DDIA 讀書會
第二章:資料模型與查詢語言
各種 Data Model 都有其獨特的性質與優缺點,開發者應該要能夠為各種情境的應用挑選正確的資料模型
探討三個主流的 Data Model: Relational Model、Document Model、Graph Model 各自的優缺點、演進史與使用時機。
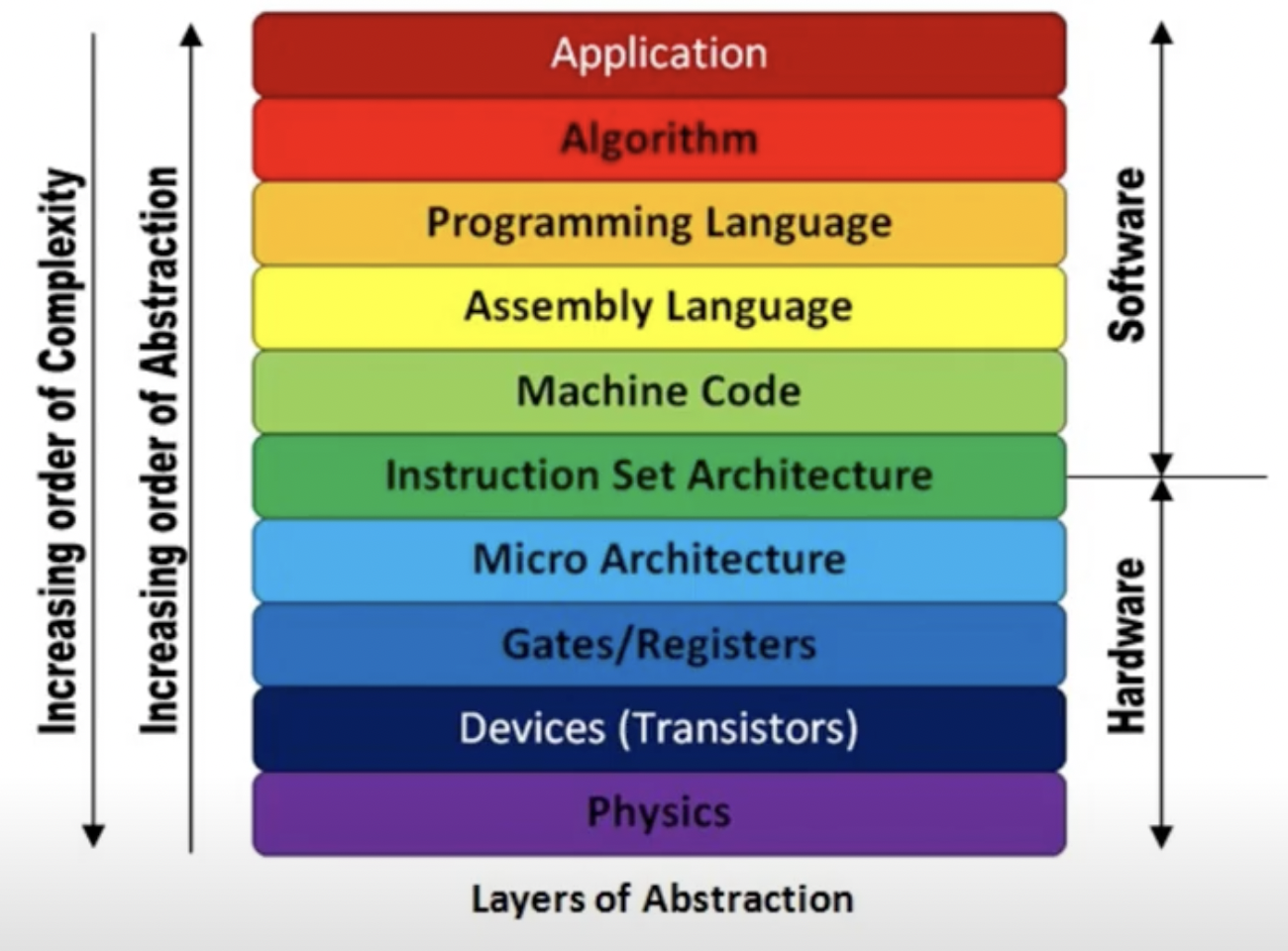
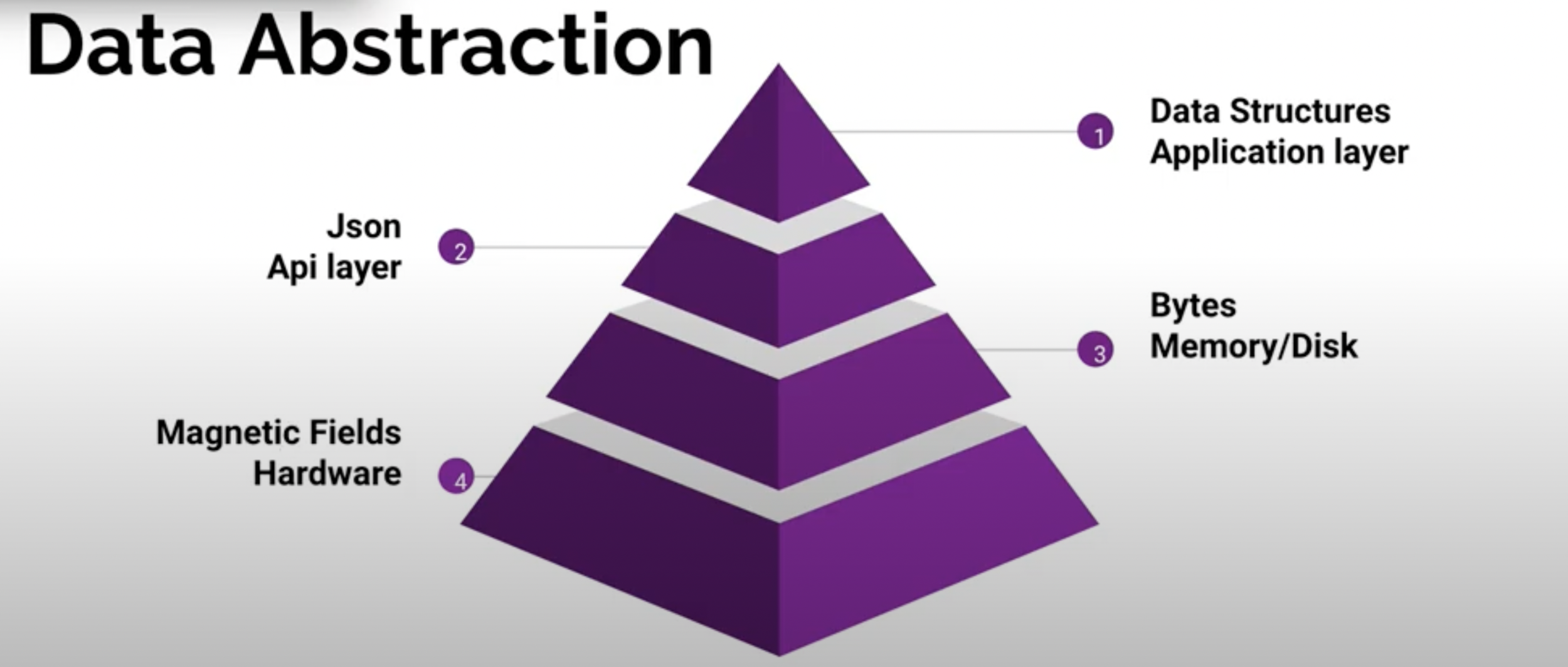
1. 應用層,資料代表現實中的資訊,like object oriented
2. XML, JSON 或關聯式資料庫的 Tables 等易於儲存的資料結構
3. 在資料庫中,上一層的 XML, JSON 都需要轉換成 bytes 的形式,才能被存在 memory 或 disk 上
4. Hardware 層級, bytes 必須被轉換成電流、磁場
層級之間定義好 API,透過 API 來溝通,將複雜實作藏於 API 之後
Relational Model 於 1970 年被提出,當時與其競爭的有 Hierarchical Model 與 Network Model,後來之所以脫穎而出主要有兩個原因:
1. 它將理應很複雜的 query 實作藏在 database 的 query optimizer 中,提供使用者簡單的 interface,使用者不用知道資料是如何被存在資料庫中或是如何被取出的
2. 多對多關聯
關係模型與文件模型
NoSQL 的誕生
1. 處理更大數據集:更強伸縮性、更高吞吐量
2. 支援一些關聯式資料庫不支援的操作
3. 更自由、更彈性:Relational Model 約束太嚴,限制太多
Probrem with Relational Model : Object Relational Mismatch
object -> table
ORM (Object Relational Mapping)
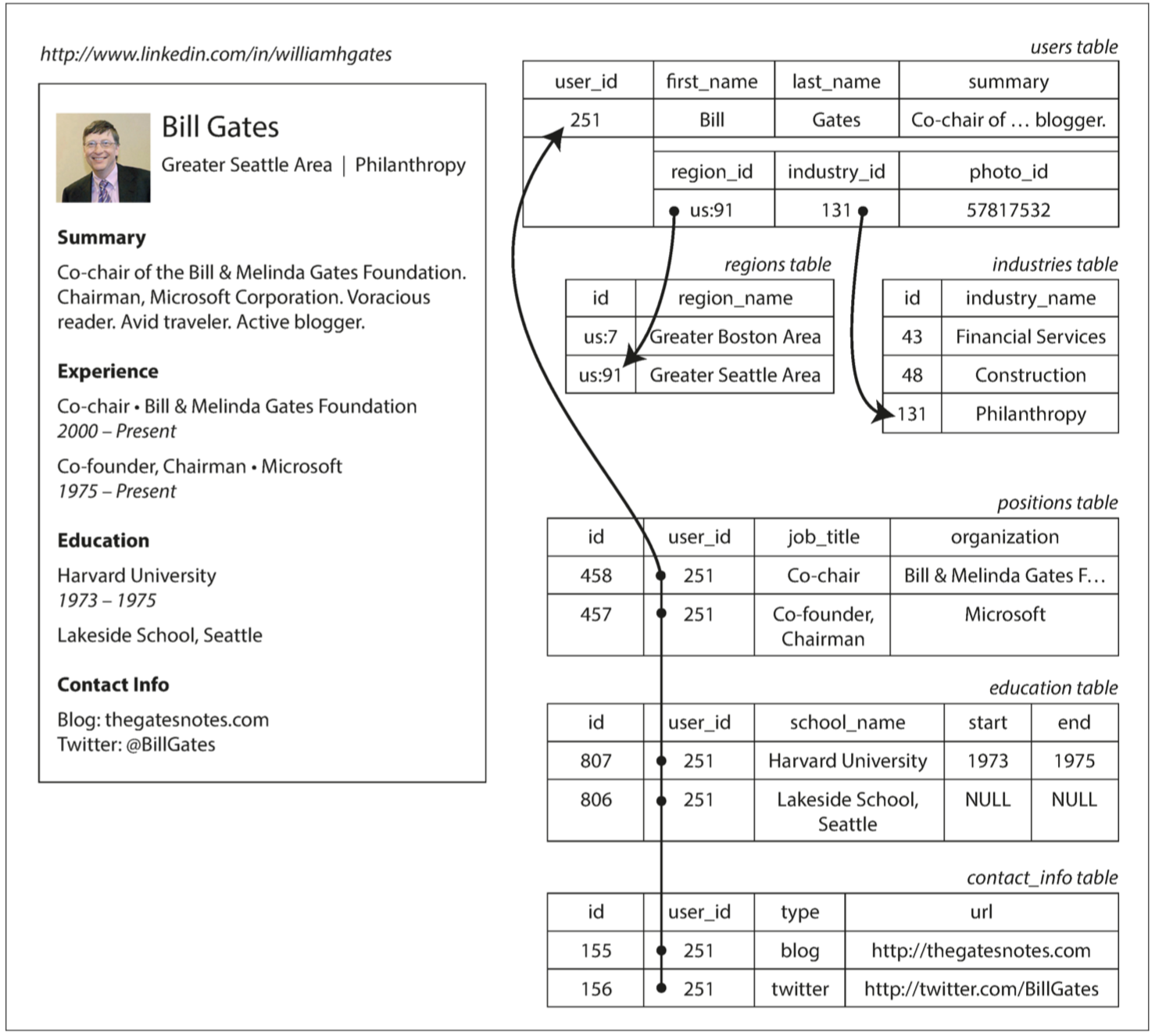
一個使用者可能有多個工作、學歷、甚至是聯絡資料, How ?
- 將工作、學歷、聯絡資料放到另一張 table 來儲存,這也是最常見的資料庫正規化方式
- 一些關聯式資料庫支援 Array 或是 JSON, XML 等儲存格式,例如 PostgreSQL。
- 直接將 JSON 或是 XML 格式編碼成 bytes 再儲存進資料庫的一個欄位。
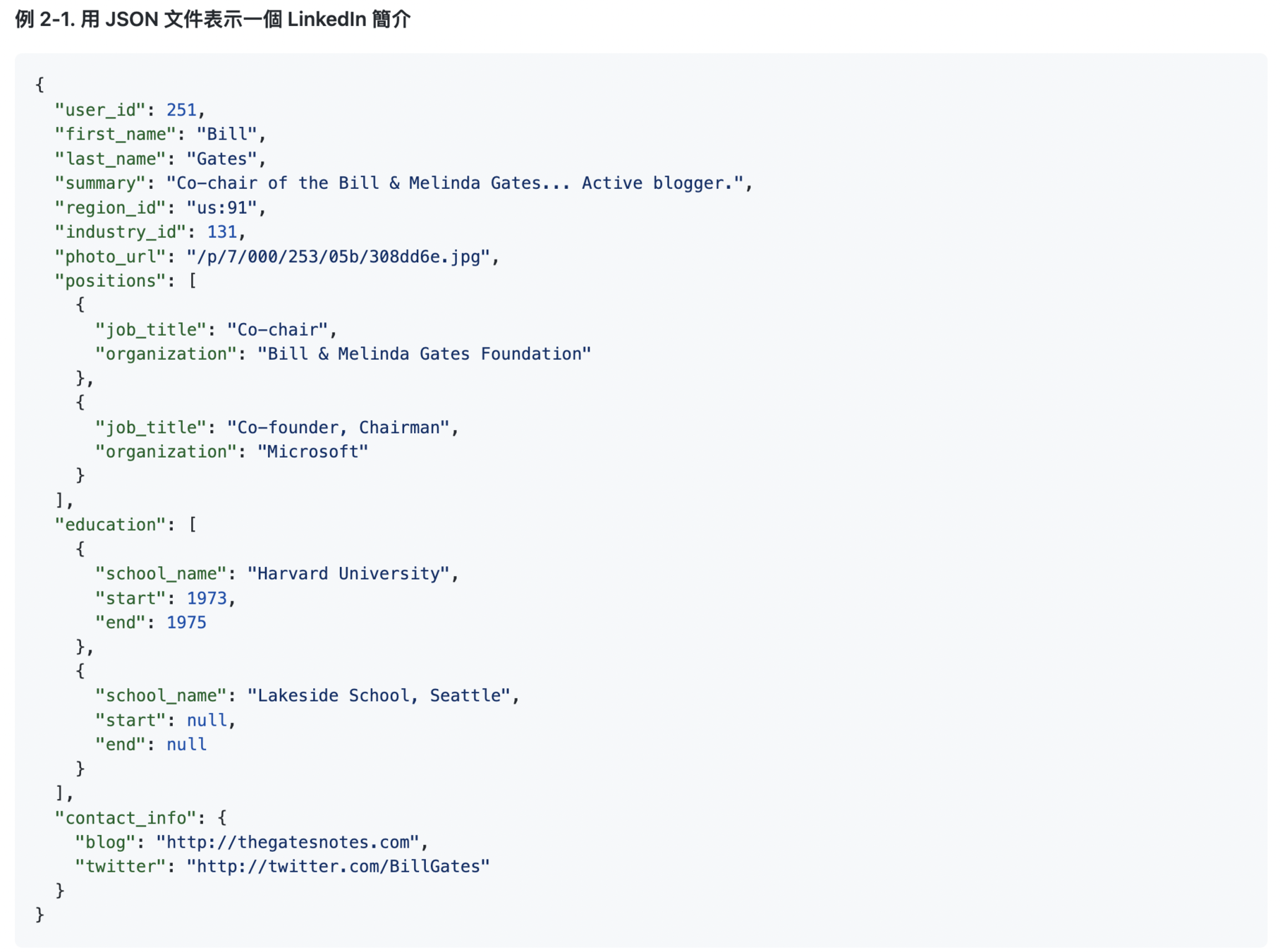
JSON 格式有更好的 locality (局部性),使用 Relational Model 必須使用多次的 Join 來關聯多個資料庫,而 JSON 中所有與此使用者相關的資訊都儲存在一起,簡單的 query 就能完成。
上面的 JSON 中 region 與 industry 都只儲存了一個 ID,而不是直接儲存字串,這樣做有幾個好處:

Duplication & Normalization & Denormalization
多對一
Relational Model -> Unique ID + Join
Document Model ->
1. 直接儲存 ex: JSON 中的 Array (denormalization,比較適合用在很少被更改的資料,因為 denormalization 會使得 update, delete 的操作變得更複雜與更沒效率)
2. 在應用層自己模擬 Join 操作(document model 通常不支援 join)
Which to choose today ?

Schemaless in document model
Schema on read : 資料的格式是隱藏、不需預先定義的,在讀出時才決定他的格式(反過來則是 schema-on-write,傳統的關係資料庫方法中,模式明確,且資料庫確保所有的資料都符合其模式)
name -> first_name, last_name
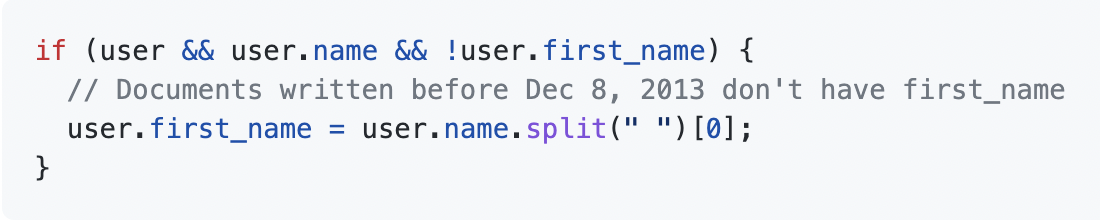

document
relational (need migration)

資料查詢語言
宣告式 (Declarative) vs 命令式 (Imperative)
SQL, CSS
SELECT * FROM animals WHERE family ='Sharks';
vs
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}MapReduce
混合宣告式與命令式,由google 提出的在多臺機器上批次處理大規模的資料的一種模式 (延伸閱讀)
db.observations.mapReduce(
function map() { // 2. 對所有符合條件 doc 執行 map
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals); // 3. 輸出一個 kv pair
},
function reduce(key, values) { // 4. 按 key 聚集
return Array.sum(values); // 5. 相同 key 加和
},
{
query: { family: "Sharks" }, // 1. 篩選
out: "monthlySharkReport" // 6. reduce 結果集
}
);MongoDB Aggregate
因為 MapReduce 需要使用者自己小心的撰寫 Javascript 程式碼,雖然可以做到很複雜的操作,但對於簡單的操作來說,還是 declarative language 更適合作為資料庫的查詢語言。
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{
$group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}
}
]);Graph Data Model
當資料庫有很多的多對多關聯,就很適合使用 graph-like data model
- Social Graph
- Web Ranking
包含點與邊,每個點與邊也可以代表不同意義,例如 Facebook 的 social graph,其中 點可能是人、地點、事件或是留言,而邊可能代表人參加的事件、事件發生的地點或是人留下的留言。
Graph Data Model
- Property Graph Model 屬性圖
- Triple Store Model 三元組儲存
Property Graph

Cypher Query Language


Cypher 是屬性圖的宣告式查詢語言,為 Neo4j 圖形資料庫而發明
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
() 代表點、[] 代表邊、: 代表邊或是點的 label、{} 內的代表 properties、-> 代表邊的方向。SQL 中的圖查詢
在 Cypher 中,用 WITHIN*0.. “沿著 WITHIN 邊,零次或多次”。它很像正則表示式中的 * 運算子。但在 SQL 中,不知道要 join 的次數

Triple Store Model
Triple Stores 透過三元組 (subject, predicate, object) 來儲存資料,ex (KK, likes, Parker),也可以描述 subject 的屬性,ex (KK, gender, female)。對應到圖形,subject 是點、predicate 是邊,而 object 可以是點也可以是值。

SPARQL query language
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}Q&A Contest
1. IBM 的資訊管理系統(IMS)使用了哪種資料模型?

2. 基因資料庫使用了哪種資料模型?

3. 哪種資料模型也被稱為 CODASYL 模型?

4. 在三元組儲存中,所有資訊都以哪三部分表示形式儲存?

5. 何者為查詢語言先驅?

6. 以下何者沒有 declarative query language ?

「語言的邊界就是思想的邊界。」這句話是誰說的?
DDIA 第一
By oldmo860617




