PyAmsterdam
info@py.amsterdam
AWS Glue
The Good, the Bad and the Ugly
What is it?
- ETL service (extract, transform, load)
- Fully managed
- Serverless
- Spark (Python, Scala)
- Python
-
Data catalog
Tables, connections, crawlers, schemas
-
Job
Teaching has made me a better developer. -
Trigger
schedule, on-demand, job event, (all, any) -
Workflow
Orchestration of jobs, triggers and crawlers
Components
Background
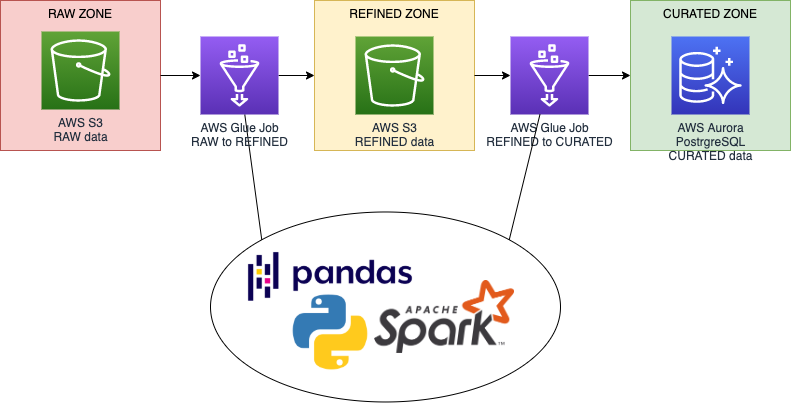
Your first job
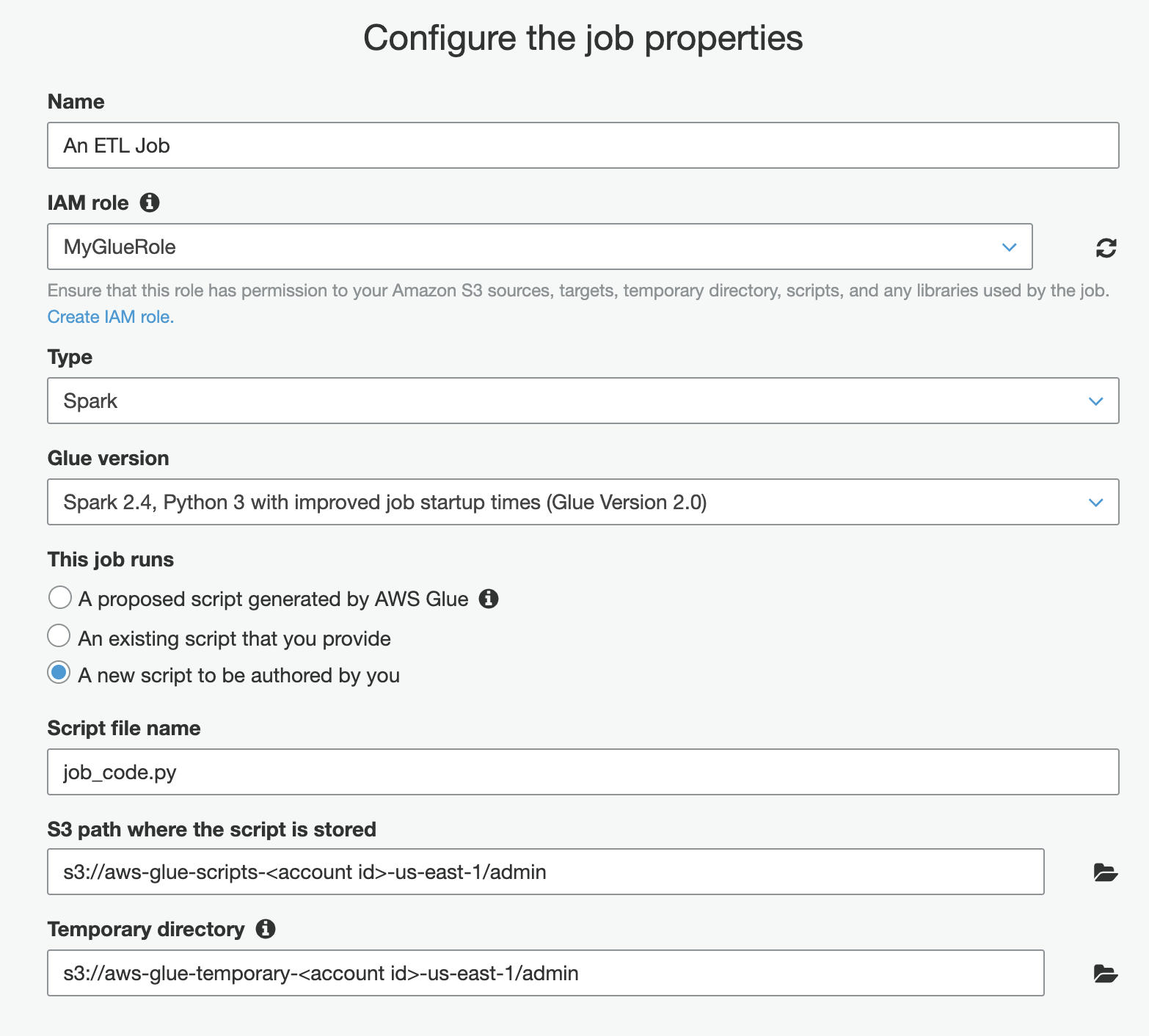
Your first job

Your first job
That's all!
Thank you for your attention.
Questions?
I'm kidding, we just getting started
Real application
├── data_sources
│ └── ds1
│ ├── raw_to_refined
│ └── refined_to_curated
└── shared
└── glue_shared_lib
├── src
│ └── glue_shared
└── testsDependencies pt.1
PySpark jobs
Python Shell jobs
.zip
.whl
.py
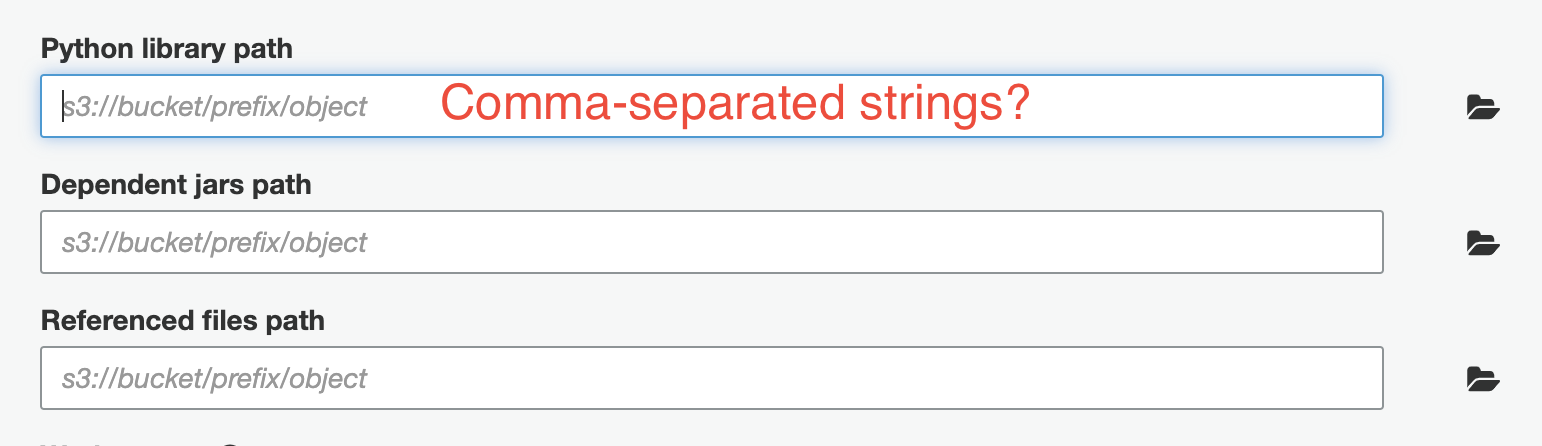
s3://bucket/prefix/lib_A.zip,s3://bucket_B/prefix/lib_X.zipDependencies pt.2
Boto3
collections
CSV
gzip
multiprocessing
NumPy
pandas
pickle
PyGreSQL
re
SciPy
sklearn
sklearn.feature_extraction
sklearn.preprocessing
xml.etree.ElementTree
zipfileDependencies pt.3
import boto3
import numpy
import pandas
print('boto3', boto3.__version__)
print('numpy', numpy.__version__)
print('pandas', pandas.__version__)boto3 1.9.203
numpy 1.16.2
pandas 0.24.2Dependencies pt.4
Traceback (most recent call last):
File "/tmp/runscript.py", line 117, in <module>
download_and_install(args.extra_py_files)
File "/tmp/runscript.py", line 56, in download_and_install
download_from_s3(s3_file_path, local_file_path)
File "/tmp/runscript.py", line 81, in download_from_s3
s3.download_file(bucket_name, s3_key, new_file_path)
File "/usr/local/lib/python3.6/site-packages/boto3/s3/inject.py", line 172, in download_file
extra_args=ExtraArgs, callback=Callback)
File "/usr/local/lib/python3.6/site-packages/boto3/s3/transfer.py", line 307, in download_file
future.result()
File "/usr/local/lib/python3.6/site-packages/s3transfer/futures.py", line 106, in result
return self._coordinator.result()
File "/usr/local/lib/python3.6/site-packages/s3transfer/futures.py", line 265, in result
raise self._exception
File "/usr/local/lib/python3.6/site-packages/s3transfer/tasks.py", line 255, in _main
self._submit(transfer_future=transfer_future, **kwargs)
File "/usr/local/lib/python3.6/site-packages/s3transfer/download.py", line 345, in _submit
**transfer_future.meta.call_args.extra_args
File "/usr/local/lib/python3.6/site-packages/botocore/client.py", line 357, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/usr/local/lib/python3.6/site-packages/botocore/client.py", line 661, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.exceptions.ClientError: An error occurred (404) when calling the HeadObject operation: Not FoundPySpark jobs
/tmp
├── pkg1
│ └── __init__.py
└── pkg2
└── __init__.pyjob workspace
pkg2/
pkg2/__init__.py
pkg1/
pkg1/__init__.pydependencies.zip
PYTHONPATH
spark-submit
spark-submit --py-files
Python Shell jobs
numpy-1.19.0-cp36-cp36m-manylinux2010_x86_64.whl
pandas-1.0.5-cp36-cp36m-manylinux1_x86_64.whldependencies
s3://bucket/prefix/numpy-1.19.0-cp36-cp36m-manylinux2010_x86_64.whl
s3://bucket/prefix/pandas-1.0.5-cp36-cp36m-manylinux1_x86_64.whlpip install numpy-1.19.0-cp36-cp36m-manylinux2010_x86_64.whl
pip install pandas-1.0.5-cp36-cp36m-manylinux1_x86_64.whl/tmp/runscript.py
Python Shell jobs
import subprocess
import runpy
import sys
import tempfile
import boto3
import argparse
import os
from urllib.parse import urlparse
from importlib import reload
from setuptools.command import easy_install
import site
import logging as log
from pathlib import Path
##TODO: add basic unittest Let's start coding
from awsglue.dynamicframe import DynamicFrame, DynamicFrameReader, ...
from awsglue.utils import getResolvedOptionsJob code structure
raw_to_refined/
├── Makefile
├── config.py
├── raw_to_refined.py
└── requirements.txtJob code - Makefile
mkdir -p $(BUILD_DIR)
pip install wheel
cp config.py $(BUILD_DIR)
# specific to python Shell Jobs
pip wheel -w $(BUILD_DIR) -r requirements.txt --no-deps
# specific to PySpark jobs
pip install -t $(BUILD_DIR) -r requirements.txt1. package
2. upload-job
3. upload-dependencies
aws s3 cp $(TRANSITION_STATE_PY) s3://bucket/code/$(JOB_NAME)/$(TRANSITION_STATE)/$(TRANSITION_STATE_PY)aws s3 sync --delete $(BUILD_DIR) s3://your-awsglue-bucket/code/$(JOB_NAME)/$(TRANSITION_STATE)/dependenciesraw_to_refined/
├── Makefile
├── config.py
├── raw_to_refined.py
└── requirements.txtJob code - config.py
raw_to_refined/
├── Makefile
├── config.py
├── raw_to_refined.py
└── requirements.txtimport logging.config
import sys
from glue_shared import parse_args
from glue_shared.defaults import default_logging_config
arguments = parse_args(sys.argv, ["APP_SETTINGS_ENVIRONMENT", "LOG_LEVEL"])
LOGGING_CONFIG = default_logging_config(arguments["LOG_LEVEL"])
logging.config.dictConfig(LOGGING_CONFIG)
JOB_CONFIG = dict(arguments)
# must be hard-coded because glue does not provide this in PyShell jobs
JOB_CONFIG["JOB_NAME"] = JOB_CONFIG.get("JOB_NAME") or "ds1-raw-to-refined"
JOB_CONFIG["JOB_ID"] = JOB_CONFIG.get("JOB_ID") or "ds1-raw-to-refined"
JOB_CONFIG["JOB_RUN_ID"] = JOB_CONFIG.get("JOB_RUN_ID") or "ds1-raw-to-refined"
JOB_CONFIG["WORKFLOW_NAME"] = JOB_CONFIG.get("WORKFLOW_NAME")
JOB_CONFIG["WORKFLOW_RUN_ID"] = JOB_CONFIG.get("WORKFLOW_RUN_ID")Job code - raw_to_refined.py
raw_to_refined/
├── Makefile
├── config.py
├── raw_to_refined.py
└── requirements.txtimport logging
import pandas as pd
from glue_shared.pandas_helpers import write_parquet
LOGGER = logging.getLogger("job")
def main():
LOGGER.info("JOB_NAME: %s", JOB_CONFIG["JOB_NAME"])
LOGGER.info("JOB_ID: %s", JOB_CONFIG["JOB_ID"])
LOGGER.info("JOB_RUN_ID %s", JOB_CONFIG["JOB_RUN_ID"])
LOGGER.info("WORKFLOW_NAME: %s", JOB_CONFIG["WORKFLOW_NAME"])
LOGGER.info("WORKFLOW_RUN_ID %s", JOB_CONFIG["WORKFLOW_RUN_ID"])
LOGGER.info("Reading raw data from %s", JOB_CONFIG["dataset_url"])
df = pd.read_csv(JOB_CONFIG["dataset_url"], sep=";")
write_parquet(df, f"s3://{JOB_CONFIG['s3_bucket']}/{JOB_CONFIG['s3_prefix']}")
if __name__ == "__main__":
from config import JOB_CONFIG
main()Job code - refined_to_curated.py
raw_to_refined/
├── Makefile
├── config.py
├── raw_to_refined.py
└── requirements.txtimport datetime
import logging
import pyspark
from glue_shared import get_spark_session_and_glue_job
from glue_shared.spark_helpers import read_parquet
LOGGER = logging.getLogger("job")
def run_etl(cfg, spark: pyspark.sql.SQLContext):
df = read_parquet(spark, f"s3://{cfg['s3_bucket']}/{cfg['s3_prefix']}")
LOGGER.debug("Count in: %s", df.count())
def main():
spark, job = get_spark_session_and_glue_job(JOB_CONFIG)
run_etl(JOB_CONFIG, spark)
if __name__ == "__main__":
from config import JOB_CONFIG
main()
Job arguments gotchas
No optional arguments (all arguments are required by default)
Different default arguments per runtime
[
"script_2020-06-24-07-06-36.py",
"--JOB_NAME", "my-pyspark-job",
"--JOB_ID", "j_dfbe1590b8a1429eb16a4a7883c0a99f1a47470d8d32531619babc5e283dffa7",
"--JOB_RUN_ID", "jr_59e400f5f1e77c8d600de86c2c86cefab9e66d8d64d3ae937169d766d3edce52",
"--job-bookmark-option", "job-bookmark-disable",
"--TempDir", "s3://aws-glue-temporary-<accountID>-us-east-1/admin"
]PySpark Job
[
"/tmp/glue-python-scripts-7pbpva1h/my_pyshell_job.py",
"--job-bookmark-option", "job-bookmark-disable",
"--scriptLocation", "s3://aws-glue-scripts-133919474178-us-east-1/my_pyshell_job.py",
"--job-language", "python"
]Python Shell Job
Logging
/aws-glue/python-jobs/output/jr_3c9c24f19d1d2d5f9114061b13d4e5c97881577c26bfc45b99089f2e1abe13ccstdout
/aws-glue/jobs/output
/aws-glue/python-jobs/outputstderr
/aws-glue/jobs/error
/aws-glue/python-jobs/errorLog group name
/aws-glue/<job-type>/<output type>/JOB_RUN_ID
Gotcha
Do not log to stderr - creation is not guaranteed
Reusing your code
glue_shared_lib
├── Makefile
├── requirements-dev.txt
├── setup.py
├── src
│ └── glue_shared
│ └── __init__.py
│ ├── argument_handlers.py
│ ├── boto3_helpers.py
│ ├── defaults.py
│ ├── glue_interface.py
│ ├── pandas_helpers.py
│ ├── spark_helpers.py
└── tests
└── __init__.py
PySpark - .py, .zip, Python Shell - .egg, .whlGlue workflow

Glue workflow
DefaultArguments
--WORKFLOW_NAME=my-workflow
--WORKFLOW_RUN_ID=wr_1e927676cc826831704712dc067b464800....Workflow Run Properties
glue_client = boto3.client("glue")
args = getResolvedOptions(sys.argv, ['JOB_NAME','WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
workflow_params = glue_client.get_workflow_run_properties(Name=workflow_name,
RunId=workflow_run_id)["RunProperties"]Automated deployment
Ensure existing S3 bucket
packaging and upload of jobs and dependencies
Requirement to have a list of dependencies in multiple formats
Automated deployment
Workflow definition in text form is not pretty

Automated deployment
---
Resources:
StartRawToRefinedTrigger:
Type: AWS::Glue::Trigger
Properties:
Actions:
- JobName: "job1"
Description: Start raw to refined jobs
Name: start-raw-to-refined
Type: ON_DEMAND
StartOnCreation: 'false'
WorkflowName: etl-workflow
Tags:
terraform: 'true'
StartRefinedToCuratedTrigger:
Type: AWS::Glue::Trigger
Properties:
Actions:
- JobName: "job2"
Description: Start refined to curated jobs
Name: start-refined-to-curated
Type: CONDITIONAL
StartOnCreation: 'true'
Predicate:
Conditions:
- LogicalOperator: EQUALS
JobName: "job1"
State: SUCCEEDED
Logical: AND
WorkflowName: etl-workflow
Tags:
terraform: 'true'
Automated deployment
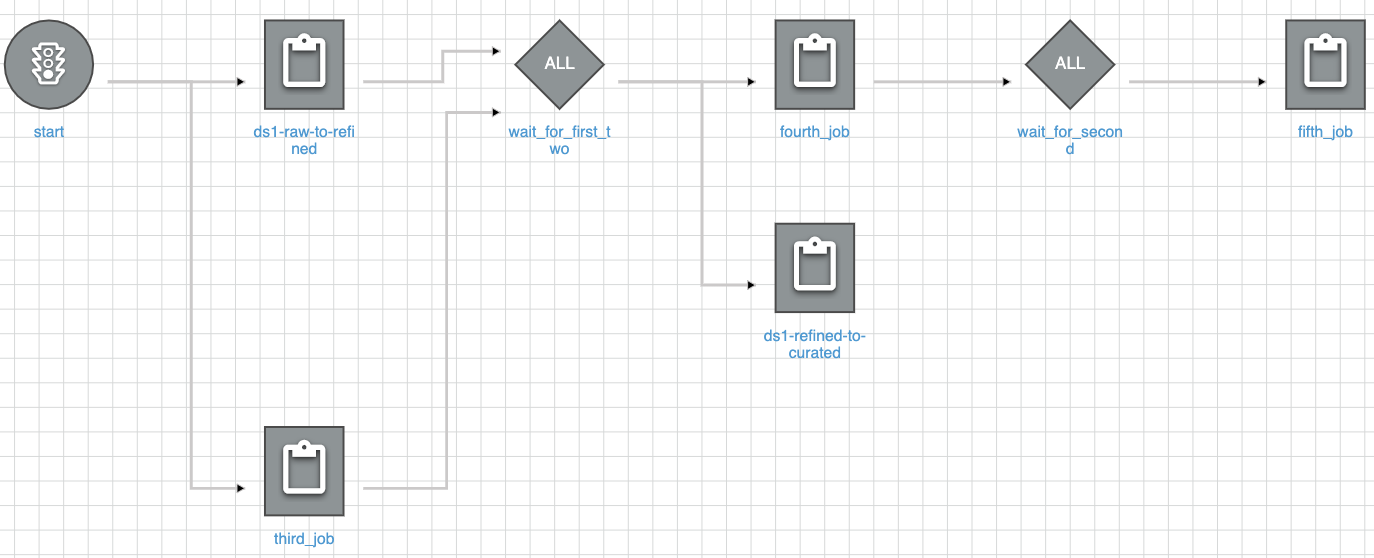
Automated deployment
resource "aws_glue_trigger" "start" {
name = "start"
type = "ON_DEMAND"
workflow_name = module.glue.workflow_name
actions {
job_name = module.ds1_raw_to_refined_job.job_name
}
actions {
job_name = module.third_job.job_name
}
}
resource "aws_glue_trigger" "wait_for_first" {
name = "wait_for_first_two"
type = "CONDITIONAL"
workflow_name = module.glue.workflow_name
actions {
job_name = module.ds1_refined_to_curated_job.job_name
}
predicate {
conditions {
job_name = module.ds1_raw_to_refined_job.job_name
state = "SUCCEEDED"
}
conditions {
job_name = module.third_job.job_name
state = "SUCCEEDED"
}
}
}
resource "aws_glue_trigger" "wait_for_second" {
name = "wait_for_second"
type = "CONDITIONAL"
workflow_name = module.glue.workflow_name
actions {
job_name = module.fifth_job.job_name
}
predicate {
conditions {
job_name = module.fourth_job.job_name
state = "SUCCEEDED"
}
}
}
And that's all folks

PyAmsterdam
info@py.amsterdam
AWS Glue PyAmsterdam
By oglop zelgo


