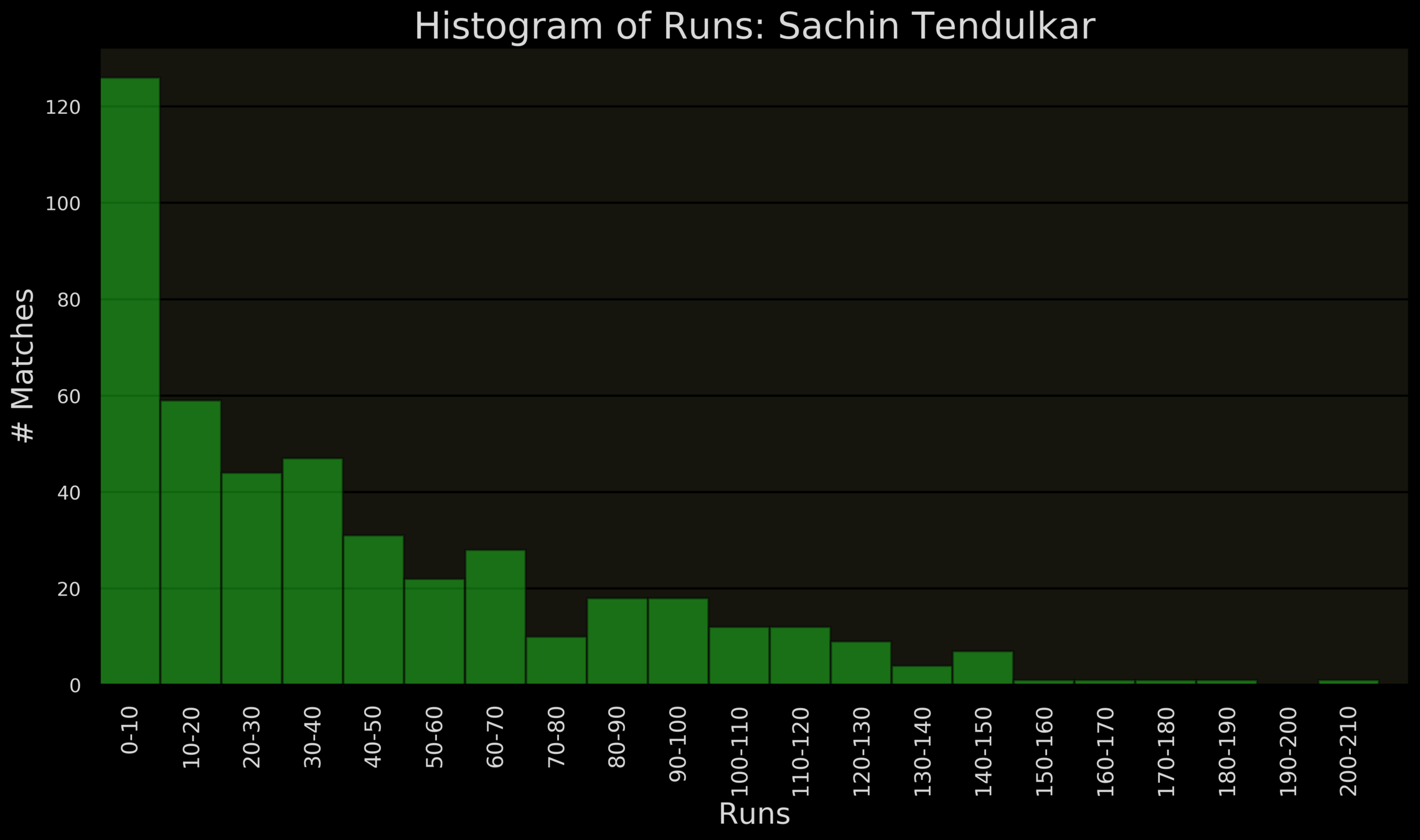
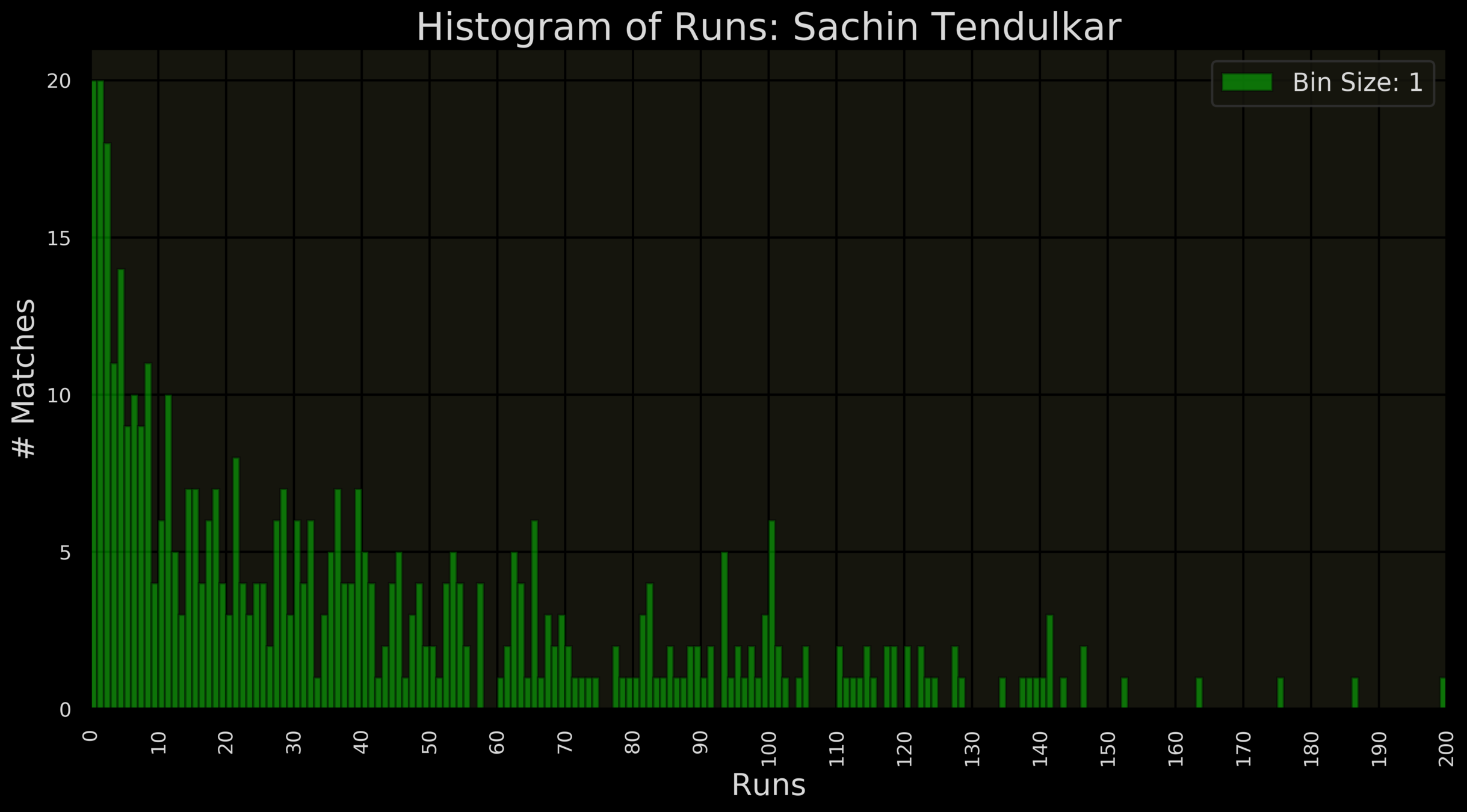
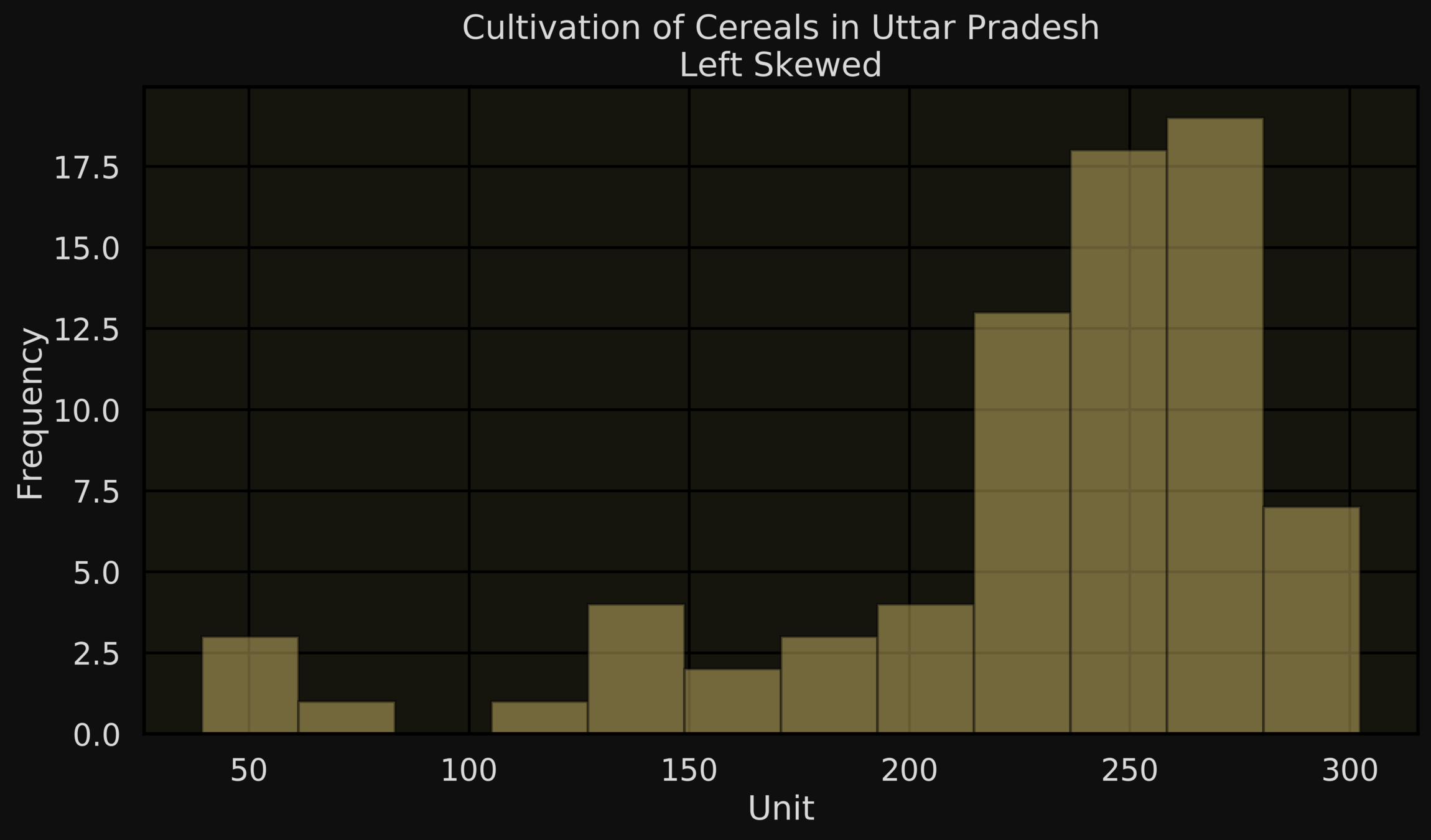
| Interval | Frequency |
|---|---|
| 0 - 10 | 126 |
| 10-20 | 59 |
| 20-30 | 44 |
| 30-40 | 47 |
| 40-50 | 31 |
| 50-60 | 22 |
| 60-70 | 28 |
| 70-80 | 10 |
| 80-90 | 18 |
| 90-100 | 18 |
| Interval | Frequency |
|---|---|
| 100-110 | 12 |
| 110-120 | 12 |
| 120-130 | 9 |
| 130-140 | 4 |
| 140-150 | 7 |
| 150-160 | 1 |
| 160-170 | 1 |
| 170-180 | 1 |
| 180-190 | 1 |
| 190-200 | 0 |
| 200-210 | 1 |
| Interval | Frequency | Cumulative Frequency |
|---|---|---|
| 0 - 10 | 126 | 126 |
| 10-20 | 59 | 185 |
| 20-30 | 44 | 229 |
| 30-40 | 47 | 276 |
| 40-50 | 31 | 307 |
| 50-60 | 22 | 329 |
| 60-70 | 28 | 357 |
| 70-80 | 10 | 367 |
| 80-90 | 18 | 385 |
| 90-100 | 18 | 403 |
| Interval | Frequency | Cumulative Frequency |
|---|---|---|
| 100 - 110 | 12 | 415 |
| 110-120 | 12 | 427 |
| 120-130 | 9 | 436 |
| 130-140 | 4 | 440 |
| 140-150 | 7 | 447 |
| 150-160 | 1 | 448 |
| 160-170 | 1 | 449 |
| 170-180 | 1 | 450 |
| 180-1900 | 1 | 451 |
| 190-200 | 0 | 451 |
| 200-210 | 1 | 452 |
| Interval | Frequency | Cumulative Frequency |
|---|---|---|
| 0 - 10 | 126 | 126 |
| 10-20 | 59 | 185 |
| 20-30 | 44 | 229 |
| Interval | Frequency |
|---|---|
| 0 - 10 | 126 |
| 10-20 | 59 |
| 20-30 | 44 |
| 30-40 | 47 |
| 40-50 | 31 |
| 50-60 | 22 |
| 60-70 | 28 |
| 70-80 | 10 |
| 80-90 | 18 |
| 90-100 | 18 |
| Interval | Frequency |
|---|---|
| 100 - 110 | 12 |
| 110-120 | 12 |
| 120-130 | 9 |
| 130-140 | 4 |
| 140-150 | 7 |
| 150-160 | 1 |
| 160-170 | 1 |
| 170-180 | 1 |
| 180-1900 | 1 |
| 190-200 | 0 |
| 200-210 | 1 |
| Interval | Frequency | Mid-point | Mid-point * frequency |
|---|---|---|---|
| 0 - 10 | 126 | 5 | 630 |
| 10-20 | 59 | 15 | 885 |
| 20-30 | 44 | 25 | 1100 |
| 30-40 | 47 | 35 | 1645 |
| 40-50 | 31 | 45 | 1395 |
| 50-60 | 22 | 55 | 1210 |
| 60-70 | 28 | 65 | 1820 |
| 70-80 | 10 | 75 | 750 |
| 80-90 | 18 | 85 | 1530 |
| 90-100 | 18 | 95 | 1710 |
| 100-110 | 12 | 105 | 1260 |
| 110-120 | 12 | 115 | 1380 |
| 120-130 | 9 | 125 | 1125 |
| 130-140 | 4 | 135 | 540 |
| 140-150 | 7 | 145 | 1015 |
| 150-160 | 1 | 155 | 155 |
| 160-170 | 1 | 165 | 165 |
| 170-180 | 1 | 175 | 175 |
|---|---|---|---|
| 180-190 | 1 | 185 | 185 |
| 190-200 | 0 | 195 | 0 |
| 200-210 | 1 | 205 | 205 |
| Interval | Frequency | Mid-point | Mid-point * frequency |
|---|---|---|---|
| 0 - 10 | 126 | 5 | 630 |
| 10-20 | 59 | 15 | 885 |
| 20-30 | 44 | 25 | 1100 |
| 30-40 | 47 | 35 | 1645 |
| 40-50 | 31 | 45 | 1395 |
| 50-60 | 22 | 55 | 1210 |
| 60-70 | 28 | 65 | 1820 |
| 70-80 | 10 | 75 | 750 |
| 80-90 | 18 | 85 | 1530 |
| 90-100 | 18 | 95 | 1710 |
| 100-110 | 12 | 105 | 1260 |
| 110-120 | 12 | 115 | 1380 |
| 120-130 | 9 | 125 | 1125 |
| 130-140 | 4 | 135 | 540 |
| 140-150 | 7 | 145 | 1015 |
| 150-160 | 1 | 155 | 155 |
| 160-170 | 1 | 165 | 165 |
| 170-180 | 1 | 175 | 175 |
|---|---|---|---|
| 180-190 | 1 | 185 | 185 |
| 190-200 | 0 | 195 | 0 |
| 200-210 | 1 | 205 | 205 |
| Interval | Frequency |
|---|---|
| 0 - 10 | 126 |
| 10-20 | 59 |
| 20-30 | 44 |
| 30-40 | 47 |
| 40-50 | 31 |
| 50-60 | 22 |
| 60-70 | 28 |
| 70-80 | 10 |
| 80-90 | 18 |
| 90-100 | 18 |
| .... ..... | .... .... |
| Interval | Frequency |
|---|---|
| 0 - 10 | 126 |
| 10-20 | 59 |
| 20-30 | 44 |
| 30-40 | 47 |
| 40-50 | 31 |
| 50-60 | 22 |
| 60-70 | 28 |
| 70-80 | 10 |
| 80-90 | 18 |
| 90-100 | 18 |
| .... ..... | .... .... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Age | Height | Weight | Cholesterol | Sugar level | .... ..... |
|---|---|---|---|---|---|
| 32 | 165 | 75 | 124 | 108 | ... |
| 24 | 172 | 81 | 112 | 98 | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... |
| Interval | Frequency | Cumulative Frequency |
|---|---|---|
| 0 - 10 | 137 | 196 |
| 10-20 | 59 | 196 |
| 20-30 | 44 | 240 |
| Interval | Frequency | Mid-point | Mid-point * frequency |
|---|---|---|---|
| 0 - 10 | 137 | 5 | 685 |
| 10-20 | 59 | 15 | 885 |
| 20-30 | 44 | 25 | 1100 |
| 30-40 | 47 | 35 | 1645 |
| 40-50 | 31 | 45 | 1395 |
| 50-60 | 22 | 55 | 1210 |
| 60-70 | 28 | 65 | 750 |
| 70-80 | 10 | 75 | 1530 |
| 80-90 | 18 | 85 | 1710 |
| 90-100 | 18 | 95 | 1260 |
| 100-110 | 12 | 105 | 1260 |
| 110-120 | 12 | 115 | 1380 |
| 120-130 | 9 | 125 | 1125 |
| 130-140 | 4 | 135 | 540 |
| 140-150 | 7 | 145 | 1015 |
| 150-160 | 1 | 155 | 155 |
| 160-170 | 1 | 165 | 165 |
| 170-180 | 1 | 175 | 175 |
|---|---|---|---|
| 180-190 | 1 | 185 | 185 |
| 190-200 | 0 | 195 | 0 |
| 200-210 | 47 | 205 | 205 |
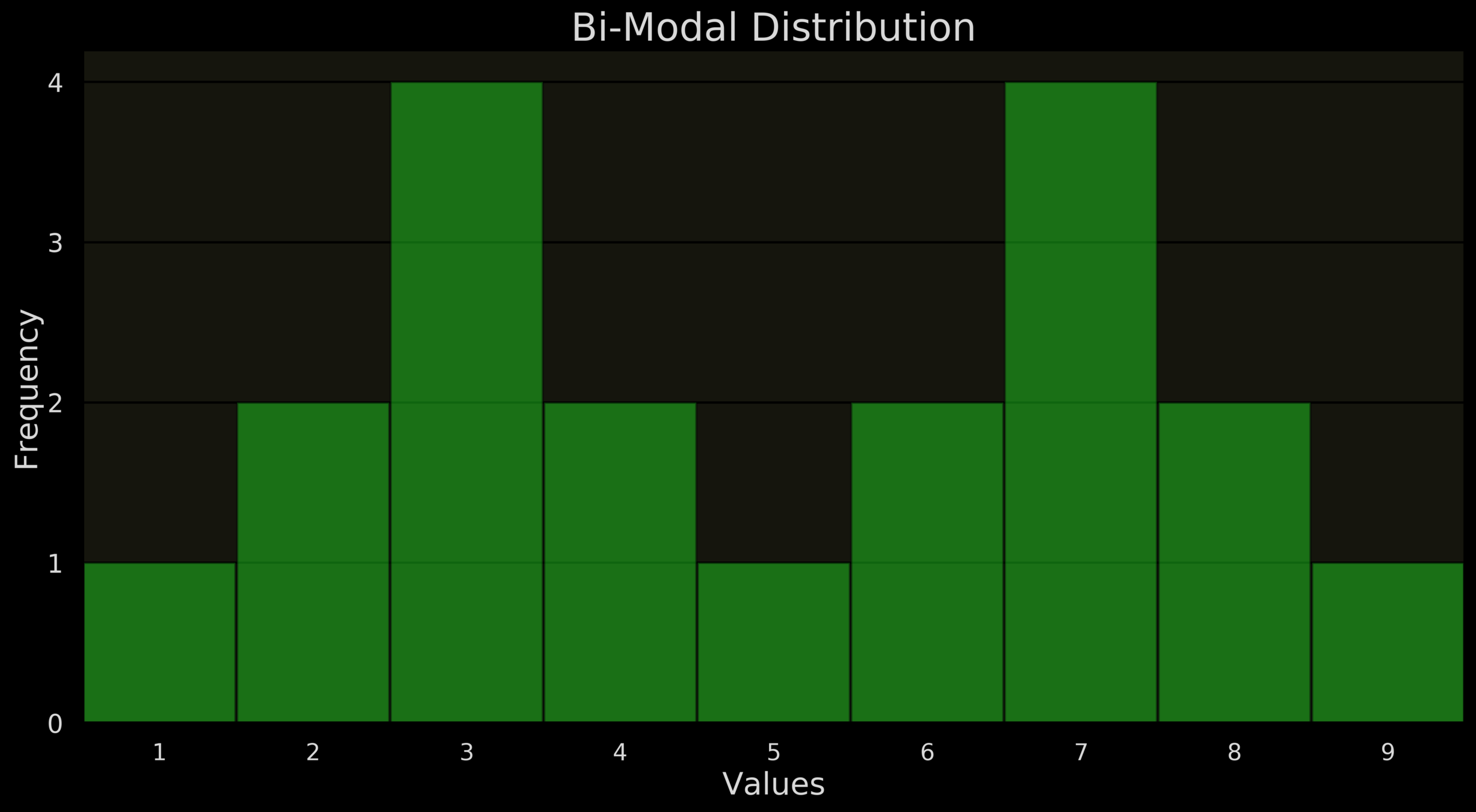
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
By One Fourth Labs
PadhAI One: FDS Week 3 (MK)



