by Pär Eriksson
Presentation
Introduction
What will be discussed
1. Main Problems/Challanges
2. How to solve them
3. Implementation suggestion
4. DEMO
5. What else can we gain/provide
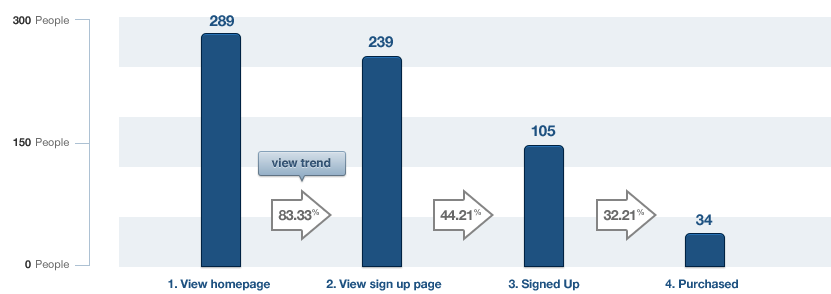
A funnel example of user actions
Main Problems/Challanges
- Use case?
- What to measure?
- Should everything be up to the customer?
- What is needed, besides the logged event?
- Isolate the sessions (not up to me)?
- Storage concerns, especially at scale.
- Could events be pre aggregated? (if so, is it worth loosing the dimensionality)
- How should the data be modelled
- How high will the operations/sec be?
(General)
(Practical)
Main Problems/Challanges
How high will the operations/second be?
What kind of operation?
Read or Write?
Probably both!
Well, it matters!!
Main Problems/Challanges
Writes/second
(main concern)
The write operation ratio increases with the number of users.
Main Problems/Challanges
Reads/second
(2nd concern)

Even though the read/write ratio is low, the reads/second should be considered.
Main Problems/Challanges
Sounds like we need the best of two worlds
Denormalization
But how?
How to solve them
Sounds like we can use MongoDB for this!?
The knowledge exists within the company!
Yes but..
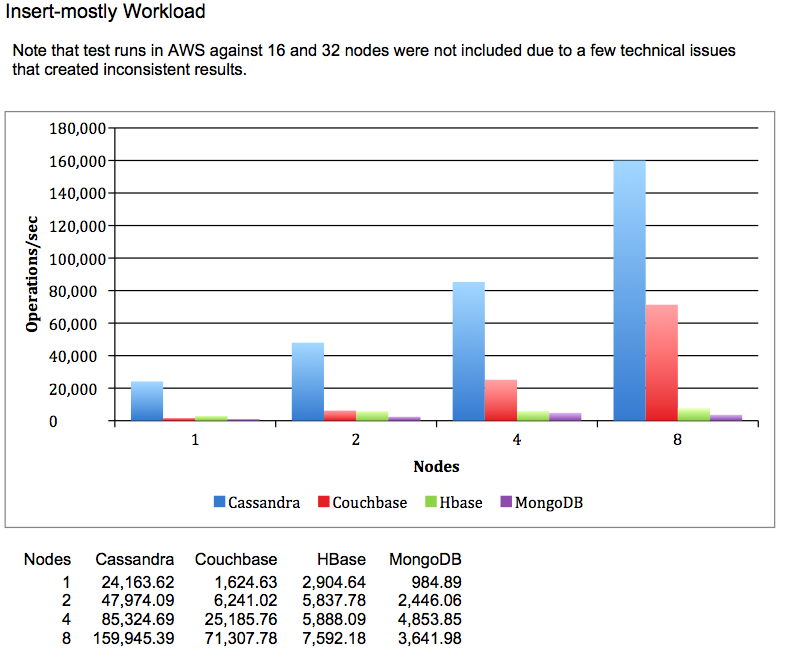
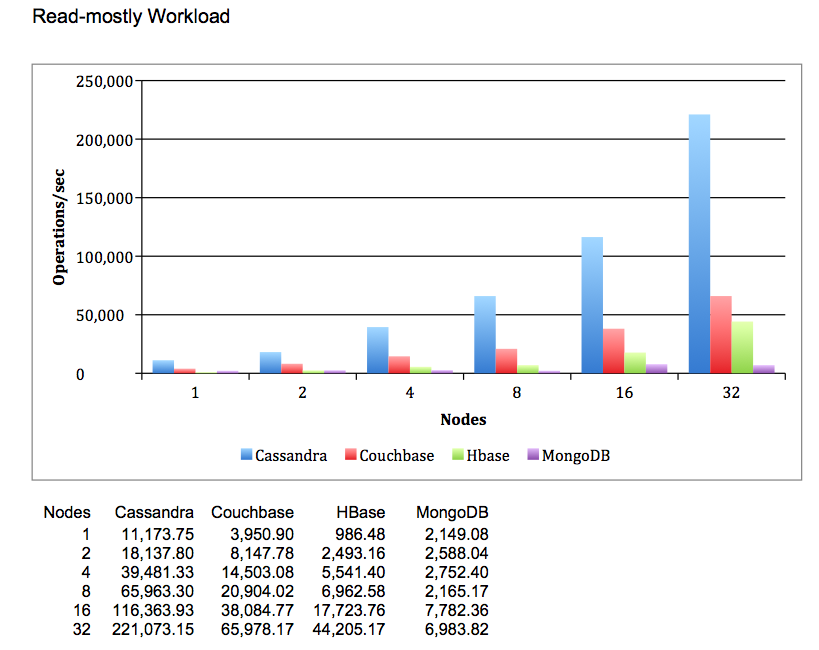
"Benchmarking Top NoSQL Databases Apache Cassandra, Couchbase, HBase, and MongoDB", by End Point 13/04-15
How to solve them
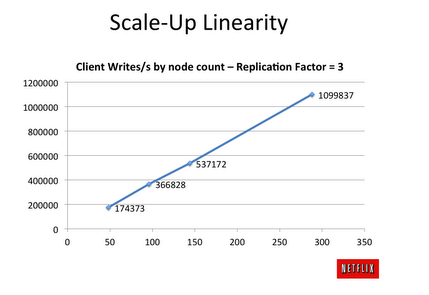
",,those blue bars look promising"

Implementation suggestion
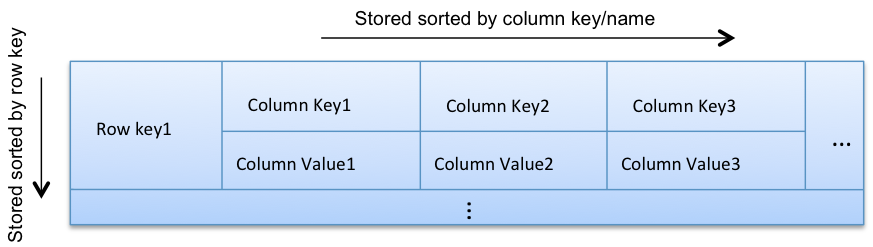
The incoming data is mainly events that are based on time
This suits the Cassandra data model (if sorted by time)
CREATE TABLE IF NOT EXISTS raw_user_ab_logs (
application text,
start_time text,
timestamp timestamp,
event text,
user_id text,
group text,
PRIMARY KEY (
(application, start_time, group),
timestamp, user_id
)
) WITH CLUSTERING ORDER BY (timestamp DESC);
Implementation suggestion
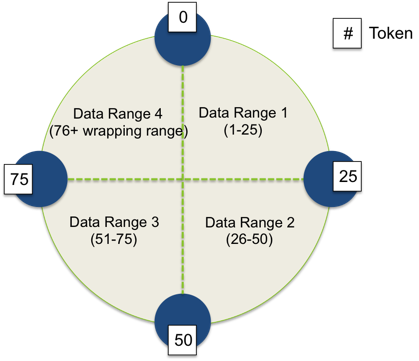
Rows are separated by its partition key
4 node Cassandra cluster that partitioning data in range of 100.
Uses consistent hashing to determine which node stores which row.
Implementation suggestion
Analyzing process
Lightning-Fast Cluster Computing
Apache Spark is a fast and general engine for large-scale data processing.
Implementation suggestion
Why Spark?
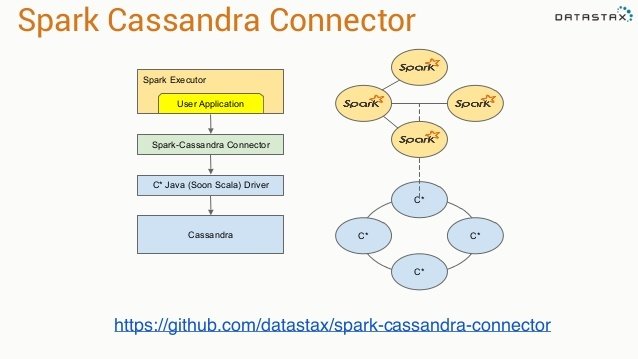
We want to process data, near its location. Preferably on the same network
Cassandra has a connector!
Implementation suggestion
Very good for scheduled batch jobs!
But this use case supports user interaction
More specifically funnel keys (start and goal key)
./bin/spark-submit \
--class <main-class>
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[<funnel-startKey>, <funnel-betweenKey>, <funnel-endKey>] //<-- application-argumentsTakes time to submit application to spark cluster.
This could most likely increase the overhead time of the query latency with 10 seconds.
!
Implementation suggestion
- Created at Ooyala in 2013
- Open source
- sbt assembly -> fat jar -> upload to server
- Call spark jobs async via HTTP
curl --data-binary @target/scala-2.10/<jar-file-name>.jar localhost:8090/jars/funnelAnalysis
curl -d "input.string = <funnel-startKey> <funnel-betweenKey> <funnel-endKey>"
> 'localhost:8090/jobs?appName=funnelAnalysis&classPath=spark.jobserver.sparkFunnelAnalysisApp'
{
"status": "STARTED",
"result": {
"jobId": "4b0edc57-b689-459b-8e7b-f99855128194",
"context": "553a26df-spark.jobserver.sparkFunnelAnalysisApp"
}
}
curl localhost:8090/jobs/4b0edc57-b689-459b-8e7b-f99855128194 <-- Get results
Spark Job-server "the saviour"
Implementation suggestion
Funnel counts (show on white board?)
DEMO
DEMO
What else can we gain/provide?
What else can we gain/provide
Going real time with lambda architecture
Usually have to implement and maintain the same logic in two different systems
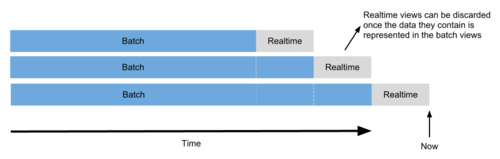
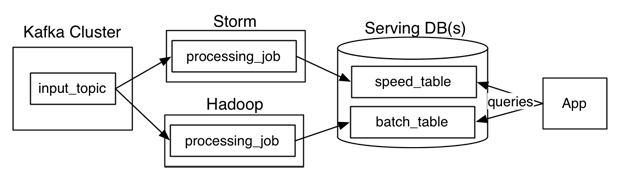
What else can we gain/provide
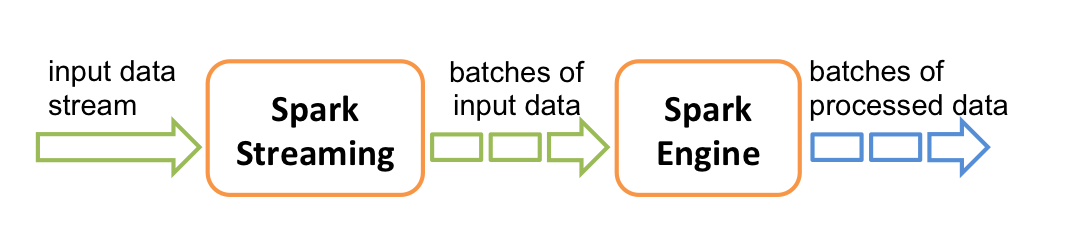
Not with Spark Streaming
(can reuse the same system logic)
What else can we gain/provide
Provide real time anomaly detection of error logs.
Let's say that the error log count for an Android application starts to increase, we can notify this to the customer directly, instead of having this as a scheduled daily batch process.
One example:
Timeplan
- The first handout of the report is planned to be the 16 of August.
2/6
16/8
31/8
First handout
Second version
- The second version at the end of August
Designing a funnel analysis data model for multi platform A/B testing
By Pär Eriksson


