






One Fourth Labs
We deliver courseware in AI and related areas
* Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, Wei Wang, Language-agnostic BERT Sentence Embedding, arXiv 2020
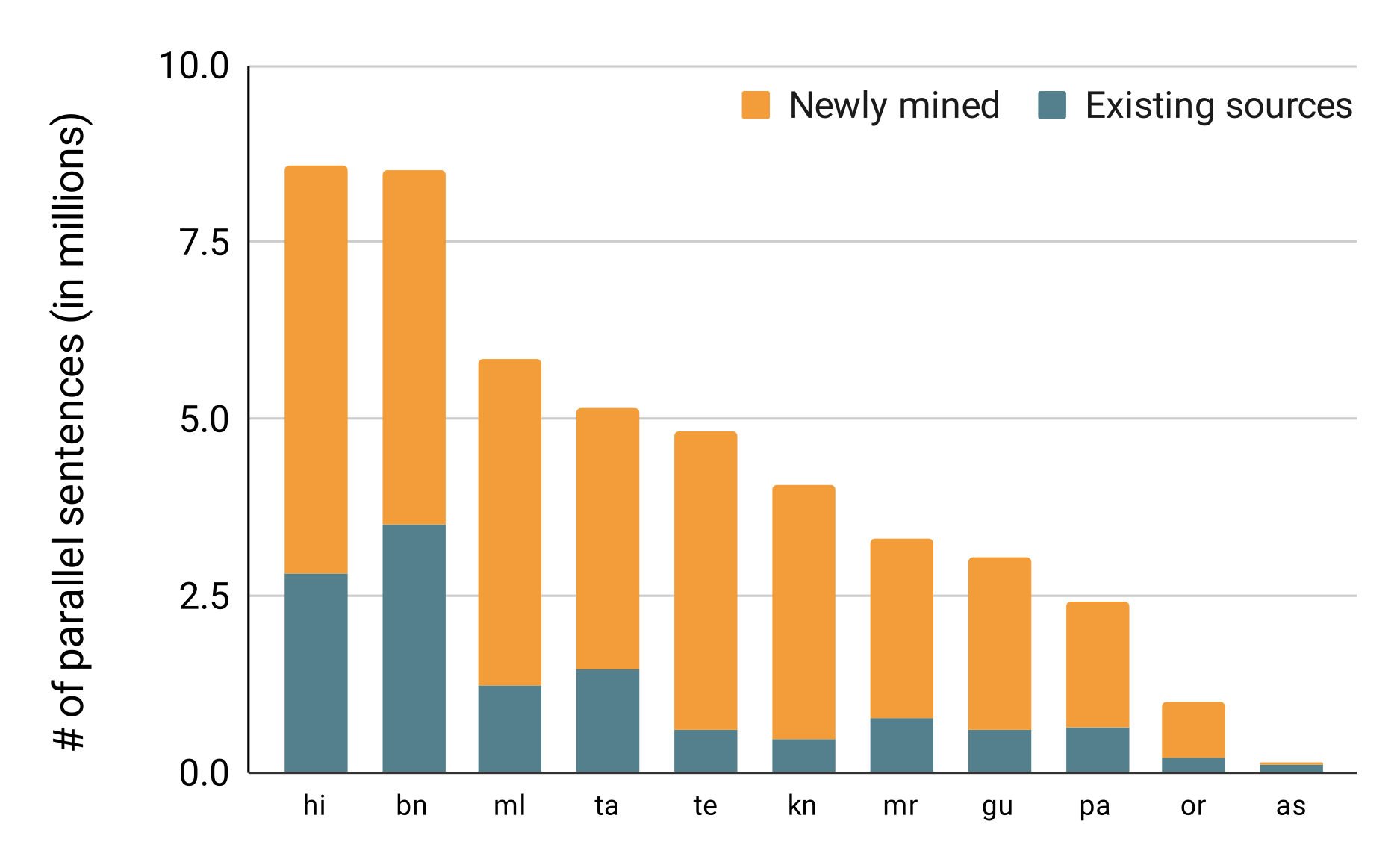
24 such news sources considered in this work with data from 2010 onwards
En
https://mykhel.com/
हि
https://hindi.mykhel.com/
https://tn.gov.in/
* Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, Wei Wang, Language-agnostic BERT Sentence Embedding, arXiv 2020
Legislative proceedings from Tamil Nadu, Andhra Pradesh, Telangana, West Bengal, Bangladesh
en_budget_2020.pdf
ta_budget_2020.pdf
https://tn.gov.in/
En
த
Jeff Johnson, Matthijs Douze, Hervé Jégou, Billion-scale similarity search with GPUs, arXiv, 2019
IndicCorp contains 1.3M (Assamese) to 100M (English) monolingual sentences for 11 Indic languages
En
100M
Hi
64M
বা
हि
ಕ
म
ଓ
த
മ
తె
অ
ગુ
ਪੰ
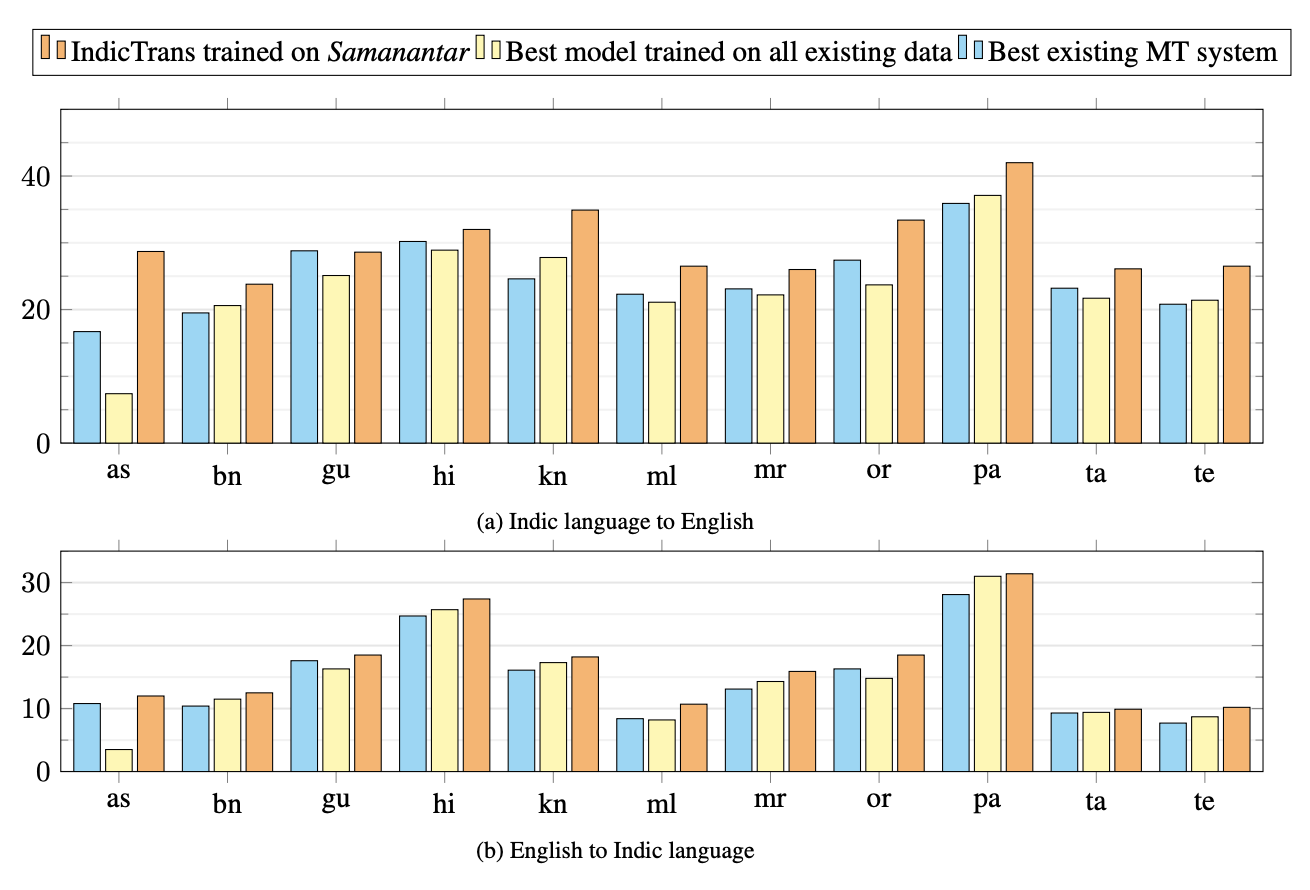
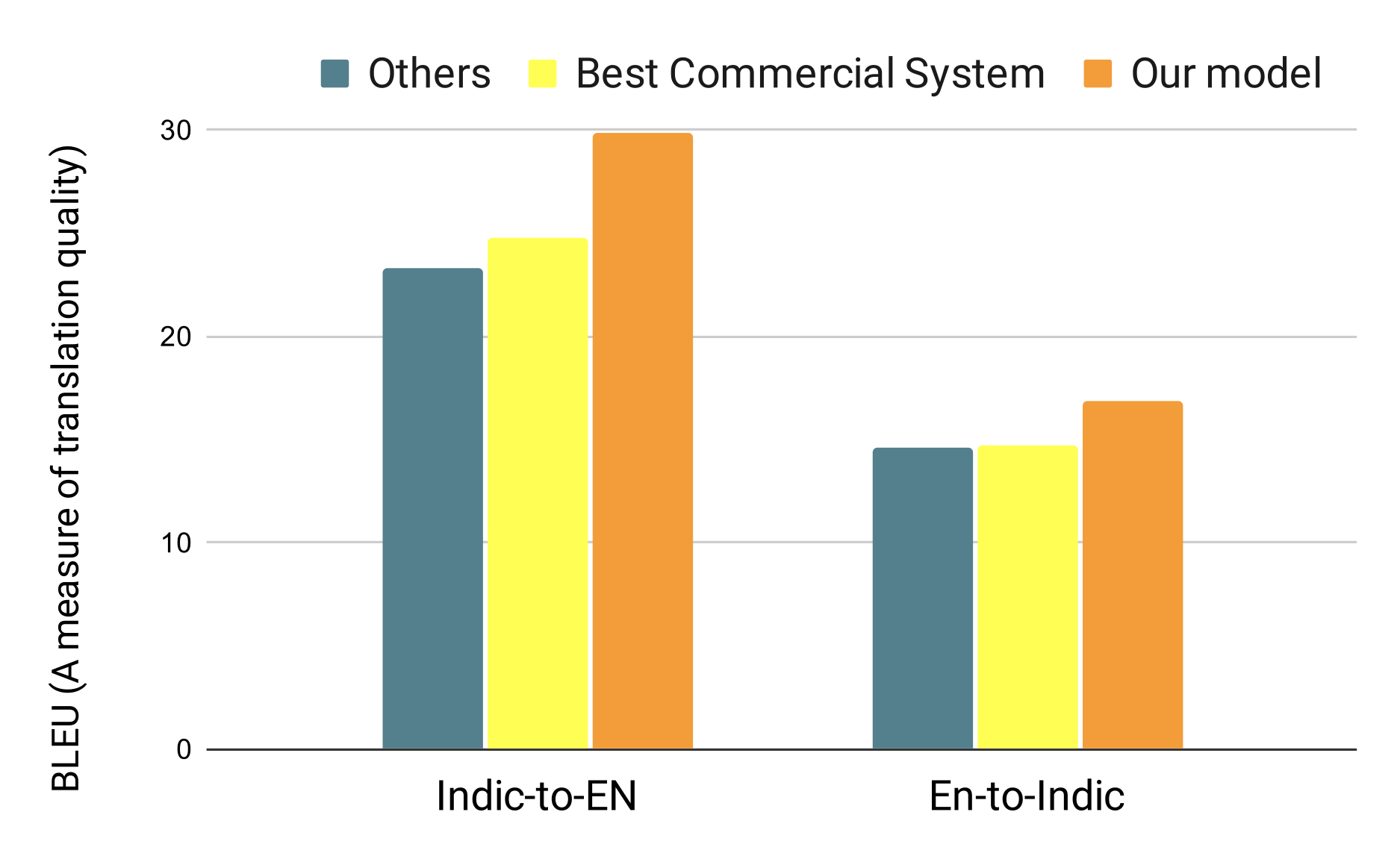
“The quality of translations is significantly improved. I would say this is more so for the legal document where there were complicated sentences/cards which were translated very well. The syntax mostly did not falter even in the face of multiple ideas/information contained in one sentence.”
“The amount of time spent on correcting/improving the translation has dropped.”
“THIS IS VERY PROMISING. AMAZED BY THE SPEED.”
“I TOOK A PRINTOUT AND WENT THROUGH EVERY LINE. THE TRANSLATION IS 98% ACCURATE AND HIGHLY SATISFIED.”
Let's make India ready for the AI age
Anoop Kunchukuttan
Mitesh M. Khapra
Pratyush Kumar
anoop.kunchukuttan@gmail.com
miteshk@cse.iitm.ac.in
pratyush@cse.iitm.ac.in
By One Fourth Labs
A hub for Indic NLP resources, datasets and tools




