Реляционные базы данных
Tinkoff python
Лекция 5
Перминов Сергей

Backend Dialog System
dialog platform for bots

Базы данных - зачем?
Чтобы хранить данные :)
Реляционные и нереляционные.
Писать свою реализацию хранилища сложно и долго.
Реляционные базы данных
Используем, когда данные хорошо структурированы, и нам важны связи между ними.
Данные хранятся в таблицах
| title | created_at | deadline | done_at |
|---|---|---|---|
| расширить API | 25.02 | 03.03 | 01.03 |
| обновиться до python 3.8 | 03.03 | 15.03 | NULL |
| добавить логов в http-клиент | 21.02 | NULL | NULL |
task
| title | ... | author | assigned_to | project |
|---|---|---|---|---|
| расширить API | ... | Даниил | Антон | chatbot |
| обновиться до python 3.8 | ... | Даниил | NULL | talkbot |
| name | role | ... |
|---|---|---|
| Даниил | project manager | ... |
| Антон | backend dev | ... |
task
user
| title | state | ... |
|---|---|---|
| chatbot | a|b testing | ... |
| talkbot | alpha version | ... |
project
| title | ... | project | project_version |
|---|---|---|---|
| расширить API | ... | chatbot | a|b testing |
| обновиться до python 3.8 | ... | talkbot | alpha version |
| добавить логов в http-клиент | ... | talkbot | alpha version |
| title | ... | project | project_version |
|---|---|---|---|
| расширить API | ... | chatbot | a|b testing |
| обновиться до python 3.8 | ... | talkbot | production |
| добавить логов в http-клиент | ... | talkbot | alpha version |
One to one
страна - столица
человек - паспортные данные
| title | author | ... |
|---|---|---|
| расширить API | Даниил | ... |
| обновиться до python 3.8 | Даниил | ... |
| добавить логов в http-клиент | Антон |
| name | role | ... |
|---|---|---|
| Даниил | project manager | ... |
| Антон | backend dev | ... |
task
user
One to many
| title | year | ... |
|---|---|---|
| Джентельмены | 2019 | ... |
| 1917 | 2019 | ... |
| Паразиты | 2019 | ... |
| login | registered_at | ... |
|---|---|---|
| foo | 05.05.2013 | ... |
| bar | 26.12.2019 | ... |
film
user
Many to many
film_rating
| film | user | rating |
|---|---|---|
| Джентельмены | foo | 9 |
| Джентельмены | bar | 6 |
| 1917 | bar | 8 |
Первичный ключ
-
позволяет однозначно идентифицировать строку;
-
должен быть отвязан от реальных сущностей.
| password_hash | registered_at | ... | |
|---|---|---|---|
| foo@kek.ru | 2cf24dba5f... | 05.05.2013 | ... |
| bar@kek.ru | 58756879c0... | 26.12.2019 | ... |
Первичный ключ
| password_hash | registered_at | ... | |
|---|---|---|---|
| foo@kek.ru | 2cf24dba5f... | 05.05.2013 | ... |
| bar@kek.ru | 58756879c0... | 26.12.2019 | ... |
| registered_at | ... | facebook_id | |
|---|---|---|---|
| foo@kek.ru | 05.05.2013 | ... | NULL |
| bar@kek.ru | 26.12.2019 | ... | NULL |
| NULL | 10.03.2020 | ... | 14446842256 |
| id | ... | facebook_id | |
|---|---|---|---|
| 1 | foo@kek.ru | ... | NULL |
| 2 | bar@kek.ru | ... | NULL |
| 3 | NULL | ... | 14446842256 |
create table
create table film (
id serial primary key,
title varchar not null,
budget integer default null,
premiere date not null
);Колонки типизированы.
-
целые цисла, строки, даты...
-
json, array, enum;
-
...
-
геометрические примитивы (некоторые БД).
* все примеры на PostgreSQL 11.6
insert
insert into film (title, budget, premiere)
values
('Джентельмены', 22000000, '2019-12-03'),
('1917', 100000000, '2019-12-04'),
('Паразиты', NULL, '2019-05-21');select
> select * from film;
id | title | budget | premiere
----+--------------+-----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
2 | 1917 | 100000000 | 2019-12-04
3 | Паразиты | | 2019-05-21> select title, premiere from film;
title | premiere
--------------+------------
Джентельмены | 2019-12-03
1917 | 2019-12-04
Паразиты | 2019-05-21
select
> select max(premiere) from film;
max
------------
2019-12-04
> select * from film
where premiere = (select max(premiere) from film);
id | title | budget | premiere
----+-------+-----------+------------
2 | 1917 | 100000000 | 2019-12-04
> select * from film where budget > 50000000;
id | title | budget | premiere
----+-------+-----------+------------
2 | 1917 | 100000000 | 2019-12-04select
> select * from film order by premiere desc;
id | title | budget | premiere
----+--------------+-----------+------------
2 | 1917 | 100000000 | 2019-12-04
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21
update
> update film
set budget = budget + 100000
where id = 2;
UPDATE 1
> select * from film;
id | title | budget | premiere
----+--------------+-----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21
2 | 1917 | 101000000 | 2019-12-04
delete
> delete from film where id = 2;
DELETE 1
> select * from film;
id | title | budget | premiere
----+--------------+-----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21
2 | 1917 | 101000000 | 2019-12-04
> select * from film;
id | title | budget | premiere
----+--------------+----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21
index
> select *
from film
where premiere > '2019-12-01';Какова сложность этого запроса - O(?)
Для фильтрации придётся проверить каждую строку таблицы.
index
> create index film_premiere_idx
on film using btree(premiere);
index
-
+ ускоряет поиск записей;
-
- замедляет вставку, обновление и удаление записей;
-
- занимает место на диске.
Лишние индексы - плохо!
create table "user" (
id serial primary key,
email varchar not null,
registered_at date default now()
);insert into "user" (email) values
('foo@kek.ru'), ('bar@kek.ru');Constraint
> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
2 | bar@kek.ru | 2020-03-07
> insert into "user" (email)
values ('bar@kek.ru');> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
2 | bar@kek.ru | 2020-03-07
3 | bar@kek.ru | 2020-03-10
Два пользователя с одинаковыми email 💩
create table "user" (
id serial primary key,
email varchar not null unique,
registered_at date default now()
);unique key
alter table "user" add unique(email);Мы должны были создать таблицу по-другому:
Или если таблица уже создана:
unique key
> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
2 | bar@kek.ru | 2020-03-07
> insert into "user" (email) values ('bar@kek.ru');
ERROR: duplicate key value violates unique
constraint "user_email_key"> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
2 | bar@kek.ru | 2020-03-07
> select * from film;
id | title | budget | premiere
----+--------------+----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21create table film_rating (
id serial primary key,
user_id integer not null,
film_id integer not null,
rating integer not null
);> insert into film_rating
(user_id, film_id, rating)
values (1, 1, 7), (9123, 143523, 4);
> select * from film_rating;
id | user_id | film_id | rating
----+---------+---------+--------
1 | 1 | 1 | 7
2 | 9123 | 143523 | 4film_rating соединяет несуществующего пользователя с несуществующим фильмом🤦♂️
create table film_rating (
id serial primary key,
user_id integer not null references "user"(id),
film_id integer not null references "film"(id),
rating integer not null
);foreing key
alter table film_rating
add constraint film_rating_user_id_fkey
foreign key (user_id) references "user" (id);
-- аналогично для film_idМы должны были создать таблицу по-другому:
Или если таблица уже создана:
foreing key
> insert into film_rating
(user_id, film_id, rating)
values (1, 1, 7), (9123, 143523, 4);
ERROR: insert or update on table "film_rating"
violates foreign key constraint
"film_rating_user_id_fkey"
DETAIL: Key (user_id)=(9123) is not present
in table "user".foreing key
> select * from "user" where id = 1;
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
> select * from film_rating where id = 1;
id | user_id | film_id | rating
----+---------+---------+--------
1 | 1 | 1 | 7
> delete from "user" where id = 1;ERROR: update or delete on table "user" violates
foreign key constraint "film_rating_user_id_fkey"
on table "film_rating"
DETAIL: Key (id)=(1) is still referenced from
table "film_rating".
create table film_rating (
id serial primary key,
user_id integer not null references "user"(id)
on delete cascade,
film_id integer not null references "film"(id),
rating integer not null
);foreing key
alter table film_rating
drop constraint film_rating_user_id_fkey,
add constraint film_rating_user_id_fkey
foreign key (user_id) references "user"(id)
on delete cascade;Мы могли бы создать таблицу по-другому:
Или если таблица уже создана:
foreing key

НЕ УДАЛЯЙ ДАННЫЕ КАСКАДОМ
> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-07
2 | bar@kek.ru | 2020-03-07
> select * from film;
id | title | budget | premiere
----+--------------+----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21> insert into film_rating (user_id, film_id, rating)
values (2, 3, 14);
> select * from film_rating;
id | user_id | film_id | rating
----+---------+---------+--------
8 | 2 | 3 | 14
14/10 - неужели настолько хороший фильм? 🤔
create table film_rating (
id serial primary key,
user_id integer not null references "user"(id),
film_id integer not null references "film"(id),
rating integer not null
check (rating > 0 and rating < 11)
);alter table film_rating
add constraint film_rating_rating_check
check (rating > 0 and rating < 11);Мы должны были создать таблицу по-другому:
Или если таблица уже создана:
check constraint
> insert into film_rating (user_id, film_id, rating)
values (2, 3, 14);
ERROR: new row for relation "film_rating" violates
check constraint "film_rating_rating_check"
DETAIL: Failing row contains (3, 2, 3, 14).check constraint
create table film_rating (
id serial primary key,
user_id integer not null references "user"(id),
film_id integer not null references "film"(id),
rating integer not null
check (rating > 0 and rating < 11)
);Что ещё может пойти не так?
insert into film_rating (user_id, film_id, rating)
values (2, 3, 10),
(2, 3, 10),
(2, 3, 10);> select * from film_rating;
id | user_id | film_id | rating
----+---------+---------+--------
3 | 2 | 3 | 10
4 | 2 | 3 | 10
5 | 2 | 3 | 10

create table film_rating (
id serial primary key,
user_id integer not null references "user"(id),
film_id integer not null references "film"(id),
rating integer not null
check (rating > 0 and rating < 11),
unique (user_id, film_id)
);alter table film_rating
add constraint film_rating_user_id_film_id_key
unique (user_id, film_id);Мы должны были создать таблицу по-другому:
Или если таблица уже создана:
Составной unique key
> insert into film_rating (user_id, film_id, rating)
values (2, 3, 10),
(2, 3, 10),
(2, 3, 10);
ERROR: duplicate key value violates unique
constraint "user_id_film_id_uq"
DETAIL: Key (user_id, film_id)=(2, 3)
already exists.
Составной unique key
Index & Constraint
-
Индексы создаём только на те колонки, по которым часто выполняем фильтрацию;
-
Unique key, foreign key, check constraint - создаём так, чтобы гарантировать максимальную корректность данных;
-
Primary key - создаём отдельную "техническую" колонку;
-
Constraint на уровне базы не отменяют проверку данных на уровне приложения.
Index & Constraint
-
Индекс автоматически создаётся на primary key, unique key;
-
В некоторых БД индекс автоматически создаётся на foreign key;
-
Foreign key должен ссылаться на первичный ключ.
foreign key
> select * from film_rating;
id | user_email | film_id | rating
----+------------+---------+--------
1 | foo@kek.ru | 1 | 7
> select * from film_rating;
id | user_id | film_id | rating
----+---------+---------+--------
1 | 1 | 1 | 7
-
Теперь труднее изменить email;
-
А что, если завтра мы начнём авторизовываться через facebook, и email станет необязательным?

> select * from "user";
id | email | registered_at
----+------------+---------------
1 | foo@kek.ru | 2020-03-08
2 | bar@kek.ru | 2020-03-08
> select * from film;
id | title | budget | premiere
----+--------------+-----------+------------
1 | Джентельмены | 22000000 | 2019-12-03
3 | Паразиты | | 2019-05-21
2 | 1917 | 101000000 | 2019-12-04
> select * from film_rating;
id | user_id | film_id | rating
----+---------+---------+--------
1 | 1 | 1 | 7
2 | 1 | 3 | 10
3 | 2 | 1 | 6
> select
f.title, fr.rating,
fr.film_id, fr.rating
from film as f
join film_rating as fr
on f.id = fr.film_id;
id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 3 | 10
1 | Джентельмены | 1 | 6
id | title
----+--------------
1 | Джентельмены
3 | Паразиты
2 | 1917 id | film_id | rating
----+---------+--------
1 | 1 | 7
2 | 3 | 10
3 | 1 | 6 id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 3 | 10
1 | Джентельмены | 1 | 6
id | title
----+--------------
1 | Джентельмены
3 | Паразиты
2 | 1917 id | film_id | rating
----+---------+--------
1 | 1 | 7
2 | 3 | 10
3 | 1 | 6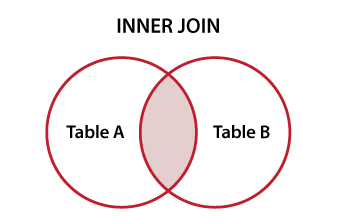
id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 3 | 10
1 | Джентельмены | 1 | 6
2 | 1917 | NULL | NULL
id | title
----+--------------
1 | Джентельмены
3 | Паразиты
2 | 1917 id | film_id | rating
----+---------+--------
1 | 1 | 7
2 | 3 | 10
3 | 1 | 6> select
f.title, fr.rating,
fr.film_id, fr.rating
from film as f
left join film_rating as fr
on f.id = fr.film_id;
id | title
----+--------------
1 | Джентельмены
3 | Паразиты
2 | 1917 id | film_id | rating
----+---------+--------
1 | 1 | 7
2 | 3 | 10
3 | 1 | 6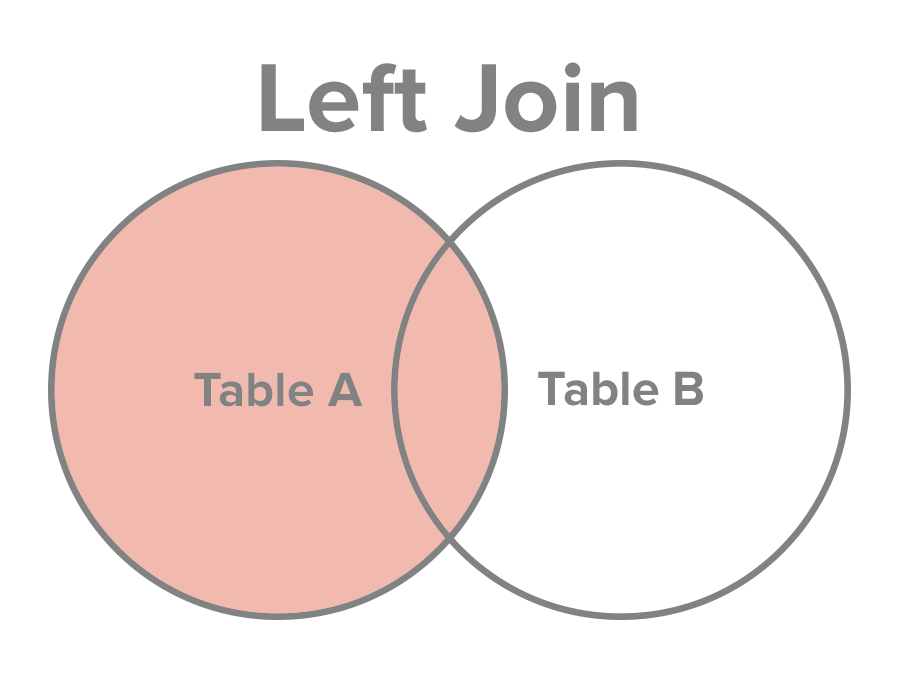
id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 3 | 10
1 | Джентельмены | 1 | 6
2 | 1917 | NULL | NULL
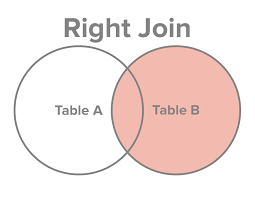
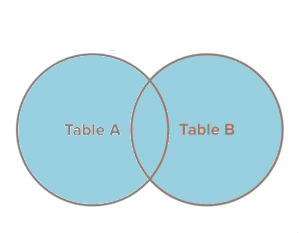
Full Join
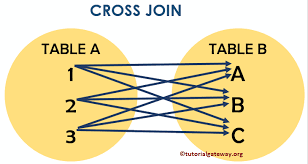
> select f.id, f.title,
fr.film_id, fr.rating
from film f cross join film_rating fr;
id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 1 | 7
2 | 1917 | 1 | 7
1 | Джентельмены | 3 | 10
3 | Паразиты | 3 | 10
2 | 1917 | 3 | 10
1 | Джентельмены | 1 | 6
3 | Паразиты | 1 | 6
2 | 1917 | 1 | 6> select f.id, f.title,
fr.film_id, fr.rating
from film f cross join film_rating fr;
id | title | film_id | rating
----+--------------+---------+--------
1 | Джентельмены | 1 | 7
3 | Паразиты | 3 | 10
1 | Джентельмены | 1 | 6
2 | 1917 | NULL | NULL
> select
f.title, fr.rating,
fr.film_id, fr.rating
from film as f
left join film_rating as fr
on f.id = fr.film_id;
Как найти фильмы без оценок?
id | title | film_id | rating
----+--------------+---------+--------
2 | 1917 | NULL | NULL
> select
f.title, fr.rating,
fr.film_id, fr.rating
from film as f
left join film_rating as fr
on f.id = fr.film_id
where fr.id is null;
Как найти фильмы без оценок?
> select u.email, f.title, fr.rating
from "user" u
join film_rating fr
on u.id = fr.user_id
join film f
on fr.film_id = f.id;
email | title | rating
------------+--------------+--------
foo@kek.ru | Джентельмены | 7
foo@kek.ru | Паразиты | 10
bar@kek.ru | Джентельмены | 6В запросе может быть много join
> select u.email, f.title, fr.rating
from "user" u
join film_rating fr
on u.id = fr.user_id
join film f
on fr.film_id = f.id;
Какова сложность этого запроса - O(?)

SQL - декларативный язык
Мы говорим, что хотим сделать, не как это сделать.
> select u.email, f.title, fr.rating
from "user" u
join film_rating fr
on u.id = fr.user_id
join film f
on fr.film_id = f.id
where
f.premiere > '2019-12-01';
SQL - декларативный язык
-
Сначала приджойнить film_rating к user?
-
Или сначала приджойнить film_rating к film?
-
Или сначала отфильтровать film по premiere?
SQL - декларативный язык
Порядок выполнения запроса зависит от
-
количества записей в таблицах;
-
наличия индексов;
-
внутренних эвристик планировщика запросов.

Как именно выполнится запрос? - оператор "explain".
Базы данных - зачем?
ACID в схемах и мемах.
A - атомарность (atomic)
С - согласованность (consistensy)
I - изоляция (isolated)
D - долговечность (durability)
Атомарность
Транзакция либо выполнится полностью, либо не выполнится вообще.

Согласованность
В базе данных отсутствуют противоречия с точки зрения приложения.
Изоляция
Конкурирующие за доступ к БД транзакции физически обрабатываются последовательно и изолированно друг от друга, но для приложения это выглядит, как будто они выполняются параллельно.

Долговечность
Если транзакция завершилась успешно, то изменения будут доступны даже при аппаратном сбое.

Уровни изоляции
-
Read uncommited (Чтение незафиксированных данных) - отсутствует в postgres;
-
Read committed (Чтение зафиксированных данных);
-
Repeatable read (Повторяемое чтение);
-
Serializable (Сериализуемость).
Read Committed
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> begin;
> update accounts
set balance = balance + 500
where id = 1;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2500
> commit;
> begin;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2500
Read Committed
-
+ работает относительно быстро
-
-
- феномен неповторяющегося чтения
-
- феномен чтения фантомов
-
- сложно для разработчика
Serializable
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> begin;
> update accounts
set balance = balance + 500
where id = 1;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2500
> commit;
> begin;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
Serializable
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> begin;
> update accounts
set balance = balance + 500
where id = 1;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2500
> begin;
> update accounts
set balance = balance + 500
where id = 1;
Serializable
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2000
> begin;
> update accounts
set balance = balance + 500
where id = 1;
> select * from accounts;
id | login | balance
----+-------+----------
1 | petya | 2500
> commit;
> begin;
> update accounts
set balance = balance + 500
where id = 1;
ERROR: could not serialize
access due to concurrent update
Serializable
-
+ транзакции никак не влияют друг на друга => максимальная согласованность данных
-
+ проще для разработчика*
-
-
- медленная скорость выполнения транзакций из-за локов
Уровни изоляции транзакций
-
помним, что в базу можеть писать не один процесс;
-
выбираем уровень изоляции, исходя из специфики приложения;
-
минимизируем локи - делаем транзакции как можно менее протяжёнными.
Нормализация
Набор рекомендаций по проектированию БД.
-
исключение избыточности - когда данные хранятся в одном месте, их проще изменять;
-
обеспечение целостности - данные должны быть консистенты;
-
не стремимся уменьшить объём данных;
-
не стремимся ускорить работу базы.
Первая нормальная форма (НФ1)
-
значения в колонке должны быть атомарны;
-
колонки не должны дублировать друг друга;
-
каждая запись - представление одной сущности.
id | user_id | watched_films
----+------------+--------------
1 | 1 | 12,15,21
2 | 2 | 14,22 id | user_id | film1 | film2 | film3
----+------------+--------+---------+------
1 | 1 | 12 | 15 | 21
2 | 2 | 14 | 22 |НФ1
Каждая запись - представление одной сущности.
id | user_id | film_id | date
----+------------+---------+------------
1 | 1 | 12 | 2019-12-03
2 | 1 | 15 | 2019-10-02
3 | 1 | 21 | 2018-12-21
4 | 2 | 14 | 2020-02-12
5 | 2 | 22 | 2019-12-25
Порядок записей не должен иметь значения.
Важен порядок - заводим явную колонку.
Потенциальный ключ
уникальный и минимальный набор атрибутов, которые описывают хранимую сущность.
НФ2
Храним в таблице только данные, которые зависят от потенциального ключа целиком.
id | user_id | task_id | task_project| project_state
----+---------+---------+--------------+---------------
1 | 1 | 1 | talkbot | alpha
2 | 1 | 2 | talkbot | alpha
3 | 1 | 3 | chatbot | a|b
4 | 2 | 4 | chatbot | a|b
5 | 2 | 5 | chatbot | a|b
Проект зависит только от задачи, но не от пользователя.
Назначение задач
Потенциальный ключ
НФ2
id | user_id | task_id
----+---------+--------
1 | 1 | 1
2 | 1 | 2
3 | 1 | 3
4 | 2 | 4
5 | 2 | 5 id | number | title | deadline | project | project_state
------+--------+-------+-----------+---------+---------------
1 | 1872 | ... | 2020-03-16| talkbot | alpha
2 | 2012 | ... | 2020-03-16| talkbot | alpha
3 | 1923 | ... | 2020-03-17| chatbot | a|b
4 | 069 | ... | 2020-03-16| chatbot | a|b
5 | 1966 | ... | 2020-03-19| chatbot | a|b
Назначение задач
Задачи
НФ3
Все колонки должны зависить только от потенциального ключа.
id | number | title | deadline | project | project_state
------+--------+-------+-----------+---------+---------------
1 | 1872 | ... | 2020-03-16| talkbot | alpha
2 | 2012 | ... | 2020-03-16| talkbot | alpha
3 | 1923 | ... | 2020-03-17| chatbot | a|b
4 | 069 | ... | 2020-03-16| chatbot | a|b
5 | 1966 | ... | 2020-03-19| chatbot | a|b
Задачи
Состояние проекта зависит не от потенциального ключа, а от колонки "проект".
НФ3
Все колонки должны зависить только от потенциального ключа.
id | number | title | deadline | project_id
------+--------+-------+-----------+------------
1 | 1872 | ... | 2020-03-16| 1
2 | 2012 | ... | 2020-03-16| 1
3 | 1923 | ... | 2020-03-17| 2
4 | 069 | ... | 2020-03-16| 2
5 | 1966 | ... | 2020-03-19| 2
Задачи
id | project | state
----+---------+-------
1 | talkbot | alpha
2 | chatbot | a|bПроекты
Денормализация
Отклонения от нормальных форм ради удобства или скорости работы.
id | title | aver_rating
----+--------------+--------------
1 | Джентельмены | 8.70
3 | Паразиты | 8.06
2 | 1917 | 8.11-
считать средний рейтинг фильма долго;
-
супер-точное значение рейтинга не требуется.
id | user_id | film_id | rating
----+---------+---------+--------
1 | 1 | 1 | 7
2 | 1 | 3 | 10
...| ... | ... | ...
Нормализация
-
набор рекомендаций по проектированию БД;
-
НФ1 = значения в колонках должны быть атомарны;
-
НФ2 = НФ1 + атрибуты должны зависеть от потенциального ключа целиком;
-
НФ3 = НФ2 + атрибуты должны зависеть только от потенциального ключа;
-
сначала нормализация, потом денормализация.
Перерыв?
SQLite
база данных в одном файле
-
+ не требует усилий по развёртыванию и настройке;
-
+ поддержка в python из коробки;
-
- нельзя одновременно писать из двух процессов;
-
- нельзя работать по сети.
Серверные базы данных
-
Oracle;
-
Microsoft SQL Server;
-
MySQL;
-
Postgres;
-
etc...
Connection pool
-
соединение расходует ресурсы базы данных;
-
количество одновременно открытых соединений ограничено;
-
соединения можно переиспользовать как на стороне БД (например, pgbouncer), так и на стороне приложения.

Что делаем из python?
Вариант 1: работаем с "сырым" sql через драйвер.
raw sql
import sqlite3
conn = sqlite3.connect('example.db')
c = conn.cursor()
c.execute("""
CREATE TABLE film (
ID INTEGER PRIMARY KEY,
title varchar, budget integer, premiere date
)
""")
c.execute("""
INSERT INTO film (title, budget, premiere) VALUES
('Джентельмены', 22000000, '2019-12-03'),
('1917', 100000000, '2019-12-04')
""")
Нет подсветки sql-синтаксиса* 👎
raw sql
res = c.execute("SELECT * FROM film;").fetchall()
for row in res:
print(row)
# (1, 'Джентельмены', 22000000, '2019-12-03')
# (2, '1917', 100000000, '2019-12-04')
conn.commit()
conn.close()
raw sql
sql-инъекции
film_id = 1
# плохо
cursor.execute(f"""
SELECT * FROM film WHERE id = {film_id}
""")film_id = '1; drop table film;'
# плохо
cursor.execute(f"""
SELECT * FROM film WHERE id = {film_id}
""")
# SELECT * FROM film
# WHERE id = 1; drop table film;

sqlite эта инъекция не сломает, потому что драйвер не может выполнить больше одного запроса за раз.
raw sql
sql-инъекции
film_id = 1
# плохо
cursor.execute(f"""
SELECT * FROM film WHERE id = {film_id}
""")? - placeholder, который сообщает драйверу, что в этом месте будет параметр, который нужно экранировать.
# хорошо
cursor.execute("""
SELECT * FROM film WHERE id = ?
""", user_id
)
raw sql
Много затрат на построение запроса.
def find_any(columns):
conditions = [
f"{column} = '?'"
for column in columns
]
return ' OR \n'.join(conditions)
# field1 = '?' OR
# field2 = '?' OR
# field3 = '?'
raw sql
Берём драйвер и просто* исполняем запросы.
-
+ видим конечный sql-запрос;
-
- результаты запросов - простые типы;
-
- мучаемся с шаблонами;
-
- помним про инъекции;
-
- зависим от диалекта sql.

Что делаем из python?
Вариант 2: object relation mapping (ORM)

ORM
-
Работаем с базой в терминах ООП, а не в терминал реляционной алгебры.
-
Есть query build - не форматируем строки вручную на python.
-
Не зависим от платформы*: сегодня sqlite, завтра postgres.
peewee
from peewee import (
SqliteDatabase, Model, CharField,
DateField, AutoField)
db = SqliteDatabase('people.db')
class Film(Model):
id = AutoField()
title = CharField()
premiere = DateField()
class Meta:
database = db
db.connect()
db.create_tables([Film])
peewee
from datetime import date
film = Film(
title='Джентльмены',
premiere=date(2019, 12, 3))
film.save()
loaded_film = (
Film.select()
.where(Film.title == 'Джентльмены')
.get()
)
print(loaded_film.title)
# Джентльменыdjango orm
from django.db import models
class Film(models.Model):
title = models.CharField(max_length=100)
premiere = models.DateTimeField()
def __str__(self):
return self.title
django orm
b = Film(
title='Джентельмены',
premiere=date(2019, 12, 3))
b.save()
loaded_film = Film.objects.get(title='Джентельмены')
print(loaded_film)
# ДжентельменыSQLAlchemy
SQLAlchemy
SQLAlchemy
не только ORM
core
- подключение к БД;
- пулы подключений;
- описание таблиц;
- составление запросов;
- результаты запросов - простые типы.
SQLAlchemy
orm
from datetime import date
import sqlalchemy as sa
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Film(Base):
__tablename__ = 'film'
id = sa.Column(sa.Integer, primary_key=True)
title = sa.Column(sa.String())
premiere = sa.Column(sa.Date())
film = Film(
title='Джентельмены',
premiere=date(2019, 12, 3))
SQLAlchemy
engine - связь SQLAlchemy с базой
engine = sa.create_engine('sqlite:///foo.db')
# или
# `pip install psycopg2`
db_url = 'postgresql://scott:tiger@localhost:5432/mydatabase'
engine = create_engine(db_url)
Base.metadata.create_all(engine)
SQLAlchemy
session - "близнец" транзакции на уровне python
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
session.add(film1) # insert
session.delete(film2) # delete
film3.title = 'new title'
session.add(user3) # update
# коммитим изменения
session.commit()
# или откатываем изменения
session.rollback()
SQLAlchemy
session нужно закрыть после использования
from contextlib import contextmanager
Session = sessionmaker(bind=engine)
@contextmanager
def create_session(**kwargs):
new_session = Session(**kwargs)
try:
yield new_session
new_session.commit()
except Exception:
new_session.rollback()
raise
finally:
new_session.close()
SQLAlchemy
session - "близнец" транзакции на уровне python
with create_session() as session:
film = Film(
title='Джентельмены',
premiere=date(2019, 12, 3),
)
session.add(film)
SQLAlchemy
session.query
with create_session() as session:
test_user = (
session.query(Film)
.filter(Film.title == '1917')
.one()
)
# SELECT film.id AS film_id,
# film.title AS film_title,
# film.premiere AS film_premiere
# FROM film
# WHERE film.title = ?
SQLAlchemy
у колонок переопределны операторы
films = (
session.query(Film)
.filter_by(title='1917')
.all()
)
films = (
session.query(Film)
.filter(Film.title == '1917')
.all()
)
SQLAlchemy
films = (
session.query(Film)
.filter(Film.title == 'Жизнь прекрасна')
.one()
)
# sqlalchemy.orm.exc.NoResultFound:
# No row was found for one()SQLAlchemy
| метод | несколько строк | одна строка | ни одной строки |
|---|---|---|---|
| all | список | список из одного объекта | пустой список |
| one | исключение | объект | исключение |
| first | случайный из объектов | объект | None |
| one_or_none | исключение | объект | None |
SQLAlchemy
with create_session() as session:
user = User(name='admin')
session.add(user)
with create_session() as session:
user = session.query(User).first()
print(user.name)
> 'admin'
SQLAlchemy
with create_session() as session:
user = session.query(User).first()
... # что-то ещё
print(user.name)
> Traceback (most recent call last):
> ...
> sqlalchemy.orm.exc.DetachedInstanceError: ...
SQLAlchemy
with create_session() as session:
user = session.query(User).first()
... # что-то ещё
print(user.name)
> Traceback (most recent call last):
> ...
> sqlalchemy.orm.exc.DetachedInstanceError: ...
транзакция открыта
пытаемся обратиться к атрибуту
другой процесс мог изменить значение в базе
SQLAlchemy
with create_session(expire_on_commit=False) as session:
user = session.query(User).first()
print(user.name)
> 'admin'
with create_session() as session:
user = session.query(User).first()
name = user.name
print(name)
> 'admin'
expire_on_commit - когда мы уверены, что с базой работает только наш процесс, например, в тестах
flush
with create_session() as session:
user = User(...)
session.add(user)
print(user.id)
# Nonewith create_session() as session:
user = User(...)
session.add(user)
session.flush()
print(user.id)
# 1flush - выполнить запрос, но не коммитить транзакцию.
SQLAlchemy
starter pack
engine = sa.create_engine(...)
Session = sessionmaker(bind=engine)
Base = declarative_base()
@contextmanager
def create_session(**kwargs):
...
class User(Base):
__tablename__ = 'user'
...
Base.metadata.create_all(engine)
with create_session() as session:
...
-
подключение к базе - engine;
-
описываем таблицы - Base;
-
работаем с сессией через контекстный менеджер.
Отношения
class UserRole(Base):
__tablename__ = 'user_role'
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String, unique=True)
...
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True)
email = sa.Column(sa.String, unique=True)
role_id = sa.Column(
sa.Integer, sa.ForeignKey(UserRole.id),
nullable=False, index=True)
...Отношения
with create_session() as session:
user = session.query(User).first()
print(user.role_id)
# 1Чтобы получить сам объект Role, нужен ещё один запрос в базу?
Отношения
from sqlalchemy import orm as so
class UserRole(Base):
__tablename__ = 'user_role'
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String, unique=True)
users = so.relationship(
'User', back_populates='role',
uselist=True)
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True)
email = sa.Column(sa.String, unique=True)
role_id = sa.Column(
sa.Integer, sa.ForeignKey(UserRole.id),
nullable=False, index=True)
role = so.relationship(
UserRole, back_populates='users',
uselist=False)Отношения
with create_session() as session:
user = session.query(User).first()
print(user.role.name)
# adminКогда мы достаём объект User, надо ли подгружать UserRole?
- lazy loading - нет, запросим его, при первом обращении по атрибуту: user.role;
- joined loading - сразу в один запрос с join;
- subquery loading - сразу в один запрос с подзапросом;
- ...
Отношения m2m
class Film(Base):
__tablename__ = 'film'
id = sa.Column(sa.Integer, primary_key=True)
...
viewers = so.relationship(
'User', secondary=lambda: user_to_film,
back_populates='films')
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True)
...
films = so.relationship(
Film, secondary=lambda: user_to_film,
back_populates='viewers')
user_to_film = sa.Table('user_to_film', Base.metadata,
sa.Column('user_id', sa.Integer, sa.ForeignKey(User.id)),
sa.Column('film_id', sa.Integer, sa.ForeignKey(Film.id)),
)
Отношения m2m
with create_session() as session:
film: Film = session.query(Film).first()
user = session.query(User).get(1)
film.viewers.append(user)
with create_session() as session:
user: User = session.query(User).get(1)
print(user.films)
# [<Film object at...>]Работаем с объектами python, не думая про m2m связь и три таблицы.
Отношения m2m
class FilmRating(Base):
__tablename__ = 'film_rating'
id = sa.Column(sa.Integer, primary_key=True)
user_id = sa.Column(sa.Integer, sa.ForeignKey(User.id))
film_id = sa.Column(sa.Integer, sa.ForeignKey(Film.id))
rating = sa.Column(
sa.Integer,
sa.CheckConstraint('rating > 0 AND rating < 11'))
viewer = so.relationship(User, back_populates='films')
film = so.relationship(Film, back_populates='viewers')
Отношения m2m
class Film(Base):
__tablename__ = 'film'
id = sa.Column(sa.Integer, primary_key=True)
...
viewers = so.relationship(
'FilmRating',
back_populates='film')
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True)
...
films = so.relationship(
'FilmRating',
back_populates='viewer')
class FilmRating(Base):
...
viewer = so.relationship(User, back_populates='films')
film = so.relationship(Film, back_populates='viewers')
Отношения m2m
with create_session() as session:
film = session.query(Film).first()
user = session.query(User).get(1)
film_rating = FilmRating(
film=film, viewer=user, rating=8)
with create_session() as session:
user: User = session.query(User).get(1)
for r in user.films:
print(f'{r.film.title}: {r.rating}')
# Джентельмены: 8Миграции
Изменения схемы базы данных.
Для SQLAlchemy:
pip install alembic
Миграции
class User(Base):
__tablename__ = 'user'
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String())
# новое поле
email = sa.Column(sa.String())alembic revision -m "add user.email column"Миграции
"""add user.email column
Revision ID: 1975ea83b712
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '1975ea83b712'
down_revision = None
branch_labels = None
def upgrade():
op.add_column('user', sa.Column('email', sa.String())
def downgrade():
op.drop_column('user', 'email')
Миграции
накатываем 🍻 и откатываем
alembic upgrade head / <revision_id>
alembic downgrade <revision_id>
from project.db import Base
@pytest.fixture(autouse=True)
def _init_db():
Base.metadata.create_all()
yield
Base.metadata.drop_all()
Как тестировать
-
отдельная тестовая база;
-
создаём данные перед тестом;
-
чистим базу между тестами.
docker
-
"На сервере не работает, а у меня всё работает."
-
Один подход к разным приложениям.
-
Как virtualenv, только на уровне ОС.
-
docker - изолированная среда для запуска одного приложения: веб-сервера, базы данных...
docker

dockerfile
Инструкция, как "приготовить" процесс, который мы хотим запустить.
-
образ, который берём за основу;
-
установка системных пакетов;
-
установка библиотек языка;
-
копирование кода;
-
указание точки входа.
docker
FROM alpine
RUN apk update && \
apk add --update python3-dev py3-pip && \
pip3 install --upgrade pip
COPY requirements.txt /tmp/requirements.txt
RUN pip3 install -r /tmp/requirements.txt
WORKDIR /server
COPY ./server /server
CMD ["gunicorn", "app:app", "-b", "0.0.0.0:8000"]
Образ и контейнер
class ImageV1: # docker build -> image:v1
...
container1_v1 = ImageV1() # docker run image:v1
container2_v1 = ImageV1() # docker run image:v1
...
# some time later
class ImageV2: # docker build -> image:v2
...
container1_v2 = ImageV2() # docker run image:v2
container2_v2 = ImageV2() # docker run image:v2
...
docker
docker run --help
# запускаем:
docker run -p 5432:5432 postgres:11.6
# посмотреть, какие контейнеры сейчас подняты:
docker ps
# подключаемся к базе из терминала:
docker exec -it <container_name> psql -U postgres
docker-compose
инструмент для управления несколькими связанными контейнерами: например, контейнер с веб-сервисом и контейнер с базой данных.
-
запустить и соединить несколько связанных сервисов;
-
не запоминать миллион флагов команд для запуска.
docker-compose
version: '2.4'
web-app:
image: my_image_name:version
environment:
- DB_URL=postgresql://postgres:postgres@db/postgres
ports:
- 5000:5000
depends_on:
- db
db:
image: postgres:11.6
environment:
- POSTGRES_DB=postgres
- POSTGRES_PASSWORD=password
ports:
- 5432:5432
docker-compose.yamlДЗ
Вопросики
DB
By persi



