Jumping over data land mines with blaze
Recap of @mrocklin's talk
Blaze is good at:
-
Separating computation from data
-
Migration between different data sources
-
Providing an well-known API for computing over different data sources (think pandas)
Separating computation from data
>>> from blaze import Symbol, discover, compute
>>> import pandas as pd
>>> df = pd.DataFrame({'name': ['Alice', 'Bob', 'Forrest', 'Bubba'],
... 'amount': [10, 20, 30, 40]})
...
>>> t = Symbol('t', discover(df))
>>> t.amount.sum()
sum(t.amount)
>>> compute(t.amount.sum(), df)
100
>>> compute(t.amount.sum(), df.values.tolist())
100
>>> compute(t.amount.sum(), df.to_records(index=False))
100Migrating between different data sources
>>> from blaze import into, drop
>>> import numpy as np
>>> into(list, df)
[(10, 'Alice'), (20, 'Bob'), (30, 'Forrest'), (40, 'Bubba')]
>>> into(np.ndarray, df)
rec.array([(10, 'Alice'), (20, 'Bob'), (30, 'Forrest'), (40, 'Bubba')],
dtype=[('amount', '<i8'), ('name', 'O')])
>>> into('sqlite:///db.db::t', df)
<blaze.data.sql.SQL at 0x108278fd0>
>>> drop(_) # remove the database for the next example
>>> result = into(pd.DataFrame, into('sqlite:///db.db::t', df))
>>> result
amount name
0 10 Alice
1 20 Bob
2 30 Forrest
3 40 Bubba
>>> type(result)
pandas.core.frame.DataFrameA comfortable API
>>> from blaze import Data
>>> d = Data(df)
>>> d.amount.dshape
dshape("4 * int64")
>>> d.amount.
d.amount.count d.amount.max d.amount.shape
d.amount.count_values d.amount.mean d.amount.sort
d.amount.distinct d.amount.min d.amount.std
d.amount.dshape d.amount.ndim d.amount.sum
d.amount.fields d.amount.nelements d.amount.truncate
d.amount.head d.amount.nrows d.amount.utcfromtimestamp
d.amount.isidentical d.amount.nunique d.amount.var
d.amount.label d.amount.relabel
d.amount.map d.amount.schema
>>> d.name.dshape
dshape("4 * string")
>>> d.name.
d.name.count d.name.head d.name.max d.name.nunique
d.name.count_values d.name.isidentical d.name.min d.name.relabel
d.name.distinct d.name.label d.name.ndim d.name.schema
d.name.dshape d.name.like d.name.nelements d.name.shape
d.name.fields d.name.map d.name.nrows d.name.sortBlaze also lets you DIY
Who's heard of the q language?
q)x:"racecar"
q)n:count x
q)all{[x;n;i]x[i]=x[n-i+1]}[x;n]each til _:[n%2]+1
1bCheck if a string is a palindrome
q)-1 x
racecar
-1
q)1 x
racecar1Print to stdout, with and without a newline
Um, integers are callable?

How about:
1 divided by cat

q)1 % "cat"
0.01010101 0.01030928 0.00862069
However, KDB is fast
so....
Ditch Q,
Keep KDB+
kdbpy: Q without the WAT, via blaze
- KDB+ is a database sold by Kx Systems.
- Free 32-bit version available for download on their website.
- Column store*.
- Makes big things feel small and huge things feel doable.
- Heavily used in the financial world.
Why KDB+/Q?
*It's a little more nuanced than that
-
It's a backend for blaze
-
It generates q code from python code
-
That code is run by a q interpreter
What is kdbpy?
To the notebook!
It's a WIP
- Only partial support for KDB's partitioned and splayed tables
- Q code is different for different kinds of tables
- We really want a single API to drive the different kinds
- Q code is different for different kinds of tables
- No profiling on really huge things yet
- Code generation is overly redundant in certain cases
How does Q compare to other blaze backends?
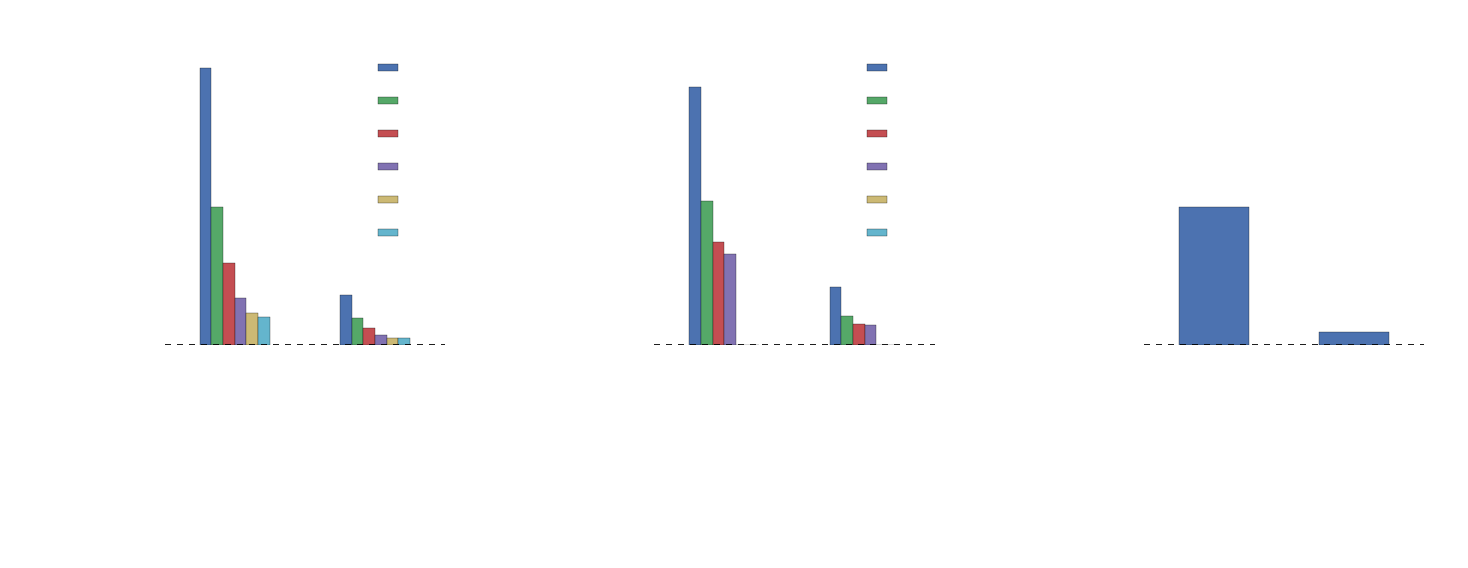
NYC Taxi Trip Data
≈16 GB (trip dataset only)
partitioned in KDB+ on date (year.month.day)
vs
blaze
The computation
-
group by on
-
passenger count
-
medallion
-
hack license
-
-
sum on
-
trip time
-
trip distance
-
-
cartesian product of the above
The hardware
- two machines
- 32 cores, 250GB RAM, ubuntu
- 8 cores, 16GB RAM, osx
Beef vs. Mac 'n Cheese vs. Pandas
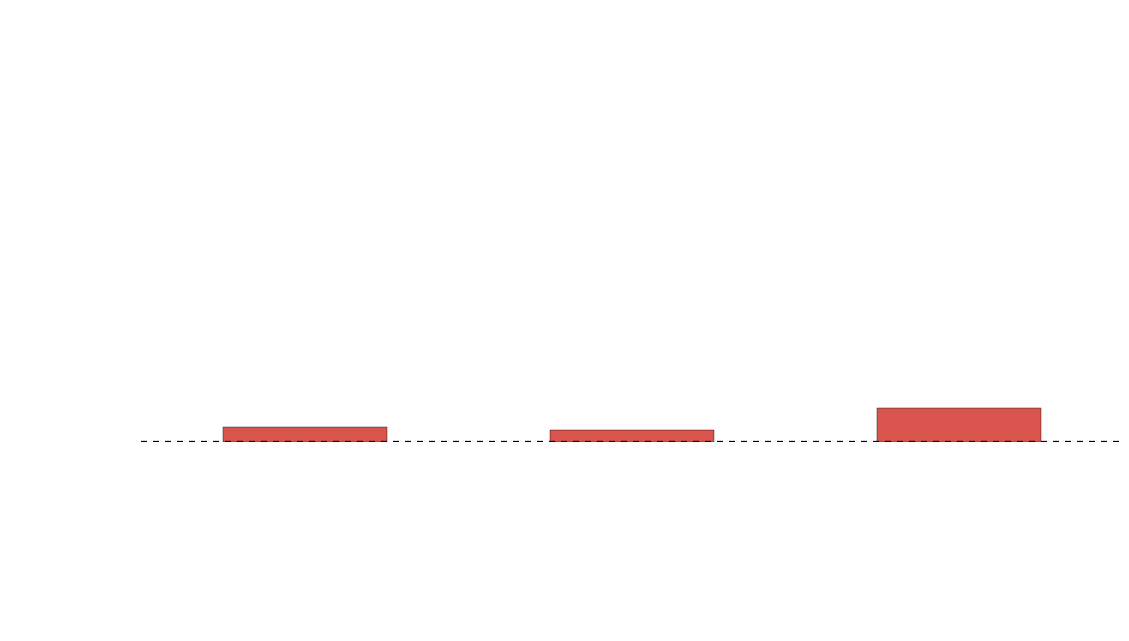
How pe-q-ular...
Questions
- Did I partition the dataset optimally in KDB?
- Are my queries optimal?
-
Is this a fair comparison?
- bcolz splits each column into chunks that fit in cache
- kdb writes a directory of columns per value in the partition column
-
kdb is using symbols instead of strings
- symbols are much faster in kdb
-
requires an index column for partitions
- can take a long time to sort
- strings are not very efficient
- symbols are really a categorical type
How does the blaze version work?
bcolz +
pandas +
multiprocessing
bcolz
- Column store
- directory per column
- Column chunked to fit in cache
- numexpr in certain places
- sum
- selection
- arithmetic
- transparent reading from disk
pandas
- fast, in-memory analytics
Multiprocessing
- compute each chunk in separate process
Storage
Compute
Parallelization
Usage Example
>>> from blaze import by, compute, Data
>>> from multiprocessing import Pool
>>> data = Data('trip.bcolz')
>>> pool = Pool() # default to the number of logical cores
>>> expr = by(data.passenger_count, avg=data.trip_time_in_secs.mean())
>>> result = compute(expr, map=pool.map) # chunksize defaults to 2 ** 20
>>> result
passenger_count avg
0 0 122.071500
1 1 806.607092
2 2 852.223353
3 3 850.614843
4 4 885.621065
5 5 763.933618
6 6 760.465655
7 7 428.485714
8 8 527.920000
9 9 506.230769
10 129 240.000000
11 208 55.384615
12 255 990.000000
>>> timeit compute(expr, map=pool.map)
1 loops, best of 3: 5.67 s per loopThe guts
chunk = symbol('chunk', chunksize * leaf.schema)
(chunk, chunk_expr), (agg, agg_expr) = split(leaf, expr, chunk=chunk)
data_parts = partitions(data, chunksize=(chunksize,))
parts = list(map(curry(compute_chunk, data, chunk, chunk_expr),
data_parts))
# concatenate parts into intermediate
result = compute(agg_expr, {agg: intermediate})
- Split an expression into chunks
- Get the chunked expression and the agg
- run Pool.map across each chunk
- compute the aggregate function over the intermediate
THANKS!
- Matt Rocklin
- Hugo Shi
- Jeff Reback
- Everyone @ ContinuumIO
Toys in blaze-land
By Phillip Cloud
Toys in blaze-land
Blazing through data land mines with Python




