Robotic Grasping of Novel Objects using Vision
Ashutosh Saxena, Justin Driemeyer, Andrew Y. Ng
Okan Yıldıran - 2015700153
Justin Driemeyer
Ashutosh Saxena
Andrew Y. Ng



PhD, Machine Learning, Stanford University with Andrew Y. Ng (advisor), Sebastian Thrun and Stephen Boyd.
Lots of awards.
Co-founded several companies.
MS, Computer Science - AI, Stanford University
Director of Engineering at Zynga until 2014
Chief Scientist of Baidu
Chairman and Co-founder of Coursera
Associate Professor (Research) of Stanford.
Founder of “Google Brain”
Authors
Introduction
In this paper they solved the problem of grasping novel objects by using 2D images.
We present a learning algorithm
that neither requires, nor tries to build, a 3-d model
of the object.

Grasping Point
For most of the objects, there is a small region that selected by humans as grasping point.
So, error is defined by how close our algorithm finds grasping point to that small region.

Data Generation
Instead of collecting real-world data, they generated a huge data-set that is automatically labeled in different lightning conditions, positions and with randomized features like colors and scales.



Feature Extraction
Divide image into small patches and try to estimate if it is grasping point or not.
For each patch look for edges, textures and color.

Feature Extraction
Convert image to YCbCr color space.
- Y - Intensity Channel
- Apply 6 Edge filters
- Apply 9 Laws' masks
- Cb and Cr - Color channel
- Apply Averaging filter
For each patch = 17 features


Feature Extraction
Also use different spatial scales (3 in paper)
For each patch
17 * 3 = 54 features
In a 5x5 window, compute neighbors
For each patch
= 17 * 3 + 24 * 17
= 459 features

Probabilistic Model
- Image is taken from slightly different angle due to small positioning error.
- They modeled this error with Gaussian.
- Then they used logistic regression to model grasping points.
- The parameter of this model θ ∈ R^459 is learned
using standard maximum likelihood for logistic regression - Given two or more images, they triangulated and computed 3d position of the point

Optimization
Their algorithm calculates every possible cell grasp performance which is extremely inefficient
(over 110 seconds)
Instead they only computed places close to possible grasping points by 3σ
(about 1 second)
Robot Platforms
5-dof

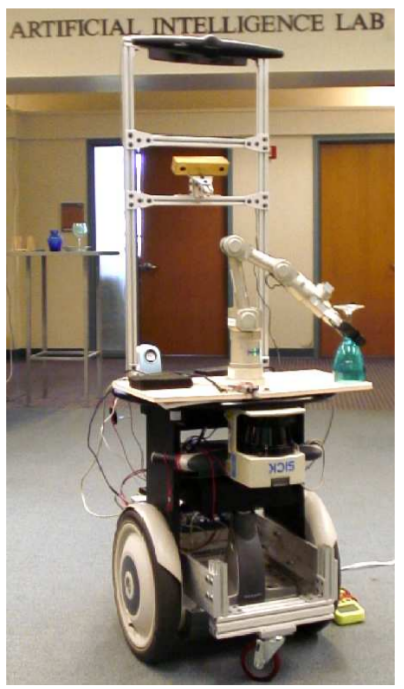
7-dof
Experiment 1: Synthetic data
The average accuracy for classifying whether a 2-d image patch is a projection of a grasping point was 94.2%
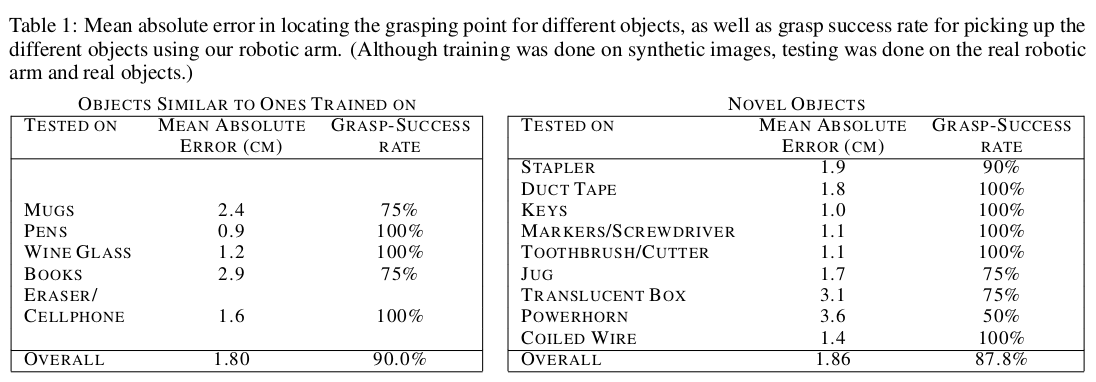
Experiment 2: Grasping novel objects
Training was performed on synthetic images.
Test with real world objects with 5-dof robot.
Experiment 3:
Unloading items from dishwashers
Achieved an average grasping success rate of 80.0% in a total of 20 trials

Experiment 4:
Grasping kitchen and office objects
They studied how they can use information about object type and location to improve the performance of the grasping algorithm.

Experiment 5:
Grasping using 7-dof arm
7-dof robotic platform that is more capable manipulator showed improvement over grasping objects such as bowls.

Conclusions
We proposed an algorithm for enabling a robot to grasp an object that it has never seen before. Our learning algorithm neither tries to build, nor requires, a 3-d model of the object.
Thank you
Robotic Grasping of Novel Objects using Vision
By Okan Yildiran
Robotic Grasping of Novel Objects using Vision
Paper Presentation


