Title Text


@DataOskar@datasci.social
@DataOskar


Si tienes una cuenta de Google, existe un registro histórico de todas tus ubicaciones.
Aunque nunca hayas tenido la localización activada.
Si has usado una red Wifi o has encendido los datos móviles, existe ese registro.
Este es un extracto del mío.
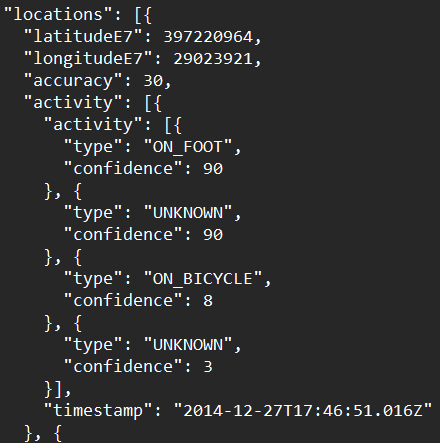
Lo descargué hace un año y medio.
Vosotros si queréis podéis descargar el vuestro.
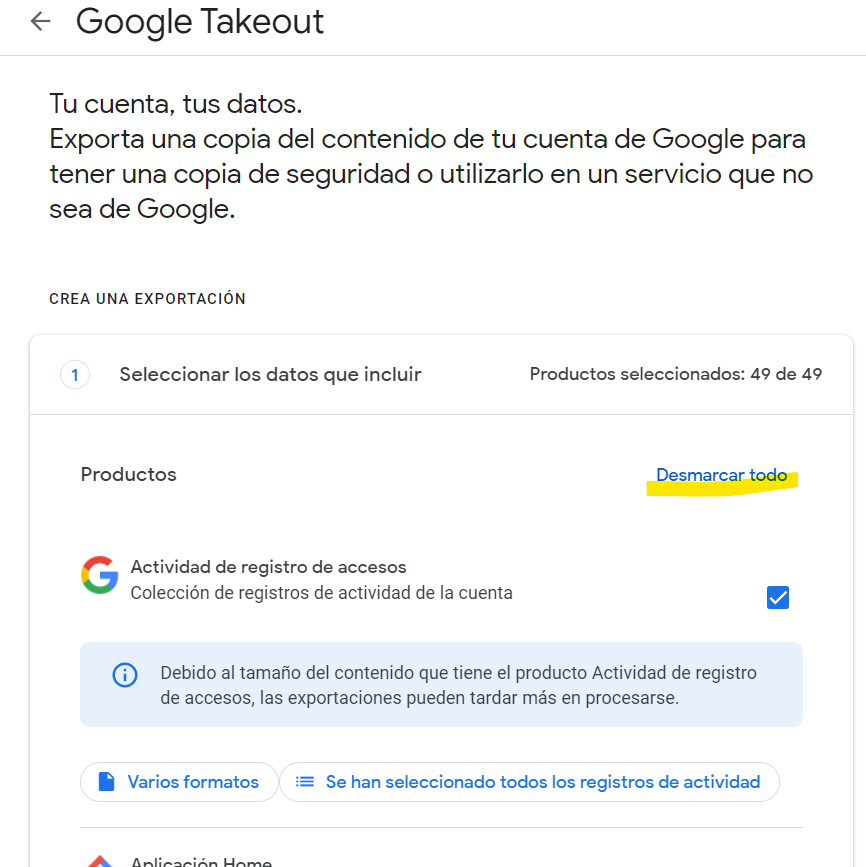
https://takeout.google.com/

Yo me lo descargué para este proyecto.
Y con el motivo de la Festa OpenSource Girona 2023, he convertido el proyecto en un repositorio Open Source con el que cualquiera podríais replicarlo sin apenas esfuerzo.
Pero primero, permitidme contaros la historia que dió sentido al proyecto.

Ella es Aina y nos conocimos (oficialmente) el 6 de Junio de 2021.
Y desde casi el primer día, me repetía una frase:
"Me suenas"
Ella creía que nos habíamos visto antes.
Y tenía sentido.
Los dos vivimos en Inca, Mallorca.
De niños, los dos veraneábamos en Alcudia.
Además, los dos fuimos a la universidad en Cataluña: ella en Barcelona y yo en Sabadell.
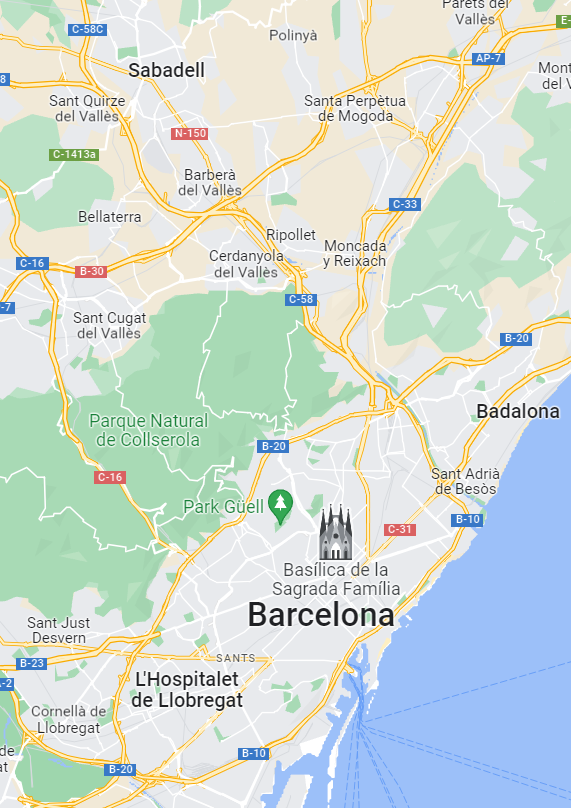
Y, por eso, tenía sentido.
Quizá en algún momento coincidimos en espacio y tiempo.
Me puse manos a la obra.
Primero, como buen Junior Data Scientist, desarrollé el proyecto en un Jupyter Notebook que nadie, a parte de mi yo del pasado, entendía ni era capaz de replicar.
Ahora, que ya tengo algo más de experiencia, lo he rehecho usando Kedro.
Si no conocéis Kedro:
- Es un framework para desarrollar código de Ciencia de Datos de una forma limpia y estructurada.
- Estandariza la creación de código para este tipo de proyectos.
- Es Open Source y los proyectos en Kedro son fácilmente llevados a producción.
- Maneja la complejidad y facilita la colaboración entre equipos.
- Incluye, por defecto, visualización de pipelines, catálogo de datos, templates de proyectos, experiment tracking...
Si no conocéis Kedro:
- Es un framework para desarrollar código de Ciencia de Datos de una forma limpia y estructurada.
- Estandariza la creación de código para este tipo de proyectos.
- Es open source y los proyectos en Kedro son fácilmente llevados a producción.
- Maneja la complejidad y facilita la colaboración entre equipos.
- Incluye, por defecto, visualización de pipelines, catálogo de datos, templates de proyectos, etc.

Kedro
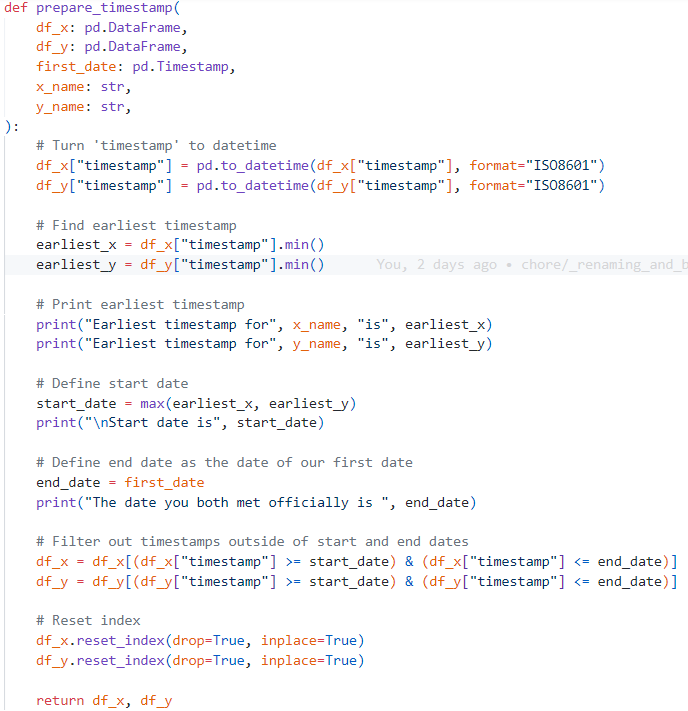
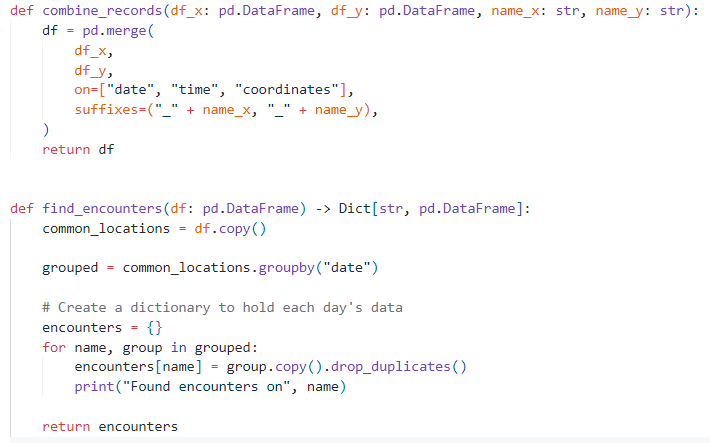
En cuanto a Kedro, este proyecto es muy simple.
Tiene 3 entradas en el catalog (un archivo que indica dónde se definen los datos que entran o salen).
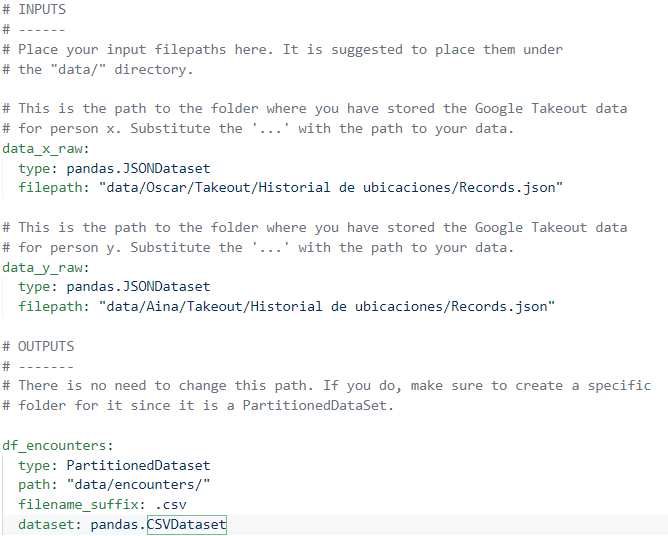
Tiene 5 parámetros (archivo dónde el usuario puede configurar variables para modificar el comportamiento del pipeline sin modificar el código)

Tiene una sola pipeline (pasos ordenados que transforman los datos de un punto inicial a un punto final).

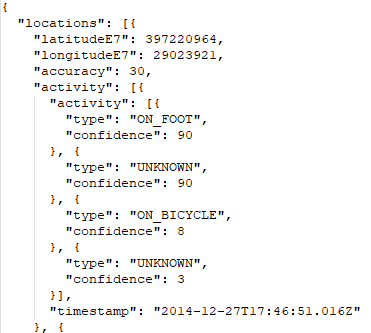
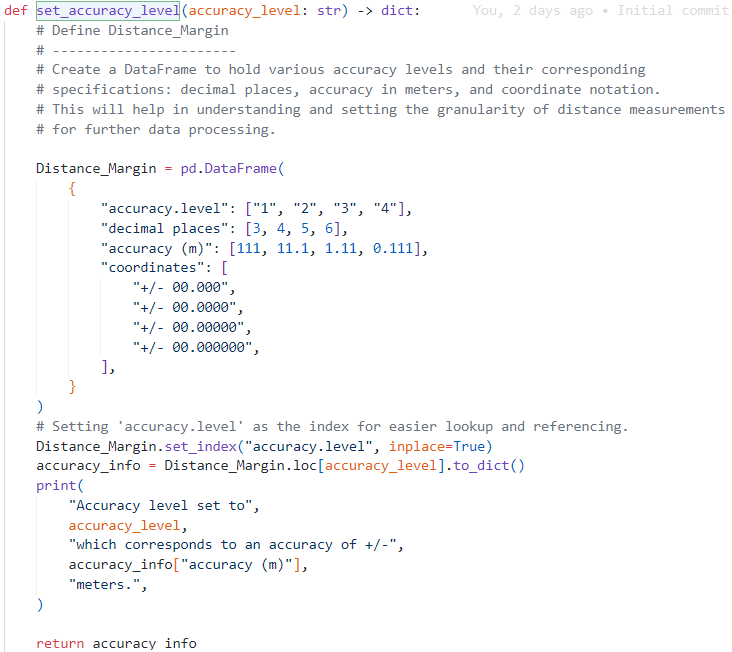
Vamos a ver qué hace la pipeline mirando a sus nodos (o más bien, a las funciones detrás de esos nodos)




¿Pero Aina y tu coincidisteis o no?


31 de marzo de 2018
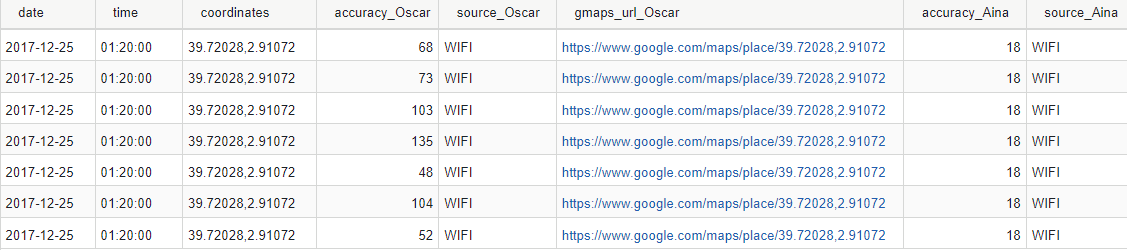
Coincidimos, pero solo hay un registro.
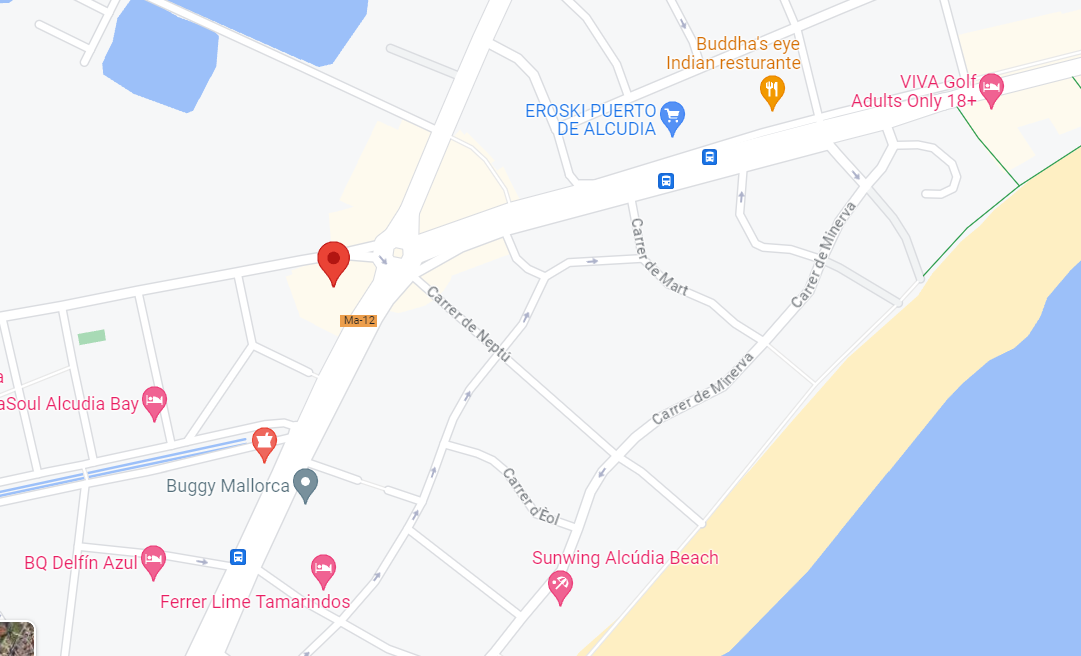

25 de diciembre de 2017
28 de diciembre de 2017

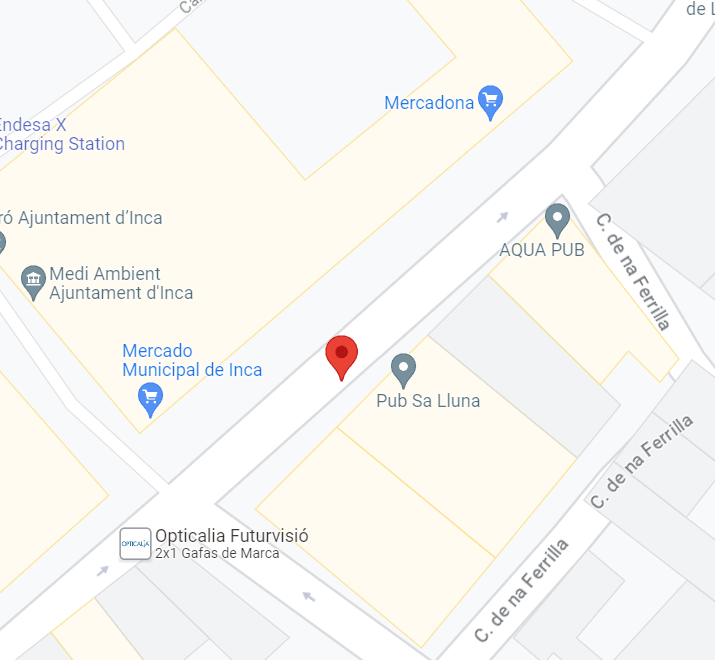


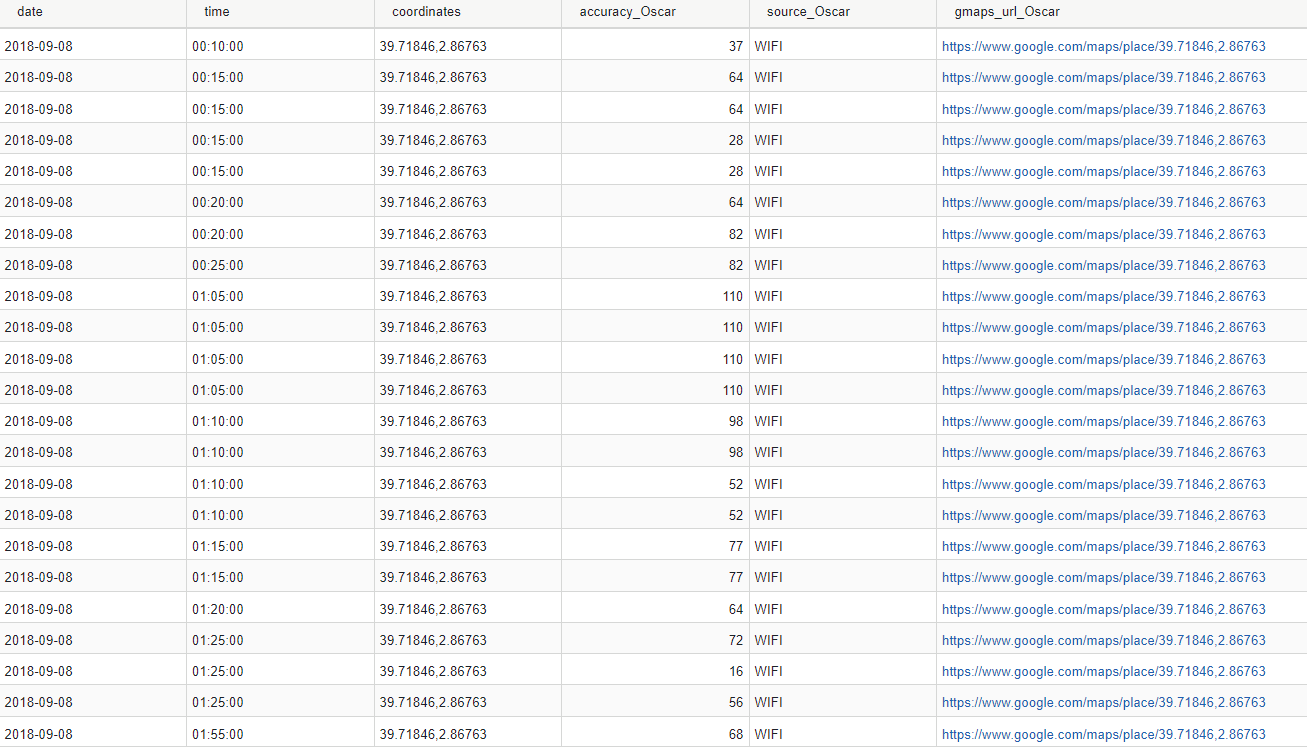
8 de septiembre de 2018
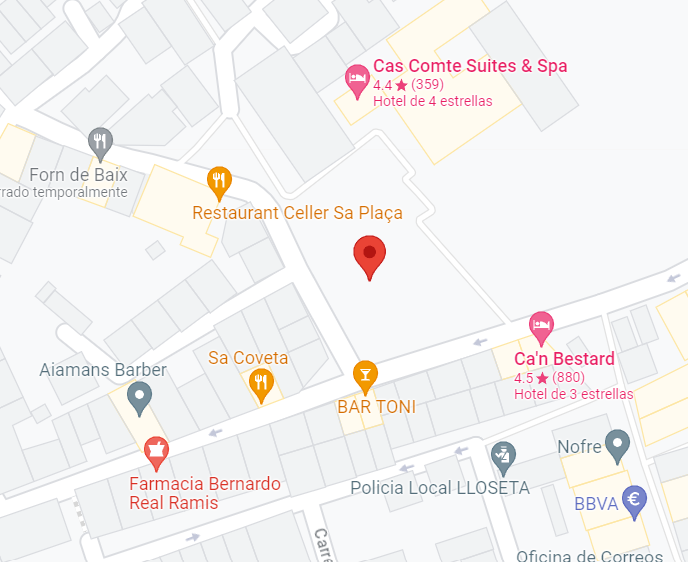



Si queréis probar a ver si habéis coincidido con alguien, aquí teneis el repo.
Y por supuesto cualquier contribución será bien recibida!

https://github.com/OscarTienda/mesuenas
@DataOskar@datasci.social
@DataOskar
¡Muchas gracias!
Me_suenas
By Óscar Tienda Beteta