




Patrick Power
Economics PhD @ Boston University
We all intuitively understand what it means for something to Cause something else
Many of the questions that we're interested in are causal in nature
Set of People
Set of Possible Data Sets
Generalize
Context
What is the effect of taking BA222 versus the Excel Equivalent on Earnings Five Years after Graduation?
Notation
Five Year Post College Earnings if the person took BA222
Five Year Post College Earnings if the person did not take BA222
Estimand
Idea
Approximate the Average Treatment Effect by comparing the earnings of students who took BA222 with the earnings of those who took the Excel Equivalent
The Average Earnings for those who took BA222
The Average Earnings for those who took the excel equivalent
Difference-in-Means
Difference-in-Means
Average Treatment on the Treated
Selection Bias
Python Exercise
means = '###FILL THIS IN###'.mean()
print(f'The difference in means is: ${means.loc[1.0] - means.loc[0.0]:.0f}')Difference-in-Means
treated_df = df['###FILL THIS IN###']
ATT = treated_df['###FILL THIS IN###'].mean() - treated_df['###FILL THIS IN###'].mean()
print(ATT)Average Treatment on the Treated
means_y0 = df.groupby('###FILL THIS IN####'].mean()
selction_bias = means_y0.loc[1.0] - means_y0[0.0]
print(selction_bias)Selection Bias
Idea # 2
Instead of taking the difference between treated and control groups, let's average local differences between treated and control groups
Summary (thus far)
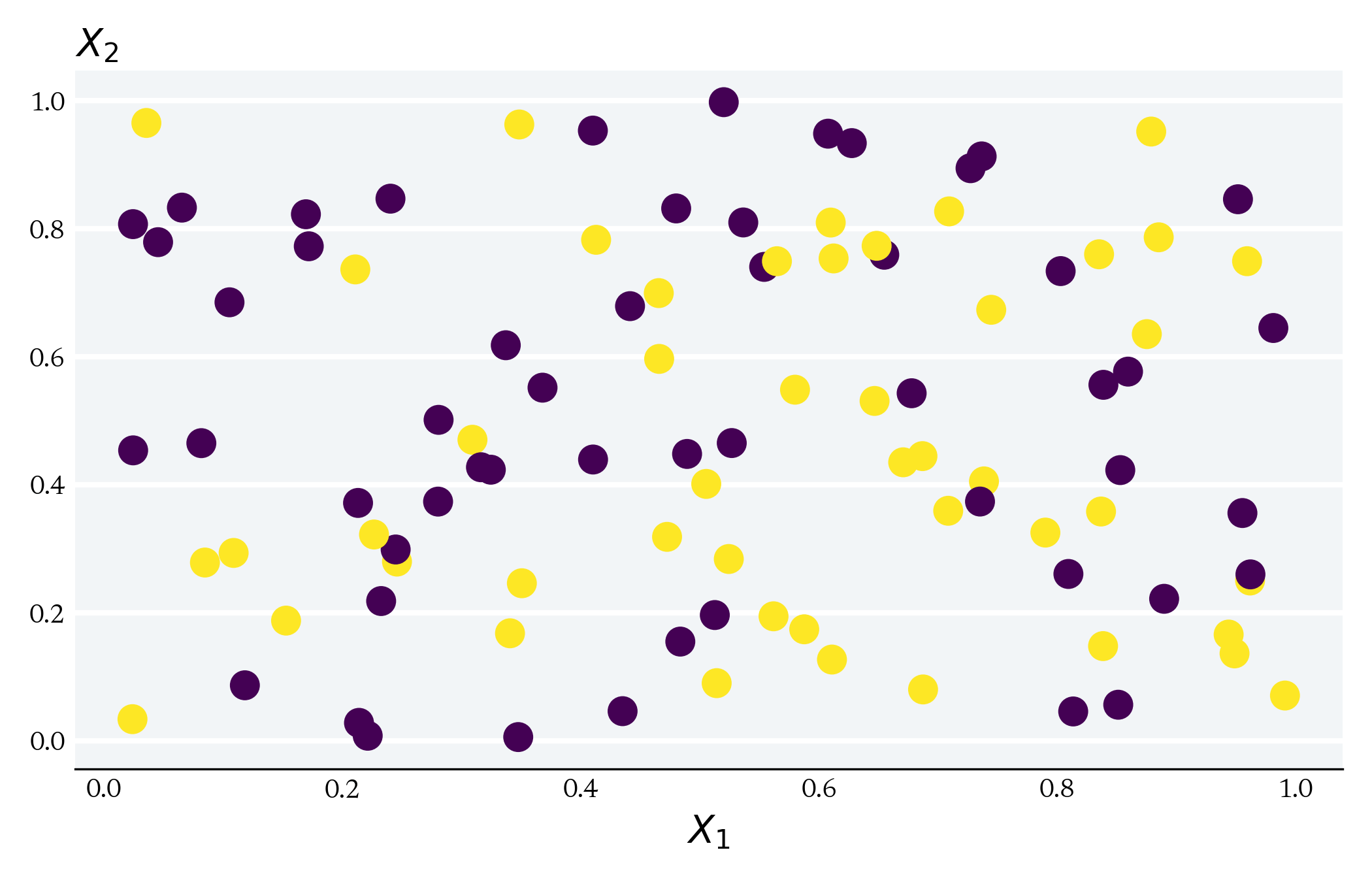
Local with respect to features/ independent variables
(1) Take difference-in-means within each group
(2) Take the average differences
Idea # 2
Let's assume we observe a Questrom Concentration
Accounting
Finance
Marketing
Real Estate
Strategy
Under what conditions is this a good idea?
Key Assumption
"Within each concentration, the decision about to take BA22 is independent of the potential outcomes"
Python Exercise
estimate = 0
variables = ['X0', 'X1', 'X2', 'X3', 'X4']
for var in variables:
df_temp = df['###FILL THIS IN###']
weight = len(df_temp) / len(df)
effect = df_temp.groupby('Treatment')['Outcome'].mean().loc[1.0] - df_temp.groupby('Treatment')['Outcome'].mean().loc[0.0]
estimate += weight*effect
print(estimate)Average Within Group Difference in Means
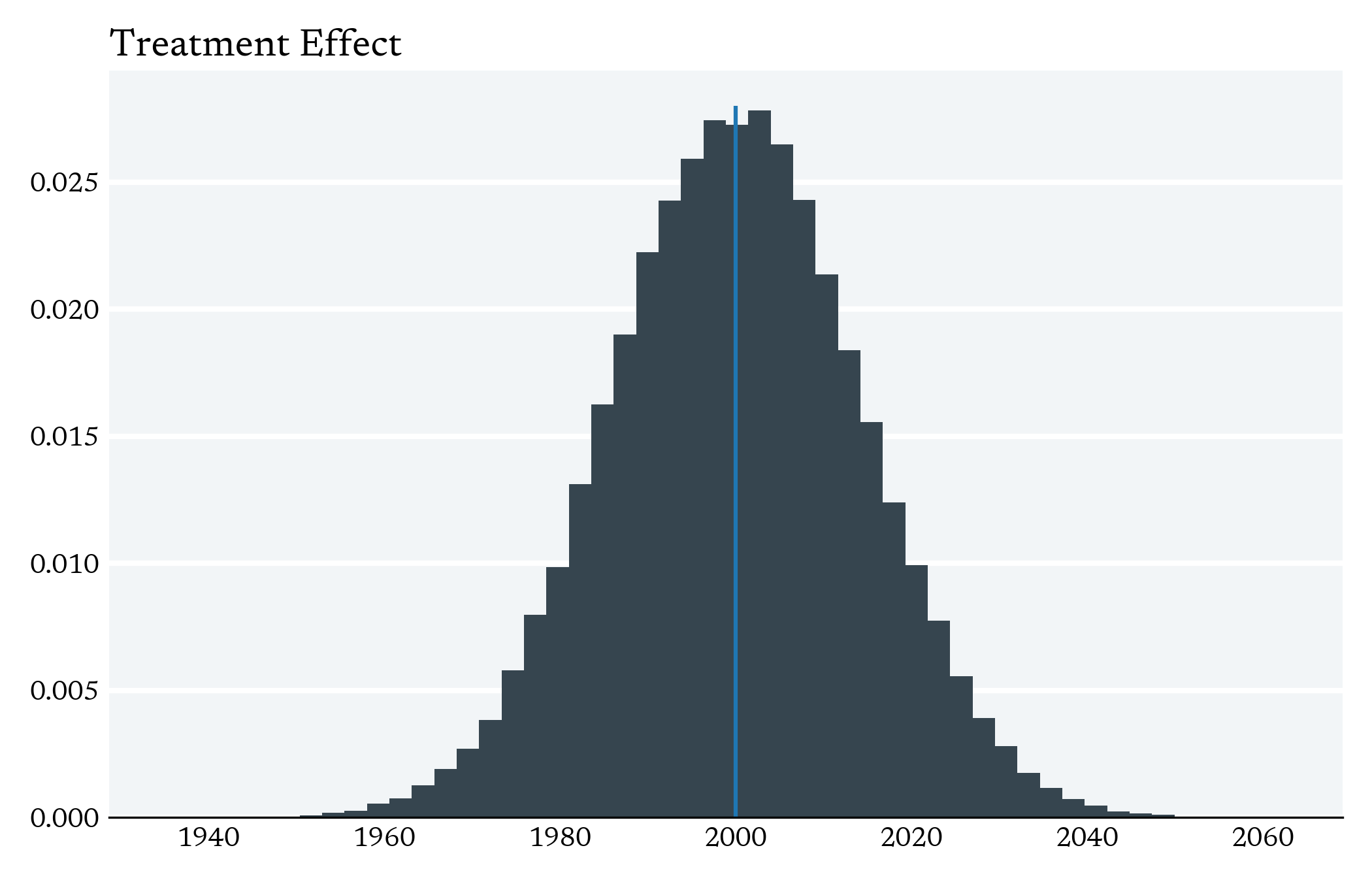
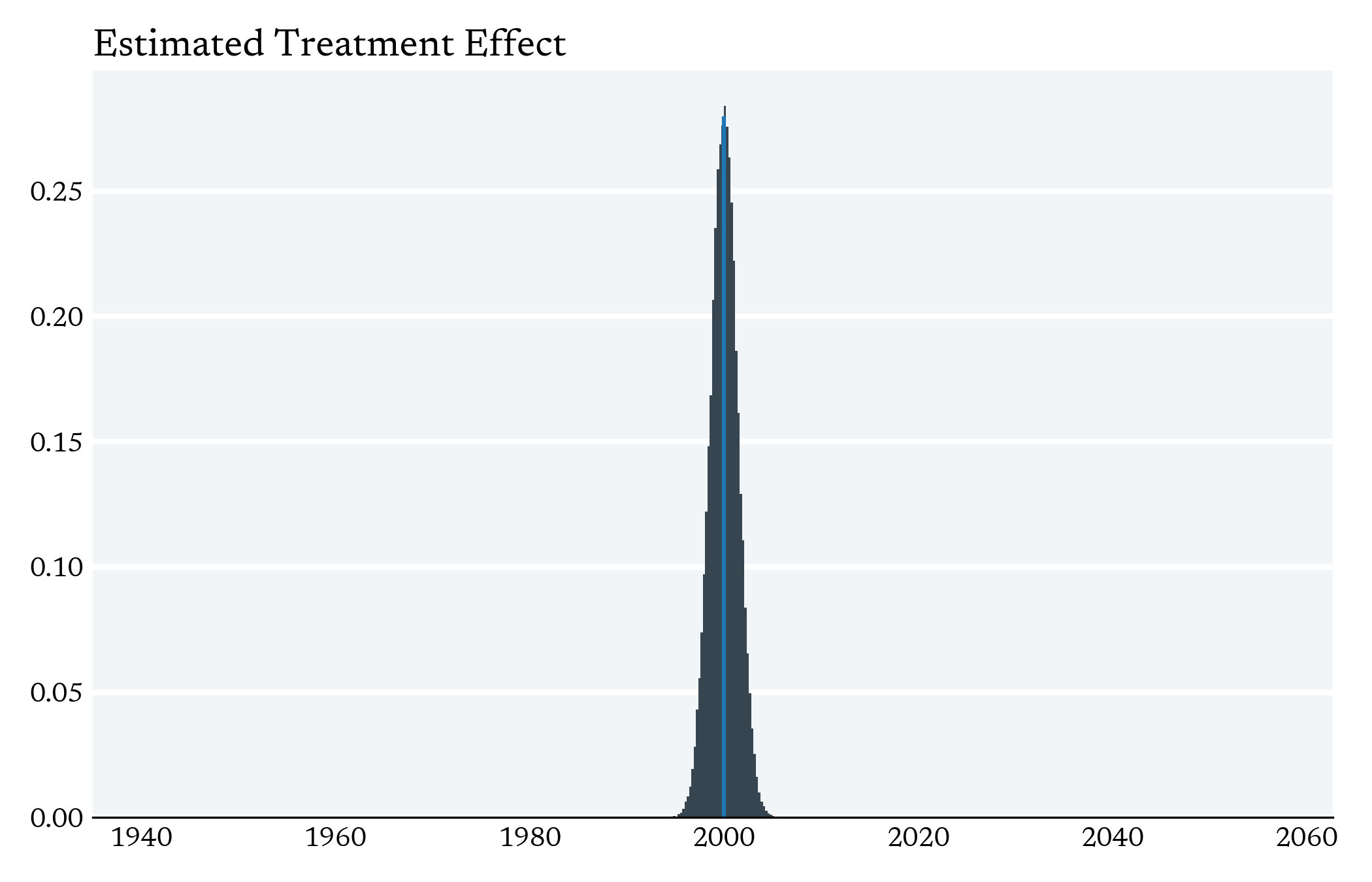
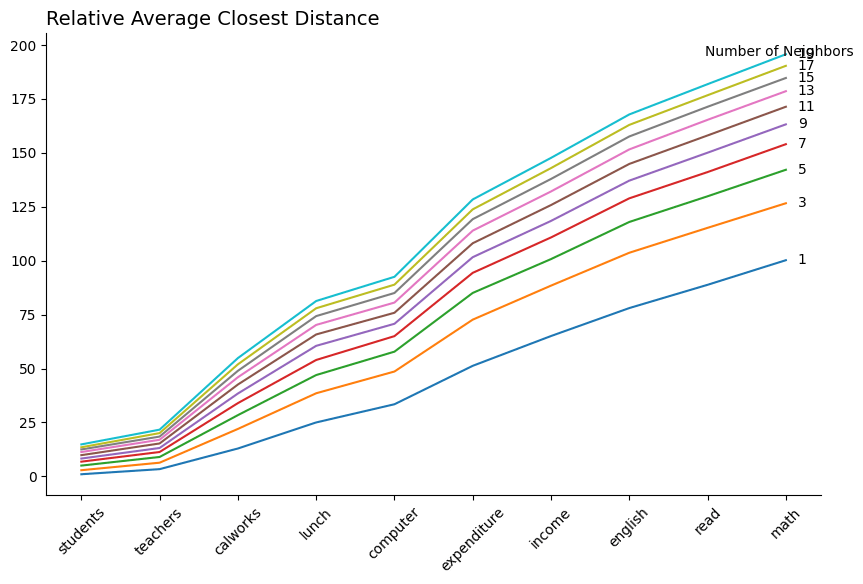
The Central Tension in Causal Inference is between local variation in Treatment and the Curse of Dimensionality
Summary
In causal inference, we are concerned about selection bias
One idea is to include additional controls such that
The Conditional Expectation Function is central to our Framework for Estimating Causal Effects
Conditional Expectation Function
Population OLS Model
Sample OLS Model
In Class Excise
Hypothetically, let's say you wanted to estimate the impact that a specific teacher had on the average student's midterm grade.
(B) If so, which controls would you include to reduce the selection bias?
Notation
Indicator of specific teacher
Midterm grade if they didn't have that teacher
Midterm grade if they did have that teacher
(A) Are you concerned about selection bias?
Estimation Challenges
Curse of Dimensionality
Omitted Variables
Sensitivity
We're concerned that a variable like Ability, X, is driving the selection bias
Coefficient of Interest
Not in Our Data Set
Let's say that we observe the Outcome and Treatment variable
Observed Coefficient
Coefficient of Interest
The average change in the outcome given a per unit change in the latent variable, holding treatment constant
Nuisance Parameter
The slope parameter from regressing the Treatment on the Latent Variable
At a High Level, Causal Inference doesn't work as well as we might hope
I don't think this is emphasized as much as it should be in introductory econometric classes (which makes sense partly, why demotive the class?!)
Example
Using only experimental variation, we cannot determine whether the use of experimental vouchers has a high long run impact (however measured) than the use of standard vouchers
Research
Credible
Important
Choice Set
What This Means:
(1) We'll have to make "Approximations"
(2) The data alone doesn't provide a unique answer to our question
In practice, we often cannot provide guarantees for the performance of our approach under plausible assumptions
By Patrick Power




