Metodyki
i
techniki programowania
enum, switch, preprocesor, porady odnośnie tworzenia kodu, ...
- enum
- switch
- przesłanianie zmiennych
- przestrzeń nazw
- preprocesor
- jak faktycznie pisać
- program (konstrukcja programu)
- savoir vivre programisty oraz
- kilka pomocnych wskazówek
Zagadnienia:
savoir vivre oraz kilka pomocnych wskazówek
#include <iostream>
int main(){
if(a<5)
std::cout<<"a";
std::cout<<"b";
bool outer_flaga=true;
for (;outer_flaga;){
for(;;){
outer_flaga=false;
bool flaga=false;
if(!flaga){
flaga=true;
......}
break;}}
return 0;}Obojętnym jest czy otwarcie instrukcji będzie linijkę poniżej deklaracji funkcji czy nie, mamy tylko pilnować tabulacji:
Właściwa tabulacja pozwala łatwiej śledzić logikę programu.
#include <iostream>
int main()
{
if(a<5)
std::cout<<"a";
//nie ma obowiązku używania "{}" po if, ale wykonuje wtedy tylko pierwszą linijke po warunku
std::cout<<"b";
//znaczy to, że jak 'a' będzie większe od 5, to 'a' się nie wypisze, a 'b' już tak
bool outer_flaga=true;
for (;outer_flaga;)
{ //otwarcie instrukcji jest na tym samym poziomie co jej deklaracja
for(;;) //instrukcja jest juz poziom wyzej
{
outer_flaga=false;
bool flaga=false;
if(!flaga){
flaga=true;
......
}
break;
//dzieki tabulacji wiemy, że break jest w II forze, a nie w ifie.
}
}
return 0;
}Tabulatory i jak ich używać oraz kilka innych wskazówek:
Tworzymy rozbudowane zmienne, bo się pogubimy przy zmiennych jak będziemy używać tylko a,b,c,d
Nawet w pętlach, jak nie używasz zmiennej tylko do przeliczenia, ale też chcesz go użyć (przypisać itp.) to zamiast 'i' tworzyć zmienną np. "iterator_po_miesiącach"
#include <iostream>
int main()
{
bool outer_flaga=true;
for (;outer_flaga;) //pętla wykonuje się póki outer_flaga to prawda
{
for(;;) //pętla nieskończona
{
outer_flaga=false;
//dzięki temu, jak wyjdziemy z tej pętli, to wyjdziemy też z wczesniejszej
bool flaga=false;
if(!flaga){ //flaga==false
flaga=true; // od teraz nie wejdzie jeszcze raz do ifa
......
}
break; //przerywa pętle for, w której się znajduje.
//nistety nie ma breaka wielopoziomowego, dlatego jesli pętla jest zagnieżdżona w pętli,
// to aby przerwać poprzednią, trzeba zrobić tak jak wyżej
}
}
return 0;
}enum
typ wyliczeniowy, gdy chcemy ograniczyć ilość możliwych stanów do skończonej ilości
#include <iostream>
#include <vector>
enum Miesiac {sty, lut, mar, kwi, maj, cze, lip, sie, wrz, paz, lis, gru};
//typ wyliczeniowy, definiujemy nazwe "Miesiac" i co moze byc wywołane "sty, lut..."
int main(){
Miesiac miesiac_na_enumie = sty; // zmienna od enuma, przypisujemy
Miesiac miesiac_na_enumie2 = 3;
// mozna tak zrobic, ale wybierze odpowiednią wartość z enuma czyli mar?
for(Miesiac i=sty; i<=gru;i++)
{
std::cout<<i<<std::endl; // wypisze wszystko z enuma, tak jak ma podane
}
std::vector<Miesiac> m; //tak też można zrobić z enumem
}Niestandardowe przypisanie wartości w typie wyliczeniowym:
#include <iostream>
enum Miesiac {sty, lut, mar, kwi, maj, cze, lip, sie, wrz, paz, lis, gru};
//typ wyliczeniowy, definiujemy nazwe "Miesiac" i co moze byc wywołane "sty, lut..."
enum Miesiac_Bestest {sty=1, lut, mar, kwi=100, maj, cze, lip, sie, wrz, paz, lis, gru}
// lut=2, mar=3, maj =101, cze=102 nie definujemy podczas wywołania, można to zrobić tylko tu
int main(){
for(Miesiac_Bestest i=sty; i<=gru;i++)
{
std::cout<<i<<std::endl; // wypisze wszystko z enuma, tak jak ma podane
}
}switch
#include <iostream>
enum Miesiac {sty, lut, mar, kwi, maj, cze, lip, sie, wrz, paz, lis, gru};
void funif(Miesiac miesiac){
if(miesiac==sty)
{
std::cout<<"styczeń";
return; //możemy mimo void, wtedy wyrzuca nas na koniec funkcji.
}
else if(miesiac==lut)
{
.....
///itd, dla każdego miesiąca najbardziej optymalny if, ale wymyslono cos bardziej optymalnego
}
}Inaczej: wielopoziomowy if
Tutaj mamy przykład prawie najbardziej optymalnego ifa:
przyklad z ifami
#include <iostream>
enum Miesiac {sty, lut, mar, kwi, maj, cze, lip, sie, wrz, paz, lis, gru};
void funswitch(Miesiac miesiac){
switch(miesiac){
// switch to if wielopoziomowy, czyli to co wczesniej. switch jest przystosowany do inta
case sty:
// w przypadkach nie można użyć zakresów!!! czyli np. [sty, lut] !NIE!
std::cout<<"styczeń"<<std::endl;
break;
// to samo co break w forach, przenosi nas na koniec switcha
case lut:
std::cout<<"luty"<<std::endl;
//break;
//jak nie ma breaka to idzie do końca (lub do następnego casa z breakiem)
....
....
default:
std::cout<<"pozostałe miesiące"<<std::endl;
break;
// default nie musi być ostatni, więc może mieć breaka
//oraz dzieje się jeśli inne przypadki się nie dzieją
}
}To samo co wcześniej z użyciem switcha:
przesłanianie nazw
#include <iostream>
int main(){
int main=20; //przesłaniamy funkcję, można, ale po co? :)
int i=100;
for(;;){
int i=200;
}
std::cout<<i<<std::endl;
//'i' będzie 100, bo 200 jest wewnątrz pętli for 'i' umiera wraz z tą pętlą for.
for(int i=0;i<10;i++){
for(int i=0;i<10;i++){
//można tak, ale problem się zacznie jak będzie się chciało
// wykorzystać któres 'i' poza jego pętlą, a raczej wewnątrz drugiej pętli
//jest to ból, nie tylko dla programującego, ale też tego co będzie sprawdzał :c
}
}
}Polega na użyciu nazwy zmiennej/funkcji już użytej, ale nie na tym samym poziomie kodu. Jest to dozwolone, ale może powodować niepotrzebne komplikacje, jak będzie się chciało edytować kod itp.
Jest sposób na użycie przesłoniętej zmiennej, należy użyć "::" przed zmienną, wtedy kompilator wie, że musi jej szukać w niższej przestrzeni.
Jednak odnosząc się do wcześniej wspomnianych zasadach savoir vivre, najlepiej jest używać pełnych nazw na zmienne, dzięki czemu oszczędzimy sobie kłopotu z przesłanianiem.
#include <iostream>
int main(){
int i=100;
for(;;){
int i=200;
::i++;
//dobieramy się do 'i' będącego 3 linijki wyżej bez "::" modyfikowalibysmy 'i' z pętli
}
std::cout<<i<<std::endl; //'i' będzie 101
}przestrzeń nazw
Jest to przestrzeń, w której możemy stworzyć dowolne funkcje o dowolnej (nawet wcześniej zdefiniowanej) nazwie. Jedynym "ograniczeniem" tej dowolności jest fakt, że nazwy przestrzeni głównych nie mogą się powtarzać oraz aby użyć stworzonej funkcji musimy wypisać wszystkie nazwy przestrzeni w której to dana funkcja się znajduje.
Wstawienie using namespace std w pliku nagłówkowym w globalnej przestrzeni nazw jest złą praktyką programistyczną
using namespace std;//includy
void foo(){ //domyślna przestrzeń nazw
...}
//możemy używać określonych nazw np. cout, vector, ale nie w przestrzeni ogólnej,
//ponieważ mogą być one zdeklarowane w innej przestrzeni, którą wczytamy z daną biblioteką!
namespace dziwy{ //stworzona przez nas przestrzeń nazw dziwy
enum vector {maly, duzy, sredni};}
namespace wyklad{
namespace czwarty{ //stworzylismy przestrzeń nazw "czwarty" w przestrzeni nazw"wyklad"
void foo(){ //jesli teraz chcemy wywołać funkcję,
//musimy użyć pełnej przestrzeni nazw czyli: "wyklad::czwarty::foo()"
...}}}
int main(){
//using namespace std; // możemy tu spłaszyć przestrzeń, ale dopiero tu,
// a nie w ogólnej przestrzeni nazw, ponieważ spłaszczenie wczesniej powoduje,
//że nie będzie możan użyć tego w żaden inny sposób!
std::vector<int> vi; //odwołujemy się do pełnej przestrzeni
//nazw, jak mamy "using namespace std;" to nie możemy tworzyć zmiennej vector
//i innych zdefiniowanych w standardowej przestrzeni nazw
//można i tak:
using std::vector<int>;
vector<int>; //i wtedy działa już tak do końca, tak samo jak przy spłaszczeniu,
//tego nie można już cofnąć, co znaczy, że używamy tak do końca
foo(); // wywołuje "foo" z przestrzeni ogólnej
wyklad::czwart::foo(); // wywołuje "foo" z przestrzeni nazw "czwarty" z"wyklad"
dziwy::vector v=dziwy::vector::maly; //przypisanie do vectora 'v' z przestrzeni
//nazw "dziwy", "mały" z tej samej przestrzeni
}preprocesor
Preprocesor używa makrodefinicji (rozpoczynających się od #). Głównymi (najczęściej wykorzystywanymi) jego cechami są:
#define identifier replacement
#ifdef ... #endif
#ifndef //if NON define#ifdef pozwala na użycie nazw makro (skompilowanie programu) TYLKO kiedy została ona zdefiniowana, ale już niezależnie od jej wartości:
Dzięki #define tworzymy nowe makro, które możemy wykorzystywać przy wszystkich funkcjach/zmiennych jak np. vector.
#define TABLE_SIZE 100
int table1[TABLE_SIZE];
int table2[TABLE_SIZE];
// równoważne
int table1[100];
int table2[100];#ifdef TABLE_SIZE
int table[TABLE_SIZE];
#endif //jesli definicja TABLE_SIZE istnieje to:
int table[wartosć];#pragma once
Wskazanie dla preprocesora, że ma dany plik nagłówkowy uwzględniać przy dodawaniu tylko raz.
Oznacza to, że nasz plik "funkcje.h", mimo iż z konieczności, aby wszystko zadziałało jest wklejony i do "funkcje.cpp" i do "main.cpp" (patrz slajd 9), to w ostatecznej wersji kodu, którą to kompilator będzie widział, cały kod z "funkcje.h" wystąpi tylko raz, a nie tyle ile mamy plików na niego się powołujących.
#pragma once // dodawane na początku pliku nagłówkowegoincludey
#include <> lub ""
include powoduje, że kompilator wkleja kod, kod z pliku danej bibliotek np. iostream...
<> szuka w standardowych ścieżkach systemu i wkleja kod biblioteki
"" szuka w folderze i wkleja kod z pliku
w przypadku gdy plik znajduje się w innym folderze podaje się jego ścieżkę np.
"nazwafolderu1/nazwafolderu2/nazwapliku.h"
#include <nazwa>
#include "nazwa.rozszerzenie"
#include "nazwafolderu1/nazwapliku.rozszerzenie"Przykładowa ścieżka
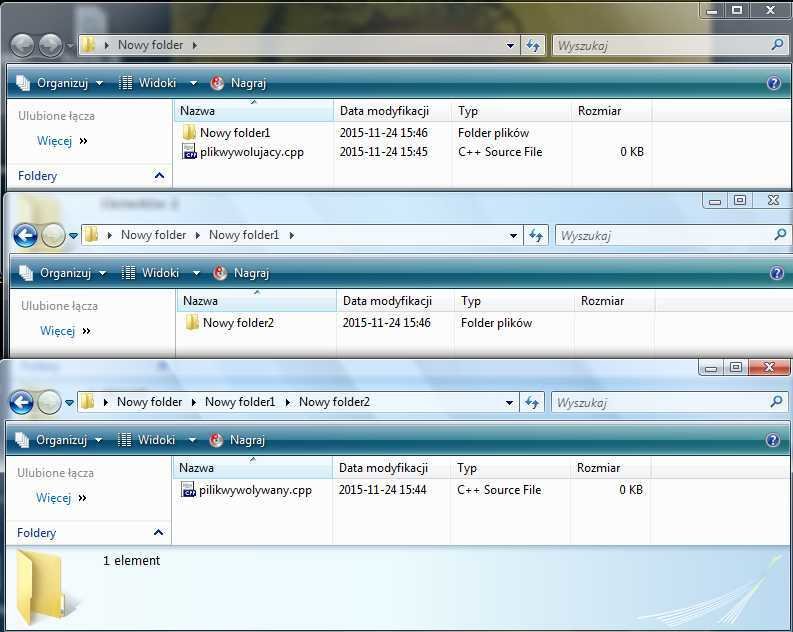
deklaracja/definicja - różnice
deklaracja - zajęcie nazwy, wskazanie kompilatorowi, że dana nazwa ma być użyta w przyszłości
definicja - opisanie kompilatorowi czym tak naprawdę jest dany byt
#inlcude<iostream>
int foo(int,int,int); //deklarujemy, że ma nazwę, definicję możemy ułożyć później
//przed mainem deklaracje
int main(){
foo(1,2,3);
return 0;
}
//po mainie definicje
int foo(int a, int b, int c){ //tworzymy definicję wczesniejszej deklaracji
return a+b+c;
}Poprawny zapis pliku main.cpp
#include <iostream>
#include "funkcje.h"
int main(){
std::cout << convert({'a','b'});
foo(1,2,3);
return 0;
}
#include "funkcje.h"
int foo(int a,int b,int c){
return a+b+c;
}
std::string convert(const std::vector<char> & v){
}#pragma once
#include <string>
#include <vector>
int foo(int,int,int);
std::string convert(const std::vector<char> & v);
main.cpp
funkcje.cpp
funkcje.h
Include wkleja nam dany kod, znaczy to, że jeśli już raz wkleiliśmy bibliotekę w "funkcje.h", a potem funkcje wklejamy do "main.cpp", to cały kod z funkcji wraz z bibliotekami wklei się do maina
Model kompilacji języka c++
1. Preprocesor analizuje kod, przed rozpoczęciem kompilacji rozwija wszystkie dyrektywy, zanim jakikolwiek kod będzie przekazany do kompilacji.
2. kompilacja
2a ewentualna optymalizacja
3. linkowanie
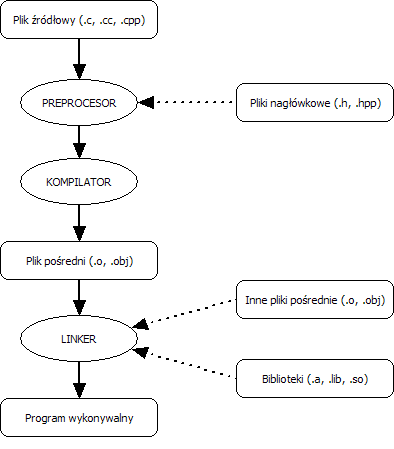
następne wydarzenia po stworzeniu programu:
- kompilują się pliki z kodem (.cpp)
- tworzą się pliki pośrednie - obiekty (.o, .obj)
- linkują się wszystkie obiekty wraz ze skompilowanymi bibliotekami
- tworzy się program (.exe)
konstrukcja programu
- osobno tworzymy pliki nagłówkowe (.h)
- w każdym pliku nagłówkowym zamieszczamy odpowiednie odnośniki do bilbiotek (iostrem, vector itp. itd.)
- osobno tworzymy pliki z kodem (.cpp)
- w każdym pliku z kodem includujemy właściwe nagłówki
Rola Visual Studio
Kompilowane są wszystkie pliki z kodem, które są wprost wstawione w projekt w Visual Studio.
Inaczej rzecz ujmując, Visual Studio robi z naszym kodem to, co przedstawia schemat blokowy, ułatwiając nam życie poprzez wgląd do odpowiednich katalogów (oraz automatyczne ich wywoływanie) tj. katalog plików nagłówkowych, plików źródłowych itd. itp.
enum, switch, preprocesor, itd.
By pedzimaz
enum, switch, preprocesor, itd.
enum, switch, preprocesor, rady odnośnie tworzenia kodu



