
Research Guild Meeting
Interlude
NMT on mobile and in browser
- Does not require internet connection
- Low latency
- Savings on infrastructure (no need in servers!)
- Can be used against us
- Model's speed
- Model's size
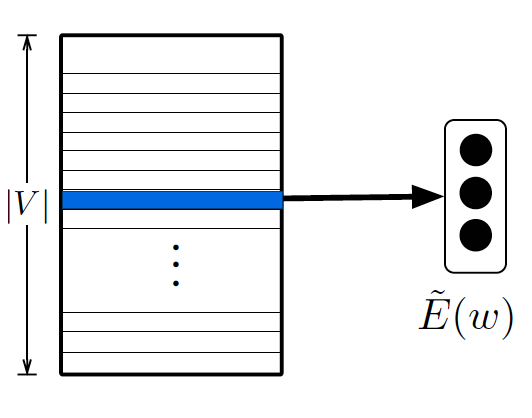
Embeddings are large!
160Mb for 80,000 words
(d=500)
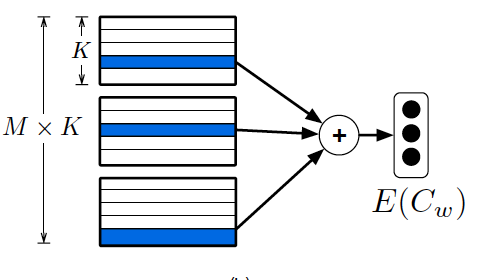
Compositional coding
C_{\text{dog}}=(3,2,4)
Compositional coding
C_{\text{dog}}=(3,2,4)
Compositional coding
C_{\text{dog}}=(3,2,4)
C_{\text{dogs}}=(3,2,3)
Compositional coding
C_{\text{dog}}=(3,2,4)
C_{\text{dogs}}=(3,2,3)
Compositional coding
C_{\text{dog}}=(3,2,4)
C_{\text{dogs}}=(3,2,3)
1. Find optimal codebooks
2. Find optimal codes
Goals:
Training end-to-end
Compositional coding
E(C_w) = \sum^M_{i=1}{A_i^\top d_w^i}
$$d_w^i$$
is one-hot encoded vector
Model architecture
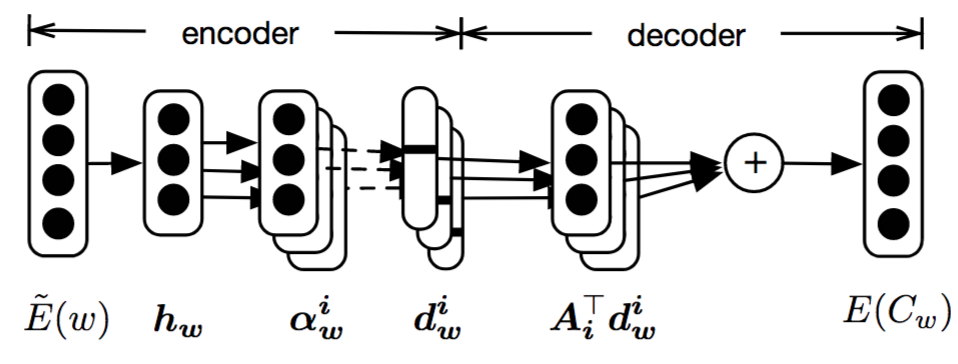
Predict
codes
Predict
codebooks
Original
embedding
Reconstructed
embedding
Model architecture
How to back-propagate through
discrete one-hot?
Gumbel-softmax trick!
Results

Machine Translation
Machine Translation

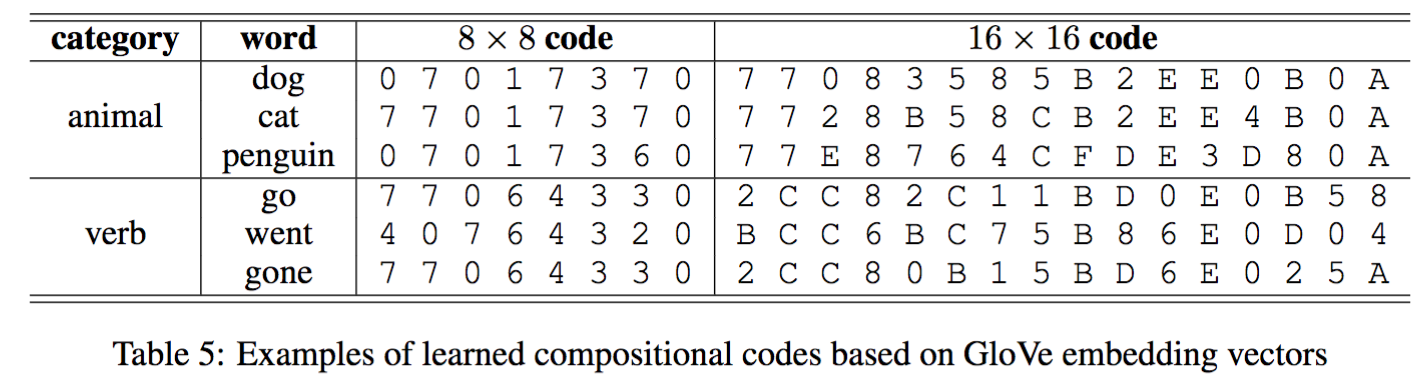
Examples
Conclusions
- 94% to 99% compression rate
- BLEU improved (compression as regularization)
- Nice example of Gumbel-softmax trick
- Can help interpretability
Questions?
Compressing Word Embeddings
By Oleksiy Syvokon



